
[Paper Explain] TOOD: Thống nhất Classification và Localization cho Object Detection
Bài đăng này đã không được cập nhật trong 3 năm
Tại sao lại là TOOD?
- Vì trong paper này có một phần mà các paper về Object Detection hiện nay áp dụng khá nhiều, tiêu biểu là YOLOv6 hay DAMO-YOLO mới ra gần đây.
- Cách giải quyết vấn đề dễ hiểu, trực quan, kèm theo chứng minh về mặt hình ảnh rõ ràng
- Author thân thiện :v
Task conflict, Task misalignment
Trong Object Detection (OD), ta phải làm 2 nhiệm vụ: Xác định vật thể nằm ở đâu trong ảnh (Localization, Regression) và phân loại xem vật thể đó là vật thể gì (Classification). Vì vậy, bài toán OD là một bài toán Multi-task learning (làm nhiều việc cùng một lúc). Một model OD thì gồm 2-3 phần: Backbone, Neck (có thể có hoặc không) và Head. Phần Backbone dùng để lấy ra các đặc trưng của ảnh, phần Head thì sẽ sử dụng các đặc trưng đó để làm 2 nhiệm vụ đã nói ở trên.
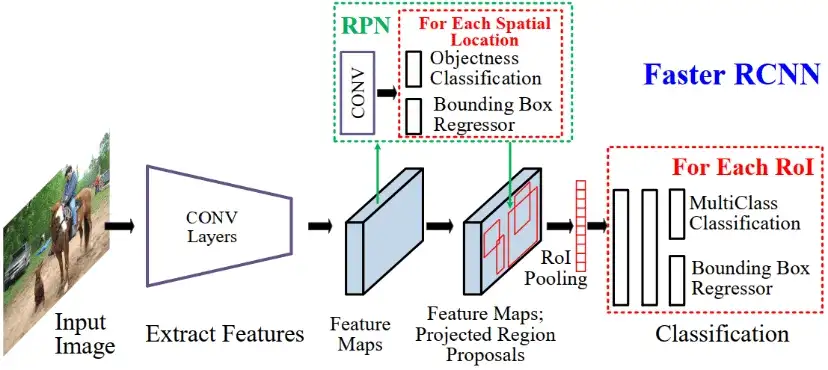
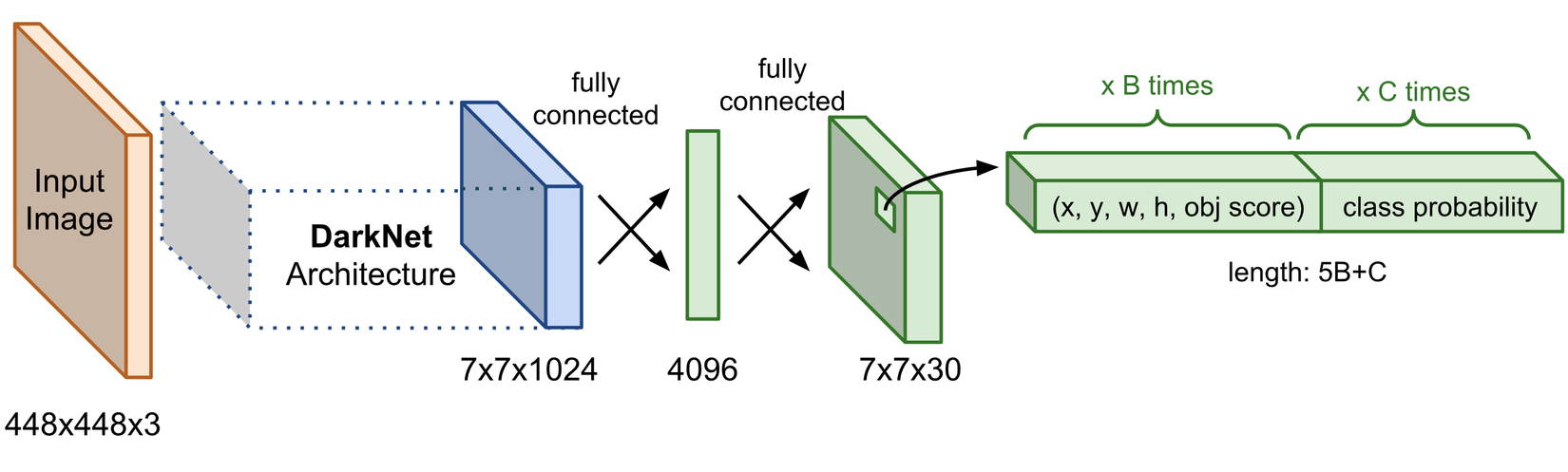
