Kaggle Challenge Solution: Quick, Draw! Doodle Recognition Challenge
Bài đăng này đã không được cập nhật trong 7 năm
Xin chào tất cả các bạn, hôm nay mình sẽ hướng dẫn các bạn giải quyết một bài toán tương đối phổ biến trong lĩnh vực thị giác máy tính, đó là bài toán phân loại hình ảnh bằng cách sử dụng các mô hình Deep Learning. Bài toán này là một "challenge" của website Kaggle, một website rất phổ biến cho cộng đồng các nhà khoa học dữ liệu thi đấu với nhau, nhằm giải quyết các bài toán thực tế.
Bài toán
Challenge mà chúng ta sẽ cùng nhau giải quyết trong bài viết này là Quick, Draw! Doodle Recognition Challenge.
Đây là một bài toán phân loại hình ảnh dựa trên ảnh vẽ tay của người dùng khi chơi trò chơi vẽ hình, các bạn có thể chơi game tại website này. Khi chơi, mỗi người chơi sẽ được yêu cầu vẽ hình ảnh của một thực thể nào đó, ví dụ như: ô tô, xe máy, máy bay, bàn, ghế, ... Hệ thống phân loại mà chúng ta xây dựng sẽ có nhiệm vụ nhận diện và phân loại hình vẽ của người chơi, kiểm tra rằng người chơi đang vẽ đúng hay sai, mà cho biết hình vẽ hiện tại của người dùng giống với thực thể nào nhất. Đây là một trò chơi khá thú vị và đòi hỏi tính nhanh nhạy. Bây giờ chúng ta sẽ cùng nhau phân tích dữ liệu của bài toán.
Overview
Trước khi xử lý với dữ liệu, chúng ta tất nhiên cần phải tải dữ liệu về tại đường dẫn của Challenge ở phía trên. Dữ liệu của chúng ta bao gồm:
- sample_submission.csv - mẫu tệp dùng để nộp đáp án lên Kaggle
- test_raw.csv - dữ liệu test nguyên gốc
- test_simplified.csv - dữ liệu test đã được đơn giản hoá (nhằm giảm dung lượng bộ nhớ)
- train_raw.zip - dữ liệu dùng để huấn luyện gốc
- train_simplified.zip - dữ liệu dùng để huấn luyện đã được đơn giản hoá
Để đơn giản và tiết kiệm bộ nhớ, chúng ta sẽ chỉ làm việc với dữ liệu đã được đơn giản hoá, dữ liệu này cũng đảm bảo được rằng không mất đi các thuộc tính cần thiết so với dữ liệu gốc ban đầu (nếu chúng ta xử lý với dữ liệu gốc, lượng dữ liệu mà chúng ta cần tải về là 73GB, và sau khi giải nén và sinh ảnh ra thì tốn khoảng 300GB bộ nhớ).
Cách đánh giá mô hình
Trong cuộc thi này, kết quả của mọi người được đánh giá dựa trên công thức Mean Average Precision @ 3 (MAP@3) như sau:
trong đó, U là số lượng ảnh trong tập dữ liệu test, P(k) là precision at cutoff k, n là số lượng dự đoán trên mỗi ảnh. Để dễ hiểu hơn, các bạn có thể tham khảo một cách giải thích về độ đo này tại đường dẫn: https://www.kaggle.com/wendykan/map-k-demo
Giải thưởng
Giải thưởng của cuộc thi này như sau:
- First place: $12000
- Second place: $8000
- Third place: $5000
(khá thú vị phải không ?!! :v)
Tiền xử lý dữ liệu
Để giải quyết tốt một bài toán, việc tiền xử lý dữ liệu là một việc vô cùng quan trọng, việc xử lý dữ liệu chiếm phần lớn thời gian trong việc giải quyết một bài toán Machine Learning. Trong bài toán này cũng vậy, để có được một kết quả tốt, chúng ta cần phải phân tích những đặc điểm của dữ liệu, nhằm đem lại kết quả tốt nhất cho bài toán.
