
[Paper Explain] YOLOF: Lời tạm biệt cho multi-scale features trong Object Detection?
Bài đăng này đã không được cập nhật trong 3 năm
Ôn lại kiến thức
Multi-scale features là gì và tại sao chúng lại cần thiết cho Object Detection?
Lấy ví dụ về một mạng Object Detection khá phổ biến: YOLO. Như đã biết, điểm yếu của YOLO hồi mới ra mắt đó chính là khả năng phát hiện vật thể nhỏ cực kì kém. Đó là vì YOLO đã không tận dụng được Multi-scale features. YOLOv1 thực hiện đưa ra kết quả dự đoán Bounding Box (BBox) và Class dựa trên feature maps cuối từ backbone có kích cỡ là . Nếu chưa rõ YOLOv1, các bạn có thể xem lại ở đây.
là một kích cỡ quá nhỏ, các bạn có thể tưởng tượng như là tấm ảnh đưa vào model sẽ được chia ra làm cell (ô vuông), và ta sẽ phải nhìn vào một cell đó, đoán xem trong cell đó có Object gì, BBox của nó là gì. Và với một cell có kích cỡ quá lớn như vậy, thì vật thể nhỏ sẽ chiếm một phần cực nhỏ trong cell đó, và đương nhiên vật thể to sẽ dễ phát hiện hơn.
Vì vậy, để dễ phát hiện vật thể nhỏ hơn, thì ta chỉ cần chia ảnh thành nhiều cell hơn, mỗi cell có kích cỡ bé hơn. Nhưng như thế lại gây ra khó khăn cho việc phát hiện vật thể to. Vì một cái vùng nhỏ như thế, thì đâu chứa được vật thể to, model sẽ gặp khó khăn trong việc phát hiện ra vật thể to và vẽ BBox cho nó.
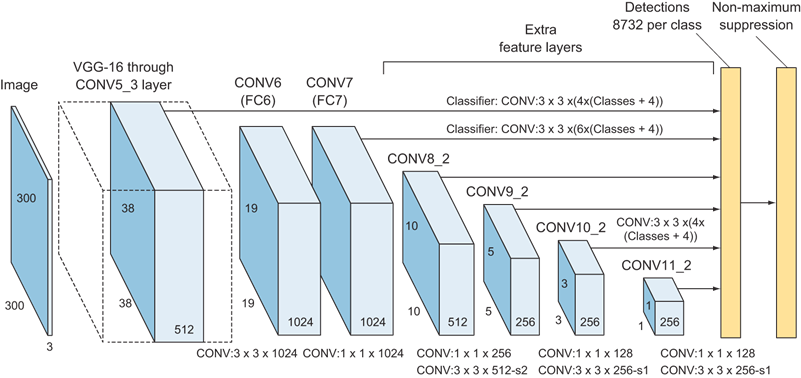
Để phát hiện được vật thể đa dạng kích cỡ, đơn giản là ta chỉ cần nhiều lần chia ảnh, mỗi lần sẽ phục vụ cho object ở kích cỡ khác nhau, dễ không? Đúng dễ, SSD là một model có tưởng như thế (Hình 1). Việc sử dụng nhiều kích cỡ features như vậy để thực hiện dự đoán là sử dụng multi-scale features. Nhưng điểm gì khiến cho SSD vẫn yếu đối với việc phát hiện object nhỏ? Đó là vì feature maps ở những lớp nông, có kích cỡ lớn, thì lại tương đối yếu, và không tốt cho việc dự đoán BBox cũng như phân loại object là Class nào.
Feature Pyramid Network (FPN)
Để giải quyết vấn đề detect các object với nhiều kích cỡ khác nhau, FPN ra đời (Hình 2).
