
[B5'] Shake-Shake Regularization and Shake-Drop Regularization for Deep Residual Network
Bài đăng này đã không được cập nhật trong 5 năm
Khi overfit xảy ra, một trong các biện pháp hiệu quả là tăng cường lượng data học (train data). Các phương pháp phổ biến hiện nay bao gồm Data augmentation, Adversarial traning thực hiện thêm dữ liệu với Input đầu vào hoặc 1 phương pháp gần đây là Label smoothing và MixCut thực hiện cả augmentation cho Label. Từ ý tưởng này, Xavier Gastaldi đã nghĩ ra kỹ thuật ứng dụng augmentation với các internal representation (hay có thể hiểu là feature space) với Shake-shake regularization áp dụng với họ kiến trúc nhà ResNet. Hãy cùng tìm hiểu nhé!
1. Shake-Shake Regularization
Kiến trúc mạng ResNet nhánh thông thường
trong đó là input, là output
là hàm Residual Aggregated Transformations
và lần lượt là các weight với các khối residual tương ứng
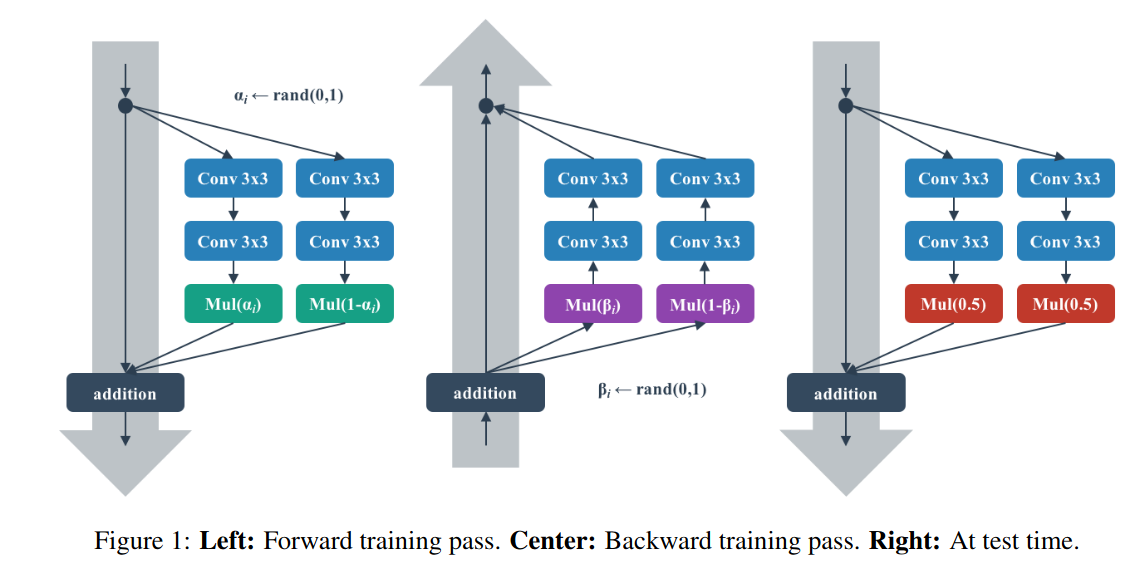
Shake-Shake regularization sẽ có thêm 1 tham số scaling coefficient
trong đó sẽ là biến ngẫu nhiêu theo uniform distribution (0, 1)
Note: Với tập test, = 0.5 sẽ cho kết quả như một lớp Dropout(0.5) thông thường
Tham số được thay đổi với các giá trị ngẫu nhiên theo distribution trước khi thực hiện lượt backward pass tiếp theo. Từ đó tạo kết quả ngẫu nhiên giữa các lần backward pass và forward pass trong quá trình traning, làm giảm khả năng học thuộc dữ liệu của model. Tác giả cũng đề cập có thể hiểu đây là 1 dạng của gradient augmentation.
