
[Paper Explain] Thủ thuật làm tăng độ chính xác cho các mạng Object Detection
Bài đăng này đã không được cập nhật trong 4 năm
Lời mở đầu
Object Detection là một trong những vấn đề căn bản nhất trong Computer Vision. Các mạng Object Detection, kể cả là một pha (SSD, YOLO,...) hay là hai pha (họ R-CNN), đều dựa trên một backbone từ một mạng Classification như VGG, ResNet, MobileNet,... Mặc dù có tốc độ phát triển cực nhanh và đạt được những thành công lớn, nhưng các mạng Object Detection đều sử dụng các cách thức xử lý dữ liệu và quá trình training khác nhau.
Trong bài hôm nay, ta sẽ khám phá các kĩ thuật hiệu quả áp dụng được lên toàn bộ các mạng Object Detection mà không hề làm tăng thời gian xử lý của mạng.
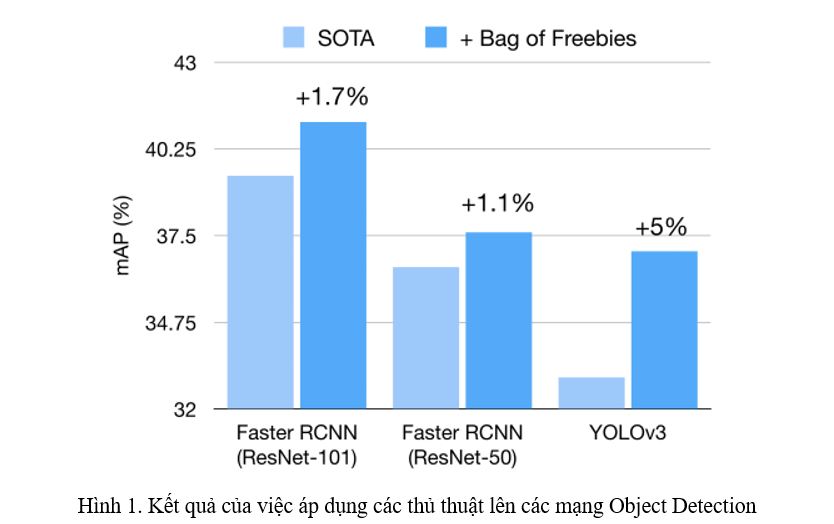
Bag of Freebies
Các kĩ thuật áp dụng dưới đây sẽ không hề làm tăng thời gian xử lý của mạng Object Detection vì vậy được gọi là Bag of Freebies.
Viusally Coherent Image MixUp for Object Detection
MixUp là một kĩ thuật Augmentation cực kì thành công trong Classification. Ý tưởng chính của MixUp trong bài toán Classification sẽ là trộn lẫn pixel thông qua nội suy giữa 2 ảnh. Cùng lúc đó, one-hot label của ảnh sẽ được biến đổi tương đương theo tỉ lệ trộn lẫn. Ý tưởng của MixUp được thể hiện trong Hình 2.

Phân phối của tỉ lệ trộn lẫn trong MixUp tuân theo phân phối . Rosenfeld et al. [1] đã có một thử nghiệm khá là thú vị, đặt tên là "Elephant in the room" (con voi trong phòng). Thử nghiệm cắt hình ảnh một con voi, đặt vào trong một cái phòng chung với các object khác. Kết quả thử nghiệm cho thấy, mặc dù với một object detection đã được train để có thể nhận diện con voi, nhưng khi đặt con voi trong phòng thì kết quả là rất khó để nhận diện con voi. Hơn nữa, sự xuất hiện của con voi ở một số địa điểm còn làm cho các object khác cũng không thể được nhận diện, thậm chí là nhận diện sai object mà trước đó đã được nhận diện đúng (Hình 4).