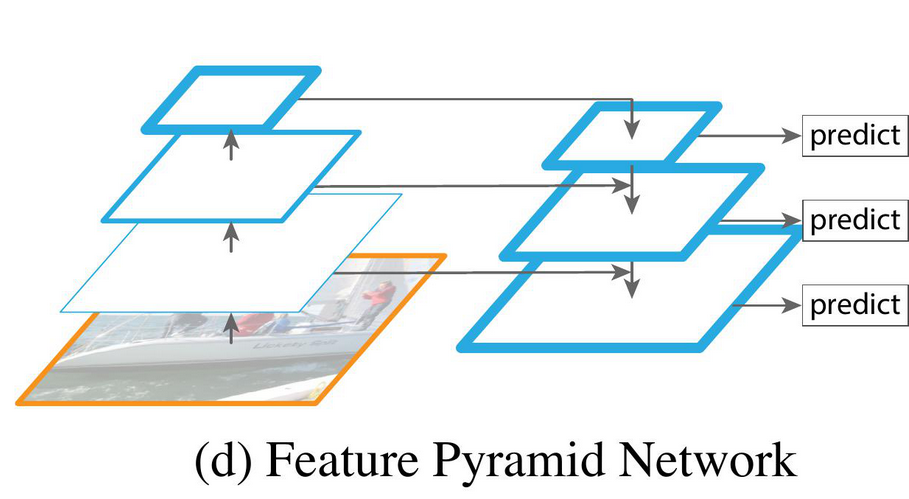
VÌ các feature maps ở lớp nông khá là yếu, nhưng lại cần thiết để predict object nhỏ, nên để tăng cường sức mạnh cho các feature maps ở lớp nông, ta thêm các feature từ các lớp sâu vào (Hình 2). Các feature maps có kích cỡ nhỏ thì sẽ chịu trách nhiệm cho việc predict vật to, các feature maps có kích cỡ to thì sẽ chịu trách cho việc predict vật nhỏ. Trong Object Detection, ta thường sử dụng các feature maps có kích cỡ so với kích cỡ ảnh đầu vào. Mình sẽ gọi nó tắt là scale , scale và scale nhé.
Như vậy, FPN đã thực hiện 2 việc:
- Multi-scale feature fusion (Kết hợp multi-scale features): Các features ở lớp sâu được biến đổi nhẹ và đưa ngược lại vào lớp nông.
- Divide-and-conquer (Chia để trị): Các object có kích cỡ khác nhau sẽ được phân vào scale tương ứng và thực hiện detect trên scale đó.
Hầu hết mọi người đều nghĩ rằng FPN tốt là do Multi-scale feature fusion, và cũng có rất nhiều hướng nghiên cứu tập trung vào việc cải thiện kết hợp features từ các scale khác nhau như nào. Mọi người hoàn toàn bỏ qua quá trình Divide-and-conquer. Và bài phân tích này (YOLOF), sẽ tập trung vào thứ mà mọi người đã bỏ qua: Chia để trị.
Trình bày vấn đề
Ta sẽ phải tìm hiểu xem từng phần của FPN có ảnh hưởng thế nào tới performance của một model. Ta sẽ gọi FPN là một encoder MiMo (Multiple-in-Multiple-out), encode mutli-scale features từ backbone và cung cấp features cho Head. Ta sẽ thực hiện thí nghiệm với MiMo, SiMo (Single-in-Multiple-out), MiSo (Multiple-in-Single-out), SiSo (Single-in-Single-out), cụ thể hơn ở Hình 3.
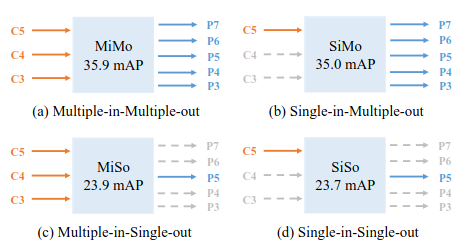
Đáng ngạc nhiên là, với SiMo encoder, chỉ dùng một scale feature từ scale cuối của backbone đạt được kết quả khá là cao so với MiMo encoder ( vs ). Còn khi sử dụng MiSo, thì kết quả giảm cực kì nhiều. Và từ MiSo chuyển sang SiSo thì lại không giảm nhiều đến thế. Hiện tượng này cho ta thấy rằng:
- Feature từ scale cuối của backbone đã mang khá là đủ thông tin để phát hiện object ở các scale khác nhau.