2. Phân tích kết quả
Khi training, tác giả có đề xuất 1 số mode để thử nghiệm
Shake: random tất cả coefficient (random ) trước khi forward pass
Even: scaling coefficient đặt bằng 0.5 trước forward pass
Keep: trong quá trình backward pass, scaling coefficient giữ nguyên với forward pass
Mức độ áp dụng:
Cấp độ Batch: giá trị scaling coefficient trong mỗi batch giống nhau
Cấp độ Image: giá trị scaling coefficient khác nhau trong mỗi điểm dữ liệu (ảnh)
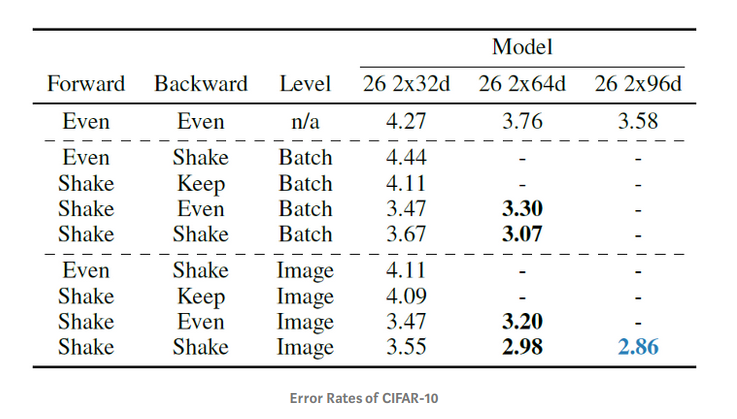
Kết quả trên tập CIFAR10
Kết quả trên tập CIFAR100

Nhìn chung với mô hình shake với forward và shake với backward cho kết quả tốt nhất trên tập CIFAR10 với Error rate thấp hơn khá nhiều (chỉ 2.86). Có lẽ vì lý do này nên tác giả đặt tên là Shake-Shake (Forward - Backward)
So sánh với các SOTA khác
 Với Shake-Shake regularization, model có error rate thấp hơn khá nhiều so với các mô hình trước đó.
Với Shake-Shake regularization, model có error rate thấp hơn khá nhiều so với các mô hình trước đó.
