
Self-Attention Text Recognition Network
Bài đăng này đã không được cập nhật trong 5 năm
Giới thiệu
Scene Text Recognition (STR) là một bài toán khó, đặc biệt khi Text trong ảnh không có hình dạng nhất định. Một phương pháp thú vị giới thiệu bởi các tác giả đến từ team Clova AI Research, NAVER. Trong paper này, Self-Attention Text Recognition Network (SATRN) được nghiên cứu và thực nghiệm nhằm giải quyết các bài toán Scene text recognition.
Tổng quan
Với bài toán Scene Text Recognition, có hai hướng tiếp cận phổ biến: chuẩn hóa ảnh đầu vào (input rectification) và sử dụng 2D feature maps.
Phương pháp đầu tiên thường sử dụng mạng Spatial Transformer Networks (STN - các bạn có thể tham khảo thêm tại đây. Tuy nhiên các quá trình áp dụng thực tế cho thấy vẫn tồn tại một nhược điểm lớn đó là chất lượng bị phụ thuộc vào khả năng transform chuẩn hóa ảnh đầu vào (đặc biệt các trường hợp khó như ảnh text dọc)
Phương pháp thứ 2 hướng tới việc sử dụng feature map 2D của ảnh đầu vào mà không ảnh hưởng đến hình dạng của ảnh. Tuy nhiên các nghiên cứu trước đây theo hướng này tương đối phức tạp (AON), đòi hỏi bouding box của ký tự (ATR), và bị phụ thuộc và các mô hình CNN như ResNet để trích xuất các feature map. Một vấn đề khác do việc sử dụng RNN/LSTM và cùng height pooling dẫn tới việc không tận dụng được các thông tin về không gian (spatial dependency/information) giữa các ký tự trong ảnh, một vấn đề nan giải trong các bài toán STR.
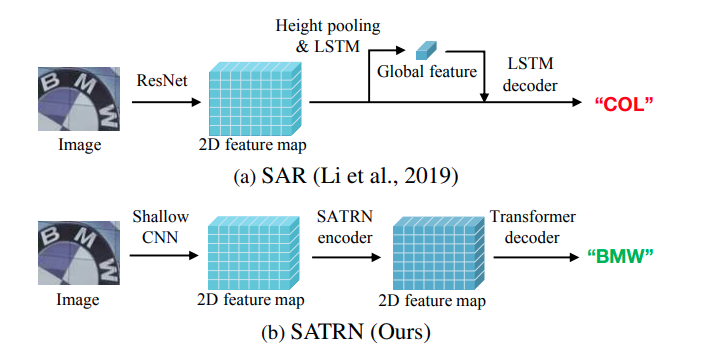
Mạng SATR tối ưu cơ chế self-attention với mục đích thu được các feature về không gian, 2D feature map ảnh text scene. Lấy ý tưởng trên mô hình Transformer, kiến trúc rất nổ trong các bài toán NLP và CV gần đây. Phương pháp của tác giả cũng bao gồm kiến trúc encoder-decoder nhằm giải quyết vấn đề representation giữa ảnh và text.
Ý tưởng chính
 Giống như Transformer, kiến trúc tổng quát của mạng SATRN bao gồm encoder (bộ mã hóa) - cột trái, với mục đích embedding ảnh thành 2D feature map và decoder (bộ giải mã) giúp trích xuất chuỗi ký tự từ feature map. Hãy cùng đi sâu vào kiến trúc phần Encoder.
Giống như Transformer, kiến trúc tổng quát của mạng SATRN bao gồm encoder (bộ mã hóa) - cột trái, với mục đích embedding ảnh thành 2D feature map và decoder (bộ giải mã) giúp trích xuất chuỗi ký tự từ feature map. Hãy cùng đi sâu vào kiến trúc phần Encoder.
Encoder
Encoder sẽ đưa ảnh qua khối Shallow CNN nhằm lấy được local pattern và texture. Feature map trích xuất sẽ được đưa qua module self-attention cùng với Adaptive 2D positional encoding. Khác với Transformer, tác giả đã thay pointwise feed forward bằng locality-aware feed forward layer.
Shallow CNN block
Shallow CNN có mục đích trích xuất các patern low lever cùng với texture của bức ảnh. Không như dữ liệu text, một bức ảnh đòi hỏi mức trích xuất trên nhiều mức độ khác nhau (ví dụ background texture).
Chính vì vậy việc bằng cách thêm một lớp CNN Shallow sẽ giảm được mức độ tính toán so với việc áp dụng trực tiếp self-attention block. Block CNN được sử dụng khá cơ bản chỉ bao gồm 2 lớp convolution với 3x3 kernel, với 2 lớp max pooling 2x2 stride 2.
Adaptive 2D positional encoding
Feature map ở bước trước sẽ được đưa qua block self-attention. Trong kiến trúc Transformer, các thông tin về vị trí được thêm bởi positional encoding (PE) vector để tạo thành chuỗi feature map 1 chiều. Tuy nhiên, việc này trở nên bất khả thi trong việc lưu trữ các đặc tính về không gian (giống như lớp fully-connected).