- Multi-scale feature fusion thì mang lại lợi ích ít hơn rất nhiều so với Divide-and-conquer
Ta có thể thấy Divide-and-conquer là một nhân tố quan trọng của FPN. Tuy nhiên, nó lại tốn nhiều bộ nhớ và làm model của ta chậm đi.
Vì thế, YOLOF: You Only Look One-level Feature ra đời.
Phân tích cost của MiMo encoder
Như đã nói ở phần trên, hiệu quả của FPN chủ yếu tới từ việc Divide-and-Conquer. Tuy nhiên, sử dụng nhiều scale sẽ khiến model của ta phức tạp hơn, và chạy chậm hơn. Ta sẽ xem xét việc MiMo encoder ảnh hưởng như nào tới tốc độ của model.
Thí nghiệm sử dụng RetinaNet với backbone là ResNet-50, hy vọng là mọi người đọc bài viết này đều đã biết ResNet và RetinaNet, còn không biết thì nên tìm hiểu đi nha. Ta sẽ chia một model Object Detection làm 3 phần: Backbone, Encoder và Decoder, hay dễ hiểu hơn thì là Backbone, Neck và Head đó. GFLOPs của từng phần sẽ được để ở Hình 4.
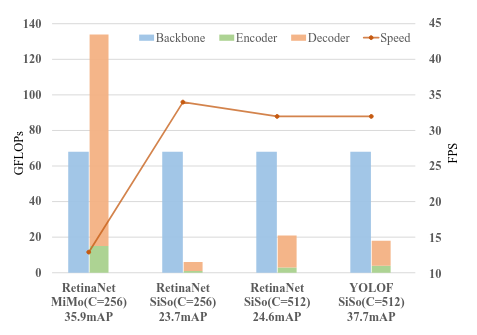
Nhìn vào Hình 4, ta có thể thấy MiMo encoder chậm hơn rất nhiều so với SiSo encoder. Việc chậm này là do thời gian xử lý của feature maps có kích cỡ lớn (tại scale )
YOLOF
Như đã bàn ở trên thì feature ở scale dường như đã mang đủ thông tin để thực hiện predict. Tuy nhiên, khi tạo ra SiSo encoder thì hiệu năng model lại tụt dốc không phanh. Ta phải thiết kế SiSo hiệu quả để hiệu năng gần tương xứng với MiMo encoder. Có 2 vấn đề khiến cho SiSo encoder tụt dốc về hiệu năng:
- Khoảng scale mà nằm trong receptive field của feature maps cuối từ backbone là khá hạn chế
- Vấn đề imbalance giữa các anchors ở trong một scale
Limited Scale Range
Phát hiện object ở nhiều scale khác nhau là một vấn đề khó trong Object Detection. Một giải pháp đó chính là tận dụng multi-scale features. Với những model sử dụng encoder dạng MiMo hay SiMo, ta tạo ra multi-level features với các receptive field khác nhau phù hợp với scale của chúng. Nếu các bạn chưa rõ về receptive field thì có thể đọc ở đây. Tuy nhiên, trong encoder dạng SiSo thì ta chỉ có một scale cho output thôi, và lúc này receptive field tại scale này là cố định. Như đã thấy ở Hình 5a, receptive field của feature maps từ scale cuối của backbone () sẽ chỉ cover trong một khoảng giới hạn, do đó nếu gặp object mà có scale không phù hợp thì sẽ toang. Do đó, ta phải tìm cách cải thiện receptive field tại đây.
