
[Paper Explain] Clustering trong Computer Vision: Hướng đi mới thay thế CNN và Transformer?
Bài đăng này đã không được cập nhật trong 3 năm
Tóm tắt
Ảnh là gì và làm thế nào để trích xuất features?
Convolutional Neural Network (CNN). CNN xem ảnh là các pixel có tổ chức theo dạng hình chữ nhật và thực hiện trích xuất features sử dụng phép Convolution ở một vùng cục bộ.
Vision Transformer (ViT). ViT xem ảnh là một chuỗi các patch và thực hiện trích xuất features sử dụng phép Self-Attention ở khoảng cách toàn ảnh.
Và bài này sẽ giới thiệu về một cách biểu diễn hình ảnh vô cùng mới và trực quan, gọi là:
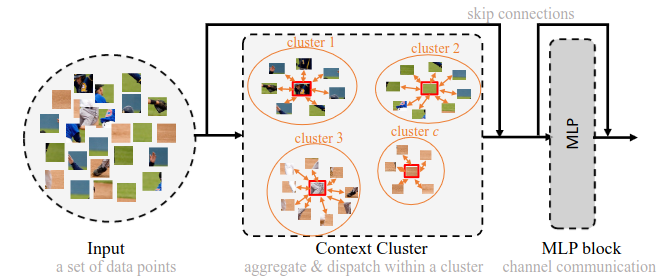
Context Cluster (CoC). CoC coi ảnh là một tập hợp các điểm (points) không có tổ chức và trích xuất features thông qua thuật toán clustering (phân cụm). Cụ thể, mỗi điểm sẽ bao gồm raw feature (feature chưa xử lý) là: màu và thông tin vị trí, sau đó ta sử dụng thuật toán phân cụm để trích xuất features. Với một thiết kế đơn giản như vây, CoC có thể đem lại khả năng giải thích (Explainable AI) thông qua việc quan sát quá trình phân cụm.
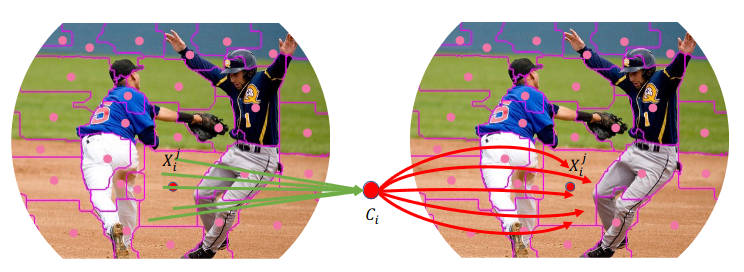
Mở đầu
Cách ta trích xuất thông tin từ ảnh phụ thuộc rất nhiều vào việc ta diễn giải, hiểu một tấm ảnh đó theo cách nào. CNN thì khái niệm hóa một bức ảnh là một tập hợp các pixel được sắp xếp theo dạng hình chữ nhật, và trích xuất local features sử dụng convolution theo dạng cửa sổ trượt. Với một vài inductive bias như tính locality và translation equivariance, CNN là một mạng tối ưu. Transformer thì coi ảnh như một chuỗi các patch, và phép Self-Attention mang tính global được sử dụng để kết hợp thông tin giữa các patches với nhau.
Các model trong mới hiện nay đều được xây dựng dựa trên Convolution hoặc Attention, hoặc là kết hợp cả 2 lại với nhau. Các phương pháp đó đều quét ảnh theo dạng từng ô (convolution) nhưng vẫn tận dụng mối tương quan giữa các vùng với nhau (attention), do đó tận dụng được cả tính locality (convolution) mà không làm mất đi global interaction (attention). Mặc dù các model đó tận dụng được cả 2 đặc trưng của Convolution và Attention, nhưng những hiểu biết vẫn chỉ nằm trong CNN và ViT. Thay vì cứ tập trung mãi vào CNN và ViT, chúng ta có thể xem xét cách trích xuất thông tin khác ngoài CNN và ViT. Như các kiến trúc toàn MLP như MLP-Mixer đã cho thấy rằng MLP cũng có thể hoạt động tốt với ảnh. Hay thậm chí là có một số nghiên cứu đã sử dụng đồ thị (Graph Neural Network).