Ở những model OD thế hệ cũ (Faster R-CNN, YOLO, yada yada), thì việc Localization và Classification được thực hiện trên cùng một nhánh của Head (Hình 1). Điều này thì có gì không tốt? Như ta đã biết, một model OD phải làm 2 việc cùng một lúc: Localization và Classification. Tuy nhiên, tính chất của 2 việc này lại khá là khác nhau. Classification thì cần sử dụng những features mang tính biểu hiện cho sự vật nào đó mạnh mẽ (discriminative features) còn Localization thì lại cần sử dụng những features mang tính hiểu được sự vật đó có giới hạn, kích cỡ như nào (thường tập trung vào vùng bao quanh sự vật - boundary region) (Hình 2)
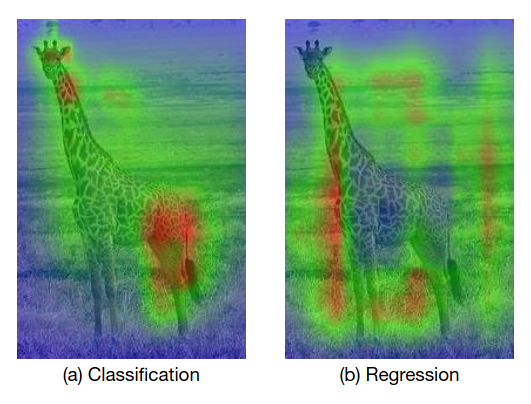
Sự khác nhau trong features của task như trên gọi là task conflict.
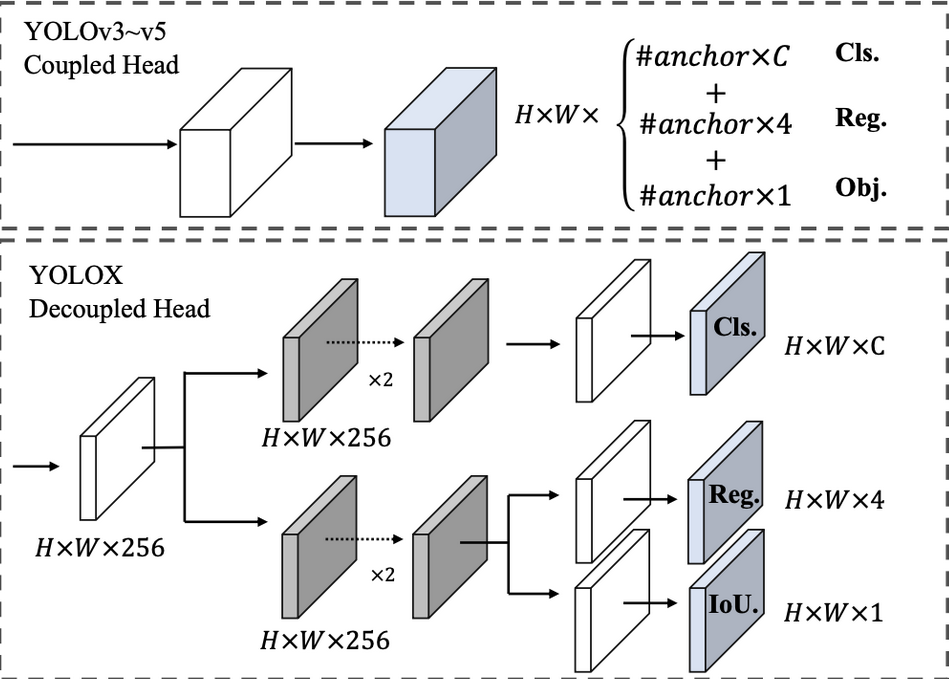
Vì vậy, ta cần phải tách biệt 2 task này với nhau trong Head của model. Và YOLOX (Hình 3) đã làm được điều đó. Head lúc này sẽ có nhiều nhánh, thay vì chỉ một nhánh, và mỗi nhánh sẽ chịu trách nhiệm cho một task khác nhau.
