
DEMON - Momentum Decay cho mô hình NN
Bài đăng này đã không được cập nhật trong 5 năm
Giới thiệu
Trong ML, DL các hàm/thuật toán tối ưu (optimizer) đóng vai trò không thể bàn cãi. Về cơ bản, thuật toán tối ưu là cơ sở để xây dựng mô hình neural network với mục đích "học " được các features của dữ liệu đầu vào, từ đó có thể tìm 1 cặp weights và bias phù hợp để tối ưu hóa mô hình.
Các thuật toán phổ biến hiện nay có thể kể đến như RMSProp, SGD, SGDM, AdaGrad và optimizer người người nhà nhà dùng Adam (AdamW). Một thống kê nhỏ trên paperwithcode  cho thấy được độ phổ biến của hàm tối ưu Adam. Số liệu này có thể không chính xác hoàn toàn nhưng đủ thấy được sức ảnh hưởng của Adam
cho thấy được độ phổ biến của hàm tối ưu Adam. Số liệu này có thể không chính xác hoàn toàn nhưng đủ thấy được sức ảnh hưởng của Adam  )
)
Tuy nhiên không có hàm tối ưu nào là tốt trong mọi trường hợp mà còn phụ thuộc vào rất nhiều yếu tố về dữ liệu, mô hình, tham số... Chính điều này khiến cho việc tìm ra hàm tối ưu phù hợp nhất trở thành một vấn đề lớn khi phải thực nghiệm rất nhiều lần với các tham số khác nhau.
Trong paper này, các tác giả từ Rice University có đề xuất một thiết kế hàm tối ưu mới, dựa trên momentum decaying. Đúng là momentum decaying thay vì weight decay hay learning rate decay.
Ý tưởng
Với sự phát triển của các mô hình Deep learning, việc huấn luyện mô hình trở nên dễ dàng hơn. Tuy nhiên quá trình này vẫn đòi hỏi nhiều resource, thời gian trong việc tuning các tham số cần thiết để tìm ra mô hình tối ưu. Các phương pháp đã được đề ra trước đây để giảm gánh nặng này ví dụ như phương pháp adaptive gradient-base (AdaGrad, Adam, AdamW nhìn chung là họ nhà Adam). Tuy nhiên tác giả khẳng định SGD/SGDM nhìn chung vẫn phổ biến hơn khi huấn luyện mô hình DNNs. Đi tìm một vài nguyên nhân cụ thể hơn thì khá nhiều tác giả đồng tình 1, 2. Tuy nhiên, để SGDM đạt hiệu năng tốt, cần phải tùy chỉnh hyperparameter cẩn thận. Dù chỉ một thay đổi nhỏ với learning rate, learning rate decay, momentum hay weight decay có thể thay đổi hiệu năng đáng kể. Và quá trình này rất tốn thời gian (grid search obviously?)
Momentum tuning
Momentum được nghĩ ra với mục tiêu ban đầu là làm tăng tốc độ học theo hướng tại độ cong nhỏ, mà tránh việc ảnh hưởng đến vùng có độ cong lớn.
Thông thường với SGDM sẽ tối tiểu hàm :
với là tỉ lệ giảm của momentum (momentum decay), là stochastic gradient, tích lũy momentum . thường được đặt giá trị mặc định là 0.9 (trong các paper nghiên cứu, thư viện PyTorch). Tuy nhiên không có nghiên cứu nào chỉ ra rằng giá trị này work tốt trong mọi trường hợp :v
Một vài paper trước đây cũng đã thử tuning giá trị momentum này. Điển hình như YellowFin (phương pháp tùy chỉnh learning rate + momentum đồng bộ và cả bất đồng bộ), các mô hình GANs 1, 2
Ôn lại kiến thức cũ =))
SGDM
Như đã nhắc ở trên, paper này hướng đến việc cải tiến SGDM
Trong đó là param tại step , là learning rate và là stochastic gradient tương ứng vơi . Có thể thấy nếu thì phép đệ quy trên trở về SGD. Giá trị của thường gần 1, trong đó 0.9 là giá trị mặc định của nhiều paper cũng như PyTorch Framework. Tuy nhiên không có nghiên cứu nào chỉ ra rằng giá trị này work tốt trong mọi trường hợp
Adaptive gradient descent
Phương pháp này tận dụng thông tin gradient trước cùng với learning rate param.