Còn trong bài này, ta sẽ xem xét lại thuật toán cổ xưa hay được sử dụng trong xử lý ảnh: Clustering. Ta sẽ coi ảnh như là một tập hợp các data points (điểm data) và nhóm các points đó vào thành các cluster. Trong mỗi cluster, ta sẽ tổng hợp các points vào center (trung tâm) rồi sau đó phân chia center đến các points trong cụm một cách thích hợp (Hình 1). Lúc này, ta sẽ coi ảnh như một Point Cloud. Việc này sẽ có thể là bước đệm tạo ra một model multi-modal giữa Point Cloud và Ảnh trong tương lai. Với tập hợp các điểm, ta sẽ sử dụng một phương pháp clustering đơn giản để nhóm các điểm vào thành các cluster. Quá trình cluster này sẽ gần giống với ý tưởng của SuperPixel, các pixel gần giống nhau sẽ được nhóm chung vào nhau, nhưng về cơ bản thì các pixel sẽ khác nhau.
Ta gọi model mới này là Context Cluster (CoC). Kiến trúc của CoC vẫn giữ được những điểm quan trọng đối với bài toán dạng ảnh như: biểu diễn hierachical (có nhiều scale), kiến trúc dạng MetaFormer. CoC có khả năng generalize tốt với các data domain khác: như Point Cloud, RGBD,... Hơn nữa, CoC còn đem lại khả năng tự giải thích một cách tuyệt vời. Bằng cách quan sát quá trình clustering, ta có thể hiểu được từng lớp trong model hoạt động như nào. Nếu hứng thú về việc quan sát quá trình clustering, các bạn có thể nhảy ngay xuống mục Visualization của bài này.
Context Cluster
Phần này sẽ mô tả Pipeline của CoC trước, cách biểu diễn Points, đường đi trong model. Sau đó, sẽ mô tả block chính: Context Cluster Block.
Pipeline
Từ ảnh thành points
Xét một ảnh đầu vào , ta sẽ thêm vào mỗi pixel tọa độ 2D, tọa độ của mỗi pixel sẽ được biểu thị là . Lúc này, ảnh sẽ được biến thành tập hợp các points (pixels) với là số lượng points, và mỗi points được biểu diễn bởi 5 đặc trưng: màu (3) và tọa độ (2)
Trích xuất features từ points
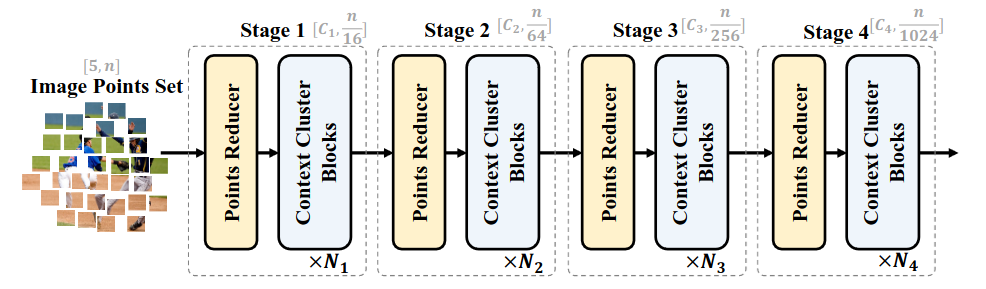
Ta sẽ trích xuất features sử dụng Context Cluster Block. Hình 2 mô tả kiến trúc mạng Context Cluster. Với một tập hợp các points ảnh , trước hết ta sẽ giảm số points xuống để tính toán đỡ nặng hơn, sau đó sẽ áp dụng các Context Cluster Block để trích xuất features. Để giảm số lượng points xuống, ta sẽ chọn ra một số anchors ở trong không gian points, và points gần anchors nhất sẽ được tổng hợp và kết hợp sử dụng một MLP (Hình 3).
Áp dụng vào từng task
Đối với task Classification, ta average toàn bộ các points rồi sau đó sử dụng một lớp FC để thực hiện Classification. Còn với những downstream task như Segmentation, Object Detection, ta phải biến đổi các points lại thành tensor 3D để có thể tích hợp với những phương pháp Segmentation, Object Detection có sẵn.
Point Reducer
Ta sẽ giảm số lượng points xuống sử dụng module Point Reducer. Để giảm số lượng points xuống, ta phải định nghĩa các anchors. Các anchors được dàn trải đều trong không gian points. Để hiểu quá trình lấy anchors kĩ hơn, ta sẽ hình dung dưới dạng các points khi được sắp xếp đúng trật tự thành ảnh.