Thế còn gì băn khoăn nữa, tách thành 2 nhánh cho 2 task khác nhau trong head, quá đơn giản. Tuy nhiên, với việc tách ra như này thì khi model thực hiện predict, kết quả giữa 2 task sẽ không thật sự thống nhất (Hình 4). Hiện tượng này gọi là task misalignment
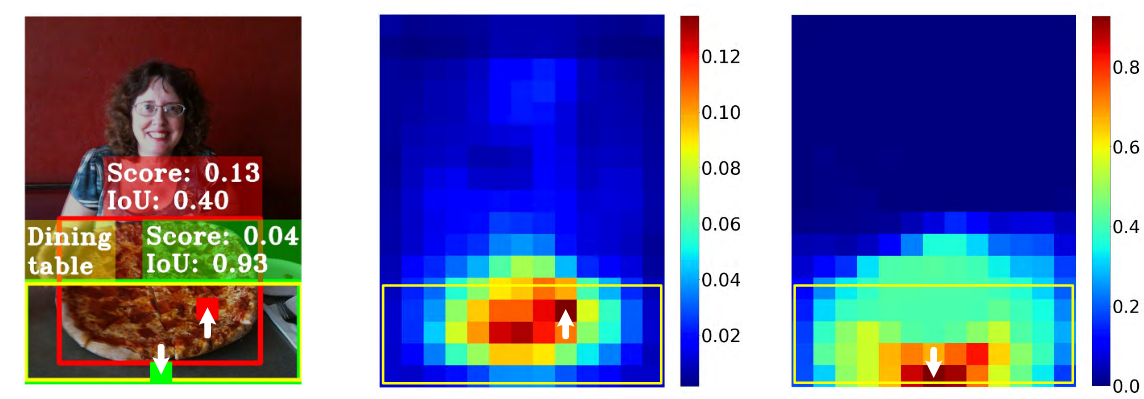
Ta đã hiểu việc không thống nhất giữa 2 tasks sẽ có ảnh hưởng như nào rồi, thế nguyên nhân của sự không thống nhất này là gì? Có 2 nguyên do:
- Không có sự tương tác giữa 2 tasks. Việc tách 2 nhánh trong Head để học các task phân biệt giúp tránh được task conflict, nhưng trớ trêu là nó lại làm giảm tương tác giữa 2 tasks với nhau.
- Label Assignment (LA) không quan tâm đến task. Hầu hết các chiến lược LA sử dụng các luật như: IoU cao (YOLO, RetinaNet,...) hay gần tâm của object (FCOS, ATSS,...). Tuy nhiên, như đã thấy ở Hình 4, những điểm có IoU cao thì chưa chắc ở đó Classification score đã cao, hay những điểm có IoU cao thì lại không hề gần tâm của object. LA hiện đại như OTA đã, không biết vô tình hay cố ý, có một chút sự tương tác giữa các task khi thực hiện assignment. Nhớ lại để OTA chọn được positive anchor giữa các anchor, thì cost phải đạt được giá trị như nào đó. Và cost trong OTA là tổng có trọng số của Classification Loss và Localization Loss (). Chi tiết về OTA các bạn có thể đọc ở đây.
Với 2 nguyên do trên, TOOD đề xuất luôn cách xử lý bao trọn cả 2 nguyên do đó: một liên quan đến kiến trúc của Head, và một liên quan đến Label Assignment.
