
Thay đổi cách viết Tiếng Việt - là dân công nghệ thì không phải sợ
Bài đăng này đã không được cập nhật trong 4 năm
Có lẽ trong những ngày gần dây trào lưu viết chữ Tiếng Việt chuẩn đang trở nên vô cùng hot trên mạng xã hội. Mình thì không muốn lạm bàn nhiều về vấn đề thay đổi chữ viết Tiếng Việt đúng hay sai vì bản thân Viblo là một nền tảng để chia sẻ kiến thức kĩ thuật của ngành công nghệ thông tin chứ không phải của ngành xã hội học nên nếu bạn muốn tiếp cận theo hướng của một người làm kĩ thuật thì hãy tiếp tục đọc bài này nhé. Trong bài viết này chúng ta sẽ cùng bài luận về những kĩ thuật lập trình và Xử lý ngôn ngữ tự nhiên cũng như Computer Vision hay Thực tế ảo sẽ trợ giúp chúng ta như thế nào nếu như thực sự đề án Thay đổi chữ Tiếng Việt này được thực hiện. OK chúng ta bắt đầu thôi nào.
Tiếng Việt được thay đổi như thế nào?

Theo đề xuất của tác giả thì Tiếng Việt được thay đổi một số phụ âm đầu như Đ - D, Tr, Ch - C ... các bạn có thể tìm thấy chi tiết như hình sau.