Phương trình này mình xin phép viết thêm bản gốc trong paper Adam cho dễ hiểu.
Phương pháp
Mục tiêu DEMON:
Giống như learning rate decay, để giảm sự phụ thuộc của gradient hiện tại và sau này. Tương tự như vậy với việc chọn momentum làm giá trị decay, nhóm tác giả kỳ vọng giảm được sự phụ thuộc gradient vào các giá trị phía sau.
Hàm tính toán momentum decay:
Trong đó là tỉ lệ cho các iteration còn lại. t là iteration hiện tại và T là tổng step.
Phân tích kỹ hơn: cùng với sẽ ảnh hưởng đến gradient phía sau (). Đồng thời cũng ảnh hưởng đến .


Nhóm tác giả đã đưa ra scheduler với quy luật mới để đưa cummulatie momentum về 0. Cho là giá trị ban đầu của , vậy tại step (trên tổng step).
Giả mã thuật toán:
 Decay momentum được cài đặt tại và .
Decay momentum được cài đặt tại và .
Thí nghiệm thực hiện
Nhóm tác giả chia thành 2 nhánh thí nghiệm chính bao gồm adaptive learning rate và adaptive momentum. DEMON được thử nghiệm trên nhiều bộ dữ liệu khác nhau với các domain khác nhau cùng rất nhiều tham số tùy chỉnh.
Các bộ dữ liệu thử nghiệm bao gồm: CIFAR10, TINY IMAGENT, CIFAR100, STL10, PTB, FMNIST, MNIST với các domain khác nhau image classification, text classification, variational auto encoder, GAN...
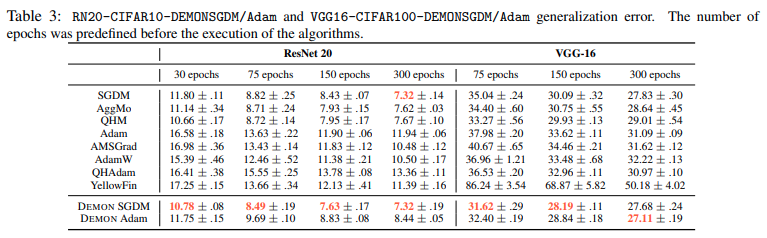
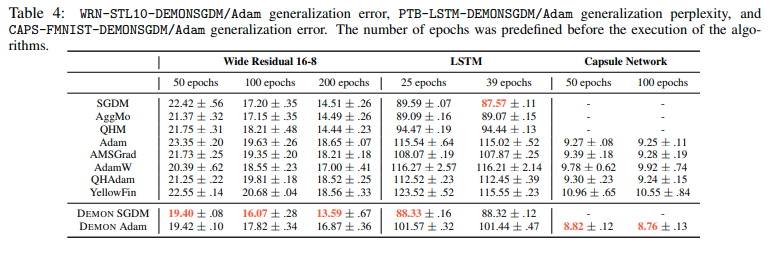
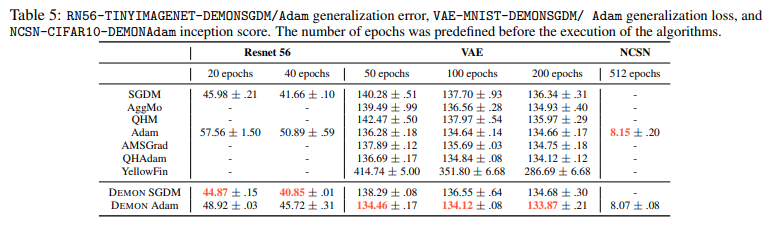
Kết quả cho thấy DEMON cho thấy kết quả tốt hơn với hầu hết các optimizer còn lại bao gồm SGDM, AggMo, QHM, Adam, AMSGrad, AdamW, QHAdam và YellowFin
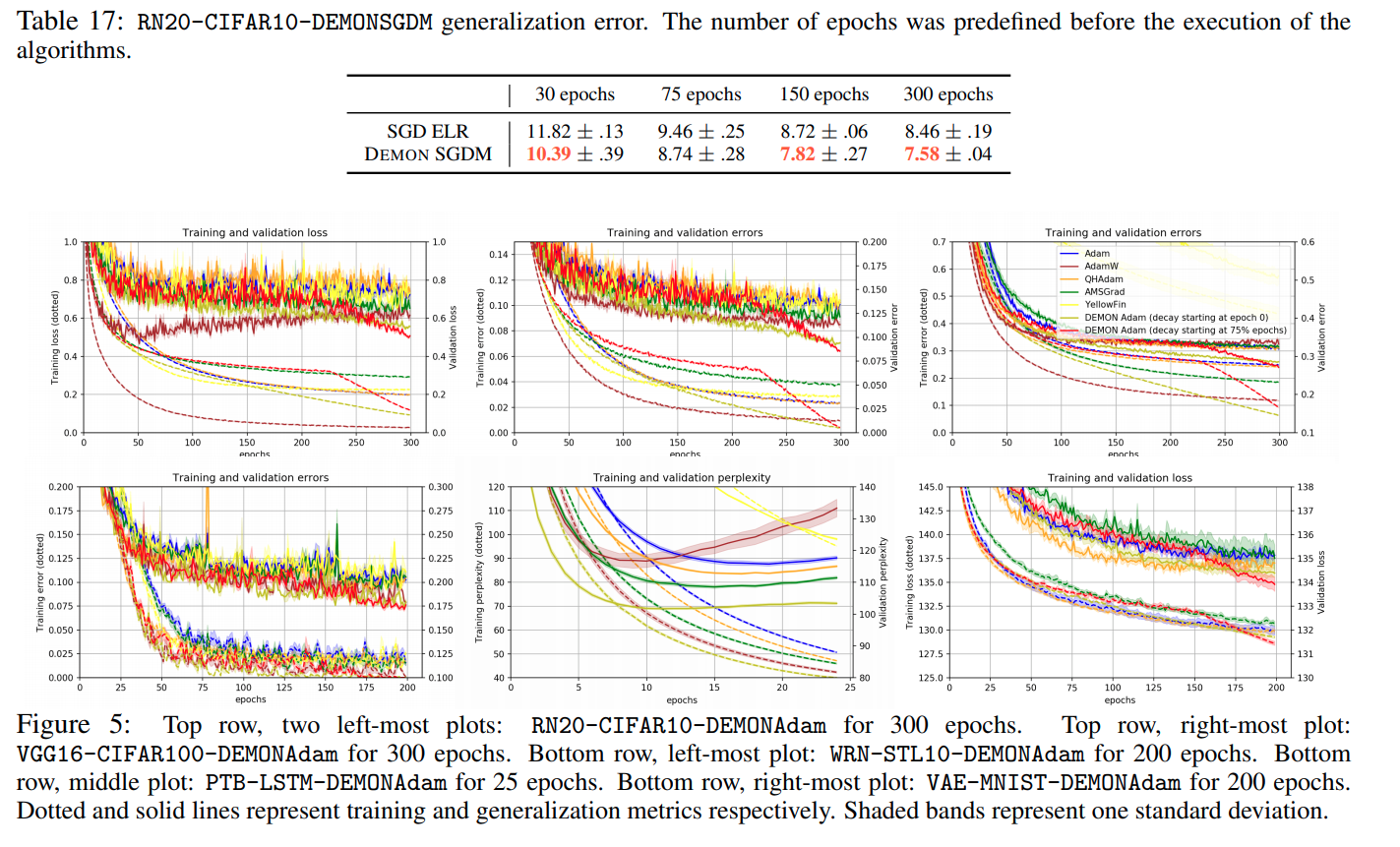
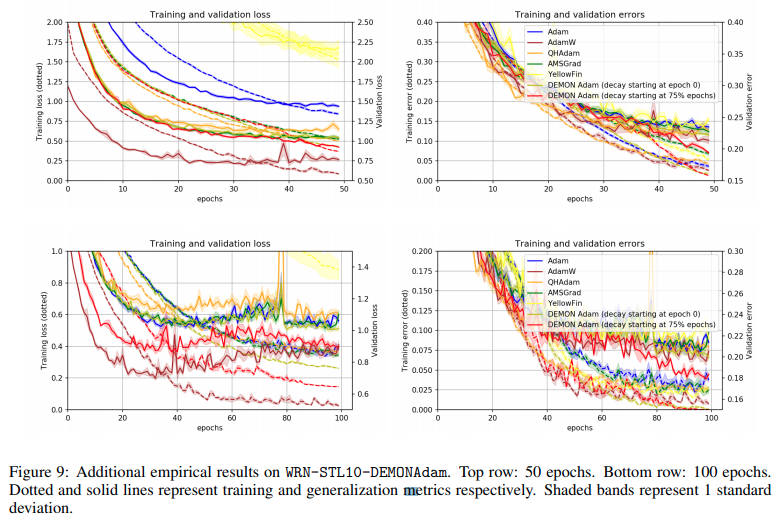
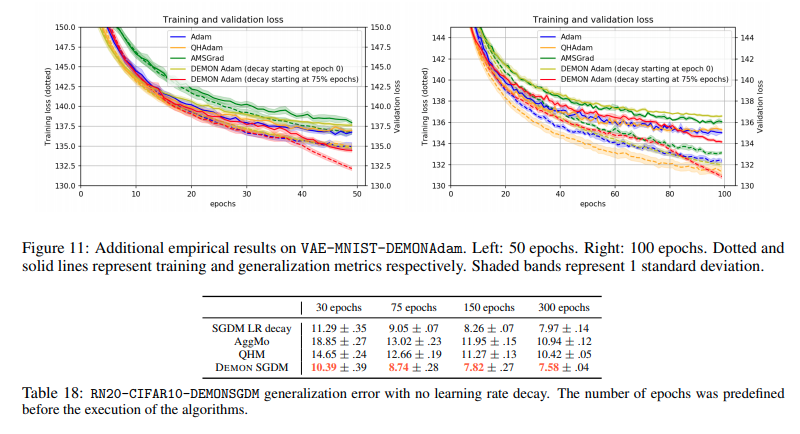
Trên đây là một vài kết quả được report trong paper. Các tác giả đã thực hiện rất nhiều thí nghiệm với nhiều tham số khác nhau để có thể tìm ra params tốt nhất với các task. DEMON được thử nghiệm với setting về 0 bắt đầu từ epoch đầu tiên hoặc 3/4 epoch. Các kết quả thí nghiệm được report cụ thể hơn trong paper, bạn đọc có thể tham khảo để biết rõ hơn.
Tổng kết
Momentum decay có kết quả tốt khi training mô hình và được thử nghiệm với các bài toán phân loại ảnh, mô hình sinh, mô hình ngôn ngữ. Khi sử dụng DEMON, mô hình nhìn chung ít nhạy cảm hơn khi tune chỉnh tham số.
Mình có thử nghiệm optimizer này trên tập CIFAR10, tuy nhiên kết quả lại thấy không chênh quá nhiều 
Nguyên nhân có thể do sử dụng community code TF, Torch hoặc số lượng epoch chưa đủ nhiều chăng?
Code Colab tham khảo
Cảm ơn các bạn đã đọc bài.
P/s: sau này mình mới phát hiện tác giả có share bản implement gốc tại openreview. Nếu có điều kiện mình sẽ thử và update lại sau
Tham khảo
[1] Demon: Momentum Decay for Improved Neural Network Training
All rights reserved
