Tìm hiểu về Convolutional Neural Networks (CNN)
Bài đăng này đã không được cập nhật trong 4 năm
1. Giới thiệu về CNN
CNN là kiến trúc lý tưởng khi giải quyết vấn đề dữ liệu hình ảnh, một trong những mô hình Deep Learning tiên tiến. Nó giúp cho chúng ta xây dựng được những hệ thống thông minh với độ chính xác cao như hiện nay. CNN được sử dụng nhiều trong các bài toán nhận dạng các object trong ảnh.
Tại sao CNN được sử dụng để xử lý hình ảnh?
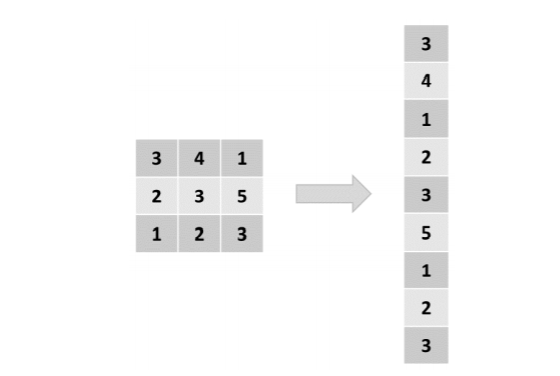
- Một hình ảnh là một ma trận các pixel, nhưng người ta thường không biến đổi ma trận thành một vector và xử lý nó bằng cách sử dụng kiến trúc mạng nơ-ron truyền thống. Lý do là vì ngay cả với hình ảnh đơn giản nhất, các pixel liền kề có sự phụ thuộc lần nhau, việc biến đổi thành vector sẽ làm mất đi thông tin phụ thuộc này và làm thay đổi ý nghĩa của bức hình. Ví dụ, biểu tượng của mắt mèo, lốp xe ô tô hoặc thậm chí là cạnh của một đối tượng được xây dựng từ một số pixel được bố trí theo một cách nhất định. Nếu chúng ta xử lý hình ảnh thành một vector, những phụ thuộc này bị mất và làm giảm độ chính xác của mô hình.
- CNN có khả năng ghi lại sự phụ thuộc không gian của hình ảnh kể từ khi nó xử lý chúng dưới dạng ma trận và phân tích toàn bộ các phần của một hình ảnh tại một thời điểm, tùy thuộc vào kích thước của bộ lọc. Ví dụ: một lớp lọc (convolutional layer) có kích thước 3 x 3 sẽ phân tích 9 điểm ảnh tại một thời điểm cho đến khi nó bao phủ toàn bộ hình ảnh.
- Mỗi phần của hình ảnh được cung cấp một tập hợp các tham số (chiều rộng và độ lệch) sẽ tham chiếu mức độ liên quan của tập hợp pixel đó với toàn bộ hình ảnh, tùy thuộc vào bộ lọc. Theo điều này, bằng cách giảm số lượng các tham số và bằng cách phân tích hình ảnh theo từng phần, CNN có thể hiển thị đại diện tốt hơn của hình ảnh.
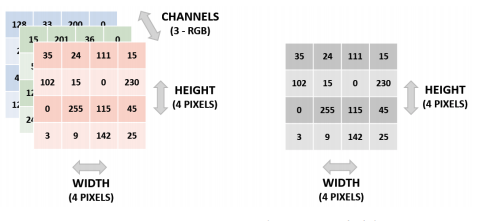
- Mỗi giá trị của ma trận đại diện cho một pixel trong hình ảnh, trong đó số được xác định bởi cường độ của màu, với các giá trị nằm trong khoảng từ 0 đến 255. Thang độ xám, pixel trắng được biểu thị bằng số 255 và pixel đen bằng số 0. Pixel xám là bất kỳ số nào ở giữa, tùy thuộc vào cường độ của màu sắc,màu xám càng nhạt, con số càng gần 255. Hình ảnh có màu thường được biểu diễn bằng hệ thống RGB, hệ thống này đại diện cho mỗi màu là sự kết hợp của đỏ, xanh lá cây và xanh lam. Ở đây, mỗi pixel sẽ có ba kích thước, một cho mỗi màu. Các giá trị trong mỗi thứ nguyên sẽ nằm trong khoảng từ 0 đến 255. Ở đây, màu càng đậm, con số càng gần 255. Ở đây, kích thước đầu tiên đề cập đến chiều cao của hình ảnh (trong số pixel), kích thước thứ hai đề cập đến chiều rộng của hình ảnh (trong số pixel) và thứ nguyên thứ ba được gọi là kênh và đề cập đến bảng màu của hình ảnh. Số kênh cho hình ảnh màu là ba (một kênh cho mỗi màu trong Hệ thống RGB). Mặt khác, hình ảnh tỷ lệ xám chỉ có một kênh:
2. Cấu trúc mạng CNN
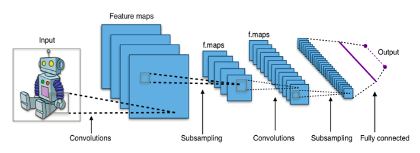
- Mạng CNN là một tập hợp các lớp tích chập chồng lên nhau và sử dụng các hàm nonlinear activation như ReLU và tanh để kích hoạt các trọng số trong các node. Mỗi một lớp sau khi thông qua các hàm kích hoạt sẽ tạo ra các thông tin trừu tượng hơn cho các lớp tiếp theo.
- Mỗi một lớp sau khi thông qua các hàm kích hoạt sẽ tạo ra các thông tin trừu tượng hơn cho các lớp tiếp theo. Trong mô hình mạng truyền ngược (feedforward neural network) thì mỗi neural đầu vào (input node) cho mỗi neural đầu ra trong các lớp tiếp theo. Mô hình này gọi là mạng kết nối đầy đủ (fully connected layer). Còn trong mô hình CNNs thì ngược lại. Các lớp liên kết được với nhau thông qua cơ chế tích chập. Lớp tiếp theo là kết quả phép tính tích chập từ lớp trước đó, nhờ vậy mà ta có được các kết nối cục bộ. Như vậy mỗi neuron ở lớp kế tiếp sinh ra từ kết quả của filter áp đặt lên một vùng ảnh cục bộ của neuron trước đó. Mỗi một lớp được sử dụng các filter khác nhau thông thường có hàng trăm hàng nghìn filter như vậy và kết hợp kết quả của chúng lại. Ngoài ra có một số lớp khác như pooling/subsampling lớp dùng để chắt lọc lại các thông tin hữu ích hơn. Trong quá trình huấn luyện mạng (traning) CNN tự động học các giá trị qua các lớp filter. Ví dụ trong tác vụ phân lớp ảnh, CNNs sẽ cố gắng tìm ra thông số tối ưu cho các filter tương ứng theo thứ tự raw pixel > edges > shapes > facial > high-level features. Lớp cuối cùng được dùng để phân lớp ảnh.
3. Ứng dụng của CNN
- Mặc dù CNN chủ yếu được sử dụng cho các vấn đề về computer vision, nhưng điều quan trọng là đề cập đến khả năng giải quyết các vấn đề học tập khác của họ, chủ yếu liên quan đến tích chuỗi dữ liệu. Ví dụ: CNN đã được biết là hoạt động tốt trên chuỗi văn bản, âm thanh và video, đôi khi kết hợp với các mạng khác quả cầu kiến trúc hoặc bằng cách chuyển đổi các chuỗi thành hình ảnh có thể được xử lý của CNN. Một số vấn đề dữ liệu cụ thể có thể được giải quyết bằng cách sử dụng CNN với chuỗi dữ liệu là các bản dịch văn bản bằng máy, xử lý ngôn ngữ tự nhiên và gắn thẻ khung video, trong số nhiều người khác.
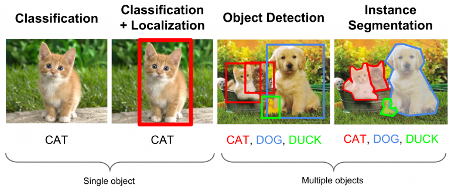
Classification: Đây là nhiệm vụ được biết đến nhiều nhất trong computer vision. Ý tưởng chính là phân loại nội dung chung của hình ảnh thành một tập hợp các danh mục, được gọi là nhãn. Ví dụ: phân loại có thể xác định xem một hình ảnh có phải là của một con chó, một con mèo hay bất kỳ động vật khác. Việc phân loại này được thực hiện bằng cách xuất ra xác suất của hình ảnh thuộc từng lớp, như được thấy trong hình ảnh sau:

Localization: Mục đích chính của localization là tạo ra một hộp giới hạn mô tả vị trí của đối tượng trong hình ảnh. Đầu ra bao gồm một nhãn lớp và một hộp giới hạn. Tác vụ này có thể được sử dụng trong cảm biến để xác định xem một đối tượng ở bên trái hay bên phải của màn hình:

Detection: Nhiệm vụ này bao gồm thực hiện localization trên tất cả các đối tượng trong ảnh. Các đầu ra bao gồm nhiều hộp giới hạn, cũng như nhiều nhãn lớp (một cho mỗi hộp). Nhiệm vụ này được sử dụng trong việc chế tạo ô tô tự lái, với mục tiêu là có thể xác định vị trí các biển báo giao thông, đường, ô tô khác, người đi bộ và bất kỳ đối tượng nào khác có thể phù hợp để đảm bảo trải nghiệm lái xe an toàn:

Segmentation: Nhiệm vụ ở đây là xuất ra cả nhãn lớp và đường viền của mỗi đối tượng hiện diện trong hình ảnh. Điều này chủ yếu được sử dụng để đánh dấu các đối tượng quan trọng của hình ảnh cho phân tích sâu hơn. Ví dụ: tác vụ này có thể được sử dụng để phân định rõ ràng khu vực tương ứng với khối u trong hình ảnh phổi của bệnh nhân. Hình sau mô tả cách vật thể quan tâm được phác thảo và gán nhãn:

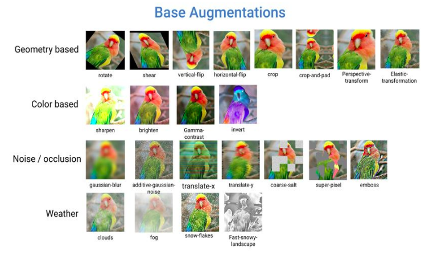
4. Tăng cường dữ liệu (Data Augmentation)
Hiện nay trong deep learning thì vấn đề dữ liệu có vai trò rất quan trọng. Chính vì vậy có những lĩnh vực có ít dữ liệu để cho việc train model thì rất khó để tạo ra được kết quả tốt trong việc dự đoán. Do đó người ta cần đến một kỹ thuật gọi là tăng cường dữ liệu (data augmentation) để phục vụ cho việc nếu có ít dữ liệu. Phương thức data aumentation cơ bản:


Flip (Lật): lật theo chiều dọc, ngang miễn sao ý nghĩa của ảnh (label) được giữ nguyên hoặc suy ra được. Ví dụ nhận dạng quả bóng tròn, thì lật kiểu gì cũng ra quả bóng. Còn với nhận dạng chữ viết tay, lật số 8 vẫn là 8, nhưng 6 sẽ thành 9 (theo chiều ngang) và không ra số gì theo chiều dọc.
Random crop (Cắt ngẫu nhiên): cắt ngẫu nhiên một phần của bức ảnh. Lưu ý là khi cắt phải giữ thành phần chính của bức ảnh mà ta quan tâm. Như ở nhận diện vật thể, nếu ảnh được cắt không có vật thể, vậy giá trị nhãn là không chính xác.
Color shift (Chuyển đổi màu): Chuyển đổi màu của bức ảnh bằng cách thêm giá trị vào 3 kênh màu RGB. Việc này liên quan tới ảnh chụp đôi khi bị nhiễu --> màu bị ảnh hưởng.
Noise addition (Thêm nhiễu): Thêm nhiễu vào bức ảnh. Nhiễu thì có nhiều loại như nhiễu ngẫu nhiên, nhiễu có mẫu, nhiễu cộng, nhiễu nhân, nhiễu do nén ảnh, nhiễu mờ do chụp không lấy nét, nhiễu mờ do chuyển động… có thể kể hết cả ngày.
Information loss (Mất thông tin): Một phần của bức hình bị mất. Có thể minh họa trường hợp bị che khuất.
Constrast change (Thay đổi độ tương phản): thay độ tương phản của bức hình, độ bão hòa.
Tài liệu tham khảo
- Hyatt Saleh, “The Machine Learning Workshop”, Packt Publishing, 2020
All rights reserved