Và chính các thông tin này khiến mô hình khó có thể rút ra các thông tin dạng chuỗi. Nhóm tác giả đề xuất Adaptive 2D positional Encoding (2DPE) nhằm xác định được PE cả chiều lẫn chiều ngang của ảnh đầu vào.
Với là 2D feature map và là vị trí tương ứng
- Self-attion không có PE được giới thiệu như sau
Trong đó
với và lần lượt là các trọng số map đầu vào cuar queries và keys
Hay nói cách khác biểu diễn trọng số attention của feature tại với query feature là .
- A2DPE có thể được biểu diễn như sau
trong đó
với , lần lượt là index của vị trí và chiều hidden
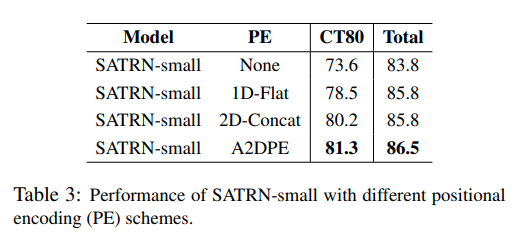
So sánh mô hình với các lớp PE khác nhau trên tập CUTE80 (tập dữ liệu chứa nhiều ảnh text cong và hình dạng phức tạp), kết quả cho thấy A2DPE có độ chính xác cao nhất trong 4 lựa chọn.
Locality-aware feedforward layer
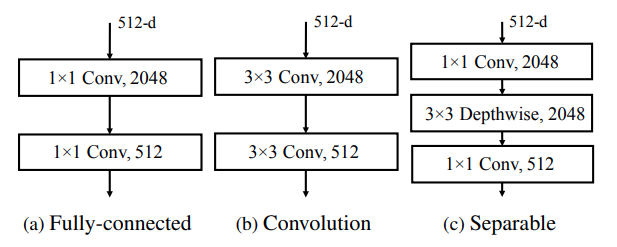
Self-attention cực kỳ hữu ích trong việc lưu trữ bộ nhớ long-term và shor-term trong 2D feature map. Tuy nhiên việc chồng nhiều lớp self-attention chỉ để lữu trữ thuộc tính short-term là điều không thực sự cần thiết. Chính vì vậy, nhóm tác giả đã thay lớp point-wise feedforward (1x1 Conv) (a) bằng Conv (b) cùng Depthwise (c).
Decoder
Phần decoder có nhiệm vụ lấy cách 2D feature từ encode và mapping thành chuỗi ký tự. Việc chuyển hóa giữa ảnh và text diễn ra tại module multi-head attention thứ 2. Model này lấy đặc trưng của ký tự hiện tại để tìm được ký tự tiếp theo trên 2D feature map. Nhìn chung phần kiến trúc này không có nhiều khác biệt với decoder Transformer.
Kết quả
Kết quả được đánh giá trên 7 test dataset khác nhau bao gồm dữ liệu dễ (regular) và khó (irregular - gồm hình dạng không cố định)
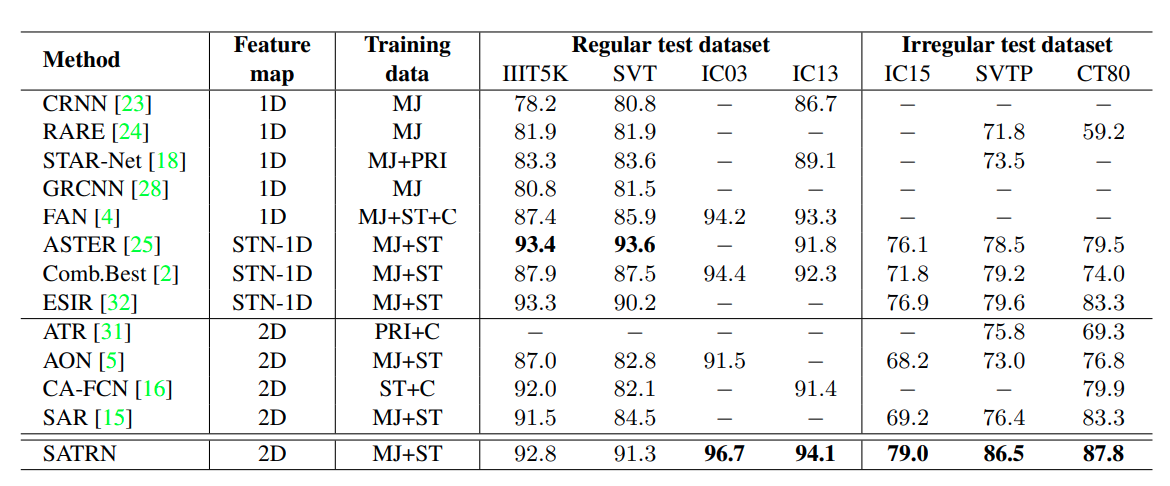
SATRN cho kết quả tốt hơn 4 phương pháp sử dụng 2D feature map khác. Trên các bộ dữ liệu khó (IC15, SVTP, CT80), SATRN thâm chí còn vượt xa phương pháp tốt nhất trước đó ESIR với xấp xỉ 4.5pp. pav
Để đánh giá hiệu quả giữa self-attention / convolution trong encoder, self-attention / LSTM trong decoder, nhóm tác giả đã so sánh cụ thể hơn 2 mô hình SATRN và SAR.
