
Fine-tuning một cách hiệu quả và thân thiện với phần cứng: Adapters và LoRA
Bài đăng này đã không được cập nhật trong 3 năm
Fine-tuning là gì?
Trong Machine Learning, Fine-tuning là một phương pháp của transfer learning, sử dụng weight của một pre-trained model để train với một bộ data mới, phù hợp với mục đích của người dùng và số lượng dataset thường nhỏ hơn khi pre-train. Việc làm này giúp tăng độ chính xác của model so với việc train trực tiếp với bộ dataset nhỏ của chúng ta. Thông thường, khi thực hiện fine-tuning, ta sẽ phải train toàn bộ hoặc một số layers của model, và cũng phải lưu lại toàn bộ các tham số của model hoặc một số layers của model được fine-tune luôn. Tức là với 10 downstream tasks, ta sẽ phải train toàn bộ model 10 lần, xong lại lưu lại weight của cả 10 models. Đối với những model nhỏ thì điều này không phải là một vấn đề lớn, tuy nhiên, trong cái kỉ nguyên mà người người nhà nhà sử dụng các model cực nặng, từ vài trăm triệu đến vài tỉ tham số: Stable Diffusion, LLaMA, yada yada,... thì việc train toàn bộ model, và lưu toàn bộ model là một vấn đề cực kì khó khăn với những người bị giới hạn về mặt phần cứng.
Parameter-efficient Fine-tuning (PEFT) với Adapters
Năm 2019, Neil Housby và đồng bọn đã nghĩ ra một cách fine-tuning một cách hiệu quả và thử áp dụng vào BERT-large: Ở mỗi khối Transformer trong model, ta chèn thêm vào 2 lớp Adapters (Hình 1) trước khi thực hiện fine-tuning. Cái hay ở đây là ta chỉ thực hiện training các lớp Adapters được chèn vào model thôi, và freeze toàn bộ pre-trained model trong quá trình fine-tuning.
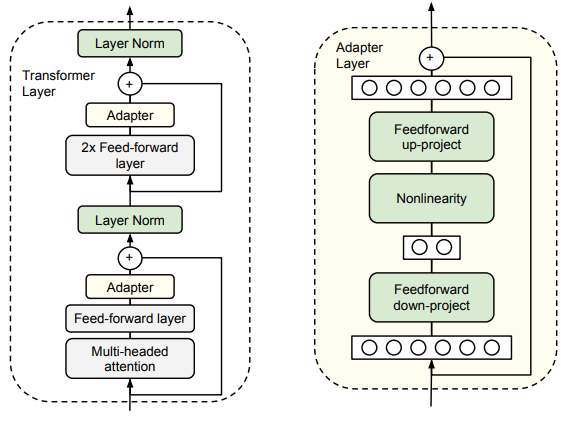
Việc freeze toàn bộ pre-trained model và chỉ train các lớp Adapters khiến số parameters cần phải train giảm đáng kể, do đó làm quá trình training ngốn ít tài nguyên hơn rất nhiều. Để mình giải thích tại sao việc giảm số parameters cần phải train lại giúp quá trình training ngốn ít tài nguyên hơn nhé.
Khi chúng ta training một Neural Network (NN) và sử dụng GPU, thì lúc này, Video RAM (VRAM) của GPU sẽ cần phải lưu trữ:
- Model weight
- Optimizer states (trạng thái của optimizer)
- Gradients (đạo hàm)
- Forward activations để tính gradients nhanh hơn
- Và một số thứ khác nữa
Khi ta freeze toàn bộ pre-trained model, thì ta sẽ không cần tính toán gradients cho chúng, cũng như không cần phải ghi nhớ lại activations của các lớp đã freeze giảm lượng VRAM cần thiết để lưu Gradients và Forward activations.
Không chỉ dừng lại ở việc ngốn ít tài nguyên hơn khi training, việc sử dụng Adapters còn ngốn ít tài nguyên hơn trong việc lưu trữ. Giờ đây, sau mỗi lần fine-tuning, thay vì phải lưu weight của model có độ nặng từ vài trăm Mb đến vài chục Gb, ta chỉ cần lưu weight của Adapters cực kì nhẹ (vài Mb). Lúc này, việc chia sẻ Adapters cho người khác thì dễ dàng hơn rất nhiều là chia sẻ cả model.
Tưởng tượng một trường hợp như này: Bạn đang có weight của Stable Diffusion 1.5 (SD 1.5) chuyên sinh ảnh gái kiểu người thật nặng 4Gb, giờ bạn muốn cái SD 1.5 của bạn sinh ảnh gái alime, thay vì phải down nguyên cái SD 1.5 nặng 4Gb nữa chuyên sinh ảnh gái alime, thì bạn chỉ cần down Adapters chuyên sinh ảnh gái alime của SD 1.5 nhẹ tầm 30-100Mb thôi, và cắm nó vào cái SD 1.5 của bạn.