3. Shake-Drop Regularization
Shake-Shake regularization tuy có kết quả rất tốt nhưng vẫn tồn tại 1 số điểm yếu
- được thiết kế cho mạng ResNet cấu trúc 3 nhánh (ResNeXt)
- nguyên nhân thực sự về độ hiệu quả chưa được làm rõ
Yoshihiro Yamada và các đồng nghiệp đã áp dụng một phương pháp để nâng cấp khả năng ứng dụng của Shake-Shake
Cụ thể, nhóm nghiên cứu đã thêm RandomDrop (hay ResDrop) vào trong mạng. RandomDrop có thể hiểu là dạng đơn giản của Dropout, tuy nhiên RandomDrop thực hiện drop layer thay vì các node như Dropout
Kiến trúc mạng Resnet:
Random Drop:
trong đó là biến ngẫu nhiên Bernoulli với xác suất
được chọn với = 0.5
Phương pháp tác giả đề xuất ShakeDrop:
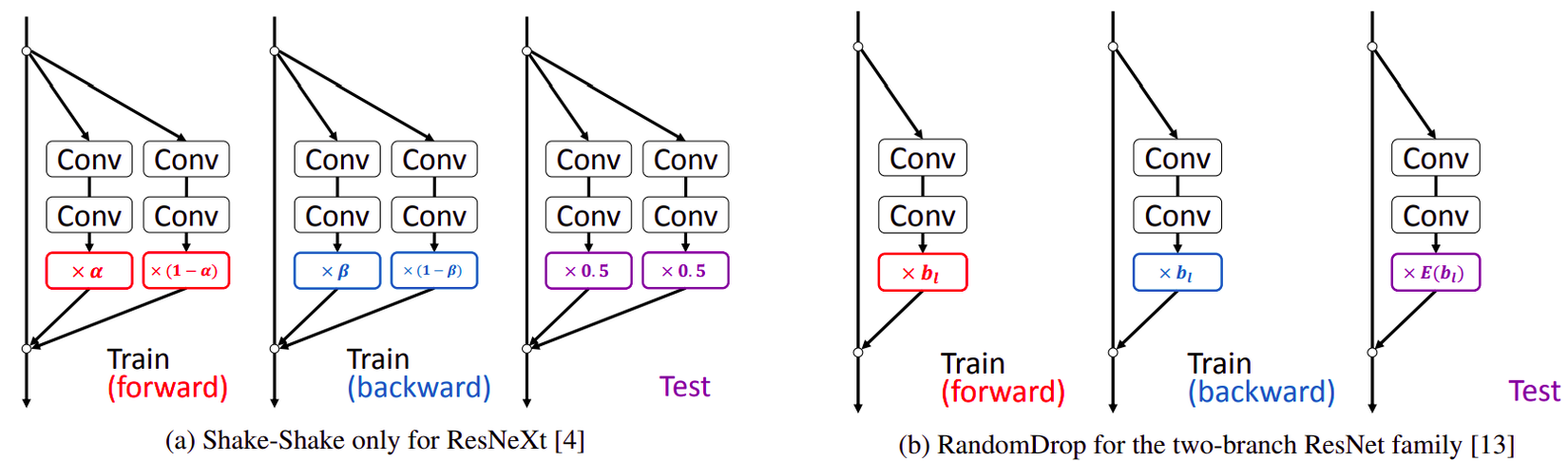
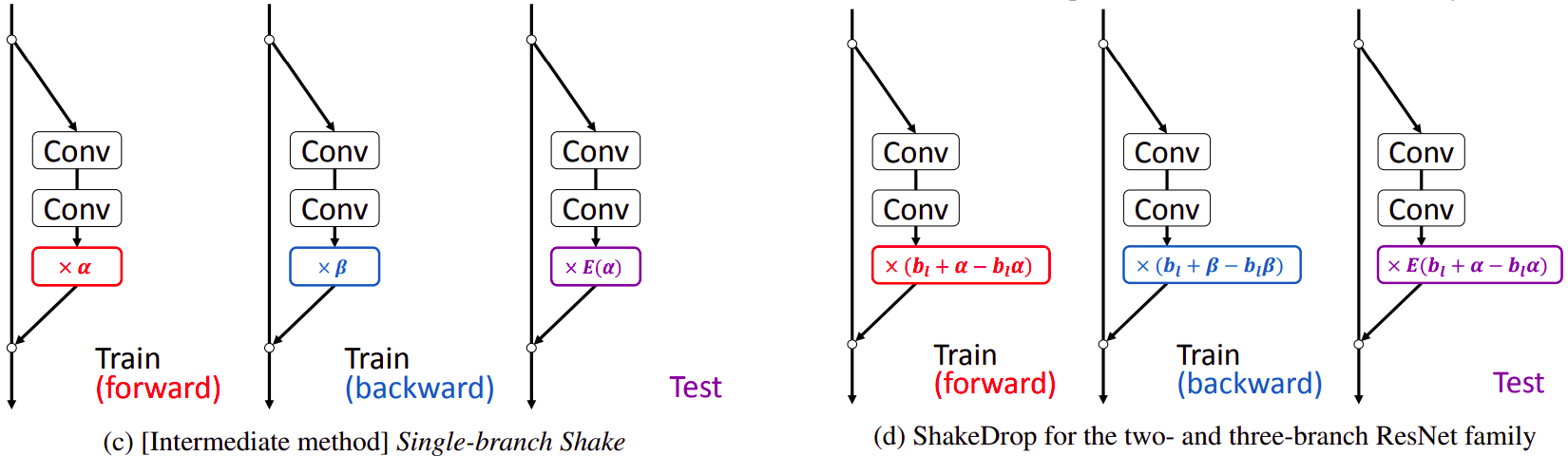
Phương pháp regularization cho mạng ResNet. a) và b) là các phương pháp được sử dụng trước đây như Shake-Shake và RandomDrop
c) là phương pháp regularization đơn giản 1 nhánh với đạo hàm của d)
