Giới thiệu về Deep Learning, thư viện Keras
Bài đăng này đã không được cập nhật trong 6 năm
1. Deep Learning là gì
Trí tuệ nhân tạo đang len lỏi vào trong cuộc sống và ảnh hưởng sâu rộng tới mỗi chúng ta, các cụm từ "Artificial Intelligence", "Machine Learing", "Deep Learning" đã không còn quá xa lạ gì. Chúng ta cùng xem hình vẽ để mô tả lại mối quan hệ giữa artificial intelligence, machine learning, và deep learning:
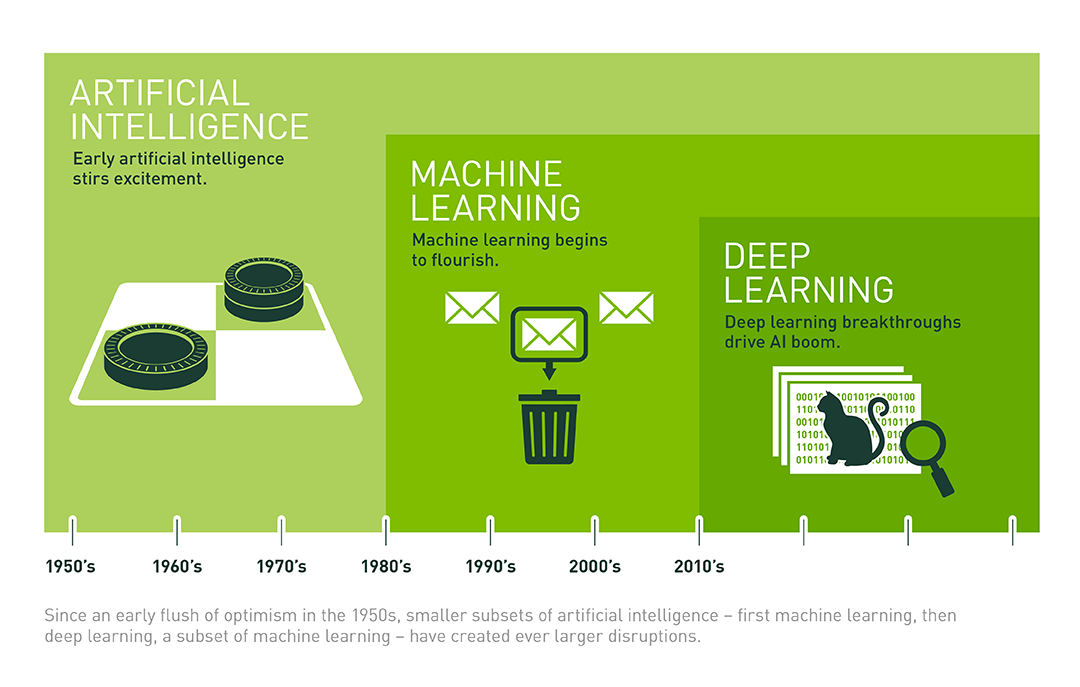
Deep learning đã và đang là một chủ đề AI được bàn luận sôi nổi. Là một phạm trù nhỏ của machine learning, deep learning tập trung giải quyết các vấn đề liên quan đến mạng thần kinh nhân tạo nhằm nâng cấp các công nghệ như nhận diện giọng nói, tầm nhìn máy tính và xử lý ngôn ngữ tự nhiên. Deep learning đang trở thành một trong những lĩnh vực hot nhất trong khoa học máy tính. Chỉ trong vài năm, deep learning đã thúc đẩy tiến bộ trong đa dạng các lĩnh vực như nhận thức sự vật (object perception), dịch tự động (machine translation), nhận diện giọng nói,… - những vấn đề từng rất khó khăn với các nhà nghiên cứu trí tuệ nhân tạo.
Để hiểu hơn về deep learning, hãy nhìn lại một số khái niệm cơ bản về trí tuệ nhân tạo.
Trí tuệ nhân tạo có thể được hiểu đơn giản là được cấu thành từ các lớp xếp chồng lên nhau, trong đó mạng thần kinh nhân tạo nằm ở dưới đáy, machine learning nằm ở tầng tiếp theo và deep learning nằm ở tầng trên cùng.