Chúng ta cùng xem một tệp dữ liệu về chim cú (owl.csv) bằng cách như sau:
owls = pd.read_csv('../input/train_simplified/owl.csv')
owls = owls[owls.recognized]
owls['timestamp'] = pd.to_datetime(owls.timestamp)
owls = owls.sort_values(by='timestamp', ascending=False)[-100:]
owls['drawing'] = owls['drawing'].apply(ast.literal_eval)
owls.head()
Kết quả thu được như sau:
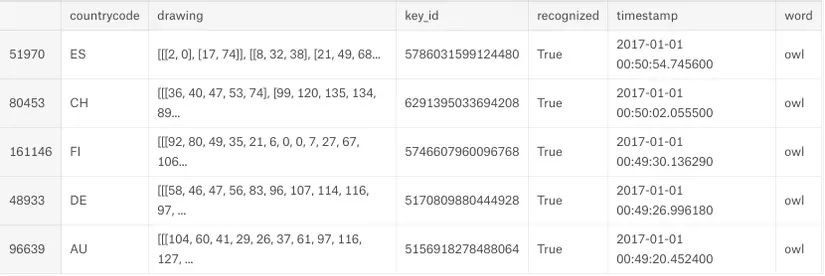
Giải thích một chút về dữ liệu mà chúng ta có được ở trên:
- countrycode: là mã quốc gia của người chơi
- drawing: dữ liệu về nét vẽ của hình vẽ, đây là dữ liệu dưới dạng các điểm ảnh, chúng ta cần nối các điểm ảnh này lại với nhau để tạo thành một hình vẽ hoàn chỉnh, phục vụ dữ liệu cho mô hình Deep Learning.
- key_id: id của hình vẽ
- recognized: trường này chỉ thị rằng hình ảnh đã được kiểm duyệt bởi con người hay chưa: recognized = True nghĩa là hình ảnh vẽ là đúng, đã qua sự xác minh của con người; recognized = False nghĩa là hình ảnh có thể được gán nhãn đúng hoặc sai. Vì vậy chúng ta cũng cần phải xử lý phần dữ liệu bị sai này. Ở phần tiếp theo mình sẽ phân tích về dữ liệu bị unrecognized.
- word: nhãn của hình ảnh
Bây giờ chúng ta cùng vẽ một số hình ảnh về chim cú, cách thực hiện như sau:
n = 10
fig, axs = plt.subplots(nrows=n, ncols=n, sharex=True, sharey=True, figsize=(16, 10))
for i, drawing in enumerate(owls.drawing):
ax = axs[i // n, i % n]
for x, y in drawing:
ax.plot(x, -np.array(y), lw=3)
ax.axis('off')
fig.savefig('owls.png', dpi=200)
plt.show();
Và hình ảnh mà chúng ta thu được là:
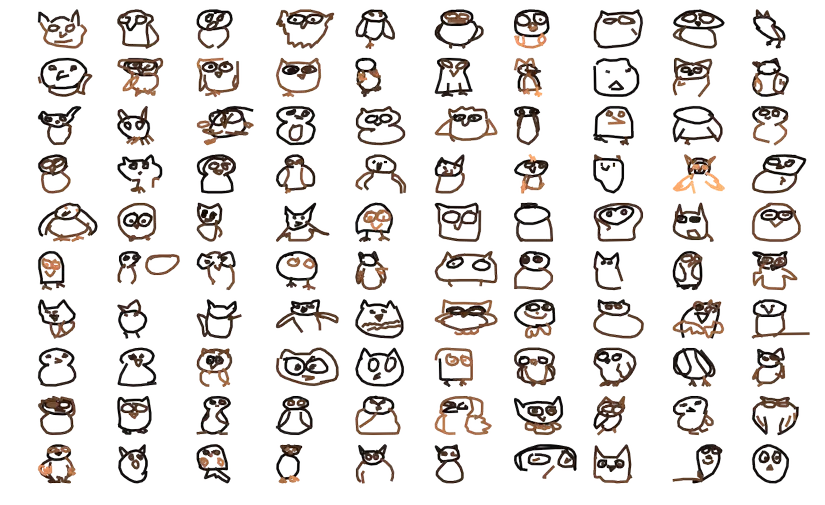
Chúng ta nhận thấy rằng có một số hình ảnh không giống chim cú lắm đúng không?  Một số hình ảnh mà mình đã phân tích được cho là gán sai nhãn cho dữ liệu như sau:
Một số hình ảnh mà mình đã phân tích được cho là gán sai nhãn cho dữ liệu như sau:

Một điều mà chúng ta có thể kiểm tra ở đây là việc dữ liệu không cân bằng, số lượng ảnh của mỗi thể loại như sau:
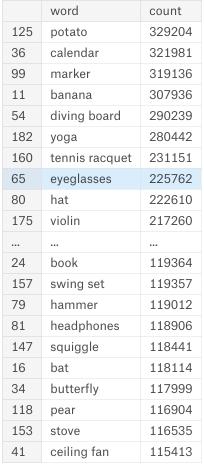
Khi huấn luyện mô hình, chúng ta cũng cần phải lưu ý đến điều này, bởi vì khi dữ liệu không cân bằng, mô hình cũng sẽ có xu hướng dự đoán nghiêng về các class có số lượng ảnh lớn hơn, nhằm mục đích tối ưu hoá hàm mục tiêu mà chúng ta sử dụng.
