Xview2 challenge và bài toán segmentation
Bài đăng này đã không được cập nhật trong 6 năm

Xin chào tất cả mọi người. Như vậy là năm 2020 sắp đến thật rồi ! Chắc hẳn ai ai trong chúng ta cũng đang rất háo hức được trở về nhà, cùng quây quần bên gia đình, bạn bè và người thân, cùng đón một năm mới tràn đầy niềm vui, hạnh phúc và may mắn đúng không  Mình chúc cho các bạn, những độc giả của viblo một năm mới an khang, hạnh phúc và gặp thật nhiều may mắn trong năm 2020.
Mình chúc cho các bạn, những độc giả của viblo một năm mới an khang, hạnh phúc và gặp thật nhiều may mắn trong năm 2020.
Đối với mình, thời điểm cuối năm này cũng là thời điểm thật lý tưởng để tự tổng kết lại những gì mình đã làm được trong năm vừa qua. Và bài viết này mình xin chia sẻ với các bạn về một cuộc thi mà ở đó mình học được rất nhiều điều! Cùng với mình điểm lại những gì mình đã làm, những kiến thức mình đã học được trong cuộc thi này nhé.
Xview2 Challenge
Xview2 là một cuộc thi thường niên, được tổ chức bởi Defense Innovation Unit, một tổ chức quân đội Hoa Kỳ. Cuộc thi này được tổ chức với mục đích tìm kiếm các giải pháp về thị giác máy để giải quyết cho các vấn đề Hỗ trợ nhân đạo và khắc phục thảm họa sau thiên tai. Khi thảm họa xảy ra, thì việc cung cấp được thông tin đánh giá thiệt hại một cách nhanh chóng nhất sẽ rất quan trọng trong việc đưa ra các quyết định hành động hỗ trợ nhân đạo trong khu vực bị ảnh hưởng, từ đó có thể giảm thiểu được tối đa những rủi ro liên quan đến con người, và những yếu tố liên quan. Tuy nhiên, để tiếp cận được khu vực bị thiên tai không hề dễ dàng khi thảm họa có thể tàn phá cơ sở hạ tầng, giao thông, và làm cô lập vùng bị ảnh hưởng.
Để giải quyết vấn đề đó, một giải pháp được nghĩ đến đó là việc sử dụng các hình ảnh vệ tinh được chụp từ trên cao hoặc từ các thiết bị UAV có thể giúp cho các chuyên gia tiếp cận và đánh giá mức độ thiệt hại tại một khu vực nào đó. Nhưng thường thì diện tích bị ảnh hưởng sẽ là cả một khu vực rộng lớn. Việc đánh giá thiệt hại thủ công bởi con người sẽ tốn rất nhiều thời gian. Cho nên thử thách được đặt ra đó là việc với hai hình ảnh đầu vào là hình ảnh trước thảm họa và hình ảnh sau thảm hoạ của các khu vực tương ứng nhau, hãy đào tạo một mô hình có thể phân loại được mức độ thiệt hại của từng ngôi nhà có trong hình ảnh.
Cuộc thi được chia ra làm hai task:
- Task 1: Đào tạo một mô hình có thể xác định được vị trí các building có trong hình ảnh
- Task 2: Đào tạo một mô hình có thể phân loại được mức độ thiệt hại của các building sau thảm họa.
Bộ dữ liệu xBD
Dữ liệu được cung cấp sẽ là một tập hợp các bộ đôi hình ảnh: trước thảm họa và sau thảm họa được chụp tại cùng một vị trí tương ứng nhau. Đối với mỗi bộ đôi hình ảnh, bộ dữ liệu cung cấp các tọa độ polygon đánh dấu vị trí của các tòa nhà nằm trong ảnh. Với hơn 850.000 các căp polygon trước và sau thảm họa được xây dựng từ sáu loại thảm họa tự nhiên khác nhau, thì hình ảnh được cung cấp được chụp ở khắp nơi trên thế giới với diện tích bao phủ là hơn 45.000 km2. Bộ dữ liệu xBD là một trong những bộ dữ liệu miễn phí lớn nhất và chất lượng cao về hình ảnh vệ tinh có độ phân giải cao được chú thích.
Kích thước của mỗi hình ảnh là 1024 * 1024, tương đối lớn, bạn có thể xem qua một cặp hình ảnh có trong bộ dữ liệu này:


Với nhãn của bộ dữ liệu, chúng được chia ra làm hai loại:
- Đối với hình ảnh trước thảm họa: tại những nơi không có building, label sẽ mang giá trị 0 và ngược lại, nơi có building, label cho từng pixel sẽ là 1.