Deep Learning được nhắc đến nhiều trong những năm gần đây, nhưng nền tảng cơ bản đã xuất hiện từ rất lâu

Đã xuất hiện từ khá lâu nhưng kể từ năm 2012, deep learning mới có những bước đột phá lớn, hàng loạt các thư viện hỗ trợ deep learning ra đời. Cùng với đó, ngày càng nhiều kiến trúc deep learning ra đời, khiến cho số lượng ứng dụng và các bài báo liên quan tới deep learning tăng lên chóng mặt.
Đã xuất hiện từ khá lâu nhưng kể từ năm 2012, deep learning mới có những bước đột phá lớn, hàng loạt các thư viện hỗ trợ deep learning ra đời. Cùng với đó, ngày càng nhiều kiến trúc deep learning ra đời, khiến cho số lượng ứng dụng và các bài báo liên quan tới deep learning tăng lên chóng mặt.
2. Giới thiệu Keras
Các thư viện deep learning thường được ‘chống lưng’ bởi những hãng công nghệ lớn: Google (Keras, TensorFlow), Facebook (Caffe2, Pytorch), Microsoft (CNTK), Amazon (Mxnet), Microsoft và Amazon cũng đang bắt tay xây dựng Gluon (phiên bản tương tự như Keras). (Các hãng này đều có các dịch vụ cloud computing và muốn thu hút người dùng).
Sau đây là một vài thống kê để mọi người có cái nhìn tổng quan về các thư viện được sử dụng nhiều nhât
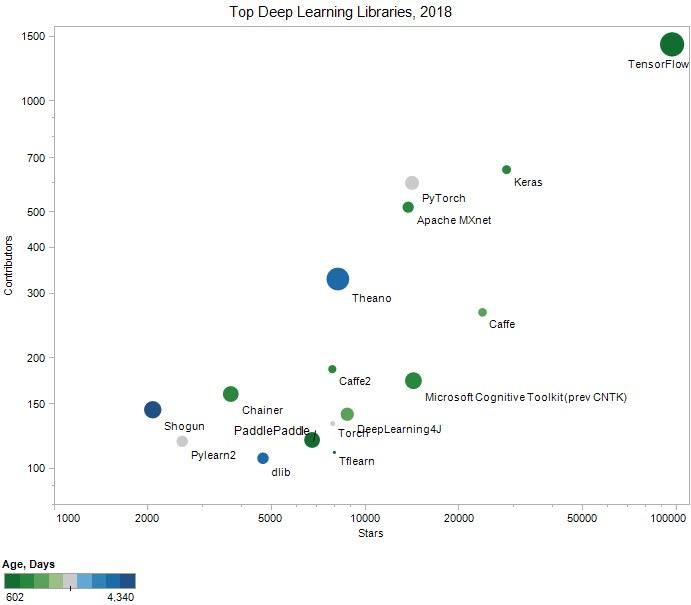
Số lượng "star" trên Github Repo, số lượng "Contributors" của các thư viện
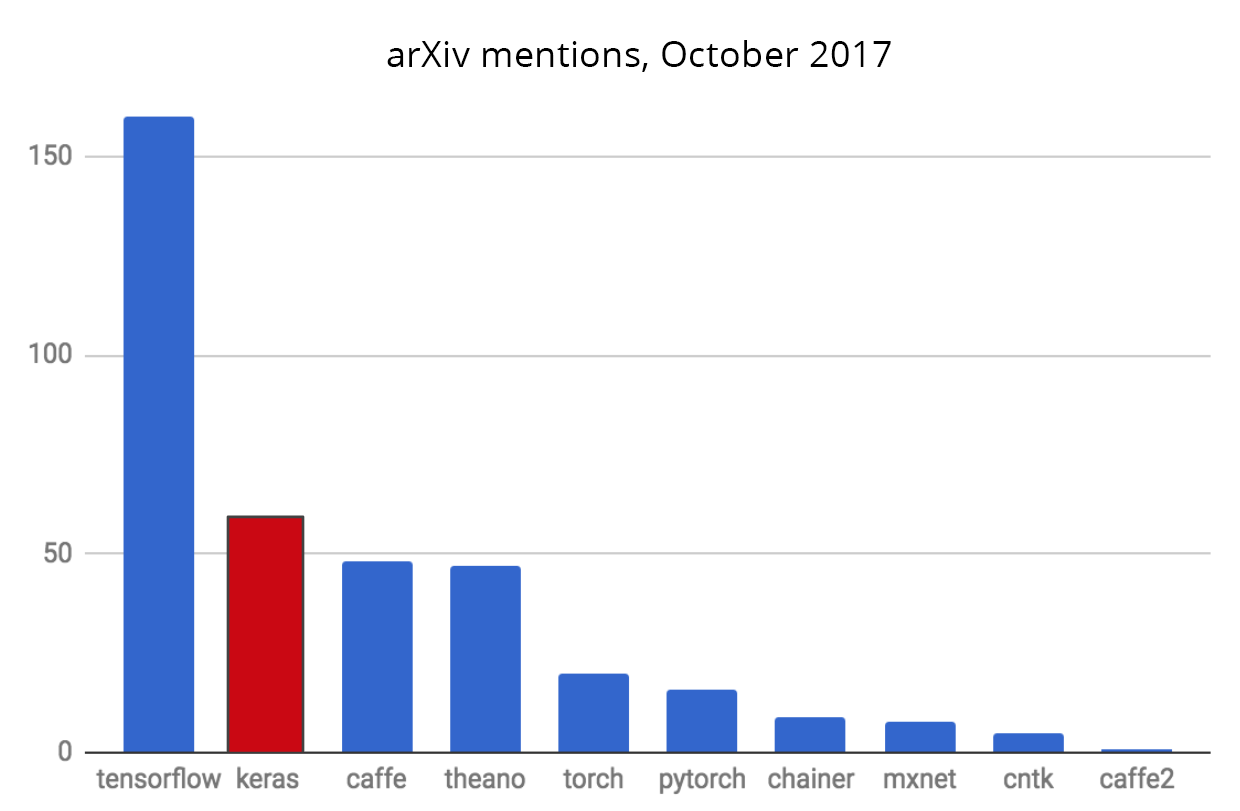
Số lượng các bài báo trên arXiv đề cập tới mỗi thư viện