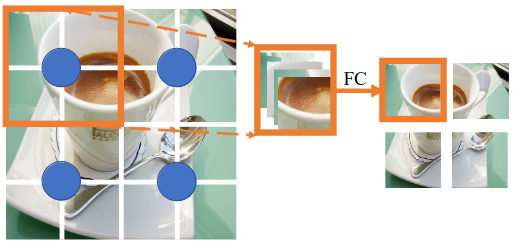
Xét 16 points như Hình 4, ta sẽ tìm ra 4 anchors được dàn đều trong không gian của 16 points đó, mỗi anchors sẽ lấy 4 points xung quanh nó. Các points được gán với cùng một anchors sẽ được concatenate lại với nhau và đưa qua một lớp FC để có thể giảm chiều dữ liệu xuống và cho phép các points giao tiếp với nhau. Sau khi thực hiện Point Reducer, ta thu được số points mới bằng số anchors. Ta chọn gán 4 points cho 1 anchors để cho giống với cách thức downsample qua các stage như của CNN và ViT. Chú ý, quá trình này gần giống với quá trình Patch Embedding của ViT.

Trong quá trình Context Cluster (trình bày ở phía dưới), ta sẽ phải tạo ra các centers để phục vụ quá trình tính toán. Cách tạo centers khác với cách tạo anchors. Ở trong Point Reducer, để tạo ra anchor, ta sẽ gom 4 points gần nhau lại, rồi đưa qua một MLP để tạo ra anchor. Còn tạo center ở trong Context Cluster, ta sẽ lấy trung bình 9 points xung quanh, như 9 points ở trong vòng tròn xanh trên Hình 5. Chú ý, các points được gom để tạo center không nhất thiết phải ở chung cluster.
Context Cluster operation
Context Clustering
Cho một tập points với là số points, là số chiều features , ta sẽ nhóm các points lại dựa trên similiary (độ tương quan) của chúng, mỗi points sẽ chỉ được gán vào một cluster.
Trước tiên, ta biến đổi để thực hiện tính similarity.
Ta tạo ra centers cách đều nhau trong không gian points, và mỗi center sẽ được tính bằng cách lấy trung bình points xung quanh nó (đã trình bày ở phần trên).
Tính ma trận pair-wise cosine similarity (độ tương tự cos) giữa và các centers .
Sau đó, ta gán các points vào các centers có similiary cao nhất với nó, tạo thành cluster.
Feature aggregating (tổng hợp feature)
Ta sẽ tổng hợp lại các điểm ở trong một cluster dựa trên độ similarity đến điểm center.
Giả dụ rằng một cluster chứa points (là tập con của ) và similarity giữa points với center là (là tập con của )
Ta sẽ biến đổi points từ không gian points sang không gian value, đạt được với là số chiều trong không gian value.
Ta tiếp tục tạo ra các center trong không gian value giống với cách tạo ra center trong quá trình Context Clustering.
Ta sẽ tính feature tổng hợp như sau:
với và à 2 hệ số có thể học được thông qua backprop để dịch chuyển similarity (tác dụng giống BN); là sigmoid activation để đưa similarity về lại khoảng ; là point thứ trong
Feature dispatching (chia lại feature)
Feature được tổng hợp sau đó sẽ được phân chia lại cho mỗi points trong cluster dựa trên độ similarity. Có thêm bước feature dispatching này giúp các points ở trong cluster có thể giao tiếp được với nhau, và thực hiện chia sẻ features đến các points ở trong cluster. Mỗi point sẽ được cập nhật như sau:
Ở đây lớp FC có vai trò là đưa chiều channel từ về
Multi-head computing
CoC cũng sử dụng ý tưởng Multi-head của Transformer và đưa nó vào trong quá trình Context Clustering cũng như là Feature Aggregating. Multi-head sẽ được sử dụng trong việc biến đổi và biến đổi . Output của Multi-head sau đó được tổng hợp thông qua một lớp FC đơn giản
Khởi tạo kiến trúc
Với những kiến thức ở trên, ta sẽ sử dụng chúng để tạo ra model hoàn chỉnh. Mặc dù Context Cluster là phép toán khác hoàn toàn so với Convolution hay Self-Attention, ta vẫn có thể sử dụng tư tưởng của chúng để tạo ra model như: Có nhiều scale, kiến trúc dạng MetaFormer.
