
[Image Segmentation] SINet: Extreme Lightweight Portrait Segmentation - SINet Paper Explaination and Coding Implementation
Bài đăng này đã không được cập nhật trong 5 năm
TIếp tục với series explain and implement paper đầy tâm huyết, hôm nay mình sẽ giới thiệu đến các bạn 1 paper mới của WACV 2020 (2020 Winter Conference on Applications of Computer Vision) đang xếp rank 1 về portrait segmentation trên tập EG1800 (theo PaperWithCode). Đây là một paper hay với sự thay đổi khá lớn so với các mô hình segment truyền thống, hãy cùng nhau tìm hiểu nhé.
Nội dung bài viết gồm những phần chính sau:
- Giới thiệu về mô hình segmentation
- Những khó khăn một mô hình segmentation gặp phải
- Một số mô hình segment phổ biến
- Giới thiệu mô hình SINET
- Giải thích chi tiết từng phần của kiến trúc SINET
- Coding và Training SINET from scratch với Keras
- Đánh giá mô hình SINET
- Bài học rút ra và hướng nghiên cứu trong tương lai
PS: Mọi thắc mắc các bạn vui lòng comment bên dưới bài hoặc gửi vào mail @nguyen.van.dat@sun-asterisk.com cho mình, mình sẽ cố gắng trả lời sớm nhất có thể nha. Và đừng quên Upvote cho mình nếu thấy có ích để mình có động lực viết những bài chất lượng hơn nữa.
I. Introduction
 Hình: Minh họa cho bài toán Image Recognition (top-left), Object Detection (bottom left) và Image segmentation (còn lại) (ảnh copy)
Hình: Minh họa cho bài toán Image Recognition (top-left), Object Detection (bottom left) và Image segmentation (còn lại) (ảnh copy)
Có lẽ đối với nhiều bạn tìm hiểu về Computer Vision (CV) các bài toán về segment không còn quá xa lạ nữa nên vì vậy ở phần này mình sẽ tóm tắt sơ qua để những bạn mới tìm hiểu về bài toán này có thể hiểu được bối cảnh chung của một bài toán segmentation là gì, baseline để đọc thêm những tài liệu khác nhé.
Là một trong những bài toán chính, quan trọng trong CV, bên cạnh Object Detection (OD). Không giống với người anh em của mình, trong khi OD đi tìm bounding box và class instance cho từng đối tượng trong ảnh thì Image Segmentation lại đi tìm class cho từng điểm ảnh trong ảnh. Chi tiết hơn: Ví dụ với một ảnh 224x224, với OD chúng ta phải tìm ra tập các tọa độ (c, x, y, w, h) cho các object trong ma trận 224x224 này (trong đó c: class, x, y: top-left location, w, h: chiều rộng, cao của bounding box), nghĩa là đầu ra của một mô hình OD sẽ phải chứa thông tin class, thông tin locations của bounding boxes nhưng với Image Segmentation thì khác, nó không cần phải đi tìm thông tin các locations này, mà đầu ra của nó sẽ có shape giống với ảnh đầu vào nhưng được phân bố rõ nét thành từng vùng cho từng thành phần trong ảnh (tức: tìm class cho từng pixel trong ảnh, những pixel có cùng class sẽ cùng màu với nhau). Xem ảnh minh họa bên trên.
Image segmentation được chia ra thành 2 loại:
- Instance Segmentation: Mô hình segment quan tâm đến các instance object khác nhau trong cùng một loại object
- Semantic Segmentation: Mô hình segment không quan tâm đến các instance object trong cùng một loại object
** Như ở hình minh họa trên, sự khác nhau giữa Semantic Segmentation và Instance Segmentation là Instance Segmentation thì quan tâm đến con cừu A, con cừu B, con cừu C trong khi Semantic Segmentation thì không quan tâm đến sự khác nhau giữa các con cừu, nó chỉ quan tâm đến con chó (1 class riêng), con cừu (1 class riêng).
** Ứng dụng của Image Segmentation: Image segmentation được sử dụng giúp các bác sĩ chuẩn đoán các khối u bất thường (Medical), hệ thống ô tô tự lái (Autonomous vehicles), phân tích ảnh vệ tinh (Satellite image analysis) ...vân vân và mây mây.
=> Giờ cùng chuyển qua phần 2: Những khó khăn của mô hình segmentation, trước khí chuyển sang phần 3 các mô hình segmentation thông dụng và phần 4 phân tích cụ thể mô hình SINet
II. Difficulty
Dưới đây chúng ta cùng điểm qua 1 số khó khăn mà 1 model segmentation cần phải đồng thời giải quyết được, mình xin phép giữ nguyên bản tiếng anh để giữ được tính chính xác trong ngữ nghĩa của các term này.

2.1. Global Consistency
Đây là 1 vấn đề phổ biến mà các model segmentation thường gặp phải, hiện tượng là mô hình thường phân biệt sai, nhầm lẫn giữa background features với object segment. Lý giải cho hiện tượng trên thường là do các receptive field trong model chưa đủ lớn để get được tính global context của ảnh => model predict sai. Mô tả cho việc này, chúng ta có thể quan sát đốm xanh ở hình b phía trên.
Nhằm mục đích tăng tính global consistency cách đơn giản nhất có thể nghĩ tới là sử dụng các receptive field lớn hơn, ta có thể tạo các Conv với size của kernel lớn hơn, tuy nhiên cách này có 1 nhược điểm có thể dễ dàng nhận thấy là: Kernel lớn hơn tương đương với số lượng parameters cũng nhiều hơn, computational time lâu hơn dẫn đến khó ứng dụng trong thực tế. Cũng vì lý do này, mà concept của Dilated Conv ra đời như 1 cách hiệu quả để có được các receptive field lớn hơn mà vẫn giữ được các localization information. Tuy nhiên, khi giá trị dilation rate tăng lên thì số lượng weights valid lại giảm xuống.