Những so sánh trên đây chỉ ra rằng TensorFlow, Keras và Caffe là các thư viện được sử dụng nhiều nhất (gần đây có thêm PyTorch rất dễ sử dụng và đang thu hút thêm nhiều người dùng).
Keras được coi là một thư viện ‘high-level’ với phần ‘low-level’ (còn được gọi là backend) có thể là TensorFlow, CNTK, hoặc Theano. Keras có cú pháp đơn giản hơn TensorFlow rất nhiều. Với mục đích giới thiệu về các mô hình nhiều hơn là các sử dụng các thư viện deep learning, tôi sẽ chọn Keras với TensorFlow là ‘backend’.
Những lý do nên sử dụng Keras để bắt đầu:
-
Keras ưu tiên trải nghiệm của người lập trình
-
Keras đã được sử dụng rộng rãi trong doanh nghiệp và cộng đồng nghiên cứu
-
Keras giúp dễ dàng biến các thiết kế thành sản phẩm
-
Keras hỗ trợ huấn luyện trên nhiều GPU phân tán
-
Keras hỗ trợ đa backend engines và không giới hạn bạn vào một hệ sinh thái
3. Linear regression với Keras
Việc huấn luyện một mô hình deep learning hay neural network nói chung bao gồm các bước:
- Chuẩn bị dữ liệu
- Xây dựng network
- Chọn thuật toán cập nhật nghiệm, xây dựng loss và phương pháp đánh giá mô hình
- Huấn luyện mô hình.
- Đánh giá mô hình
Chúng ta cùng xem Keras thực hiện các bước này thông qua ví dụ dưới đây.
Ta cùng làm một ví dụ đơn giản. Dữ liệu đầu X vào có số chiều là 2, đầu ra y = 2X[0] + 3X[1] + 4 + e với e là nhiễu tuân theo một phân phối chuẩn có kỳ vọng bằng 0, phương sai bằng 0.2.