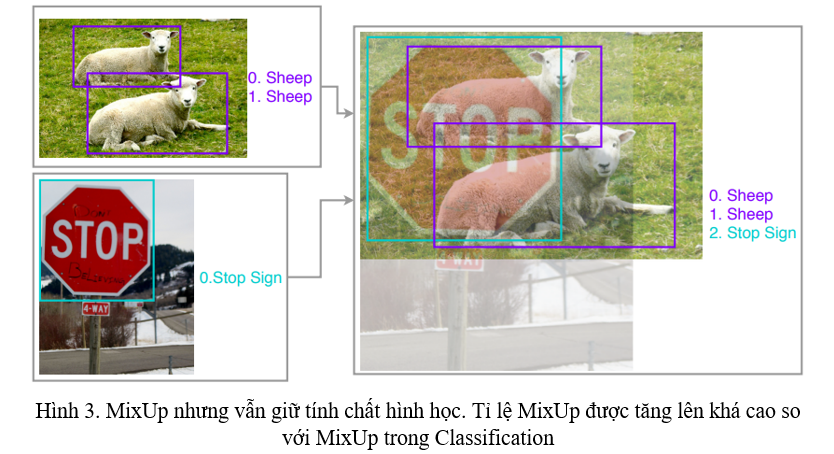
Lấy ý tưởng từ thử nghiệm trên, tác giả của paper tập trung vào sự đồng tồn tại của object. Bằng việc áp dụng một biến đổi về không gian một cách phức tạp, tác giả tạo ra occlusion, một sự nhiễu loạn về không gian. Tác giả tăng tỉ lệ pha trộn của MixUp, các object xuất hiện ở trong ảnh trở nên sống động và mạch lạc hơn so với thông thường, giống với việc chuyển đổi giữa các frames khi xem một đoạn clip với FPS thấp hơn (Hình 3). Cụ thể hơn, tác giả sử dụng MixUp nhưng vẫn giữ được tính chất hình học của chúng. Tác giả còn chọn tỉ lệ MixUp tuân theo phân phối Beta với và ít nhất là .
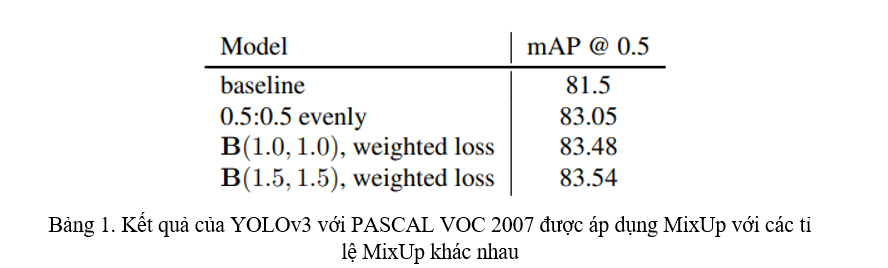
Kết quả thử nghiệm MixUp được thể hiện ở Bảng 1. Nhóm tác giả rút ra nhận xét rằng, trong Object Detection khi thường xuyên xuất hiện các hiện tượng occlusion, các mạng Object Detection sẽ tập trung vào các nơi có nhiều object tụ lại, kể cả là tự nhiên hay nhân tạo do sử dụng các phép biến đổi.
Để kiểm chứng độ hiệu quả của MixUp, tác giả tiến hành lại thí nghiệm "Elephant in the room" lên YOLOv3. Nhìn Hình 5, ta có thể thấy, model train mà không sử dụng MixUp gặp rất nhiều khó khăn trong việc phát hiện một con voi trong phòng bếp do con voi được đặt lên trùng các object khác (hiện tượng occlusion) và model học thiếu ngữ cảnh, do một con voi trong phòng bếp là một hiện tượng khó mà xảy ra. Ngược lại, model được train với MixUp có thể phát hiện được con voi do ta tạo ra các ngữ cảnh giả với MixUp. Tuy nhiên, model được training với MixUp cũng đưa ra kết quả dự đoán kém tự tin hơn, nhưng vẫn đủ tự tin để kết quả evaluation không bị giảm.

Label Smoothing cho Classification head
Đây là một kĩ thuật khá đơn giản mà hiệu quả, được sử dụng cả trong Classification mà mình đã có nhắc đến ở đây.
Label Smoothing là kĩ thuật làm mượt label có dạng one-hot theo công thức sau:
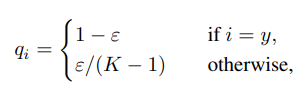
với là số class và là một hằng số nhỏ do ta chọn. Kĩ thuật này làm giảm sự tự tin thái quá của model, làm giảm khả năng overfit.
Xử lý dữ liệu
Trong Classification, mạng nơ-ron thường được khuyến khích sử dụng các biến đổi làm biến dạng cả thông tin về không gian như flip, rotate, crop,... để tăng khả năng generalized và giảm overfitting của model. Tuy nhiên, trong Object Detection, ta phải cẩn thận khi sử dụng chúng vì do đặc tính của vấn đề nên các mạng Object Detection khá nhạy cảm với những thay đổi như vậy.
Tác giả thử nghiệm một số phương pháp data augmentations như sau:
- Biến đổi hình học ngẫu nhiên: Bao gồm random crop (với một số giới hạn), random expansion, random horizontal flip và random resize.
- Thay đổi màu sắc: Bao gồm brightness, hue, saturation và contrast.
Đối với mạng Object Detection 2 pha (họ nhà R-CNN), tác giả không sử dụng random crop vì pha đầu tiên, lấy ra các proposal regions, đã thay thế random crop.