Ngoài ra, có 1 cách khác để tạo ra các model lightweight với các receptive field khác nhau là sử dụng Spatial Pyramid Pooling với các pool_size khác rồi concatenate các features lại hoặc multi-path structure cho features extraction, tuy nhiên chúng đều có 1 nhược điểm là high latency.
SINet đề xuất 1 kiến trúc mới để giải quyết vấn đề này, chúng ta sẽ cùng tìm hiểu ở phần kiến trúc của SINet
2.2. Preserving detailed local information
Một vấn đề khó khăn nữa mà các model segmentation phải đối mặt đó là làm sao để recover, preserve được các detailed local information. Yếu tố này là cực kì quan trọng để ta có thu được tính sắc nét tại các điểm viền của mask segmentation hay không. Cùng quan sát các đốm đỏ tại hình b phía trên.
Cùng nhắc lại 1 chút, chúng ta đều hiểu sau quá trình encoder ta thu được các low_resolution feature maps chứa high_level information và để thu được original resolution, ta quan tâm đến các khái niệm Transposed Conv hoặc Global Attention để Upsampling step by step. Tuy nhiên, các attention vectors này lại không phản ảnh tốt các local information do global pooling. Hiện nay, 1 phương pháp mới được đề xuất để có thể đạt được kết quả tốt hơn trong segmentation có tên là two-branch method, điển hình như FastSCNN, ContextNet, BiSeNet, 1 path cho global context, 1 cho detailed information. Điểm hạn chế là nó vẫn cần phải tính toán 2 lần, mỗi lần cho mỗi branch.
SINet đề xuất 1 kiến trúc mới để giải quyết vấn đề này, chúng ta sẽ cùng tìm hiểu ở phần kiến trúc của SINet
III. Popular Image Segmentation Architecture
Lý do có phần này là để chúng ta so sánh sự khác biệt trong mô hình SINet so với các mô hình segmentation truyền thống. Phần này chứa khá nhiều kiến thức cơ bản, nếu đã quen thuộc các bạn có thể bỏ qua và đến thẳng phần SINet (phần 4)
Như đã giới thiệu ở trên, đặc điểm của mô hình segmentation là output của mô hình sẽ có shape đầu ra giống với shape đầu vào của mô hình. Tư tưởng chính của nó là dựa vào các high_level features để dự đoán ra class cho từng pixels trong ảnh. Các high_level features này thường chứa các thông tin quan trọng như egdes, shape, của objects, global context của ảnh, thu được từ 1 network fully convolution (thường được gọi với cái tên encoder) qua từng convolution layers, mỗi layers tùy theo độ sâu chứa một loại thông tin của ảnh. Dựa vào các features này, ta cần reproduce lại spartial dimension bằng cách sử dụng các Upsampling layers. Kiểu kiến trúc này được gọi là Encoder-Decoder. Hình minh họa bên dưới:
 (ảnh copy)
(ảnh copy)
Như vậy để dễ hiểu hơn, cùng tách biệt chúng thành 2 phần riêng biệt. Dưới đây là những điều cần lưu ý về 1 mô hình segmentation:
3.1. Encoder
Các Encoder đóng vai trò quan trọng trong việc extract ra các features quan trọng của ảnh, chúng là các Convolution xếp chống lên nhau với: High_resolution features chứa low_level information (edges) và low_resolution features chứa high_level information (shape, global context). Các mô hình encoder phổ biến có thể kể đến như VGG, ResNet, Inception, Xception, MobileNet...
Ngoài ra, với encoder, các practitioner thường hướng đến việc sử dụng kỹ thuật Transfer learning hơn là training from scratch để tận dụng các features từ các mô hình đã được training từ các bộ dữ liệu lớn như ImageNet. Mọi người có thể đọc thêm các paper về transfer learning để hiểu hơn nha.
 (ảnh copy)
(ảnh copy)
3.2. Skip connection
Sự xuất hiện của Skip connection là khá quan trọng, nó làm tăng độ chính xác cho các shape đầu ra, đặc biệt là ở các vị trí boundaries. Lý do là bởi vì khi ta Upsampling từ các vị trí low-resolution tensors, 1 số thông tin low-level đã bị mất đi trong quá trình encoder. Để giải quyết vấn đề trên, ta cho phép từng Upsampling layers được add thêm các low_level features từ các layers từ Encoder tương ứng với nó. Điều này làm tăng tính smooth tại các vị trí boundaties của các object.
 (ảnh copy)
(ảnh copy)
Tuy nhiên, không phải lúc nào Skip connection cũng tốt. Mô hình SINET sẽ giúp ta giải quyết vấn đề này, cùng tìm hiểu ở phần kiến trúc của SINET nhé.
3.3. Loss function
Về cơ bản, đầu ra của mô hình sẽ là class prediction cho từng pixel của ảnh output. Như vậy hàm loss thông dụng sẽ được sử dụng là Cross_entropy.
3.4. Popular Architecture
Dưới đây chúng ta cùng liệt kê 1 số kiến trúc Image Segmentation phổ biến trước khi chúng ta đến với SINet.
FCN: là một trong những mô hình đề xuất end-to-end semantic segmentation đầu tiên. Base model thường được sử dụng là VGG hoặc ALexNet, tại layer cuối encoder, Tranposed Conv được sử dụng để upsample. Các kiến trúc phổ biến: FCN8, FCN16, FCN32, trong đó FCN8, FCN16 sử dụng skip connection.