Chuẩn bị dữ liệu huấn luyện
Có thể dễ dàng nhận thấy rằng, lượng hình ảnh/dữ liệu mà chúng ta cần phải xử lý là rất lớn, vì vậy, chúng ta không thể tải hết hình ảnh vào RAM cùng một lúc để xử lý. Cách làm mà chúng ta sẽ sử dụng ở đây là trộn tất cả các tệp dữ liệu lại với nhau, xáo trộn nó, và chia ra các tệp nhỏ hơn, để đảm bảo rằng, trong mỗi tệp nhỏ này, mỗi tệp sẽ chứa đủ tất cả các class nhằm phục vụ cho việc huấn luyện mô hình. Việc làm này mình tham khảo từ một public kernel được chia sẻ trên Kaggle tại liên kết này.
Cách thức mà chúng ta thực hiện như sau:
Đầu tiên là thêm các thư viện cần thiết:
%matplotlib inline
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import json
import os
import datetime as dt
from tqdm import tqdm
import pandas as pd
import numpy as np
Định nghĩa các hàm và class:
def f2cat(filename: str) -> str:
return filename.split('.')[0]
class Simplified():
def __init__(self, input_path='./input'):
self.input_path = input_path
def list_all_categories(self):
files = os.listdir(os.path.join(self.input_path, 'train_simplified'))
return sorted([f2cat(f) for f in files], key=str.lower)
def read_training_csv(self, category, nrows=None, usecols=None, drawing_transform=False):
df = pd.read_csv(os.path.join(self.input_path, 'train_simplified', category + '.csv'),
nrows=nrows, parse_dates=['timestamp'], usecols=usecols)
if drawing_transform:
df['drawing'] = df['drawing'].apply(json.loads)
return df
Trong đó:
- f2cat: nghĩa là file to category, hàm này có nhiệm vụ chuyển tên file thành tên của thể loại. Bởi vì tên file là *.csv, vì vậy chúng ta cần bỏ đuôi .csv đi.
- list_all_categories: trả về tất các các thể loại (nhãn/lớp) mà chúng ta cần phân biệt.