Lúc mới nhìn vào cũng hơi choáng ngợp một chút nhưng là một dân kĩ thuật chúng ta lại thấy việc thay thế này cũng không để mức khó khăn lắm. Chúng ta có thể sử dụng một regex để thay thế các chữ cái này. Dưới đây mình sẽ minh hoa cài đặt bằng Python nhé các bạn.
Đầu tiên các bạn cần phải tạo một mảng regex tương ứng với việc thay thế kí tự cũ bằng kí tự mới. Việc này được khai báo một cách đơn giản trong Python bằng việc tạo một list với phần từ thứ nhất là regex tương ứng cách viết cũ, phần tử thử hai là string thay thế tương ứng. Chúng ta tạo luôn một class để làm việc cho rảnh tay:
import re
class VnConverter(object):
def __init__(self, str):
self.str = str
self.maps = [
['k(h|H)', 'x'],
['K(h|H)', 'X'],
['c(?!(h|H))|q', 'k'],
['C(?!(h|H))|Q', 'K'],
['t(r|R)|c(h|H)', 'c'],
['T(r|R)|C(h|H)', 'C'],
['d|g(i|I)|r', 'z'],
['D|G(i|I)|R', 'Z'],
['g(i|ì|í|ỉ|ĩ|ị|I|Ì|Í|Ỉ|Ĩ|Ị)', r'z\1'],
['G(i|ì|í|ỉ|ĩ|ị|I|Ì|Í|Ỉ|Ĩ|Ị)', r'Z\1'],
['đ', 'd'],
['Đ', 'D'],
['p(h|H)', 'f'],
['P(h|H)', 'F'],
['n(g|G)(h|H)?', 'q'],
['N(g|G)(h|H)?', 'Q'],
['(g|G)(h|H)', 'g'],
['t(h|H)', 'w'],
['T(h|H)', 'W'],
['(n|N)(h|H)', 'n\'']
]
Nếu các bạn lười viết lại thì có thể sử dụng luôn regex của mình cũng được. Tiếp theo chúng ta chỉ cần viết thêm một hàm convert trong class này để chuyển cách viết cũ sang cách viết mới là xong. Hàm này như sau:
def convert(self):
for map in self.maps:
self.str = re.sub(re.compile(map[0]), map[1], self.str)
return self.str
Các bạn có thể chạy thử với đoạn text như sau
if __name__ == '__main__':
str = "Vũ Thị Thanh Thùy"
vnconvert = VnConverter(str=str)
print(vnconvert.convert())
Kết quả cho ra:
Vũ Wị Wan' Wùy
Thử với một số kết quả khác xem sao:
str = "Đảng Cộng sản Việt Nam quang vinh muôn năm"
>>> Dảq Kộq sản Việt Nam kuaq vin' muôn năm
str = "Phạm Văn Toàn sinh ra trong một gia đình nhà nho yêu nước"
>>> Fạm Văn Toàn sin' za coq một za dìn' n'à n'o yêu nướk
OK vậy là chúng ta bước đầu có thể chuyển từ chữ cũ sang chữ mới rồi nhưng một ý tưởng nảy ra trong đầu mình là muốn kiểm tra xem chữ mới này có ưu điểm gì so với chữ cũ không. Không bàn về các luận điểm của giáo sư như sẽ dễ dàng giảng dạy cho người nước ngoài hay số lượng âm thanh được chuẩn hóa theo giọng Hà Nội .... vì mình không phải là nhà ngôn ngữ học. Chỉ có một điều trong số các luận điểm là cách viết mới này tiết kiểm khoảng 10% thời gian và độ dài cho người viết. Mình rất muốn kiểm chứng và cho ra một con số cụ thể xem sao.
Chữ mới ngắn hơn chữ cũ như thế nào
Vì cùng là chữ cái Tiếng Việt nên chúng ta có thể sử dụng hàm len để đo độ dài chữ cũ và chữ mới. Chúng ta sẽ thử một vài trường hợp xem sao
str = "Phạm Văn Toàn sinh ra trong một gia đình nhà nho yêu nước"
str_convert = VnConverter(str=str).convert()
print(len(str))
print(len(str_convert))
>>> 57
>>> 53
str = "Đảng cộng sản Việt Nam quang vinh muôn năm"
str_convert = VnConverter(str=str).convert()
print(len(str))
print(len(str_convert))
>>> 42
>>> 39
Cùng thử với một đoạn văn bản dài hơn nữa nhé
str = "Đảng cộng sản Việt Nam quang vinh muôn năm"
str_convert = VnConverter(str=str).convert()
print(len(str))
print(len(str_convert))
>>> 42
>>> 39
str = "TPHCM là địa phương đầu tiên trong cả nước được Quỹ Nhi đồng Liên Hợp quốc (UNICEF) chọn thực hiện đề án Thành phố thân thiện với trẻ em, đang chờ Trung ương phê duyệt đề án này. Vụ bạo hành kinh hoàng tại lớp mầm non tư thục Mầm Xanh (quận 12) như tạt gáo nước lạnh, khiến lãnh đạo thành phố trăn trở."
str_convert = VnConverter(str=str).convert()
print(len(str))
print(len(str_convert))
>>> 302
>>> 276
Về cơ bản thì chữ mới cho được một cách viết giản lược khoảng 10% so với chữ cũ đúng như giáo sư nói. Tuy nhiên nếu thay đổi theo chữ mới thì sẽ gặp một số vấn đề khó khăn vì tiêu biểu nhất là việc số hóa lại hoàn toàn các sách báo Tiếng Việt. Chính điều này thôi thúc mình nảy ra ý tưởng sẽ viết một tool hỗ trợ chuyển từ các tài liệu sách báo scan sang các tài liệu chữ mới. Chúng ta cùng tìm hiểu thử xem có phương pháp nào làm được điều đó hay không nhé.
Chuyển từ ảnh sang chữ mới
Hãy tưởng tượng xem nếu như bạn có một tấm ảnh của một bài thơ mà muốn chuyển sang cách viết mới thì chẳng còn cách nào khác là ngồi viết lại từng dòng, từng dòng một. Như vậy thì quả thực là quá sức khó khăn. Việc đầu tiên chính là nhận diện các chữ có trong ảnh, rồi bước tiếp theo sẽ sử dụng class bên trên để chuyển nó sang cách viết mới. Bài toán đầu tiên là một bài toán của Computer Vision được gọi là Optical Character Recognition - nhận dạng chữ in. Nếu các bạn đã có kiến thức một chút về Machine Learning thì đây chính là một bài toán classification chúng ta có thể tham khảo nó trong slide sau:
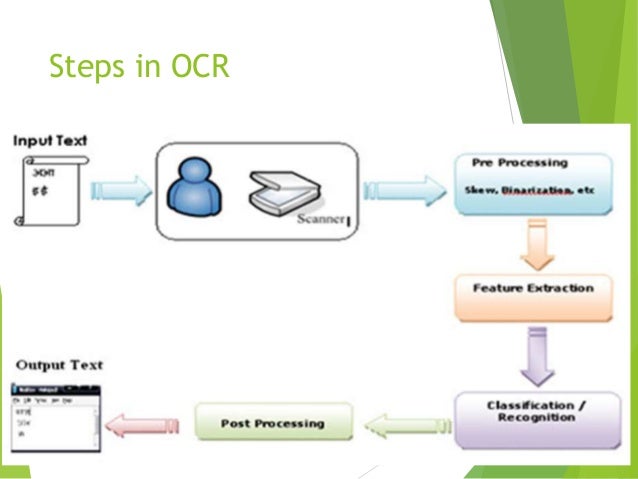
Một bài toán classification cơ bản bao gồm các bước như sau:
- Xử lý dữ liệu đầu vào
- Xây dựng model
- Đánh giá model và sử dụng
Nếu như có dữ liệu training đủ tốt bạn hoàn toàn có thể xây dựng một hệ thống như thế. Tuy nhiên với mục đích để demo ở mức độ sai số chấp nhận được thì có một phần mềm rất phổ biến chúng ta có thể sử dụng đó là Tesseract OCR các bạn có thể tham khảo trực tiếp từ thư viện của Python tại đây