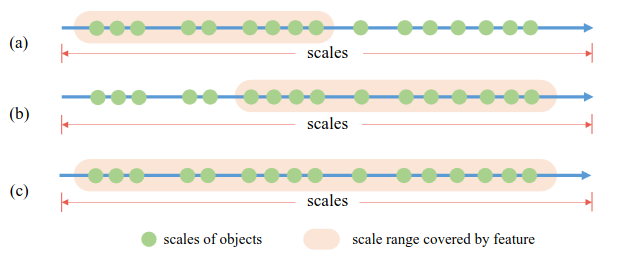
Nhóm tác giả thử mở rộng receptive field thông qua Diliated Convolution. Mặc dù dải scale được cover lúc này đã lớn hơn so với ban đầu, nhưng nó vẫn không cover đầy đủ các scales (Hình 5b), vì việc mở rộng receptive field này đã được nhân với hệ số lớn hơn . Ờ thì bây giờ thiếu một phần mà đã từng cover được chỗ scale bị thiếu thì sao? Cộng vào thôi :v Hay nói cách khác là áp dụng Residual Connection (Skip Connection) đó.
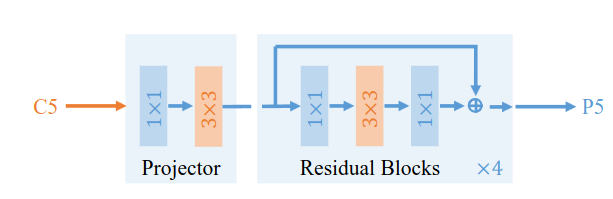
Dựa trên những thiết kế vừa đưa ra phía trên, Dilated Encoder được tạo ra (Hình 6). Dilated Encoder gồm 2 phần: Projector và Residual Block. Phần Projector dùng Conv để giảm chiều channel xuống, và sử dụng Conv để tăng cường semantic features. Sau đó là các Residual Block với các mức dilation khác nhau để có thể cover được nhiều scale.
Imbalance Problem on Positive Anchors
Việc định nghĩa thế nào là một positive anchor là một bài toán quan trọng trong Object Detection (Label Assignment). Trong RetinaNet, một loại anchor-based, nếu IoU của một anchor và ground-truth (gt) Box lớn hơn thì anchor đó sẽ được đặt làm positive anchor. Ta gọi đó là Max-IoU matching. Nếu chưa rõ về Label Assignment trong Object Detection, các bạn có thể đọc ở đây.
Trong MiMo encoder, anchors được định nghĩa sẵn ở trên từng scale, và được tạo ra cực kì dày đặc. Với cơ chế Divide-and-conquer, Max-IoU matching sẽ tạo ra đủ số lượng anchor ở trên từng scale. Tuy nhiên, nếu sử dụng SiSo encoder, số lượng anchors bị giảm đi một cách rõ rệt. Việc này gây khó khăn cho Max-IoU matching (Hình 6). Những gt Box lớn sẽ tạo ra nhiều positive anchor và những gt Box nhỏ sẽ tạo ra ít positive anchors hơn (vì thỏa mãn tiêu chuẩn IoU của gt Box lớn dễ hơn rất nhiều so với Box nhỏ), tạo ra vấn đề imbalance, khiến model của ta bị áp đảo bởi Box lớn và ít chú ý tới Box nhỏ trong training.
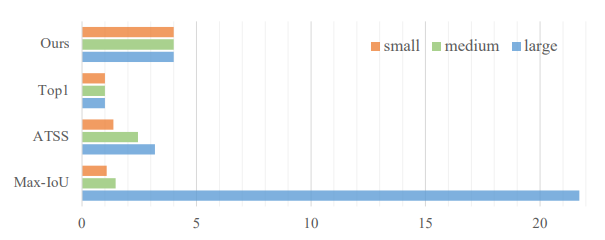
Uniform Matching: Để giải quyết vấn đề imbalance vừa nói, nhóm tác giả YOLOF tạo ra Uniform Matching: Sử dụng anchors gần nhất với một ground truth và đặt làm positive anchor hết Dù là object nào thì cũng sẽ có positive anchor.