- read_training_csv: đọc file csv và trả về dataframe
Tiếp theo chúng ta có một số biến, đối tượng và hằng cần thiết:
s = Simplified('../input')
NCSVS = 100
categories = s.list_all_categories()
Trong đó:
- s là một đối tượng của lớp Simplified
- NCSVS: số lượng file csv mà chúng ta muốn chia nhỏ dữ liệu ra
- categories: danh sách các thể loại
for y, cat in tqdm(enumerate(categories)):
df = s.read_training_csv(cat, nrows=10000)
df['y'] = y
df['cv'] = (df.key_id // 10 ** 7) % NCSVS
for k in range(NCSVS):
filename = 'train_k{}.csv'.format(k)
chunk = df[df.cv == k]
chunk = chunk.drop(['key_id'], axis=1)
if y == 0:
chunk.to_csv(filename, index=False)
else:
pchunk.to_csv(filename, mode='a', header=False, index=False)
for k in tqdm(range(NCSVS)):
filename = 'train_k{}.csv'.format(k)
if os.path.exists(filename):
df = pd.read_csv(filename)
df['rnd'] = np.random.rand(len(df))
df = df.sort_values(by='rnd').drop('rnd', axis=1)
df.to_csv(filename + '.gz', compression='gzip', index=False)
os.remove(filename)
print(df.shape)
Ở đây, với mỗi thể loại, chúng ta sẽ lấy ra 10000 ảnh, nhằm mục đích cho dữ liệu cân bằng, sau đó chúng ta sẽ chia ra 100 file nhỏ hơn. Việc chỉ sử dụng 10000 ảnh cho mỗi thể loại nhằm mục đích đánh giá và so sánh kết quả của các mô hình khác nhau trên tập dữ liệu nhỏ, sau đó chúng ta sẽ áp dụng lên toàn bộ tập dữ liệu. Việc này tiết kiệm được rất nhiều thời gian do bộ dữ liệu của chúng ta rất lớn, lên đến 50.000.000 ảnh.
Xây dựng và huấn luyện mô hình
Sau khi xử lý với dữ liệu, chúng ta thu được 100 files chứa dữ liệu khác nhau. Chúng ta cần phải sử dụng tất cả 100 files này để huấn luyện mô hình. Trong bài viết này, mình sẽ sử dụng thư viện Keras để xây dựng và huấn luyện mô hình. Đây là một thư viện tương đối dễ sử dụng và phổ biến.
Chúng ta cùng bắt đầu nào!
Vẫn như thường lệ, chúng ta cần import các thư viện cần thiết để sử dụng:
import numpy as np
import six
import tensorflow as tf
import time
import os
import sklearn
%matplotlib inline
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import os
import ast
import datetime as dt
import seaborn as sns
import cv2
import pandas as pd
import tensorflow as tf
import keras
from keras.layers import *
from keras.metrics import categorical_accuracy, top_k_categorical_accuracy, categorical_crossentropy
from keras.models import Sequential, Model
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpoint
from keras.optimizers import Adam
from keras.applications import MobileNet
from keras.applications.densenet import DenseNet121, DenseNet169
from keras.applications.mobilenet import preprocess_input
start = dt.datetime.now()
Tương đối nhiều phải không?
Tiếp theo chúng ta sẽ khai báo một số hằng số cần thiết:
DP_DIR = 'data' # thư mục chứa dữ liệu
BASE_SIZE = 256 # kích thước gốc của ảnh
NCSVS = 100 # số lượng files csv mà chúng ta đã chia ở bước trên
NCATS = 340 # số lượng category (số lớp mà chúng ta cần phân loại)
STEPS = 1000 # số bước huấn luyện trong 1 epoch
EPOCHS = 30 # số epochs huấn luyện
size = 128 # kích thước ảnh training đầu vào
batchsize = 256
np.random.seed(seed=1987) # cài đặt seed
tf.set_random_seed(seed=1987) # cài đặt seed
Ở đây chúng ta cần phải resize ảnh về 128 hoặc 64 để có thể huấn luyện một cách nhanh hơn, do hạn chế về mặt tài nguyên, ảnh 256 là tương đối lớn, khi đó, batch size mà chúng ta dùng được sẽ nhỏ hơn, và kết quả là quá trình huấn luyện sẽ lâu hơn khá nhiều.