Và để có sự tương đồng với những CNN và Transformer, cũng như là có thể sử dụng với những model Object Detection hay Segmentation có sẵn, số lượng points qua từng stage sẽ được giảm từ từ theo hệ số 16, 4, 4 và 4. Vì vậy, trong Point Reducer, ở stage đầu, một center sẽ cần lấy tới 16 points xung quanh nó, và ở những stage còn lại thì cần lấy 9 points xung quanh nó. Chỗ này có vẻ hơi buồn cười khi mà số lượng points giảm đi 4 lần nhưng lại phải gom 9 points vào một anchors? Tuy nhiên, Point Reducer ở những stage sau không giống với stage đầu. Ở những stage sau, Point Reducer có sử dụng padding và đồng thời một points có thể góp phần cho nhiều hơn 1 anchors. Quá trình Point Reducer ở những stage sau gần giống với quá trình Overlap Patch Embedding trong ViT.
Có một vấn đề về tính toán khi ta sử dụng CoC một cách thông thường. Giả dụ, ta có points, mỗi point có chiều, và có centers thì độ phức tạp tính toán sẽ là , là quá lớn khi mà kích cỡ bức ảnh lớn. Để hiệu năng tính toán được tốt hơn, ta sẽ sử dụng kĩ thuật region partition (phân vùng) bằng cách tách points theo từng vùng trước (giống như cơ chế cửa sổ của Swin Transformer), và ta sẽ tính toán similarity trong từng vùng đó thôi chứ không phải toàn bộ ảnh. Gọi số vùng là , độ phức tạp tính toán sẽ chỉ còn là . Tuy nhiên làm như vậy thì receptive field của context cluster sẽ bị giảm đi khá mạnh, và không có sự giao tiếp giữa các vùng đó với nhau.
Một số câu hỏi
Center tĩnh hay động? Các thuật toán clustering thông thường sẽ liên tục update lại center trong quá trình tối ưu, cho đến khi hội tụ mới dừng update center. Tuy nhiên, nếu đưa ý tưởng này vào CoC thì sẽ là một vấn đề quá khó để thực hiện do clustering là thuật toán chính của mỗi Block trong mạng, quá trình training thậm chí là inference sẽ tăng lên quá khủng khiếp. Vì thế, trong Context Cluster, ta giữ nguyên center để tính toán không quá nặng.