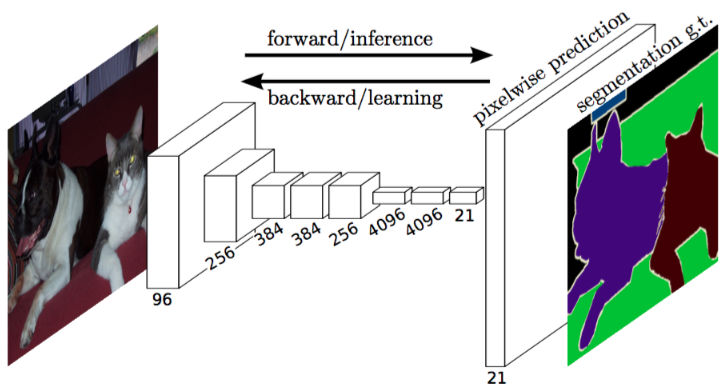
SegNet: Tuân theo kiểu kiến trúc encoder-decoder, các layers giữa 2 phần này đối xứng nhau. Layers ở decoder được upsampling dựa vào các chỉ số max-pooling tương ứng với nó ở tầng encoder. Tuy nhiên ở SegNet, skip connection không được sử dụng.
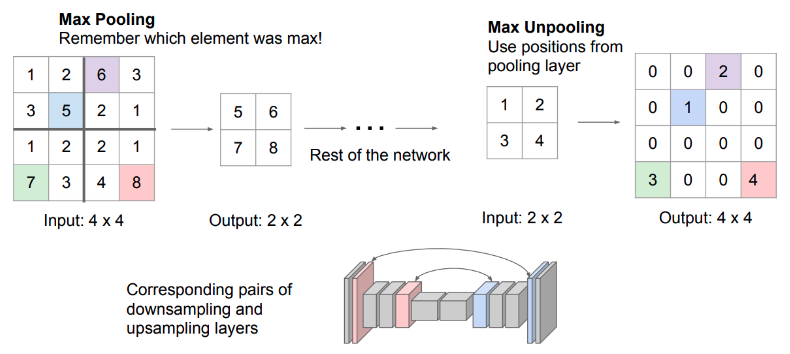
UNet: Kiến trúc tương đồng với SegNet, tuy nhiên có sự thay đổi là nó áp dụng Skip-Connection.
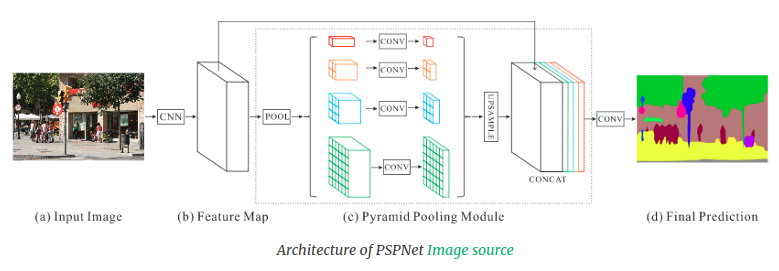
PSPNet: PSPNet được optimized để giải quyết vấn đề global context trong ảnh vì apply multi-receptive field. Pipeline của model vẫn cần 1 encoder để thu được feature maps, tại đây các feature maps này sẽ được downsampling với các pool_size khác nhau trước khi được upsampling về cùng 1 resolution. Các feature maps được concatenate nhằm mục đích tổng hợp các features từ các resolution khác nhau, chính điều này sẽ giải quyết được vấn đề global consistency, tuy nhiên do có quá nhiều nhánh dẫn đến vấn đề high latency.
Trên đây là 1 số kiến trúc segmentation phổ biến, giờ chúng ta sẽ đi đến phần chính SINet xem nó có những thay đổi gì nhé.
IV. SINet
Ngày nay, bên cạnh việc nghiên cứu mô hình, công nghệ mới, người ta bắt đầu chú ý hơn đến việc làm sao để những nghiên cứu này có tính thực tiễn cao, có thể áp dụng vào product, đó giờ đã trở thành 1 tiêu chí để đánh giá giá trị của 1 paper, nghiên cứu mới bên cạnh các yêu tố khác như độ chính xác, tính đúng đắn... Trong lĩnh vực CV, cụ thể là các bài toán Image Segmentation, các mô hình lightweight có khả năng chạy realtime, nhúng xuống các thiết bị di động mà vẫn đảm bảo độ chính xác đã trở thành một chủ đề nghiên cứu trong những năm gần đây. Vì lẽ đó, SINet cùng 1 số mô hình lightweight khác ra đời. Đứng TOP 1 ranking trên tập EG1800 theo Paperswithcode, chúng ta sẽ cùng nhau tìm hiểu kỹ hơn xem nó có gì đặc biệt:
Có thể tóm gọn sự cải tiến của mô hình SINet thành các phần như sau:
- Sự xuất hiện của
Spatial Squeeze Modulegiúp giải quyết vấn đềglobal consistencybằng cách tận dụng multi-receptive field mà vẫn giảm được số lượng tham số mô hình, và tính latency so với các mô hình multi-path structure. - Sự xuất hiện của
Information Blocking Decodergiúp chọn lọc cáclowlevel informationcho các Upsampling layers thay vì tất cả như các mô hình truyền thống. - Sự thay đổi trong hàm loss, giúp giải quyết được vấn đề ở mask boundaries.
Giờ chúng ta sẽ đi tìm hiểu cụ thể từng phần.