Như ở phần trước, chúng ta đánh giá kết quả của cuộc thi dựa trên độ đo MAP@3, vì vậy chúng ta cần phải viết hàm đánh giá để tính điểm với độ đo này:
def apk(actual, predicted, k=3):
"""
Source: https://github.com/benhamner/Metrics/blob/master/Python/ml_metrics/average_precision.py
"""
if len(predicted) > k:
predicted = predicted[:k]
score = 0.0
num_hits = 0.0
for i, p in enumerate(predicted):
if p in actual and p not in predicted[:i]:
num_hits += 1.0
score += num_hits / (i + 1.0)
if not actual:
return 0.0
return score / min(len(actual), k)
def mapk(actual, predicted, k=3):
"""
Source: https://github.com/benhamner/Metrics/blob/master/Python/ml_metrics/average_precision.py
"""
return np.mean([apk(a, p, k) for a, p in zip(actual, predicted)])
Ngoài ra, chúng ta có thể sử dụng một độ đo có thể sử dụng để quan sát quá trình huấn luyện trong bài toán này, đó là độ đo Top3 accuracy như sau:
def top_3_accuracy(y_true, y_pred):
return top_k_categorical_accuracy(y_true, y_pred, k=3)
Tiếp đến là phần xây dựng mô hình:
input_layer = Input((size, size, 1))
common_layer = Reshape((size*size,), input_shape=(size, size, 1), name='common_layer')(input_layer)
common_layer = RepeatVector(3)(common_layer)
common_layer = Reshape((3, size, size), name='rs')(common_layer)
common_layer = Permute((3, 2, 1))(common_layer)
pretrained_model = DenseNet169(weights='imagenet', include_top=True, input_tensor=common_layer, classes=1000)
layer = pretrained_model.layers[-2].output
layer = Dense(NCATS, activation='softmax')(layer)
model = Model(input_layer, layer)
Ở đây, chúng ta sẽ sử dụng weights đã được huấn luyện trên bộ dữ liệu ImageNet, việc làm này sẽ giúp mô hình của chúng ta hội tụ nhanh hơn, so với random weights. Nhưng để sử dụng được weights của ImageNet, chúng ta cần phải đưa ảnh đen trắng của chúng ta về ảnh 3 chiều, đó là lý do cho những dòng code này:
common_layer = Reshape((size*size,), input_shape=(size, size, 1), name='common_layer')(input_layer)
common_layer = RepeatVector(3)(common_layer)
common_layer = Reshape((3, size, size), name='rs')(common_layer)
common_layer = Permute((3, 2, 1))(common_layer)
Ngoài ra, số lượng thể loại của tập ImageNet là 1000, nhưng tập dữ liệu trong bài toán của chúng ta là 340, vì vậy, chúng ta sẽ bỏ lớp cuối cùng là Dense(1000) của ImageNet bằng Dense(340).
Chúng ta sẽ sử dụng Adam Optimizer và một số hàm đánh giá đã khai báo ở trên:
model.compile(optimizer=Adam(lr=0.001), loss='categorical_crossentropy',
metrics=[categorical_crossentropy, categorical_accuracy, top_3_accuracy])
Như đã nhắc đến ở phần trước, do chúng ta có 100 files nhỏ chứa dữ liệu khác nhau, vì vậy chúng ta cần xây dựng một hàm Generator để sinh dữ liệu vào trong quá trình huấn luyện. Nhiệm vụ của hàm Generator này là mỗi lần sẽ trả về một batch các ảnh. Ví dụ với batch_size = 256, hàm generator sẽ trả về 256 ảnh một lần. Hàm Generator này sẽ quét qua tất cả các file để sinh dữ liệu cho chúng ta, chi tiết như sau:
def draw_cv2(raw_strokes, size=256, lw=6, time_color=True):
img = np.zeros((BASE_SIZE, BASE_SIZE), np.uint8)
for t, stroke in enumerate(raw_strokes):
for i in range(len(stroke[0]) - 1):
color = 255 - min(t, 10) * 13 if time_color else 255
_ = cv2.line(img, (stroke[0][i], stroke[1][i]),
(stroke[0][i + 1], stroke[1][i + 1]), color, lw)
if size != BASE_SIZE:
return cv2.resize(img, (size, size))
else:
return img
def image_generator_xd(size, batchsize, ks, lw=6, time_color=True):
while True:
for k in np.random.permutation(ks):
filename = os.path.join(DP_DIR, 'train_k{}.csv.gz'.format(k))
for df in pd.read_csv(filename, chunksize=batchsize):
df['drawing'] = df['drawing'].apply(ast.literal_eval)
x = np.zeros((len(df), size, size, 1))
for i, raw_strokes in enumerate(df.drawing.values):
x[i, :, :, 0] = draw_cv2(raw_strokes, size=size, lw=lw,
time_color=time_color)
x = preprocess_input(x).astype(np.float32)
y = keras.utils.to_categorical(df.y, num_classes=NCATS)
yield x, y
def df_to_image_array_xd(df, size, lw=6, time_color=True):
df['drawing'] = df['drawing'].apply(ast.literal_eval)
x = np.zeros((len(df), size, size, 1))
for i, raw_strokes in enumerate(df.drawing.values):
x[i, :, :, 0] = draw_cv2(raw_strokes, size=size, lw=lw, time_color=time_color)
x = preprocess_input(x).astype(np.float32)
return x
Trong đó:
- Hàm draw_cv2 có nhiệm vụ vẽ và trả về ảnh với đầu vào là trường drawing của 1 bản ghi, như mô tả ở đầu bài viết
- Hàm image_generator_xd chính là hàm generator đã nhắc đến ở trên, mỗi lần hàm này sẽ trả về một số lượng bằng batch_size các cặp [x, y] tương ứng là ảnh đầu vào và nhãn của nó.
