
Xây dựng hệ thống gợi ý đơn giản với Keras
Bài đăng này đã không được cập nhật trong 7 năm
Hệ Thống Gợi Ý
Với sự phát triển cực kỳ mạnh mẽ của internet trong những năm gần đây. Mọi người có xu hướng sử dụng mạng xã hội để mua những mặt hàng cần thiết mà không mất thời gian đi ra ngoài lựa chọn. Vì vậy, thương mại điện tử cũng phát triển theo. Việc ứng dụng trí tuệ nhân tạo cũng góp phần tăng doanh thu cho các trang thương mại điện tử, ví dụ áp dụng hệ thống gợi ý. Hệ thống gợi ý (Recommender systems hoặc Recommendation systems) là một dạng của hệ hỗ trợ ra quyết định, cung cấp giải pháp mang tính cá nhân hóa mà không phải trải qua quá trình tìm kiếm phức tạp. Hệ gợi ý học từ hành vi trước đây của người dùng và gợi ý các sản phẩm tốt nhất trong số các sản phẩm phù hợp. Có rất nhiều bài viết về việc tạo mô hình gợi ý đơn giản theo Content-based hoặc Collaborative Filtering viết bằng python. Hôm nay, ở bài viết này mình sẽ demo một hệ thống gợi ý đơn giản với Deep Learning bằng Keras. Cùng thực hiện nhé!
Cài đặt Keras
Trước khi bắt đầu, chúng ta phải cài đặt keras. Ở đây mình sử dụng jupyter notebook của anaconda nhé. Mở cửa sổ command của anaconda và thực hiện như dưới đây.
$ pip install keras
$ pip install tensorflow
Để kiểm tra đã cài đặt thành công chưa bạn thực hiện lệnh:
$ pip show keras
Mọi người có thể tham khảo bài viết về cách tiếp cận keras của tác giả Hoang Dinh Thoi.
Thực hiện Model
Dataset
Trong bài viết này mình sử dụng tập Movielens 100K của Grouplens: bao gồm user_id, item_id, rating và timestamp. Các bạn có thể Download tại đây. Đọc dataset:
dataset = pd.read_csv("ml-100k/u.data",sep='\t',names="user_id,item_id,rating,timestamp".split(",")) dataset.head()
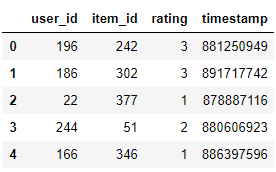
Do tập data này đã được làm sạch nên sẽ không cần qua bước làm sạch hay tiền xử lý dữ liệu nữa. Sau khi đọc dữ liệu, chia tập data thành 2 phần train và test nhé.
from sklearn.model_selection import train_test_split
train, test = train_test_split(dataset, test_size=0.2)
Tạo model
Keras rất dễ sử dụng để xây dựng model Deep Learning. Bên cạnh đó cũng dễ dàng để tạo embedding cho người dùng và những bộ phim cũng như có thể làm việc với nhiều đầu vào và đầu ra. Để ước tính được rating của mỗi user đối với mỗi bộ phim mình sẽ sử dụng Dot người dùng với embedding từng sản phẩm tương ứng. Sau đó có thể dự đoán user này thích bộ phim nào và ngược lại để gợi ý cho user một cách chính xác.
Trước khi thực hiện model chúng ta phải import package cần thiết:
import keras
from keras.layers import Input, Embedding, Flatten, Dot, Dense, Concatenate
from IPython.display import SVG
from keras.optimizers import Adam
from keras.utils.vis_utils import model_to_dot
n_users, n_movies = len(dataset.user_id.unique()), len(dataset.item_id.unique())