4.1. Information Blocking Decoder
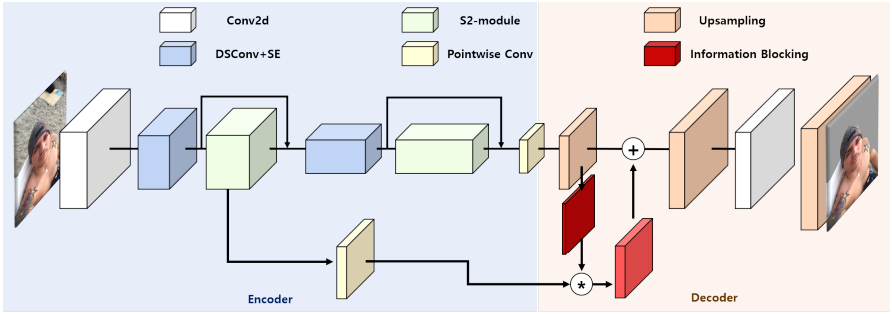
Ảnh: Kiến trúc tổng quan mô hình SINet (Ảnh copy từ official paper)
Ý tưởng của tác giả paper ở đây thực sự rất hay, sự xuất hiện của Information Blocking Decoder (phần màu đỏ) là để có sự chọn lọc trong việc tái sử dụng thêm các feature maps từ các features với different resolution của encoder. Nhưng nó không giống như các kiến trúc phổ biến như Unet, thay vì sử dụng skip connection để concat tất cả feature maps tương ứng resolution giữa encoder và decoder, nó có sự chọn lọc bằng cách: mô hình chỉ add thêm các feature maps của encoder trong trường hợp confidence score của feature maps tại decoder là thấp và block các feature maps có giá trị confidence score cao.
Tại sao lại cần chọn lọc, lý do là vì: đúng là các features của encoder khi được add thêm vào các layers tương ứng của decoder sẽ làm tăng độ chính xác cho segmentation, tuy nhiên không phải tất cả cứ add thêm vào là tốt. Những features ở decoder có confidence score cao so với ground truth, nghĩa là nó đang phản ảnh chính xác những gì nó học được từ label groung truth, vì vậy đôi khi việc add thêm các features từ encoder sẽ gây ra sự dư thừa, làm hỏng các local information tại những features decoder này.
Ý tưởng được tác giả thực hiện bằng cách: tại feature maps cuối cùng của lớp encoder, sử dụng point_wise convolution để thu được layers có shape (feature_h, feature_w, num_classes), rồi sử dụng UpSampling để thu được size của feature_maps tương ứng ở encoder cho việc lấy thông tin feature maps. Tại đây, ta apply 1 softmax activation để thu được xác suất của từng class cho từng pixel tại feature maps này và lấy ra giá trị class với confidence lớn nhất, đặt là layer c. Để thu được information blocking map, ta áp dụng 1 lamda layer: 1- c. Ý nghĩa của computation này là để block đi những feature maps có confidence score cao.
Như vậy ta đã hiểu thế nào là Information Blocking Decoder và cách tạo ra nó như thế nào, sâu hơn về cách thực hiện ta sẽ nói sâu hơn ở phần coding.
4.2. Spatial Squeeze module
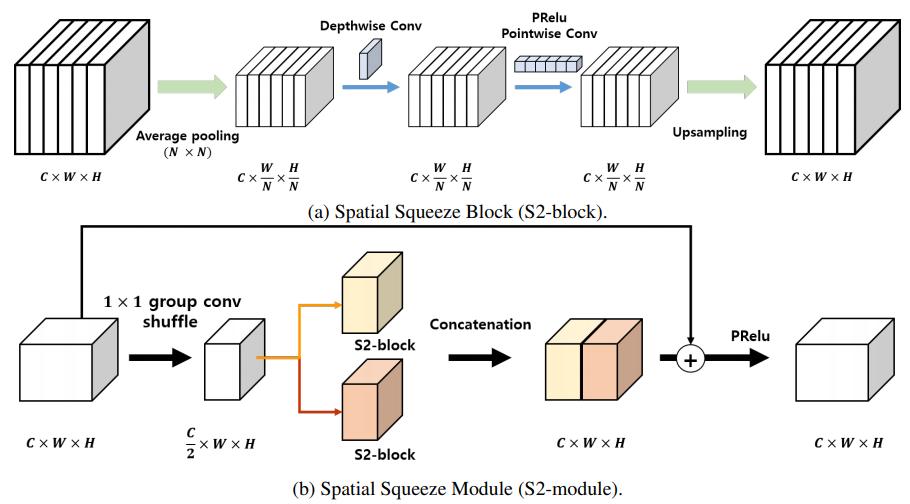
Ảnh: Kiến trúc cụ thể của Spatial Squeeze module (S2-module)
Tại phần này chúng ta sẽ nói kỹ hơn về S2-module. Sự ra đời của Spatial Squeeze model giúp giải quyết 2 vấn đề: high latency trong các mô hình multi-path structure và Average Pooling thay vì sử dụng dilatied Conv cho các receptive field lớn hơn nhằm đảm bảo tính global consistency. Ý tưởng chính của S2-module là tuân theo cơ chế split-transform-merge, đầu tiên nó sử dụng 1 poinwise conv để giảm số feature maps = rồi đưa qua 2 S2-block, features thu được từ 2 S2-block này sẽ được merge qua phép toán concatenation. 1 residual connection cũng được apply cho input features và merged features, các residual này cho phép mô hình có khả năng train lâu hơn với tham số learning rate lớn mặc dù số lượng tham số mô hình là khá nhỏ.
Trong S2-block, để tạo ra multi-receptive field, nó tận dụng Average Pooling với các pool_size khác nhau thay vì dilated Conv, thêm nữa, sự kết hợp giữa Depthwise Conv + Pointwise Conv để giảm lượng tham số mô hình thay vì sử dụng Conv truyền thống. Giữa Depthwise Conv và Pointwise Conv tác giả sử dụng 1 non-linear activation PRelu trước khi được Upsampling trở về original resolution.
Kết hợp những yếu tố trên giúp ta thu được 1 mô hình lightweight nhưng vẫn giải quyết được các vấn đề mà 1 mô hình segmentation gặp phải.
4.3 Network Design for SINet
 Ảnh (copy từ official paper)
Ảnh (copy từ official paper)
Đi qua 2 phần chính của SINet là S2-module và Information Blocking Decoder, giờ ta cần có cái nhìn tổng quan về mô hình.
Toàn bộ cấu trúc của encoder được mô tả ở hình trên, phần decoder các bạn có thể xem lại hình ở phần 4.1 nhé.