Kiến trúc
Với những kiến thức vừa nói ở trên, YOLOF có kiến trúc như ở Hình 7
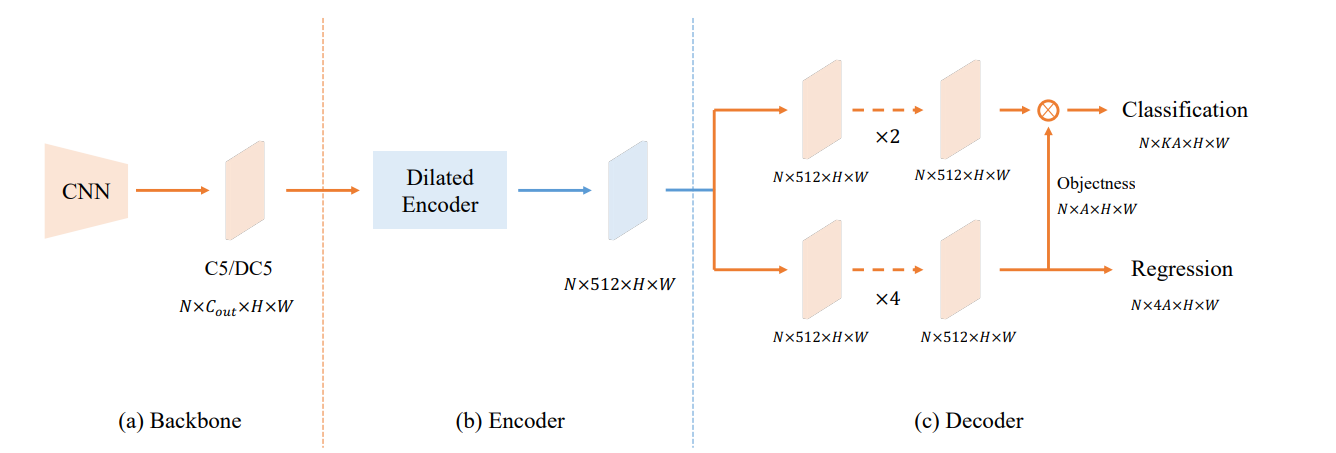
Ta sẽ chỉ lấy một scale từ backbone, là feature maps từ scale tức . Neck của YOLOF (hay còn gọi là Encoder) là Dilated Encoder đã nói ở phía trên với số channel là . Head của YOLOF có hơi dị một chút. Ta vẫn có 2 nhánh Classification và Regression như bình thường, tuy nhiên ở nhánh Classification thì chỉ sử dụng 2 Conv module (Conv + ReLU + GN) nhưng ở nhánh Regression thì lại dùng 4 Conv module. Thêm nữa, ở nhánh Regression cũng có predict ra Objectness nhưng nó là Implicit Objectness, tức là sẽ không hề có target cho Objectness này, mà predict được ra bao nhiêu, nhân với Classification và tính loss trên Classification :v
Một chút so sánh
YOLOF vs RetinaNet
Vì base của YOLOF là RetinaNet, nên sẽ rất dễ hiểu khi so sánh YOLOF với RetinaNet
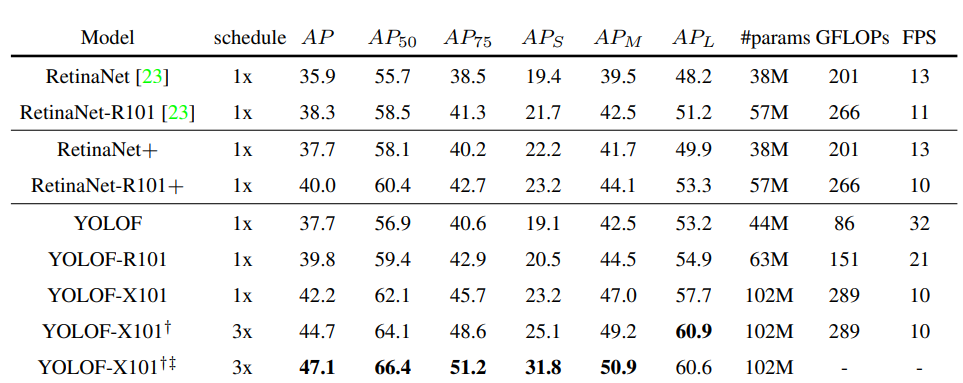
Bảng 1 là kết quả của YOLOF và RetinaNet. RetinaNet ở phần đầu của bảng là model y hệt RetinaNet trong paper của RetinaNet. Tuy nhiên, phần Head của YOLOF có một số thay đổi: Implicit Objectness, sử dụng GIoU Loss và Group Norm (GN). Nên RetinaNet + ở phần 2 của bảng là RetinaNet với những thay đổi trong Head như của YOLOF. Ta có thể thấy, với việc không có scale và , của YOLOF khá là thảm so với RetinaNet. Chứng tỏ, để phát hiện object nhỏ, thì các feature maps có kích