- Hàm df_to_image_array_xd có nhiệm vụ trả về mảng các cặp [x, y] (phục vụ cho tập validation và tập test)
Tiếp theo, chúng ta sẽ sinh ảnh cho tập validation, do tập validation chúng ta chọn chỉ là 1 file cuối trong 100 files ở trên, sinh ra tập ảnh có dung lượng chỉ tầm 2GB, nên chúng ta không cần phải dùng generation cho tập validation. Cách làm như sau:
valid_df = pd.read_csv(os.path.join(DP_DIR, 'train_k{}.csv.gz'.format(NCSVS - 1)), nrows=34000)
x_valid = df_to_image_array_xd(valid_df, size)
y_valid = keras.utils.to_categorical(valid_df.y, num_classes=NCATS)
print(x_valid.shape, y_valid.shape)
print('Validation array memory {:.2f} GB'.format(x_valid.nbytes / 1024.**3 ))
Chúng ta tạo generator cho tập huấn luyện như sau:
train_datagen = image_generator_xd(size=size, batchsize=batchsize, ks=range(NCSVS - 1))
# NCSVS - 1 = 99 (không lấy file cuối cùng vì file đó dùng cho tập validation)
Cuối cùng là phần huấn luyện mô hình:
filepath = 'models/densenet169/accuracy_{val_categorical_accuracy:.10f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='val_categorical_accuracy', verbose=1, save_best_only=True, mode='max')
callbacks = [
ReduceLROnPlateau(monitor='val_categorical_accuracy', factor=0.7, patience=10, mode='max', cooldown=3, verbose=1),
checkpoint
]
model.fit_generator(
train_datagen, steps_per_epoch=STEPS, epochs=EPOCHS, verbose=1,
validation_data=(x_valid, y_valid),
callbacks = callbacks
)
Trong đó:
- checkpoint dùng để lưu giữ các mô hình tốt nhất trong quá trình huấn luyện
- ReduceLROnPlateau() dùng để điều chỉnh learning rate ngay trong quá trình huấn luyện, nhằm mục đích cho mô hình đạt kết quả tốt hơn
- do chúng ta dùng hàm generator để sinh dữ liệu, nên khi huấn luyện, chúng ta phải gọi hàm fit_generator
Kết quả thu được sau 27 epoch như sau:
Epoch 00025: val_categorical_accuracy improved from 0.76794 to 0.76856, saving model to models/densenet169/accuracy_0.7685588236.hdf5
Epoch 26/30
1000/1000 [==============================] - 308s 308ms/step - loss: 0.8504 - categorical_crossentropy: 0.8504 - categorical_accuracy: 0.7772 - val_loss: 0.9234 - val_categorical_crossentropy: 0.9234 - val_categorical_accuracy: 0.7593
Epoch 00026: val_categorical_accuracy did not improve
Epoch 27/30
1000/1000 [==============================] - 308s 308ms/step - loss: 0.8416 - categorical_crossentropy: 0.8416 - categorical_accuracy: 0.7787 - val_loss: 0.8750 - val_categorical_crossentropy: 0.8750 - val_categorical_accuracy: 0.7741
Epoch 00027: val_categorical_accuracy improved from 0.76856 to 0.77412, saving model to models/densenet169/accuracy_0.7741176471.hdf5
Ở cuộc thi này, mỗi models mình training khoảng 300 epochs thì sẽ đạt kết quả tốt nhất.
