"Hello World" Machine Learning Project in Python Step-By-Step
Bài đăng này đã không được cập nhật trong 7 năm
Introduction
Bạn muốn làm machine learning với python, nhưng bạn đang gặp khó khăn khi bắt đầu?. Vậy bài viết này sẽ là sample với từng bước từng bước thực hiện để bạn có thể có được project đầu tiên về machine learning vs python. Let's start!
Các bước bạn sẽ cần phải làm:
- Download và cài đặt python3, python Scipy và những package hữu dụng nhất cho machine learning trong python
- Load dataset và hiểu về cấu trúc dữ liệu bằng cách sử dụng statistical summaries và data visualization.
- Xây dựng lên một vài machine learning models và chọn lấy cái mà bạn cho là best với bài toán của bạn.
How Do You Start Machine Learning in Python?
The best way mình nghĩ để bắt đầu học machine learning là bằng cách hiểu dưới dạng tổng quát một bài toán machine learning, sau đó thiết kế và hoàn thành các project nhỏ trước.
Beginners Need A Small End-to-End Project
Tất nhiên khi bắt đầu học một cái gì đó mới lạ, chúng ta thường có xu hướng đọc sách hoặc xem các course online khá nhiều, nhưng nhìn chung có một đặc điểm chung là chúng ta được thực hành rất ít nếu các nguồn này chỉ cung cấp về lý thuyết là phần nhiều, vì vậy chúng ta thường nhanh quên và khó hiểu bản chất vấn đề.
Việc hoàn thành một project nhỏ từ đầu tới cuối là rất quan trọng để có thể raise up level lên những bài toán khó và phức tạp hơn.
Một project machine learning có thể không tuyến tính, nhưng hầu hết nó đều đi qua các bước sau:
- Xác định bài toán, xác định vấn đề
- Chuẩn bị dữ liệu
- Đánh giá thuật toán
- Cải thiện kết quả
- Biểu diễn kết quả
Machine Learning in Python: Step by Step tutorial
Chúng ta sẽ bắt đầu thực hiện từng bước bài toán tại đây. Ở đây mình sẽ xây dựng bài toán classification cho Iris Flowers, bạn có thể download dữ liệu tại Iris flowers dataset
Các bước chúng ta sẽ thực hiện:
- Installing the Python and SciPy platform.
- Loading the dataset.
- Summarizing the dataset.
- Visualizing the dataset.
- Evaluating some algorithms.
- Making some predictions.
1. Downloading, Installing and Starting Python SciPy
Bước này các bạn tự tìm hiểu nha, có khá nhiều bài hướng dẫn trên mạng. Các bạn nên cài các packages sau để phục vụ cho các bài toán machine learning: python 3.5+, scipy, numpy, pandas, matplotlib, sklearn, ...
2. Load The Data
2.1 Import libraries
Đầu tiên, chúng ta sẽ import tất cả các modules, objects chúng ta sẽ sử dụng
# Load libraries
import pandas
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
2.2 Load Dataset
Chúng ta có thể load data trực tiếp từ UCI machine learning respo và sử dụng pandas để load dữ liệu, xác định cấu trúc dữ liệu qua thống kê và visualization.
# Load dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pandas.read_csv(url, names=names)
Nếu quá trình load data gặp vấn đề, bạn có thể down file iris.csv về local, rồi vẫn dùng công thức kia bằng cách thay url trỏ đến file csv ở local.
3. Summarize the Dataset
Bây giờ chúng ta sẽ dành 1 chút time để nhìn sơ qua về dataset xem chúng có những gì.