cỡ to vẫn khá là quan trọng. Tuy nhiên, của YOLOF lại hoàn toàn hơn hẳn RetinaNet. Đây là một điều khá dễ hiểu bởi YOLOF tập trung hoàn toàn vào scale chuyên sử dụng để phát hiện object to. YOLOF có tốc độ khá nhanh so với RetinaNet (gấp 3 lần với backbone ResNet-50)
YOLOF vs DETR
DETR cũng là một loại model chỉ sử dụng mỗi scale , và sử dụng Self-Attention trong Head. DETR cũng phát hiện object to rất tốt, và gặp khó khăn trong việc phát hiện object nhỏ (tính chất của Self-Attention thuần mà).
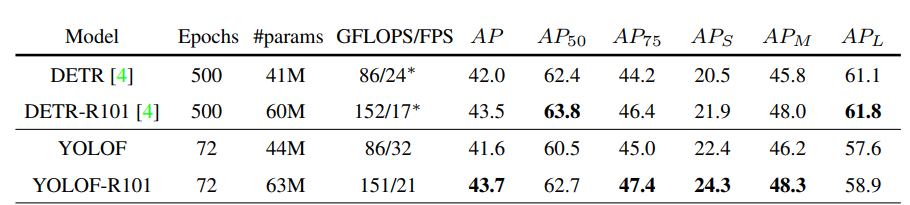
Bảng 2 là kết quả của YOLOF và DETR. của DETR vẫn hơn so với YOLOF, tuy nhiên chỉ dùng Convolution mà đạt kết quả như này là dã khá tốt rồi. Hơn nữa, của YOLOF hơn một chút so với DETR. Nhưng quan trọng nhất là, YOLOF hội tụ nhanh hơn rất rất nhiều so với DETR. Nếu chỉ cần phát hiện object to, YOLOF là lựa chọn cho bạn.
TL;DR
[W]hat
- Một loại model Object Detection chỉ thực hiện detect dựa vào scale giống như DETR, nhưng không sử dụng Self-Attention
[W]hy
- Tăng tốc độ so với những model dựa vào nhiều scale (, , ), gọi là multi-scale features
Ho[W]
- Phân tích FPN (Feature Pyramid Network) và chỉ ra rằng tính chất chia để trị (Divide-and-conquer) của FPN rất quan trọng chứ không chỉ mỗi multi-scale features
- Tận dụng duy nhất scale để tăng tốc model, phân tích những gì còn thiếu và sai khi chỉ sử dụng scale này
All rights reserved