Một lý do nữa cho việc fine-tuning sử dụng Adapters thay vì model đó chính là vấn đề lãng quên task cũ của model khi thực hiện fine-tuning trên task mới. Tuy nhiên, mình sẽ không nói tại đây vì bài này mình muốn nói về tài nguyên training khi sử dụng Adapter.
Vào năm 2020, Pfeiffer và đồng bọn đã tạo ra AdapterHub, một nơi chuyên để chia sẻ Adapter. Đúng vậy, thay vì chia sẻ model, thì mọi người bây giờ lại chia sẻ Adapter cho nhau (Hình 2).
Low-rank Adaptation: LoRA
Điểm yếu của Adapters thông thường
Như mình đã nói ở trên, sử dụng Adapters tức là ta phải chèn thêm vào model các lớp Adapters. Tức là trong quá trình forward của model, độ nặng tính toán tăng lên, và không có cách trực tiếp nào để loại bỏ quá trình tính toán thêm này của Adapters. Mặc dù độ nặng tính toán của từng layer Adapter là nhỏ, tuy nhiên, như đã nhắc tớ ở trong VoVNet, việc chèn thêm nhiều layer nhỏ sẽ làm tăng số phép tính tuần tự của model, giảm khả năng tính toán song song của GPU không tận dụng tốt khả năng tính toán song song của GPU.
Quá trình Fine-tuning
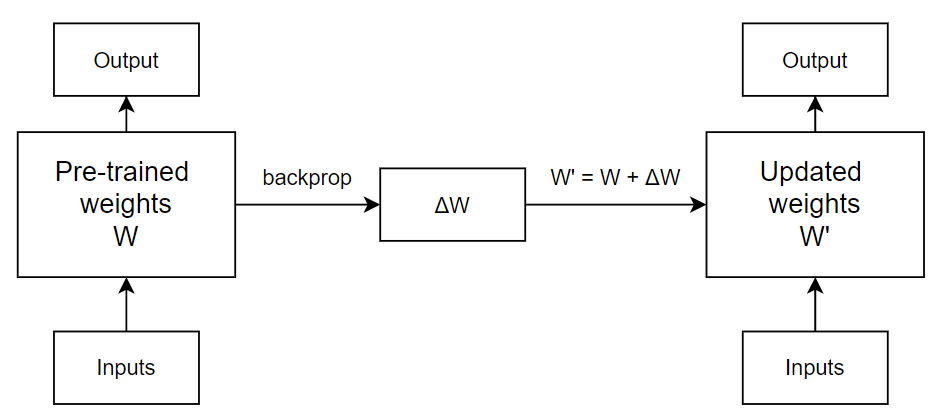
Quá trình weight của một layer được thay đổi như thế nào khi fine-tune được thể hiện ở Hình 3. Pre-trained weights của model sẽ biến thành updated weights dựa trên giá trị weight cần thay đổi thu được từ quá trình backprop. Và ở iteration tiếp theo, lại được update với một khác.
Quá trình forward sau mỗi iteration như sau:
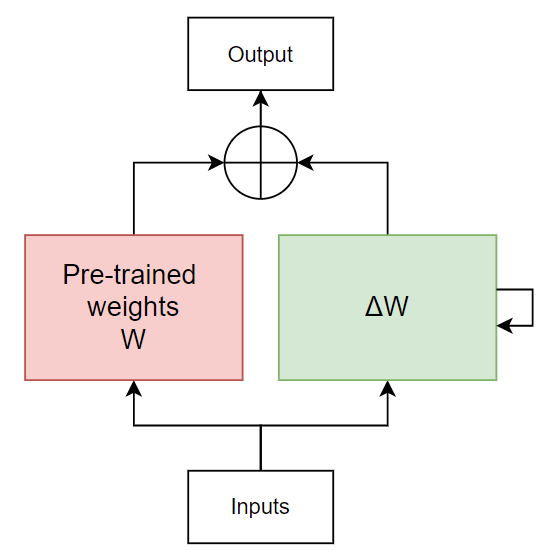
Giờ thử nhìn quá trình cập nhật của fine-tuning theo 1 cách nhìn khác nhé (Hình 4). Tại mỗi iteration, thay vì cập nhật thì ta cập nhật (Như cách mình cố tình biểu diễn iteration 2 ở phía trên). Lúc này, pre-trained weights sẽ luôn được giữ nguyên (freeze), và ta chỉ cần biết được toàn bộ là có thể thu được model weight sau finetune bằng cách cộng với .