Overlap hay non-overlap clustering? Ta chỉ một point đến một center cụ thể thay vì một points có thể đến nhiều centers. Mặc dù gán points đến nhiều centers thay vì một có thể mang lại hiệu năng cao hơn, tuy nhiên độ phức tạp tính toán lại tăng lên khá nhiều nên tác giả chọn không làm như vậy.
Kết quả
Classification (ImageNet)
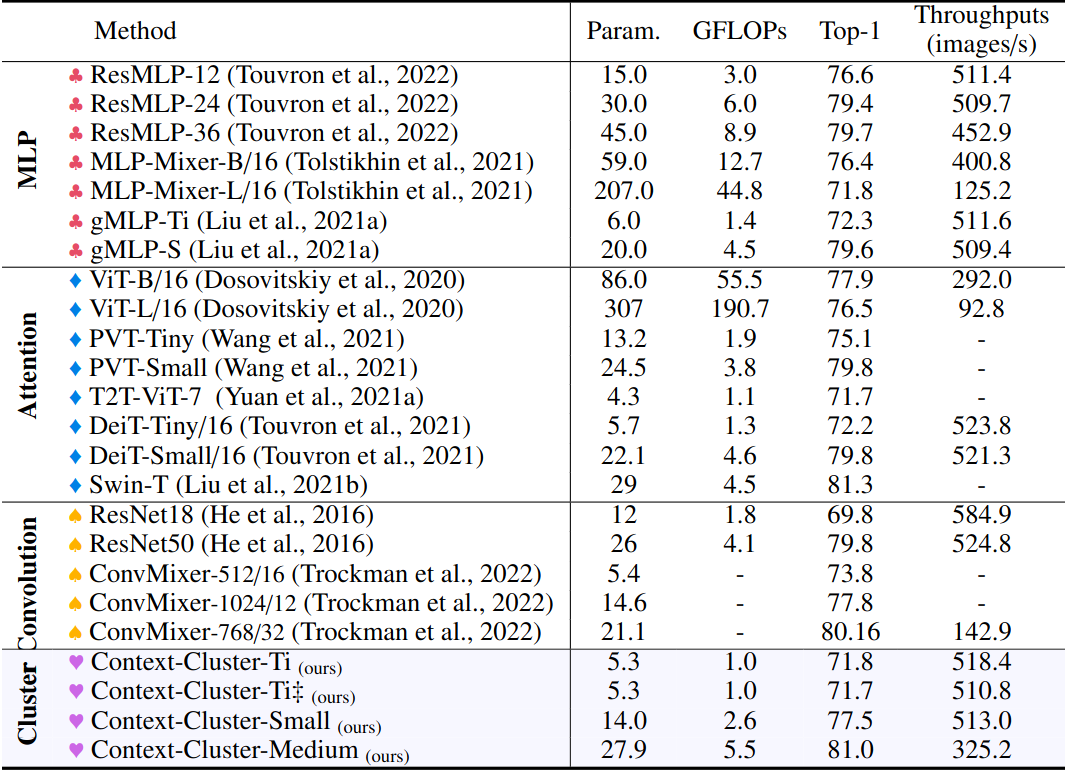
Object Detection (COCO)


Semantic Segmentation (ADE20K)
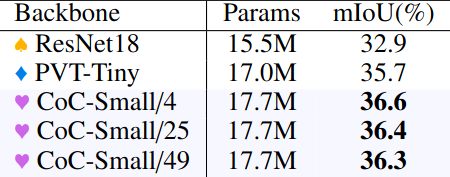
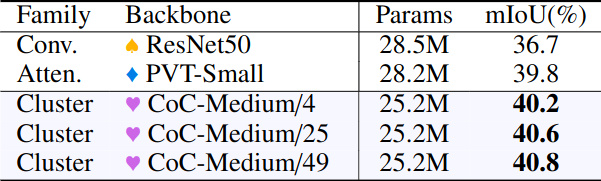
Visualization
Đây là phần thú vị nhất trong cái bài viết này. Thay vì phải học các phương pháp phức tạp như Grad-CAM bla bla để quan sát xem cái model của mình nó hoạt động như nào, thì với CoC ta chỉ cần nhìn quá trình clustering là đã có thể thấy rõ được rồi
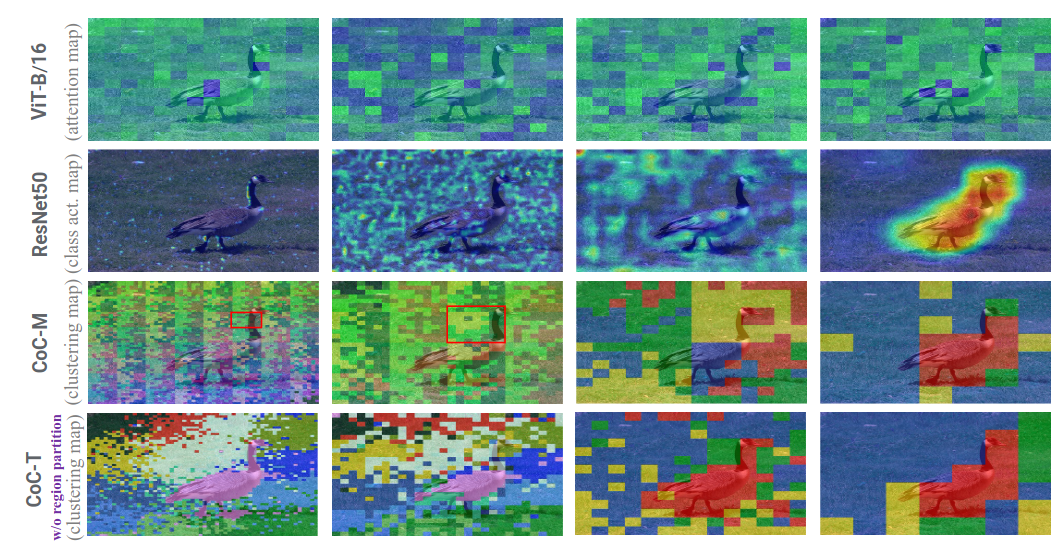
Do Viblo không cho up file quá lớn lên nên mình sẽ dẫn một số GIF visualize nữa nhìn khá là thú vị. Kết quả của các GIF dưới đều là từ stage 1 của CoC không region partition.
GIF 1: https://github.com/ma-xu/Context-Cluster/blob/main/images/gifcompressor/A_Stage0_Block0_Head1-min.gif
GIF 2: https://github.com/ma-xu/Context-Cluster/blob/main/images/gifcompressor/B_Stage0_Block0_Head1-min.gif
GIF 3: https://github.com/ma-xu/Context-Cluster/blob/main/images/gifcompressor/3_Stage0_Block0_Head1-min.gif
Reference
Image as Set of Points: https://arxiv.org/abs/2303.01494
Github CoC: https://github.com/ma-xu/Context-Cluster
All rights reserved