Thông quả hình ảnh mô hình tổng quan ở phần 4.1 và cấu trúc encoder ở phần 4.3 này chúng ta có thể xây dựng được mô hình SINet, với những điều đáng chú ý như ta thấy ở đây tác giả coi S2-module như các bottleneck của mô hình với các giá trị k là kernel_size của depthwise conv và p là pool_size trong Average Pooling trong S2-block. Sau 2 bước downsampling với 1 normal Conv và 1 Depthwise conv + SE (Squeeze-and-Excitation block), tác giả sử dụng 2 block S2-module cho bottleneck đầu tiên và 8 block S2-module cho bottle tiếp theo. Vì trong paper không nêu rõ về cái Depthwise Conv + SE này nên mình sẽ bổ sung thêm để mọi người hiểu và có thể implement được. Cụ thể hơn mọi người có thể đọc thêm về 2 paper (SENet và Depthwise Separable Convolutional ResNet with Squeeze-and-Excitation Blocks for Small-footprint Keyword Spotting) mình sẽ để trong phần references.
 HÌnh: Squeeze-and-Excitation block (ảnh copy)
HÌnh: Squeeze-and-Excitation block (ảnh copy)
In addition, với sau mỗi bottleneck S2-module, tác giả đều apply residual connection giữa bottleneck inputs với its output. Điều này giúp module train lâu hơn. Cụ thể về residual connection các bạn có thể đọc thêm ở paper ResNet, mình sẽ để link ở phần references.
4.4 Weighted auxiliary loss
Chúng ta đều thấy mỗi phần tử của Loss sẽ phản ánh khá nhiều cái mà mô hình sẽ train và kết quả nhận được. Ở đây ngoài Cross Entropy Loss, tác giả sử dụng thêm 1 boundary Loss cho riêng phần boundary để tăng độ chính xác cho những boundary của segmented mask.
Trong đó: là ground truth, là predicted label, là một hệ số hyperparam dùng cân bằng giữa cross entropy loss và boundary loss. f là phép toán morphological diation và erosion với window_size = (15 x 15) trên ground truth. biểu thị toàn bộ pixel của ground truth còn biểu thị riêng phần pixel của vùng boundary trong morphology operation.
Giờ chúng ta sẽ đi đến phần implement mô hình
V. Implement model
Ở phần 4, mình đã đi vào việc phân tích model và ý nghĩa của từng phần trong model này. Giờ chúng ta sẽ cùng implement cái model này với keras. Cho đến thời điểm mình viết bài này vẫn chưa có 1 respo nào implement SINet với Keras, vì vậy phần souce code mình sẽ public sau khi mình cần refactor lại 1 số đoạn nha.
Ở phần này mình xin phép chỉ cung cấp code, giải thích cho các phần các bạn có thể đọc lại phần 4 và để lại comment cho mình nếu có nhé.
1. Depthwise Conv + Squeeze-and-Excitation block
def _squeeze_excite_block(self, inputs, ratio=16, block_id=1):
filters = inputs.shape[self.channel_axis]
se_shape = (1, 1, filters) if self.channel_axis == -1 else (filters, 1, 1)
se = GlobalAveragePooling2D(name="squeeze_glo_avg_%s" % block_id)(inputs)
se = Dense(filters // ratio, activation="relu",
kernel_initializer="he_normal",
kernel_regularizer=l2(self.reg),
use_bias=False, name="squeeze_squ_%s" % block_id)(se)
se = Dense(filters, activation="relu",
kernel_initializer="he_normal",
kernel_regularizer=l2(self.reg),
use_bias=False,
name="squeeze_exci_%s" % block_id)(se)
se = multiply([inputs, se], name="squeeze_scale_%s" % block_id)
return se
def _depthwise_conv_se_block(self, inputs, pointwise_conv_filters, alpha,
depth_multiplier=1, strides=(2, 2), block_id=1,
kernel=(3,3), ratio=16):
"""
DS-Conv + SE
"""
x = self._depthwise_conv_block(inputs, pointwise_conv_filters, alpha,
block_id=block_id, strides=strides)
x = self._squeeze_excite_block(x, ratio=ratio, block_id=block_id)
x = Activation("relu")(x)
return x
2. S2-Block
def _s2_block(self, inputs, pointwise_conv_filters, alpha,
depth_multiplier=1, strides=(1, 1), block_id=1,
kernel=(3,3), pool_size=(1,1), padding_size=(1, 1)):
x = AveragePooling2D(pool_size=pool_size, strides=(2, 2),
data_format=IMAGE_DATA_FORMAT, padding="same")(inputs)
x = Activation("relu")(x)
x = self._depthwise_conv_block(x, pointwise_conv_filters, alpha,
block_id=block_id, kernel=kernel,
padding_size=padding_size)
x = UpSampling2D(size=(2, 2), interpolation="bilinear", name="s2_block_%s" % block_id)(x)
x = BatchNormalization(axis=self.channel_axis)(x)
x = Activation("relu")(x)
return x
3. S2-Module
def _s2_module(self, inputs, pointwise_conv_filters, alpha,
depth_multiplier=1, strides=(1, 1), block_id=1,
kernel_conv=(3, 3), kernel_ds_1=(3, 3),
kernel_ds_2=(3, 3), pad_ds_1=(1, 1), pad_ds_2=(1, 1),
pool_block_1=(1, 1), pool_block_2=(1, 1)):