Thay đổi training schedule
Phần này mình cx đã có bài phân tích ở đây, paper này chỉ tập trung nói về learning rate decay và warmup. Mình khá lười và ý tưởng cũng giống y hệt nên mình xin phép không viết lại phần này nhé 
Sử dụng các size ảnh khác nhau trong training cho các mạng một pha
Các ảnh trong lúc training sẽ có các size khác nhau. Để phù hợp với sự thiếu hụt bộ nhớ và training theo batch một cách đơn giản, các mạng nơ-ron thường được train với một size ảnh cố định. Để giảm thiểu overfitting và cải thiện tính generalized của mạng, ta sử dụng nhiều size ảnh khác nhau trong training. Cụ thể hơn, một batch gồm ảnh sẽ có size là bội số của stride của mạng, ví dụ với stride là của YOLOv3, các batch ảnh sẽ có size thuộc
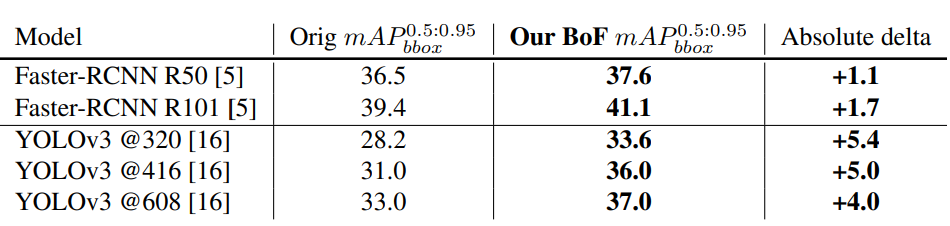
Kết quả
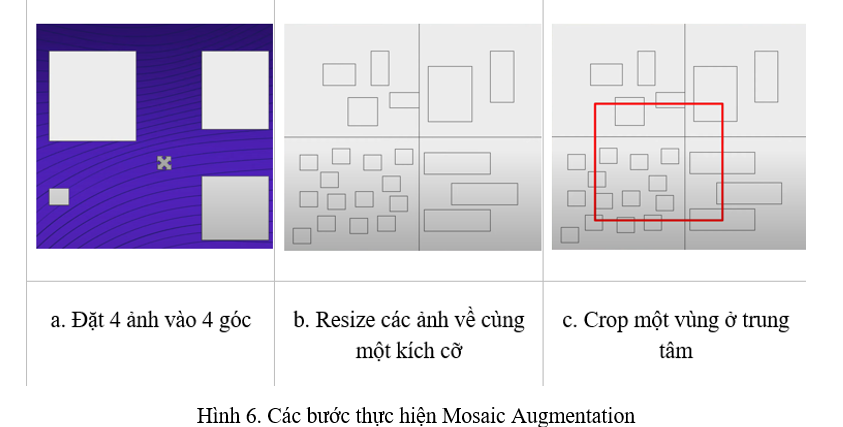
Mosaic Augmentation
Tuy k được nhắc tới trong paper nhưng đây là một kĩ thuật Data Augmentation cực kì mạnh trong Object Detection. Cá nhân mình đã sử dụng kĩ thuật này rất nhiều, độ hiệu quả và ổn định mà Mosaic Augmentation đem lại là rất cao. Mosaic Augmentation lần đầu được giới thiệu trong YOLOv4, do tác giả của YOLOv5 nghĩ ra
Các bước để thực hiện Mosaic Augmentation như sau:
- Chọn 4 ảnh ngẫu nhiên và cho 4 góc khác nhau của một hình vuông.
- Resize các ảnh đã chọn về cùng 1 kích cỡ và đặt chúng vào các góc khác nhau.
- Crop ra một vùng trung tâm ngẫu nhiên, vùng được crop sẽ là ảnh được sử dụng để đưa vào model
Các bạn có thể xem hình 6 để hiểu rõ hơn về các bước thực hiện Mosaic Augmentation.
Kết
Phía trên là những phân tích về một số các thủ thuật được sử dụng để làm tăng độ chính xác cho bài toán Object Detection. Trong paper còn có một số thủ thuật nữa nhưng mình không phân tích tới vì nó là thủ thuật liên quan tới dataset COCO và PASCAL VOC, cũng như là thủ thuật áp dụng lên dàn máy xịn xò có nhiều GPU, thứ mà đa số chúng ta không có được 
Hy vọng các bạn có thể áp dụng được những phương pháp nói trên vào các bài toán Object Detection của mình và đem lại hiệu quả tốt.
Reference
[1]. Amir Rosenfeld, Richard Zemel, John K. Tsotsos, "The Elephant in the Room", https://arxiv.org/abs/1808.03305
All rights reserved