- Đối với hình ảnh sau thảm họa: bởi vì số lượng class được phân loại cho từng pixel sẽ nhiều hơn, cho nên đối với các pixel không thuộc building, chúng được đánh thành 0, và đối với các pixel thuộc những building đã bị phá hủy, thì tùy thuộc vào mức độ nào mà chúng được đánh từ giá trị 1 đến 3, tương ứng cho các mức độ: Tòa nhà không bị phá hủy, Tòa nhà bị hư hại nhẹ, Tòa nhà bị thiệt hại lớn, Tòa nhà bị phá hủy hoàn toàn.
Nhiệm vụ của mình bây giờ là giải quyết hai vấn đề:
- Xác định được nơi nào có building, hoặc những building đã bị phá hủy trong hình ảnh
- Phân loại được mức độ thiệt hại của từng building vừa phát hiện được.
Các bạn hãy cùng mình điểm lại các bước mà mình đã làm để giải quyết hai vấn đề này nhé 
Các bước giải quyết bài toán
Đánh giá bộ dữ liệu
Điều đầu tiên đối với mỗi bài toán computer vision nới riêng, hay bất kỳ bài toán AI nào nói chung, có lẽ các bạn đều đồng ý với mình rằng, việc nhìn nhận, đánh giá dữ liệu đầu vào để từ đó thực hiện các công việc tiền xử lý dữ liệu trước khi đưa vào mô hình sẽ là bước khá là quan trọng đúng không. Vì vậy, mình sẽ nói trước về những gì mình đã làm với bộ dữ liệu xBD này. Nếu các bạn có ý tưởng hay hơn về việc xử lý dữ liệu đầu vào, hãy comment cho bài viết của mình nhé.
Đầu tiên, nhờ các anh trong team hướng dẫn, mình đã thực hiện chia nhỏ hình ảnh đầu vào thành nhiều hình ảnh con. Các bạn còn nhớ, mình đã đề cập đến kích thước hình ảnh đầu vào ở phần trên của bài viết không, kích thước của mỗi hình ảnh là (1024 * 1024), tương đối lớn phải không? Và kích thước hình ảnh lớn như vậy sẽ làm tăng độ phức tạp tính toán khi bạn trainning mô hình, đặc biệt là khi phần cứng máy tính của chúng ta bị giới hạn.
Do đó, mình đã chia hình ảnh lớn thành các hình ảnh con với kích thước là (256 * 256) không overlap lên nhau, và điều đó cũng tương tự cho hình ảnh label tương ứng.


Chọn mô hình đào tạo
Đối với challenge này, mình lựa chọn mô hình mạng UNET để thực hiện track segment building. Lý do mình chọn mô hình này bởi vì cấu trúc của mô hình khá dễ hiểu và đem lại độ chính xác khá cao trong việc segment được các building trong hình ảnh.
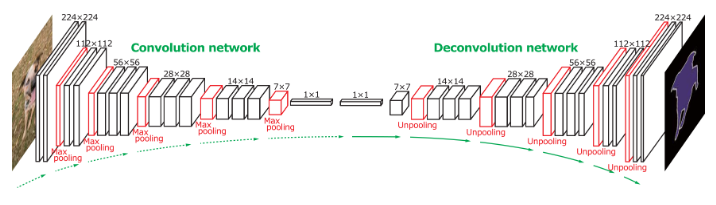
Nói về UNET, mạng này bao gồm hai thành phần là encoder và decoder. Phần encoder tượng tự như các mạng CNN bình thường khác, có tác dụng trích xuất các đặc trưng trừu tượng của hình ảnh đầu vào. Khi càng vào các layer sâu bên trong, thì kích thước của hình ảnh càng trở lên nhỏ, điều đó đồng nghĩa với việc tương đối nhiều thông tin của hình ảnh gốc ban đầu đã bị mất, hình ảnh đến lúc này chỉ giữ các đặc trưng quan trọng. Tuy nhiên, đầu ra được yêu cầu là hình ảnh có cùng kích thước với hình ảnh đầu vào và các building phải được mask một cách chính xác. Để giải quyết vấn đề này, mạng UNET đề xuất một phần được gọi là decoder. Phần mạng này có tác dụng vừa up-scale hình ảnh lên kích thước mong muốn và vừa có mục đích giữ lại được các thông tin đã bị mất khi thực hiện encoder bằng cách sử dụng thông tin của các layer tương ứng trước đó từ mạng encoder. Đây là điều đặc biệt của UNET khi mà chúng ta vừa trích xuất được đặc trưng trừu tượng của hình ảnh và vẫn giữ được các thông tin thể hiện độ chi tiết của hình ảnh ban đầu.