Một số kỹ thuật bổ sung
Ngoài việc xây dựng một mô hình cơ bản như ở trên, mình còn sử dụng thêm một số kỹ thuật bổ sung như sau:
Sử dụng hình vẽ và batch size lớn
Khi chúng ta sử dụng hình vẽ có kích thước lớn, điều đó đồng nghĩa với việc chúng ta có thể có được nhiều thuộc tính hơn từ hình vẽ đầu vào, từ đó mô hình của chúng ta có thể cho kết quả tốt hơn.
Với việc sử dụng batch size lớn, mô hình sẽ có khả năng lọc những hình vẽ bị gán nhãn sai, và loại bỏ được sự ảnh hưởng của những hình vẽ này đến kết quả học của mô hình.
Learning Rate Schedule
Khi huấn luyện mô hình, chúng ta có thể điều chỉnh tham số learning rate nhằm mục đích làm cho mô hình tiến tới cực tiểu địa phương một cách nhanh hơn và tốt hơn. Thông thường, nếu mô hình không có kết quả thuận lợi sau một vài epochs, chúng ta sẽ giảm learning rate đi 3-5 lần, khi đó bước nhảy của mô hình sẽ nhỏ hơn, và không bị nhảy qua điểm cực tiểu địa phương.
Ngoài cách làm này, chúng ta còn có thể sử dụng phương pháp Snapshot Ensemble. Trong phương pháp này, chúng ta sẽ điều chỉnh learning rate theo hàm cosine với biến số là epoch, sau đó chúng ta sẽ lấy những kết quả tốt nhất thu được từ mô hình này và thực hiện việc ensemble.
Làm sạch dữ liệu
Như đã nhắc đến ở phần xử lý dữ liệu, dữ liệu của chúng ta bao gồm cả những hình vẽ bị gán nhãn sai, số lượng hình vẽ bị gán nhãn sai chiếm khoảng 5% trên toàn bộ dữ liệu. Vì vậy, chúng ta cần phải có phương pháp để loại bỏ những hình vẽ này.
Do số lượng hình vẽ bị gán nhãn sai là tương đối lớn, vì vậy chúng ta không thể lọc bằng tay được. Phương pháp mà chúng ta sử dụng ở đây là như sau: Chúng ta lấy mô hình tốt nhất và thực hiện dự đoán trên tập dữ liệu hình ảnh "unrecognized", với những hình ảnh nào có nhãn dự đoán với độ chính xác lớn hơn 80% hoặc 90%, trong khi hình vẽ đó được gán nhãn khác với nhãn được dự đoán, chúng ta sẽ thực hiện thay thế nhãn ban đầu bằng nhãn được dự đoán này. Kết quả thu được từ việc làm này là tương đối chính xác và có hiệu quả.
Oversampling Data
Do việc dữ liệu không cân bằng, điều này có thể làm cho mô hình có xu hướng dự đoán nghiêng về những lớp có số lượng hình vẽ trong tập huấn luyện lớn hơn, làm giảm độ chính xác của mô hình. Vì vậy, chúng ta cần phải thực hiện tăng số lượng ảnh của những lớp có ít ảnh hơn bằng cách sao chép những hình ảnh này. Việc làm này cũng cho kết quả tốt hơn trong quá trình huấn luyện mô hình.
Đặt trọng số cho lớp và mẫu dữ liệu
Ngoài cách sử dụng Over Sampling cho dữ liệu đầu vào, có một cách khác để xử lý dữ liệu không cân bằng, đó là thực hiện đặt trọng số cho các lớp, những lớp có số lượng ảnh ít sẽ được đặt trọng số cao hơn, khi đó ảnh hưởng của nó đến hàm mất mát cũng cao hơn và mang lại tính công bằng khi huấn luyện giữa các lớp.