"""
The function to build S2 block
"""
x = self._conv_block(inputs, pointwise_conv_filters, alpha,
kernel=(1, 1), block_id=block_id, padding="same")
x1 = self._s2_block(x, pointwise_conv_filters, alpha, depth_multiplier=depth_multiplier,
strides=strides, kernel=kernel_ds_1, block_id=str(block_id) + "_1",
padding_size=pad_ds_1, pool_size=pool_block_1)
x2 = self._s2_block(x, pointwise_conv_filters, alpha, depth_multiplier=depth_multiplier,
strides=strides, kernel=kernel_ds_2, block_id=str(block_id) + "_2",
padding_size=pad_ds_2, pool_size=pool_block_2)
x = Concatenate(axis=self.channel_axis)([x1, x2])
x = Add()([inputs, x])
x = PReLU()(x)
return x
4. Encoder
def build_encoder(self):
"""
Build encoder function
"""
input_shape = (IMG_HEIGHT, IMG_WIDTH, IMG_CHANNEL)
if IMAGE_DATA_FORMAT == "channels_first":
input_shape = (IMG_CHANNEL, IMG_HEIGHT, IMG_WIDTH)
inputs = Input(shape=input_shape)
x = Lambda(lambda z: z[...,::-1], output_shape=input_shape,
name="swap_color_channel")(inputs)
if self.mean_substraction:
x = Lambda(lambda z: (z - np.array(self.mean_substraction))*self.image_val,
output_shape=input_shape,
name="mean_substraction_inputs")(x)
x1 = self._conv_block(x, 12, self.alpha, strides=(2, 2), block_id=1)
x2 = self._depthwise_conv_se_block(x1, 16, self.alpha, block_id=2)
x3 = self._depthwise_conv_se_block(x2, 48, self.alpha, block_id=3, strides=(1, 1))
x4 = self._s2_module(x3, 24, self.alpha, block_id=4, kernel_ds_2=(5, 5), pad_ds_2=(2, 2))
x5 = self._s2_module(x4, 24, self.alpha, block_id=5)
x6 = Concatenate(axis=self.channel_axis, name="concat_2_5")([x2, x5])
x7 = self._depthwise_conv_se_block(x6, 48, self.alpha, block_id=6)
x8 = self._depthwise_conv_se_block(x7, 96, self.alpha, block_id=7, strides=(1, 1))
x9 = self._s2_module(x8, 48, self.alpha, block_id=8, kernel_ds_2=(5, 5), pad_ds_2=(2, 2))
x10 = self._s2_module(x9, 48, self.alpha, block_id=9)
x11 = self._s2_module(x10, 48, self.alpha, block_id=10,
kernel_ds_1=(5, 5), pad_ds_1=(2, 2),
kernel_ds_2=(3, 3), pool_block_2=(2, 2))
x12 = self._s2_module(x11, 48, self.alpha, block_id=11,
kernel_ds_1=(5, 5), pad_ds_1=(2, 2),
kernel_ds_2=(3, 3), pool_block_2=(4, 4))
x13 = self._s2_module(x12, 48, self.alpha, block_id=12)
x14 = self._s2_module(x13, 48, self.alpha, block_id=13,
kernel_ds_1=(5, 5), pad_ds_1=(2, 2),
kernel_ds_2=(5, 5), pad_ds_2=(2, 2))
x15 = self._s2_module(x14, 48, self.alpha, block_id=14,
kernel_ds_1=(3, 3), pool_block_1=(2, 2),
kernel_ds_2=(3, 3), pool_block_2=(4, 4))
x16 = self._s2_module(x15, 48, self.alpha, block_id=15,
kernel_ds_1=(3, 3), pool_block_1=(1, 1),
kernel_ds_2=(5, 5), pad_ds_2=(2, 2), pool_block_2=(2, 2))
x17 = Concatenate(axis=self.channel_axis, name="concat_16_7")([x16, x7])
x17 = Activation("relu")(x17)
x = self._pointwise_conv_block(x17, N_CLASSES, self.alpha, block_id=16)
x = Activation("relu")(x)
return inputs, x, x8, x5, x1
5. Decoder
def build_decoder(self):
inputs, x, x8, x5, x1 = self.build_encoder()
x = UpSampling2D((2, 2), data_format=IMAGE_DATA_FORMAT,
interpolation="bilinear")(x)
x = BatchNormalization(axis=self.channel_axis)(x)
x_ac = Activation("softmax")(x)
x_blocking = K.max(x_ac, axis=-1, keepdims=True)
x_blocking = Lambda(lambda x: 1 - x, name="information_blocking_decoder")(x_blocking)
x5_pws = self._pointwise_conv_block(x5, self.n_classes, self.alpha, block_id=18)
x_mul = Multiply()([x5_pws, x_blocking])
x = Activation("relu")(x)
x = Add()([x_mul, x])
x = Activation("relu")(x)
x = UpSampling2D((2, 2), interpolation="bilinear")(x)
x = BatchNormalization(axis=self.channel_axis)(x)
x = Activation("relu")(x)
x = self._conv_block(x, self.n_classes, self.alpha, kernel=(1, 1), padding="same", block_id=19)
x = UpSampling2D((2, 2), interpolation="bilinear")(x)
x = BatchNormalization(axis=self.channel_axis)(x)
x = Activation("relu")(x)
x = Reshape((-1, self.n_classes))(x)
x = Activation("softmax")(x)
model = Model(inputs=inputs, outputs=x)
return model
VI. Training
Ok đến đây chúng ta đã đi được 3/4 chặng đường rồi. Giờ đã hiểu model, đã có model. Chúng ta sẽ đến bước training, những điều chúng ta cần quan tâm là Dataset là gì, chuẩn bị dataset như thế nào, training bao nhiêu epochs với learning rate là bao nhiêu, kỹ thuật training như thế nào để model hội tụ, chúng ta sẽ nói ở phần này. Đầu tiên là Dataset.