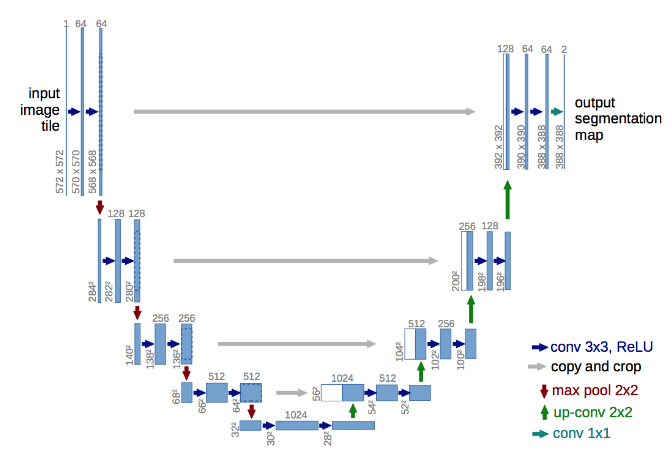
Ở đầu ra của mạng UNET, tại mỗi vị trí pixel, mình thực hiện phân loại nhị phân bởi vì tại mỗi vị trí này, chúng sẽ nhận giá trị 1 cho những pixel thuộc building và 0 cho những pixel ko có building. Loss function mình sử dụng là binary_crossentropy.
Kích thước của hình ảnh đầu ra sẽ là (256 * 256 * 1). Trình optimizer mình sử dụng là Adam với learning_rate = 1e-4. Batch_size = 5 (do máy mình hơi yếu, sẽ tốt hơn nếu có thể tăng giá trị này lên  ). Ngoài ra, do số lượng hình ảnh tương đối lớn, mình có code một trình data_generator để có thể train đến đâu load hình ảnh đến đó. Điều này sẽ cải thiện được tốc độ đào tạo mà không tốn RAM lưu trữ một lượng lớn hình ảnh khi đào tạo. Các bạn có thể tham khảo đoạn code sau nhé:
). Ngoài ra, do số lượng hình ảnh tương đối lớn, mình có code một trình data_generator để có thể train đến đâu load hình ảnh đến đó. Điều này sẽ cải thiện được tốc độ đào tạo mà không tốn RAM lưu trữ một lượng lớn hình ảnh khi đào tạo. Các bạn có thể tham khảo đoạn code sau nhé:
"""
Create model UNet for segment building on image
"""
# import libraries
import os
import json
import numpy as np
import keras
from keras.models import Model
from keras.layers import Conv2D, UpSampling2D, MaxPooling2D, Dropout, Cropping2D, Input, merge
from keras.optimizers import SGD, Adam
from keras.callbacks import ModelCheckpoint, LearningRateScheduler, TensorBoard
from keras import backend as K # want the Keras modules to be compatible
from keras.utils import to_categorical
def UNet(filters_dims, activation='relu', kernel_initializer='glorot_uniform', padding='same'):
"""
Define contruct model UNet
"""
inputs = Input((256, 256, 3))
new_inputs = inputs
conv_layers = []
# encoding phase
print("Construct encoding phase ... ")
for i in range(len(filters_dims) - 1):
print("Stage :", i+1)
print("========================================")
print(new_inputs.shape)
conv = Conv2D(filters_dims[i], 3, activation=activation, padding=padding, kernel_initializer=kernel_initializer)(new_inputs)
print(conv.shape)
conv = Conv2D(filters_dims[i], 3, activation=activation, padding=padding, kernel_initializer=kernel_initializer)(conv)
conv_layers.append(conv)
new_inputs = MaxPooling2D(pool_size=(2, 2))(conv)
print(new_inputs.shape)
# middle phase
print("Construct middle phase ... ")
print("========================================")
conv = Conv2D(filters_dims[-1], 3, activation=activation, padding=padding,
kernel_initializer=kernel_initializer)(new_inputs)
conv = Conv2D(filters_dims[-1], 3, activation=activation, padding=padding,
kernel_initializer=kernel_initializer)(conv)
new_inputs = Dropout(0.5)(conv)
print(new_inputs.shape)
# reverse order for list
filters_dims.reverse()
conv_layers.reverse()
# Decoding Phase
print("Construct decoding phase ... ")
for i in range(1, len(filters_dims)):
print(i)
print("========================================")
print(new_inputs.shape)
up = Conv2D(filters_dims[i], 3, activation=activation, padding=padding,
kernel_initializer=kernel_initializer)(UpSampling2D(size=(2, 2))(new_inputs))
concat = merge([conv_layers[i-1], up], mode='concat', concat_axis=3)
conv = Conv2D(filters_dims[i], 3, activation=activation, padding=padding,
kernel_initializer=kernel_initializer)(concat)
new_inputs = Conv2D(filters_dims[i], 3, activation=activation, padding=padding,
kernel_initializer=kernel_initializer)(conv)
print(new_inputs.shape)
# Ouput layer
outputs = Conv2D(2, 1, activation='sigmoid', padding='same',