Ngoài việc có thể đặt trọng số cho lớp, chúng ta cũng có thể đặt trọng số cho từng mẫu dữ liệu. Trong bài toán này, chúng ta sẽ ứng dụng cách làm này bằng cách đặt trọng số lớn hơn cho những mẫu dữ liệu được gán nhãn đúng, và trọng số nhỏ hơn cho những mẫu dữ liệu. Từ đó ta tăng được mức độ quan trọng của dữ liệu được gán nhãn đúng lên và giảm độ quan trọng của những mẫu dữ liệu bị gán nhãn sai.
Test Time Augmentation
Thông thường, trong quá trình huấn luyện mô hình, chúng ta thường sử dụng một số phương pháp để làm đa dạng dữ liệu huấn luyện như: xoay ảnh, lật ngược ảnh, làm méo ảnh... Nhưng trong bài toán này, do lượng ảnh đầu vào là tương đối lớn, vì vậy chúng ta có thể không sử dụng phương pháp này.
Mặt khác, chúng ta có thể sử dụng nó trong quá trình dự đoán kết quả. Chúng ta có thể dùng mô hình để dự đoán kết quả cho ảnh gốc và ảnh được augmentation, sau đó chúng ta sẽ lấy trung bình. Cách làm này làm cho kết quả dự đoán được trên tập test tăng 0.1%.
Ensemble
Đây là kỹ thuật rất phổ biến trong các cuộc thi về khoa học dữ liệu, bằng cách huấn luyện nhiều mô hình khác nhau, sau đó kết hợp chúng lại với nhau. Phương pháp này cho kết quả tăng hơn 1% trên tập test.
Optimization
Bằng cách sử dụng những kỹ thuật này, chúng ta sẽ đạt được kết quả tốt hơn rất nhiều so với chỉ một mô hình đơn lẻ mà chúng ta đã xây dựng ở phía trên.
Kết quả
Kết quả thu được khi áp dụng một số kỹ thuật ở phía trên và với các mô hình khác nhau như sau:
| model name | Image size | Local CV | LB |
|---|---|---|---|
SE_ResNext50 |
128 | 0.890 | 0.944 |
SE_ResNext101 |
128 | 0.890 | NAN |
SE_ResNet50 |
128 | 0.887 | 0.940 |
ResNet50 |
128 | NAN | 0.941 |
Densenet169 |
128 | 0.886 | 0.938 |
Xception |
128 | NAN | 0.937 |
Densenet121 |
128 | NAN | 0.933 |
Densenet201 |
128 | 0.880 | NAN |
Đây là kết quả training mà team mình thu được, NAN nghĩa là mình quên không lưu giữ lại kết quả của thành phần đó. Kết quả cuối cùng trên bảng xếp hạng và vị trí thứ 5 trên Public Leader Board và vị trí thứ 11 trên Private Leader Board:
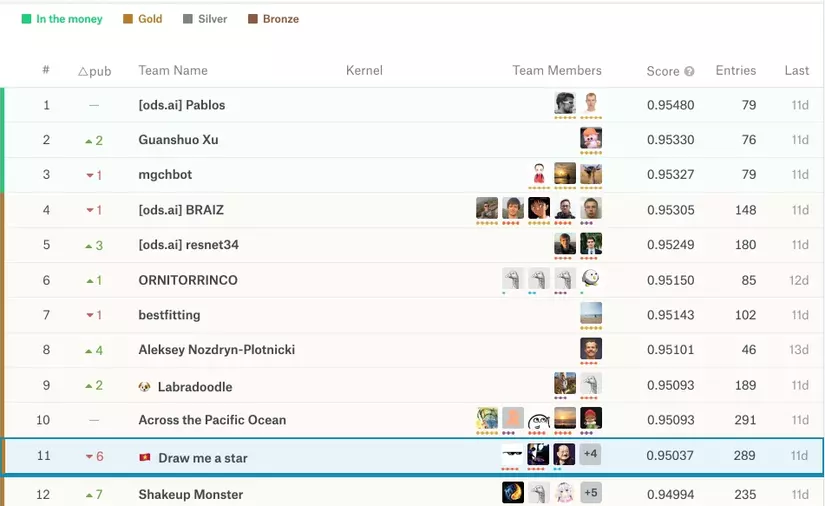
Cám ơn các bạn đã đọc bài viết! Đừng quên upvote nếu cảm thấy bài viết có ích các bạn nhé!
All rights reserved