“Conv” thể hiện lớp convolution; E[x] là giá trị expected của x; với , và là tham số coefficients ngẫu nhiên
4. Thí nghiệm
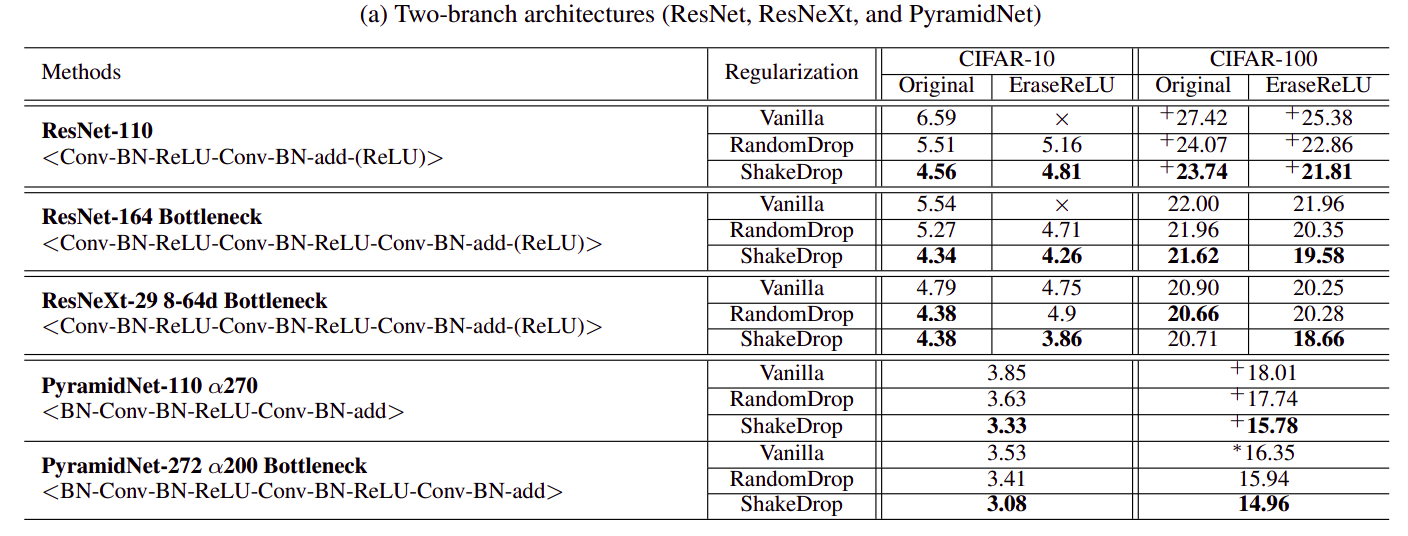
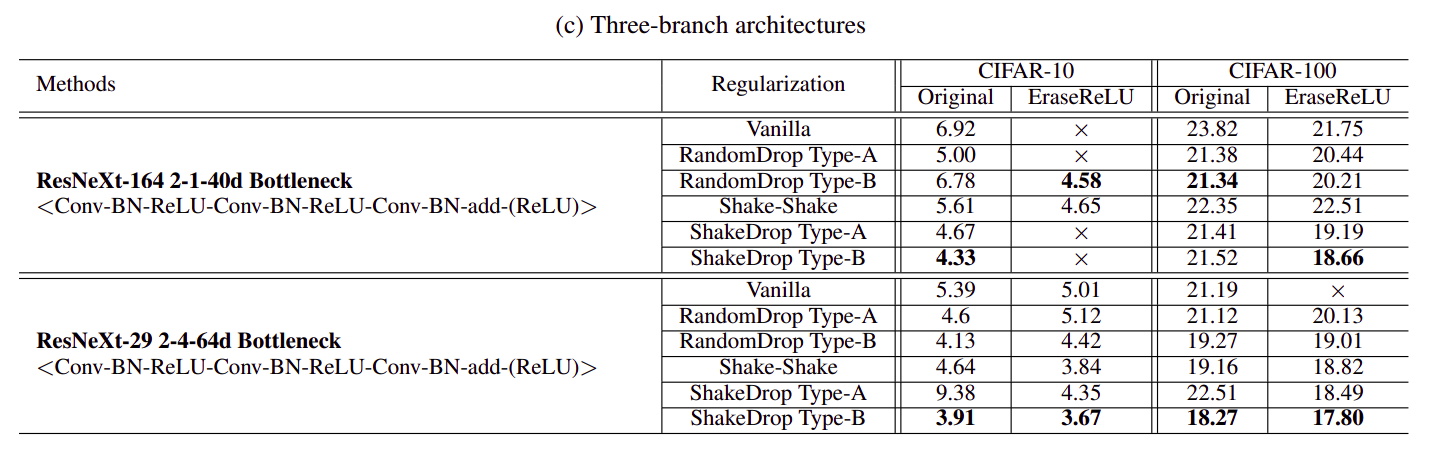
Theo thí nghiệm, ShakeDrop phù hợp nhất với PyramidNet khi thu được error rate 3.08 trên tập CIFAR-10 và 14.96 trên tập CIFAR-100. ShakeDrop cũng cho kết quả tốt hơn khi cùng áp dụng với mô hình 3 nhánh ResNeXt.
5. Kết luận
ShakeDrop là phương pháp stochastic regularization có thể được ứng dụng cho mạng ResNet nhằm hạn chế quá trình overfit. Qua các thí nghiệm, tác giả đã chứng minh được ShakeDrop có performance tốt hơn các phương pháp trước đó (Shake-Shake và RandomDrop). Các bạn có thể tham khảo paper gốc ShakeDrop để có thể xem thêm kết quả thí nghiệm của tác giả trên các mạng ResNeXt, Wide-ResNet, PyramidNet với các layer khác nhau trên các tập dữ liệu ImageNet, COCO mà mình chưa đề cập trong bài Viblo này.
Cảm ơn các bạn đã đọc bài!
Reference
All rights reserved