6.1 Dataset
SINet được tác giả training và đánh giá trên tập EG1800 bao gồm 1500 cho train và 300 cho validation, tuy nhiên chỉ có 1309 cho train và 270 cho validation là có thể sử dụng. Do đó nhóm tác giả tự sinh thêm dữ liệu bằng cách sử dụng tập Baidu dataset chứa 5382 ảnh raw, và segment label full body của người. Dữ liệu được sinh thêm bằng cách sử dụng Face Detection sau đó mở rộng vùng lấy để thu được ảnh portrait và segment cho vùng portrait cần lấy. Ngoài ra, họ cũng crawl thêm dữ liệu và sử dụng pretrained segment model DeepLabv3 + SE-ResNeXt-50 để thu thêm dữ liệu rồi cùng nhau check lại chất lượng các bức ảnh đó xem có đảm bảo chất lượng không trước khi được đưa vào model để training. Các bạn có thể đọc cụ thể thêm trong paper SINet (mục 3.4)
6.2 DataGenerator
Trước khi đưa vào model training, ta cần có 1 class DataGenerator giúp model train theo batch, tại đây ta sẽ apply thêm 1 số preprocess như resize ảnh, tăng constrast, mean-substracttion, data augmentation. Các bước tiền xử lý của paper này được mô phỏng lại giống hệt như ở paper PortraitNet, bao gôm các bước như sau:
Vì nội dung khá dài nên mình xin phép lược bỏ bước resize ảnh về kích thước 224x224, và mọi bước tiền xử lý dưới đây đều được apply cho ảnh có kích thước (224x224).
6.2.1 Normalize
Mean substraction ([103.94, 116.78, 123.68], RGB) kết hợp với 1 hệ số image_val (0.017) được áp dụng. Code như sau:
def mean_substraction(self, image, mean=[103.94, 116.78, 123.68], image_val=0.017):
image = image.astype("float32")
image[:, :, 0] -= mean[0]
image[:, :, 1] -= mean[1]
image[:, :, 2] -= mean[2]
image *= image_val
image = image[..., ::-1]
return image
6.2.2 Data Augmentation
Các methods augmentations được sử dụng trước training bao gồm các bước sau:
** Geometric aug:
- random horizontal flip
- random rotation {−45◦ ∼ 45◦}
- random resizing {0.5 ∼ 1.5}
- random translation {−0.25 ∼ 0.25}
def _load_augmentation_aug_geometric(self):
return iaa.Sequential([
iaa.Sometimes(0.5, iaa.Fliplr()),
iaa.Sometimes(0.5, iaa.Rotate((-45, 45))),
iaa.Sometimes(0.5, iaa.Affine(
scale={"x": (0.5, 1.5), "y": (0.5, 1.5)},
order=[0, 1],
mode='constant',
cval=(0, 255),
)),
iaa.Sometimes(0.5, iaa.Affine(
translate_percent={"x": (-0.25, 0.25), "y": (-0.25, 0.25)},
order=[0, 1],
mode='constant',
cval=(0, 255),
)),
])
** Non-geometric aug:
- random noise {Gaussian noise, σ = 10 }
- image blur {kernel size is 3 and 5 randomly }
- random color change {0.4 ∼ 1.7}
- random brightness change {0.4 ∼ 1.7}
- random contrast change {0.6 ∼ 1.5}
- random sharpness change {0.8 ∼ 1.3}
def _load_augmentation_aug_non_geometric(self):
return iaa.Sequential([
iaa.Sometimes(0.5, iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.05*255), per_channel=0.5)),
iaa.Sometimes(0.5, iaa.OneOf([
iaa.GaussianBlur(sigma=(0.0, 3.0)),
iaa.GaussianBlur(sigma=(0.0, 5.0))
])),
iaa.Sometimes(0.5, iaa.MultiplyAndAddToBrightness(mul=(0.4, 1.7))),
iaa.Sometimes(0.5, iaa.GammaContrast((0.4, 1.7))),
iaa.Sometimes(0.5, iaa.Multiply((0.4, 1.7), per_channel=0.5)),
iaa.Sometimes(0.5, iaa.MultiplyHue((0.4, 1.7))),
iaa.Sometimes(0.5, iaa.MultiplyHueAndSaturation((0.4, 1.7), per_channel=True)),
iaa.Sometimes(0.5, iaa.LinearContrast((0.4, 1.7), per_channel=0.5))
])
Kết quả sau khi augment:
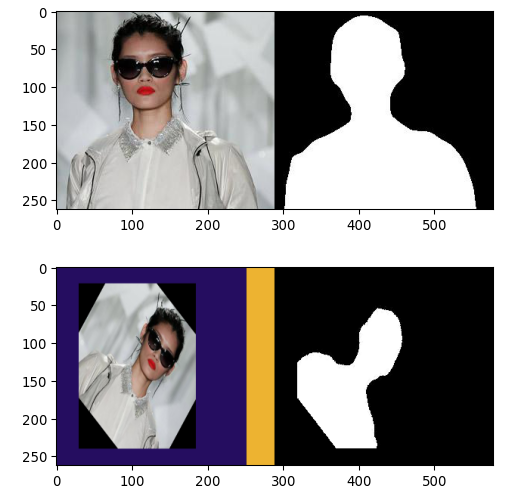
Tất cả các bước augment bên trên, mình đều sử dụng lib imgaug
6.3 Loss Function
Để training được, ta cần build 1 custom class loss, 1 function cho việc tính Cross Entropy và 1 function cho việc tính Boundary Loss. Mình xin chia sẻ code như sau:
class SINetLoss:
def __init__(self, lamda=0.9):
self.lamda = lamda
def gt_dilation(self, y_true):
y_true = tf.reshape(y_true, (-1, IMG_HEIGHT, IMG_WIDTH, N_CLASSES))
dilation = tf.nn.max_pool2d(y_true, ksize=(15, 15), strides=1, name='dilation2D', padding="SAME")
dilation = tf.reshape(dilation, (-1, IMG_HEIGHT*IMG_WIDTH, N_CLASSES))
return dilation
def gt_erosion(self, y_true):
y_true = tf.reshape(y_true, (-1, IMG_HEIGHT, IMG_WIDTH, N_CLASSES))
erosion = -tf.nn.max_pool2d(-y_true, ksize=(15, 15), strides=1, name='erosion2D', padding="SAME")
erosion = tf.reshape(erosion, (-1, IMG_HEIGHT*IMG_WIDTH, N_CLASSES))
return erosion
def log_loss(self, y_true, y_pred):
loss = -tf.reduce_sum(y_true * tf.math.log(y_pred), axis=-1)
return loss
def boundary_loss(self, y_true, y_pred):
dilation = self.gt_dilation(y_true)
erosion = self.gt_erosion(y_true)
boundary = tf.math.subtract(dilation, erosion)
loss = -tf.reduce_sum(boundary * tf.math.log(y_pred), axis=-1)
return loss
def compute_loss(self, y_true, y_pred):
batch_size = tf.shape(y_pred)[0]
self.lamda = self.lamda
log_loss_ = tf.cast(self.log_loss(y_true, y_pred), tf.float32)
boundary_loss_ = tf.cast(self.boundary_loss(y_true, y_pred), tf.float32)
total_loss = log_loss_ + self.lamda * boundary_loss_
total_loss *= tf.cast(batch_size, tf.float32)
return total_loss
Bỏ qua Cross Entropy cho toàn bộ pixel của output đầu ra, ta sẽ nói kỹ hơn về cái boundary loss này. Để tính được nó, ta cần thực hiện 2 phép toán dilation và erosion morphology với window_size = (15x15) trên ground truth, boundary sẽ thu được bằng cách sử dụng substraction element-wise giữa 2 matrix dilation và erosion này. Boundary loss sẽ là các giá trị cross entropy giữa ground truth và predicted label nhưng chỉ trên các pixel của boundary mà thôi.