Dưới đây là đoạn code ví dụ về huấn luyện mô hình linear regression bằng Keras:
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras import optimizers
# 1. create pseudo data y = 2*x0 + 3*x1 + 4
X = np.random.rand(100, 2)
y = 2* X[:,0] + 3 * X[:,1] + 4 + .2*np.random.randn(100) # noise added
# 2. Build model
model = Sequential([Dense(1, input_shape = (2,), activation='linear')])
# 3. gradient descent optimizer and loss function
sgd = optimizers.SGD(lr=0.1)
model.compile(loss='mse', optimizer=sgd)
# 4. Train the model
model.fit(X, y, epochs=100, batch_size=2)
Kết quả
Epoch 1/100
100/100 [==============================] - 0s 5ms/step - loss: 1.7199
Epoch 2/100
100/100 [==============================] - 0s 709us/step - loss: 0.0388
Epoch 3/100
100/100 [==============================] - 0s 675us/step - loss: 0.0415
Epoch 4/100
100/100 [==============================] - 0s 774us/step - loss: 0.0392
Epoch 5/100
.....
Epoch 100/100
100/100 [==============================] - 0s 823us/step - loss: 0.0393
Ta thấy răng thuật toán hội tụ khá nhanh và MSE loss khá nhỏ sau khi huấn luyện xong.
Giải thích chút code nhé:
create pseudo data
-
Sequantial([<a list>]) là thể hiện việc các layer được xây dựng theo đúng thứ tự trong [<a list>]. Phần tử đầu tiên của list thể hiện kết nối giưa input layer và layer tiếp theo, các phần tử tiếp theo của list thể hiện kết nối của các layer tiếp theo.
-
Dense thể hiện một fully connected layer, tức toàn bộ các unit của layer trước đó được nối với toàn bộ các unit của layer hiện tại. Giá trị đầu tiên trong Dense bằng 1 thể hiện việc chỉ có 1 unit ở layer này (đầu ra của linear regression trong trường hợp này bằng 1). input_shape = (2,) chính là kích thước của dữ liệu đầu vào. Kích thước này là một tuple nên ta cần viết dưới dạng (2,). Về sau, khi làm việc với dữ liệu nhiều chiều, ta sẽ có các tuple nhiều chiều. Ví dụ, nếu input là ảnh RGB với kích thước 224x224x3 pixel thì input_shape = (224, 224, 3).
gradient descent optimizer and loss function
- Thể hiện việc chọn phương pháp cập nhật nghiệm, ở đâu ta sử dụng Stochastic Gradient Descent (SGD) với learning rate lr=0.1. Các phương pháp cập nhật nghiệm khác có thể được tìm thấy tại Keras-Usage of optimizers. loss='mse' chính là mean squared error, là hàm mất mát của linear regression.
Sau khi xây dựng được mô hình và chỉ ra phương pháp cập nhật cũng như hàm mất mát, ta huấn luyện mô hình bằng: #4
(Keras khá giống với scikit-learn ở chỗ cùng huấn luyện các mô hình bằng phương thức .fit()). Ở đây, epochs chính là số lượng epoch và batch_size chính là kích thước của một mini-batch.
Để xem hệ số tìm được của linear regression, ta sử dụng:
model.get_weights()
Kết quả
[array([[1.996118 ],
[3.0239758]], dtype=float32), array([3.963116], dtype=float32)]
ở đó, phần tử thứ nhất của list này chính là hệ số tìm được, phẩn tử thứ hai chính là bias. Kết quả này gần với nghiệm mong đợi của bài toán (y = 2X[0] + 3X[1] + 4).
4. Kết luận
-
Keras là một thư viện tương đối dễ sử dụng đối với người mới bắt đầu. Nó cung cấp các hàm số cần thiết với cú pháp đơn giản.
-
Khi đi sâu hơn vào deep learning trong các bài sau, chúng ta sẽ dần làm quen với các kỹ thuật lập trình với Keras. Hy vọng sau bài viết mọi người đã hiểu qua về Deeplearning cũng như thư viện Keras.
5. Tài liệu tham khảo
All rights reserved