kernel_initializer='glorot_uniform')(new_inputs)
print(outputs.shape)
model = Model(input=inputs, output=outputs, name='UNet')
model.compile(optimizer=Adam(lr=1e-4),
loss='binary_crossentropy',
metrics=['accuracy', 'mse'])
return model
"""
Function helper for trainning model segmentations
"""
# import libraries
import cv2 as cv
import numpy as np
import os
from os import walk, path, makedirs
import h5py
from tqdm import tqdm, trange
import sys
import keras
import cv2 as cv
class DataGenerator(keras.utils.Sequence):
"""
Class data generator for model Segment UNet
"""
def __init__(self, train_dataset, labels, batch_size = 1, dim=256, n_channels=3, n_classes=2, shuffle=True):
""" Initialization """
self.dim = dim
self.batch_size = batch_size
self.labels = labels
self.train_dataset = train_dataset
self.n_channels = n_channels
self.n_classes = n_classes
self.shuffle = shuffle
self.on_epoch_end()
def __len__(self):
'Denotes the number of batches per epoch'
return int(np.floor(len(self.train_dataset) / self.batch_size))
def __getitem__(self, index):
'Generate one batch of data'
# Generate indexes of the batch
indexes = self.indexes[index*self.batch_size:(index+1)*self.batch_size]
# Find list of IDs
list_IDs_temp = [self.train_dataset[k] for k in indexes]
list_IDs_label = [self.labels[k] for k in indexes]
# Generate data
X, y = self.__data_generation(list_IDs_temp, list_IDs_label)
return X, y
def on_epoch_end(self):
'Updates indexes after each epoch'
self.indexes = np.arange(len(self.train_dataset))
if self.shuffle == True:
np.random.shuffle(self.indexes)
def __data_generation(self, list_IDs_temp, list_IDs_label):
'Generates data containing batch_size samples' # X : (n_samples, *dim, n_channels)
# Initialization
X = np.empty((self.batch_size, self.dim, self.dim, self.n_channels))
y = np.empty((self.batch_size, self.dim, self.dim))
# Generate data
for i in range(len(list_IDs_temp)):
# Store sample
image = cv.imread(list_IDs_temp[i])
if image is None:
X[i,] = np.zeros((256, 256, 3))
else:
X[i,] = image
for i in range(len(list_IDs_label)):
# Store class
label = cv.imread(list_IDs_label[i])
if label is None:
gray_label = np.zeros((256,256))
else:
gray_label = cv.cvtColor(label, cv.COLOR_BGR2GRAY)
gray_label[gray_label==255] = 1
y[i] = gray_label
return X, keras.utils.to_categorical(y, num_classes=self.n_classes)
def get_files(input_fordel):
"""
Get path image data
"""
disaster = os.listdir(input_fordel)
origin_image_files = []
mask_image_files = []
for disaster_name in disaster:
base_disaster_images_dir = path.join(input_fordel, disaster_name, "images")
base_disaster_mask_images_dir = path.join(input_fordel, disaster_name, "masks")
for f in next(walk(base_disaster_images_dir))[2]:
origin_image_files.append(path.join(base_disaster_images_dir, f))
mask_image_files.append(path.join(base_disaster_mask_images_dir, f))
return origin_image_files, mask_image_files
Đào tạo mô hình
"""
Trainning model Unet for segment building object
"""
# import libraries
import numpy as np
import cv2 as cv
import os
from os import walk, path, makedirs
import json
from keras.callbacks import ModelCheckpoint, LearningRateScheduler, TensorBoard
from utils import get_files, DataGenerator
from UNet import UNet
if __name__ == "__main__":
# create model UNet
unet_config = 'config/unet.json'
print('unet json: {}'.format(os.path.abspath(unet_config)))
with open(unet_config) as json_file:
config = json.load(json_file)