Dưới đây là một vài methods phổ biến:
3.1 Dimensions of Dataset
Sử dụng shape method để xác định xem dataset có bao nhiêu rows, bao nhiêu columns
print(dataset.shape)
(150, 5)
hoặc lấy 20 phần tử đầu tiên:
print(dataset.head(20))
Kết quả:
sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
5 5.4 3.9 1.7 0.4 Iris-setosa
6 4.6 3.4 1.4 0.3 Iris-setosa
7 5.0 3.4 1.5 0.2 Iris-setosa
8 4.4 2.9 1.4 0.2 Iris-setosa
9 4.9 3.1 1.5 0.1 Iris-setosa
10 5.4 3.7 1.5 0.2 Iris-setosa
11 4.8 3.4 1.6 0.2 Iris-setosa
12 4.8 3.0 1.4 0.1 Iris-setosa
13 4.3 3.0 1.1 0.1 Iris-setosa
14 5.8 4.0 1.2 0.2 Iris-setosa
15 5.7 4.4 1.5 0.4 Iris-setosa
16 5.4 3.9 1.3 0.4 Iris-setosa
17 5.1 3.5 1.4 0.3 Iris-setosa
18 5.7 3.8 1.7 0.3 Iris-setosa
19 5.1 3.8 1.5 0.3 Iris-setosa
3.2 Statistical Summary
Ở đây chúng ta sẽ xem sơ lược qua về dataset như số lượng, giá trị trung bình, min, max...
print(dataset.describe())
Kết quả:
sepal-length sepal-width petal-length petal-width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
3.3 Class Distribution
Thử xem mỗi class có bao nhiêu instances:
print(dataset.groupby('class').size())
Kết quả:
class
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
4. Data Visualization
Sau khi đã hiểu sơ qua về dataset, bây giờ mình sẽ xem dataset dưới một góc nhìn khác bằng một vài method visualizations.
Chúng ta sẽ xem 2 loại plots:
- Univariate plots to better understand
each attribute. - Multivariate plots to better understand
the relationships between attributes.
4.1 Univariate Plots
Chúng ta sẽ bắt đầu với một vài univariate Plots cho mỗi biến cá nhân. Ví dụ:
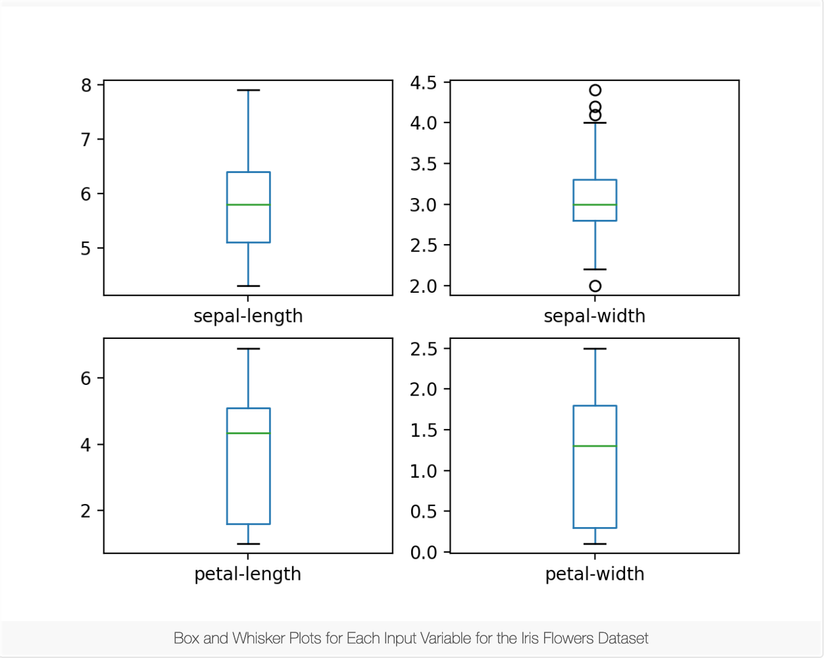
# box and whisker plots
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show()
Rõ ràng, nó đem lại 1 cái nhìn rõ ràng hơn về sự phân bố của mỗi thuộc tính đầu vào:
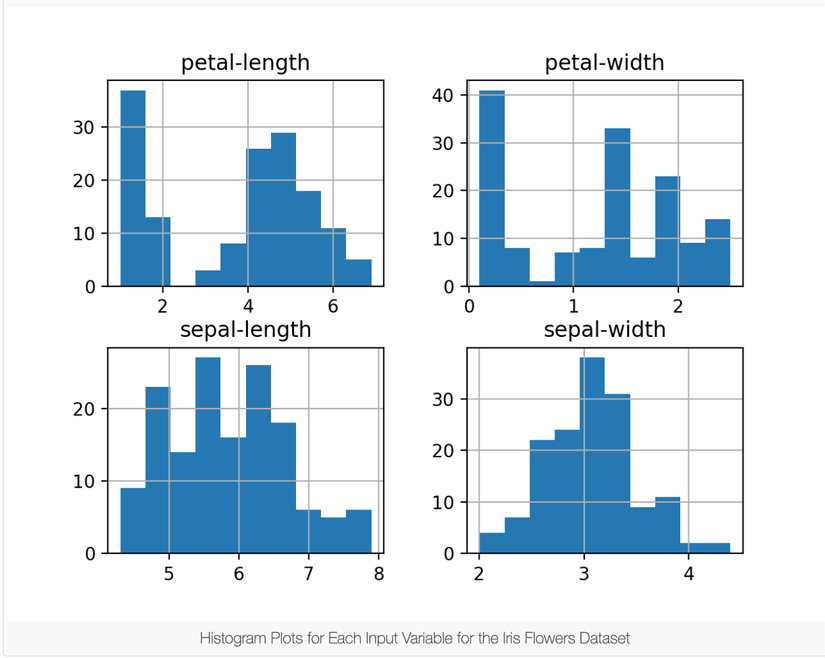
Hoặc, tạo một histogram cho mỗi biến đầu vào.