Biểu diễn delta W
Mục đích của LoRA là tìm cách biểu diễn ma trận thành một dạng biểu diễn nhẹ hơn. Năm 2020, có một paper nói rằng những mô hình ngôn ngữ pre-trained có intrinsic dimension (hay intrinsic rank) cực kì thấp, tức là, model này có thể được biểu diễn sử dụng số chiều ít hơn rất nhiều so với số chiều gốc của model, mà vẫn giữ được performance khi đem đi fine-tune.
Tận dụng ý tưởng này, nhóm tác giả của LoRA cũng cho rằng, cũng có thể được biểu diễn với số chiều ít hơn rất nhiều số chiều gốc của . LoRA chọn sử dụng Matrix decomposition để biểu diễn ma trận bằng tích của các ma trận con với độ nặng tính toán thấp hơn việc tính trên ma trận gốc. Có rất nhiều phương pháp Matrix decomposition (LU decomposition, Singular Value Decomposition, ...), và LoRA chọn sử dụng phương pháp Neural Network :v
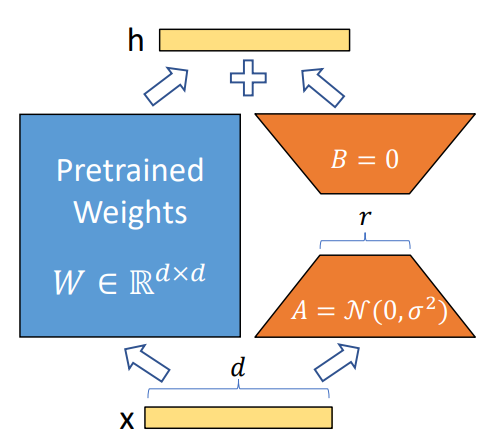
LoRA phân tách ma trận thành 2 ma trận con và với số rank thấp hơn rất nhiều ma trận ban đầu. Cụ thể, với và số rank . Lúc này, output của layer đó sẽ trở thành:
Ma trận được khởi tạo theo random Gaussian init, còn ma trận thì được khởi tạo toàn 0, vậy nên có giá trị khi bắt đầu training. Và quá trình training sẽ tối ưu để tìm ra ma trạn và .
Tại sao phân tách ma trận thành 2 ma trận và lại khiến tính toán nhẹ đi?
Nhìn vào Hình 6, số phần tử mà ma trận ban đầu có là , còn số phần từ mà sau khi phân rã ma trận thành 2 ma trận và có là: . Thử thay số vào nhé. Chọn . Số phần tử của ma trận trước phân rã là: , số phần tử sau phân rã là , ít hơn tới lần.
Để có thể phân tách được một layer Linear, LoRA thêm vào Linear layer đó 2 lớp Linear nữa, mỗi lớp Linear đại diện cho ma trận và . Lúc này nó giống như việc training một NN bình thường thôi. Chú ý là, hiện tại LoRA mới chỉ hỗ trợ phân tách weight của layer Linear, và chưa hỗ trợ cho những layer khác.
Tại sao LoRA cũng thêm layers vào mà không bị chậm giống Adapters thông thường?
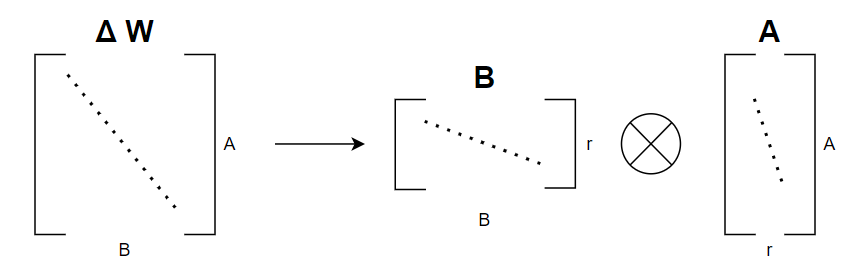
Đúng, bản chất LoRA cũng là thêm các layers vào trong model. Nhưng cái hay của LoRA là nó có thể Re-parameterize sau khi training xong. Về kĩ thuật Re-parameterize, mình đã có nói qua ở đây. Trong quá trình training, việc forward qua model vẫn chậm, nhưng sau khi train xong, thu được và , ta sẽ thực hiện một phép Re-parameterize cực kì đơn giản:
Lúc này, 2 Linear layers đại diện cho và đã được gộp vào Linear layer ban đầu, thế là lại chỉ còn một Linear layer.
Kết
Với việc chia sẻ LoRA của Stable Diffusion đầy rẫy trên mạng, hy vọng sau bài này các bạn đã hiểu được LoRA là gì, tại sao nó lại nhẹ hơn model Stable Diffuision, và nó có ích như thế nào.
All rights reserved