Task-aligned Head
Ta sẽ thiết kế một Head để model có thể thống nhất 2 task này với nhau (task align) nhưng đồng thời vẫn phải giữ cho chúng không xảy ra hiện tượng task conflict. Task-aligned Head (T-Head) làm điều này thông qua 2 bước: align ở mức features, và align ở mức prediction. Thay vì tách thẳng thành 2 nhánh từ ban đầu để tránh task conflict, T-Head cho chúng 1 nhánh trước, để lấy sự tương tác giữa 2 task với nhau, rồi sau đó mới tách thành 2 nhánh (nghe tới đây thì có vẻ bất hợp lý vì 1 nhánh phần đầu sẽ gây ra task conflict, lúc sau mới tách thì có muộn không? Đọc tiếp các bạn sẽ rõ được tại sao lúc sau T-Head vẫn có thể tránh được task conflict).
Phần 1 nhánh lúc đầu sẽ dùng để 2 task tương tác vs nhau, gọi là task interactive features. Gọi là output features của FPN, ta tạo ra lớp Conv liên tiếp nhau để học task interactive features :
với là output task interactive features ở Conv layer thứ trong số Conv layers. là Conv layer thứ , là ReLU activation. Trong TOOD, để cho có cùng số Parameters với các models 2 nhánh khác.
Task-aligned predictor
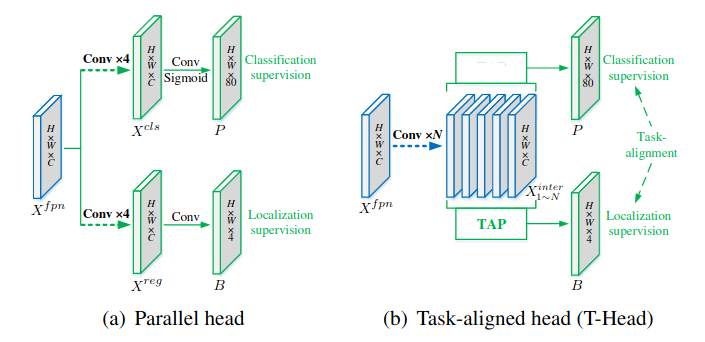
Như đã nói ở trên, kiến trúc 1 nhánh sẽ gây ra hiện tượng task conflict. Và giờ ta phải tách features của từng task ra một cách hợp lý. Hợp lý là như nào? Nếu tách như thông thường, áp dụng một loạt các Conv layers nữa thì khác gì các Head của model khác đâu. Lúc này, ta sẽ sử dụng kĩ thuật Attention để model tự chọn các features cần thiết cho các task (các bạn có thể đọc bài này để có cái nhìn chi tiết hơn về kĩ thuật Attention, một kĩ thuật cực kì quan trọng). Ở phía trên, ta đã có được task interactive features với là số Conv layers để học task interactive features. Ta sẽ thực hiện Layer Attention để phân task interactive features ở layer thứ : về với task phù hợp cho nó. Ủa thế thì mất đi sự tương tác giữa 2 task rồi còn đâu, lại task nào về nhà của task đấy? Đúng nếu sử dụng một ngưỡng cứng để phân thì có vẻ là chả khác gì như ban đầu, nhưng ta sử dụng ngưỡng mềm, tức là 0.7 có thể về task Classification, và 0.3 có thể về task Localization. Features thu được sau khi đi qua Layer Attention gọi là Task specific features.
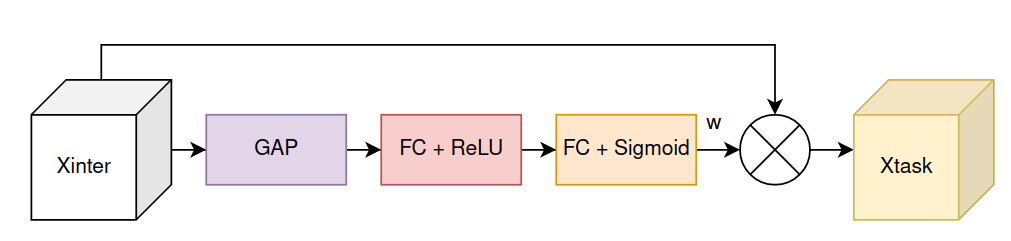
Quá trình Layer Attention được thực hiện như sau (Hình 6):
Với là attention weight cho task interactive features được lấy từ . được tạo ra như sau:
Với là sau khi thực hiện Global Average Pooling (GAP), là 2 lớp Fully Connected (FC), là ReLU activation và là sigmoid activation. Quá trình tính được thể hiện trên Hình 6. Quá trình tính Layer Attention gần như y hệt với cách tính Channel Attention của Squeeze and Excitation, chỉ khác là số neurons trong không bằng số channel của mà bằng . Mình đã có hỏi tác giả rằng tại sao lại sử dụng Layer Attention thay vì Channel Attention của Squeeze and Excitation, thì tác giả nói rằng chúng có chung một mục đích, tuy nhiên Layer Attention lại nhẹ hơn khá nhiều và tác giả cũng nghĩ rằng như thế là đủ tốt rồi.