Note: Ở phần cuối cùng, mình có nhân thêm loss với batch_size nữa mặc dù đây là loss theo batch rồi, thực nghiệm sau rất nhiều lần training cho thấy sau khi mình nhân thêm kết quả với hệ số này giúp model hội tụ nhanh hơn và tốt hơn. Phần này là mình custom thêm so với loss ban đầu của tác giả.
6.4 Training
Tại đây, mình sẽ follow theo chính các bước của paper, model sẽ được train trên toàn bộ 600 epochs với Optimizer là Adam, leanring rate khởi đầu là 7.5e-3 với weight decay = 2e-4. 300 epoch đầu, mình chỉ train riêng encoder với batch_size=36, 300 epoch sau mình mở toàn bộ layer và train với batch_size=24. Tuy nhiên, mình có thay đổi 1 chút, mình có apply 1 cái LearningRateScheduler callback.
sinet_loss = SINetLoss().compute_loss
init_lr = 7.5e-3
opt = Adam(lr=init_lr, decay=2e-4, beta_1=0.9, beta_2=0.999, epsilon=1e-07,)
model.compile(optimizer=opt, loss=sinet_loss, metrics=["accuracy"])
checkpoints = ModelCheckpoint(filepath=os.path.join(trained_weight, "best_weights.h5"),
monitor="val_loss",
save_weights_only=True,
save_best_only=True,
verbose=1)
Đóng/mở layer:
for idx, layer in enumerate(model.layers):
print(idx, layer.name, layer.trainable)
layer.trainable = True
if idx > 361:
layer.trainable = False
Poly Decay:
def poly_decay(epoch):
maxEpochs = 600
baseLR = INIT_LR
power = 1.0
alpha = baseLR * (1 - (epoch / float(maxEpochs))) ** power
return alpha
Training:
H = model.fit_generator(train_datagen.generate(),
epochs=600,
steps_per_epoch=train_datagen.get_n_examples() // train_datagen.batch_size,
validation_data=val_datagen.generate(),
validation_steps=val_datagen.get_n_examples() // val_datagen.batch_size,
callbacks=[checkpoints, LearningRateScheduler(poly_decay)],
initial_epoch=0
)
Kết quả cuối cùng sau 600 epochs, mình thu được các chỉ số accuracy/loss: loss: 0.3473 - accuracy: 0.9729 - val_loss: 0.4149 - val_accuracy: 0.9605. Dưới đây là 1 số kết quả của model:



Phần code prediction và parse kết quả các bạn có thể tham khảo trong respo của mình, mình xin phép không show lên đây nữa nha. Đến đây bài đã khá dài rồi, chúng ta sẽ đi đến phần kết luận.
Mình sẽ Public source code ngay sau khi mình refactor lại code. Mong mọi người hủng hộ mình. Xin cảm ơn!!!
Updated: Mọi người có thể tham khảo SINet với keras tại đây https://github.com/DatDaiGia/SINet-keras
VII. Conclusion
Trên đây là toàn bộ những gì về SINet mình muốn chia sẻ về paper SINet, 1 paper với khá nhiều sự thay đổi trong một mô hình segmentation so với các mô hình cổ điển. Ứng dụng của image segmentation hay portrait segmentation là rất nhiều, vì vậy đây hoàn toàn là 1 mảnh đất màu mỡ để ta có những nghiên cứu trong tương lai. Cảm ơn mọi người đã đọc cho đến tận đây, mọi ý kiến đóng góp đều là vô cùng tốt đối với mình để có được những bài viết chất lượng trong tương lai.
REFERENCES
https://arxiv.org/pdf/1911.09099.pdf
https://github.com/titu1994/keras-squeeze-excite-network
https://arxiv.org/pdf/1709.01507.pdf
https://arxiv.org/abs/2004.12200
https://www.yongliangyang.net/docs/mobilePotrait_c&g19.pdf
https://github.com/aleju/imgaug
https://www.researchgate.net/publication/311609041_Deep_Residual_Learning_for_Image_Recognition
https://github.com/aleju/imgaug
https://divamgupta.com/image-segmentation/2019/06/06/deep-learning-semantic-segmentation-keras.html
https://paperswithcode.com/task/portrait-segmentation
All rights reserved