n_latent_factors = 3
Sau đó chúng ta thực hiện model sau:
movie_input = keras.layers.Input(shape=[1],name='Item')
movie_embedding = keras.layers.Embedding(n_movies + 1, n_latent_factors, name='Movie-Embedding')(movie_input)
movie_vec = keras.layers.Flatten(name='FlattenMovies')(movie_embedding)
user_input = keras.layers.Input(shape=[1],name='User')
user_vec = keras.layers.Flatten(name='FlattenUsers')(keras.layers.Embedding(n_users + 1, n_latent_factors,name='User-Embedding')(user_input))
prod = Dot(name="Dot-Product", axes=1)([movie_vec, user_vec])
model = keras.Model([user_input, movie_input], prod)
model.compile('adam', 'mean_squared_error')
- input: Đầu vào cho cả movie và user
- embedding layers: embedding cho cả movie và user
- Dot: Dùng để kết hợp embedđing của user và movie
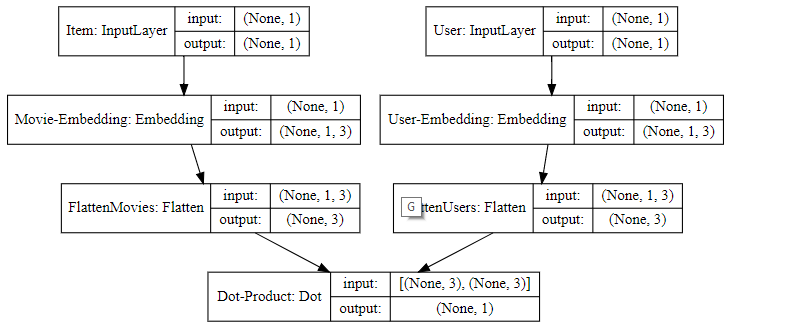
Visualize
Chúng ta thực hiện lệnh sau đây để visualisation model
SVG(model_to_dot(model, show_shapes=True, show_layer_names=True, rankdir='HB').create(prog='dot', format='svg'))
Cấu trúc mạng neural network như sau:
Train Model
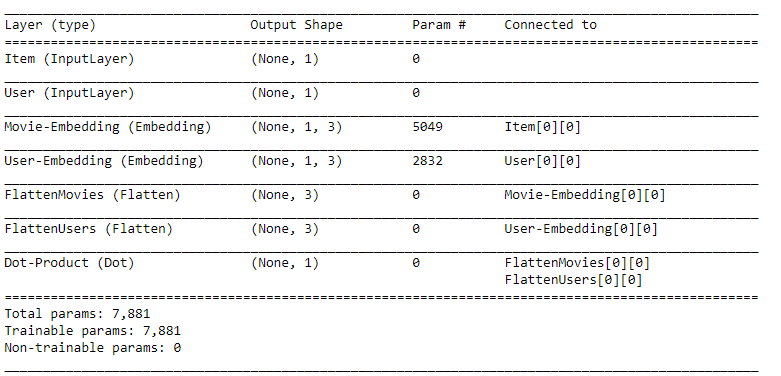
Khi chúng ta sử dụng lệnh summary: Input:
model.summery()
Output: Chúng ta có 7881 tham số
Thực hiện train model, ở đây mình để epochs=10 cho nhanh nhé, mọi người có thể tăng giá trị epochs lên tùy ý.
history = model.fit([train.user_id, train.item_id], train.rating, epochs=10, verbose=0)
Tiếp theo chúng ta sẽ giới thiệu phim cho người dùng nhé. Chúng ta sẽ lấy ra những bộ phim mà có giá trị dự đoán cao nhất để gợi ý cho user.
movie_data = np.array(list(set(dataset.item_id)))
user = np.array([1 for i in range(len(movie_data))])
predictions = model.predict([user, movie_data])
predictions = np.array([a[0] for a in predictions])
recommended_movie_ids = (-predictions).argsort()[:5]
print(recommended_movie_ids)
print(predictions[recommended_movie_ids])
output:
[1391 1588 1590 1431 1519] [9.892052 7.8635187 7.5646224 6.81038 6.7250285]
Bây giờ chúng ta sẽ lấy ra thông tin chi tiết từng bộ phim:
m_cols = ['movie_id', 'title', 'release_date', 'video_release_date', 'imdb_url']
movies = pd.read_csv('ml-100k/u.item', sep='|', names=m_cols, usecols=range(5), encoding='latin-1') movies.head()
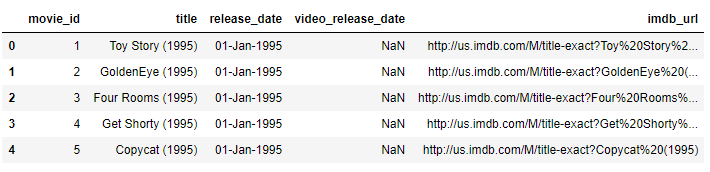
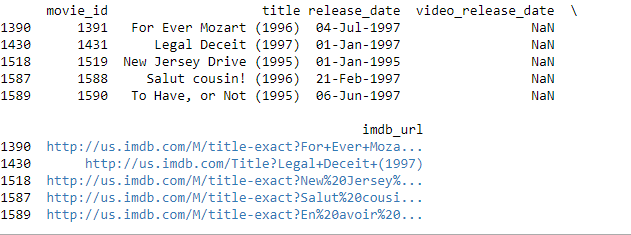
Print ra những bộ phim có trong recommended_movie_ids
print(movies[movies['movie_id'].isin(recommended_movie_ids)])
Output:
Kết Luận
Có rất nhiều phương pháp để xây dựng một hệ thống gợi ý. Tuy nhiên embedding là một phương pháp ánh xạ từ các giá trị rời rạc và rất có ích trong việc tính similarity hay mục đích trực quan hóa. Đối với bài toán đơn giản này có thể không tốt bằng các phương pháp khác, nhưng khi sử dụng neural network để xây dựng nhiều bài toán khác lại tốt hơn.
All rights reserved