print("Initializing UNet model")
model = UNet(filters_dims=config['filters_dims'],
activation=config['activation'],
kernel_initializer=config['kernel_initializer'],
padding=config['padding'])
model.summary()
training_config = 'config/training.json'
print('training json: {}'.format(os.path.abspath(training_config)))
with open(training_config) as json_file:
config = json.load(json_file)
input_fordel = "/home/tuananh/tuananh/sun/xview2_challenge/datasets/xBD_segment"
image_paths, mask_paths = get_files(input_fordel)
train_image_dataset = image_paths[:30000]
label_train_dataset = mask_paths[:30000]
validation_image_dataset = image_paths[30000:]
label_validation_dataset = mask_paths[30000:]
training_generator = DataGenerator(train_image_dataset, label_train_dataset, batch_size=config["batch_size"])
validation_generator = DataGenerator(validation_image_dataset, label_validation_dataset, batch_size=config["batch_size"])
# saving weights and logging
filepath = 'weights/' + model.name + '.{epoch:02d}-{loss:.2f}.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1,
save_weights_only=True, save_best_only=True, mode='auto', period=1)
tensor_board = TensorBoard(log_dir='logs/')
model.fit_generator(generator=training_generator,
validation_data=validation_generator,
use_multiprocessing=True,
workers=1,
epochs=config["epochs"],
shuffle=True,
verbose=1,
batch_size=config["batch_size"],
initial_epoch=0,
callbacks=[checkpoint, tensor_board])
# # loading data for segment
# print("Loading data ... ")
Sau khi train khoảng 10 epoch, mình thấy mô hình segment building tương đối tốt. Và theo mình đánh giá mô hình Unet dùng cho bài toán segmentattion khá dễ cho việc triển khai và đào tạo mô hình.
Phân loại mức độ thiệt hại cho từng building
Sau khi train được mô hình segment building tương đối ổn, mình chuyển sang tìm cách phân loại mức độ thiệt hại cho các building. Ban đầu, mình nghĩ sẽ thực hiện hai mô hình. Một mô hình segment các building trước, sau đó crop các building đó ra khỏi hình ảnh gốc và cho chúng vào một trình phân loại mức độ thiệt hại. Tuy nhiên, mình có để ý, đầu ra của mô hình UNET có thể custom được bằng cách: tại một vị trí của pixel, không nhất thiết pixel ấy chỉ nhận giá trị là 0 và 1, mà chúng ta có thể gán giá trị từ 0 đến 4 tương ứng với mức độ thiệt hại đã được định nghĩa của challenge. Do đó, mình quyết định custom lại mô hình UNet, với layer đầu ra sẽ sử dụng activation là softmax và loss function là categorical_crossentropy. Các tham số phục vụ cho việc train mình sử dụng tương tự với khi train mô hình UNet thông thường. Và giá trị loss và accuracy của mô hình có xu hướng giảm.
Tuy nhiên, do thời gian có hạn, và do máy của mình khá yếu cho nên mô hình mình submit chỉ cho kết quả là 0.71 cho segment building và 0.25 cho việc phân loại thiệt hại của các building. Tương đối thấp, và có lẽ việc phân loại thiệt hại mô hình chưa học được gì nhiều từ dữ liệu, haizz.
Nhưng dù sao thì mình cũng rất vui khi tham gia challenge này, vì mình đã học được một bài toán mới về segmentation, học được cách suy nghĩ nên làm những gì trước khi tiếp xúc với một bài toán, đánh giá dữ liệu ra sao và đào tạo mô hình thế nào. Em cảm ơn hai anh Phan Huy Hoang và Trung Thành Nguyễn đã hướng dẫn em cách thi challenge này.
Các bạn có thể xem thông tin cuộc thi tại đây.
Cảm ơn các bạn đã đọc đến đây, một lần nữa, năm mới sắp đến rồi, mình xin chúc các bạn một năm mới an khang, hạnh phúc và gặp thật may mắn trong năm 2020. 
All rights reserved