Rồi sau đó tiền prediction (ngay trước khi đưa ra prediction) của task tương ứng sẽ được thực hiện tính với :
Với là concatenation của các , là Conv để giảm chiều channels của cái feature maps được concatenate lại, là ReLU activation, là Conv với số channel tương ứng của task và là function ứng với task của nó: sigmoid với nhánh Classification và distance -> box với nhánh Localization.
Prediction alignment
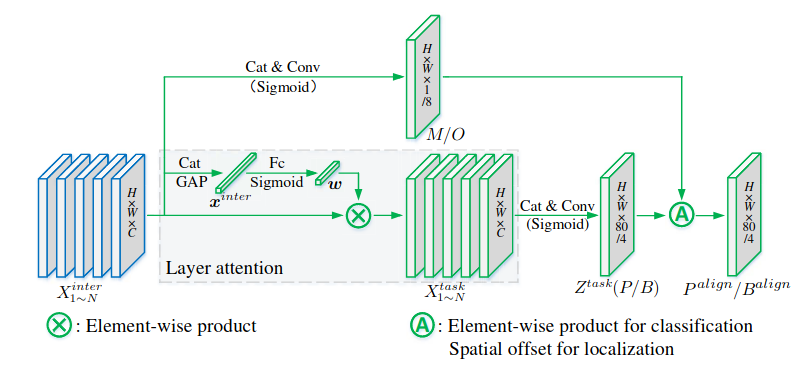
Nếu chỉ dừng lại ở bên trên, thì đã đủ để làm một cái Head có vẻ chất lượng rồi, prediction ổn áp các kiểu r. Cơ mà có lý do bên trên mới chỉ là tiền prediction . Sau đó, tác giả tiếp tục đưa thêm sự tương tác giữa 2 task trong quá trình prediction để 2 tasks align hơn nữa. Trong các model khác, ta có một nhánh phụ được sinh ra từ nhánh Localization, gọi chung là LQE (Localization quality estimation): ví dụ như Centerness của FCOS, IoU Score của ATSS, Objectness Score của YOLOX,... Nhược điểm của chúng là ta chỉ có thể align task Classification dựa trên features của task Localization trong quá trình inference. GFL (nếu chưa rõ về GFL, các bạn có thể đọc ở đây) đã nhận thấy điều này là hơi bất hợp lý, và đã có thể align chúng cả trong quá trình training. Tuy nhiên, nó vẫn chỉ là align 1 phía (Classification nhận features từ Localization). TOOD thực hiện align 2 phía (Hình 7).
Gọi tiền prediction của nhánh Classification là , tiền prediction của nhánh Localization là . Ta sẽ thực hiện alignment với cả 2 nhánh. Xét nhánh Classification, ta sẽ sinh ra spatial probability map để align classification prediction trên từng điểm không gian của feature maps như sau:
được tính từ task interactive features như sau:
với là Conv, là ReLU activation, là Conv với output channel là 1, là sigmoid activation.
Tiếp theo đó, để align nhánh Localization, ta thực hiện học spatial offset map (8 là 2 lần 4, tức là mỗi giá trị của Bounding Box sẽ được điều chỉnh theo 2 chiều ) để điều chỉnh prediction Bounding Box tại mỗi địa điểm trên feature maps như sau:
Đây chính là một phép Spatial Attention đặc biệt, bản chất spatial offset map mà ta học được chính là học offset map của Deformable Convolution, và quá trình tạo ra chính là quá trình thực hiện phép Deformable Convolution với input feature maps và offset . Nếu chưa rõ về cách Deformable Convolution hoạt động, các bạn có thể đọc ở đây.