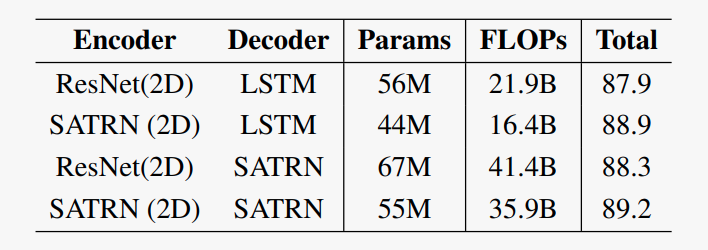
- Độ cân bằng giữa chính xác - hiệu quả
Bảng trên so sánh độ chính xác và hiệu quả (số lượng params và FLOPs) giữa các loại encoder và decoder khác nhau. Sử dụng SATRN (2D) ecoder có kết quả nhỉnh hơn ResNet encoder, và kết quả cũng tương tự khi thay LSTM decoder bằng SATRN trong khi cải thiện được hiệu quả về bộ nhớ cũng như hiệu năng (giảm 12 triệu params và 5.5 FLOPs). Kết quả này cho thấy encoder dựa trên self-attention có thể trích xuất nhiều thông tin feature maps từ ảnh hơn so với ResNet thông thường, đồng thời giảm được lượng tham số và chỉ số FLOPS. Phần decoder giữ nguyên cấu trúc của Transformer cũng cho accuracy cao hơn 0.3pp tuy nhiên lại tốn nhiều bộ nhớ và hiệu năng thấp hơn (tăng 11M params và 19.5 FLOPs).
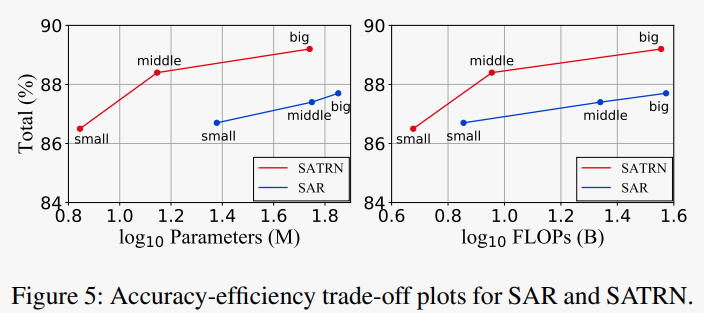
Hình 5 cho thấy việc sử dụng lớp self-attention cho khả năng trade-off giữa độ chính xác và hiệu quả tốt hơn.
- So sánh Định tính
Self Attention map của ký tự tương ứng với ROI
 Tác giả công nhận rằng với ký tự 'M', lớp self-attention sẽ tiếp nhận được ký tự 'A' là tiếp theo. SA ở lớp 2 (depth 2) đã chuyển 'sự chú ý' đến ký tự tiếp theo, tận dụng được khả năng tính toán liên kết xa (long-range connection) của self-attention. Cũng nhờ lý do này, SATRN có khả năng đạt hiệu năng tốt cũng như lược bỏ các đặc trưng không cần thiết lặp lại (do convolutional encoder).
Tác giả công nhận rằng với ký tự 'M', lớp self-attention sẽ tiếp nhận được ký tự 'A' là tiếp theo. SA ở lớp 2 (depth 2) đã chuyển 'sự chú ý' đến ký tự tiếp theo, tận dụng được khả năng tính toán liên kết xa (long-range connection) của self-attention. Cũng nhờ lý do này, SATRN có khả năng đạt hiệu năng tốt cũng như lược bỏ các đặc trưng không cần thiết lặp lại (do convolutional encoder).

Ngoài ra, bằng việc điều chỉnh động vector encoding hay tỉ lệ encoding chiều cao với encoding chiều dọc (nôm na là dùng để phân loại dạng text), A2DPE có thể giảm được gánh nặng tính toán cho các module khác.

Một ví dụ khác: 2D attention maps với dạng text nhiều dòng
Tổng kết
Đây là phương pháp tiếp cận khá thú vị với tận dụng 2D feature map cùng cơ chế self-attention. Bằng cách này, nhóm giả đã có thể giải quyết được một phần vấn đề với hình ảnh text dạng không cố định. Tại thời điểm publish paper này, mô hình đạt SOTA trong bài toán nhận diện text dạng khó
Cảm ơn các bạn đã đọc, nếu hay thì xin hãy upvote hoặc xem lại lần nữa =))
Reference
[1] SATRN - On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
[2] https://github.com/clovaai/SATRN.git
[3] SAR - Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition
[4] STN - Spatial Transformer Networks
All rights reserved