Lúc này bạn có thể chuyển một đoạn văn bản in trên ảnh thành một đoạn text. Để minh họa tôi sử dụng một đoạn code Python như sau.
from PIL import Image
import pytesseract
class OCR(object):
def ocr_from_image(self, imgPath, lang = 'vie'):
return pytesseract.image_to_string(Image.open(imgPath), lang=lang)
Bạn hãy thử với một đoạn văn bản Tiếng Việt được lưu trên bức ảnh. Mình sẽ lấy luôn ví dụ về Luật giáo dục trong bài nghiên cứu của chính Giáo sư. Bức ảnh đó như sau

Tiến hành chạy đoạn code sau với bức ảnh trên:
str = OCR().ocr_from_image(imgPath='tv.png')
print(str)
Sau khi chạy chúng ta sẽ lấy ra được các chữ viết trên bức ảnh này như sau:
[LUẬT GIÁO DỤC Điều 7. Ngôn ngữ dùng trong nhà trường và cơ sở giáo dục khác; dạy và học tiếng nói, chữ viết của dân tộc thiêu sô; dạy ngoại ngữ.....
Vậy là bước nhận dạng chữ từ ảnh đã thành công và không gây khó khăn gì cho chúng ta. Với phần mềm OCR chúng ta hoàn toàn có thể số hóa lại những tài liệu văn bản được in trên giấy hay trên ảnh. Các bạn đừng quá lo lắng về điều đó. Bước cuối cùng chỉ là thực hiện chuyển đổi chữ cũ ở trên ảnh thành chữ mới thôi
str_convert = VnConverter(str=str).convert()
print(str_convert)
Và đây là kết quả
[LUẬT ZÁO ZỤK Diều 7. Qôn qữ zùq coq n'à cườq và kơ sở záo zụk xák; zạy và họk tiếq nói, cữ viết kủa zân tộk wiêu sô; zạy qoại qữ.
Không quá khó khăn phải không các bạn
Chuyển đổi ngược từ chữ mới về chữ cũ
Việc chuyển đổi ngược lại từ chữ mới về chữ cũ không đơn giản như chúng ta nghĩ. Hiểu theo cách của toán học thì việc biến đổi chữ cũ thành chữ mới giống như một ánh xạ từ một không gian gốc với số chiều lớn hơn về một không gian mới có số chiều nhỏ hơn nên rõ ràng là không thể sử dụng một hàm tuyến tính áp dụng cho từng từ giống như các bước chuyển đổi phía trên. Chúng ta cần phải thêm vào một số thông tin khác để hệ thống có thể học được tương tự như một số tập luật. Một mô hình Deep Learning có thể được sử dụng để học các tham số này. Nó tương đương với một bài toán Machine Translation mà một mô hình nổi tiếng để làm việc này đó chính là LSTM

Vấn đề này khá dài nên mình xin phép được đề cập đến trong một bài khác.
Đừng sợ thay đổi
Như các bạn thấy đấy. Đứng trước một sự thay đổi chúng ta nên nhìn nhận nó theo các cách khác nhau và luôn có những cách nào đó để có thể giải quyết nó. Từ một vấn đề thay đổi này chúng ta có thể thực hiện nhiều dịch vụ phục vụ cho đời sống hơn và cũng làm tăng cơ hội phát triển cho chúng ta hơn. Vậy nên có một điều mình muốn chia sẻ sau cùng là Là một người nắm trong tay công nghệ, bạn đừng ngại thay đổi điều gì cả. Xin tạm dừng ở đây và hẹn gặp lại các bạn trong những bài viết sau.
All rights reserved