Tương tự, cũng được tính từ task interactive features :
Task Alignment Learning (TAL)
TOOD tạo ra TAL để tăng cường khả năng alignment của model thông qua 2 quá trình: Label Assignment (LA) và tính Loss.
Task-aligned Sample Assignment
Xét Classification Score và IoU Score chính là 2 nhân tố để đánh giá chất lượng của prediction, ta sẽ đo độ align giữa 2 task sử dụng một chỉ số kết hợp giữa Classification Score va IoU Score như sau:
với và lần lượt là Classification Score và IoU Score, 2 hyper-parameter và dùng để điều chỉnh trọng số giữa 2 nhân tố. lúc này gọi là alignment metric
Để tăng cường sự align trong quá trình LA, ta sẽ tìm cách để sử dụng alignment metric . Chiến thuật LA của TOOD cực kì đơn giản: với mỗi object trong ảnh, ta sẽ chọn anchors có giá trị cao nhất làm positive samples, còn lại là negative. Nó cũng na ná SimOTA của YOLOX. SimOTA của YOLOX thì chọn anchors có giá trị foreground cost thấp nhất. Tuy nhiên, trong SimOTA được chọn theo thuật toán Dynamic-k, chứ không phải chọn tay như trong TAL của TOOD :v
Task-aligned Loss
Không chỉ dừng lại ở việc sử dụng alignment metric trong LA, tác giả còn "to infinity and beyond", sử dụng cả alignment metric trong cả Loss. Classification Loss. Thông thường, Classification sử dụng BCE làm Loss, tức là lúc này, target cho BCE Loss chỉ có hoặc . Tuy nhiên, để align Classification theo Localization thì ta sẽ tìm cách đưa alignment metric nói trên vào Classification Loss. Tuy nhiên, và (Classification Score và IoU Score) là 2 giá trị luôn , nên khi và lớn thì sẽ trở nên cực cực nhỏ, và lúc này, Classification Loss với target như vậy sẽ khiến model khó hội tụ. Vì vậy, ta sử dụng normalized là làm target. sẽ được xác định như nào? Khi prediction, ta biết là sẽ có nhiều vị trí trên feature maps đưa ra prediction cho một object, và mỗi vị trí sẽ sinh ra một Bounding Box (BBox), và ứng với nó chính là IoU Score của BBox đó. Thì lúc này sẽ được chọn là giá trị IoU Score cao nhất trong số toàn bộ các IoU Score từ prediction. Classification Loss được định nghĩa như sau:
Classification Loss gồm 2 phần, phần đầu là cho Positive anchor, phần sau là Negative anchor. là số lượng positive anchor, là số lượng negative anchors, là predicted Classification Score, là IoU Score lớn nhất trong số các BBox được predict ra với GT Box, là hệ số cân bằng. Nhìn thì có vẻ khủng bố nhưng thực chất nó chính là Quality Focal Loss được lấy từ Generalized Focal Loss. Chi tiết về Quality Focal Loss các bạn có thể đọc ở đây: https://viblo.asia/p/paper-explain-generalized-focal-loss-learning-qualified-and-distributed-bounding-boxes-for-dense-object-detection-bWrZnAwmKxw#_quality-focal-loss-qfl-5
Localization Loss. Một Box được predict tốt thì sẽ có Classification Score cao và IoU cũng cao, hay cao. Hơn nữa, việc học từ một BBox có chất lượng cao như vậy thì sẽ lợi cho model hơn là học từ BBox có chất lượng thấp BBox có chất lượng cao và BBox có chất lượng thấp sẽ không nên được đánh giá ngang bằng với nhau trong quá trình training Sử dụng làm hệ số cho Localization Loss. Cụ thể, Localization Loss được tính như sau:
Với và lần lượt là ground truth và predicted BBox. là GIoU Loss
Kết quả

Reference
TOOD: Task-aligned One-stage Object Detection: https://arxiv.org/abs/2108.07755
All rights reserved