# histograms
dataset.hist()
plt.show()
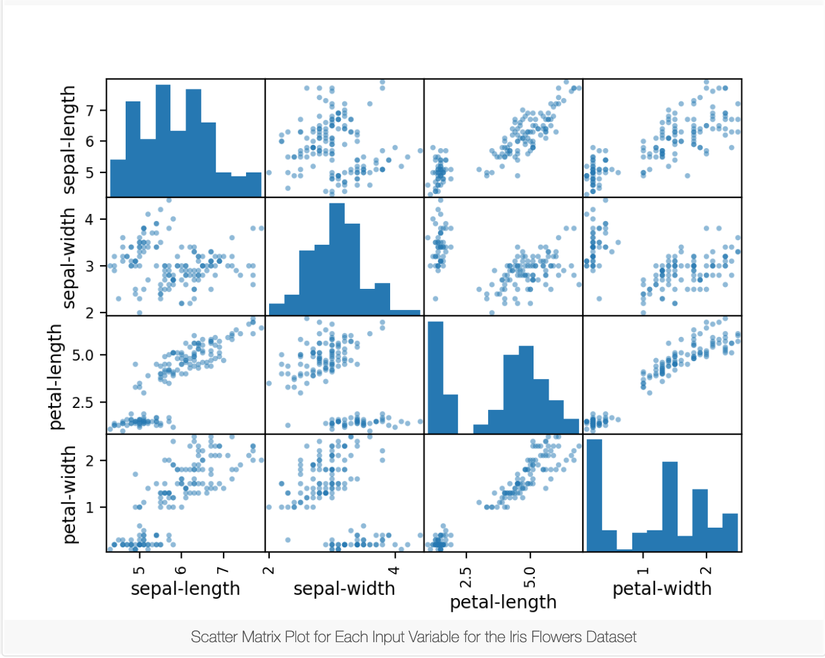
4.2 Multivariate Plots
Bây giờ chúng ta sẽ xem sự tương tác giữa các biến. Đầu tiên, chúng ta hãy nhìn vào điểm phân tán của tất cả các cặp thuộc tính. Điều này có thể hữu ích để phát hiện mối quan hệ có cấu trúc giữa các biến đầu vào.
# scatter plot matrix
scatter_matrix(dataset)
plt.show()
Lưu ý nhóm đường chéo của một số cặp thuộc tính, điều này cho thấy chúng có một mối tương quan lớn và một mối quan hệ có thể dự đoán được.
5. Evaluate Some Algorithms
Bây giờ chúng ta sẽ đi tạo một vào mô hình training cho dữ liệu, và ước lượng độ chính xác của chúng trên tập dữ liệu test.
5.1 Create a Validation Dataset
Chúng ta cần biết được models chúng ta vừa tạo có thực sự tốt hay không bằng cách sử dụng các phương pháp thống kê để ước lượng độ chính xác của models trên một tập dữ liệu được gọi là unseen data.
Bằng cách, giữ lại một phần nhỏ của tập dữ liệu ban đầu và phần này mô hình thuật toán sẽ không được training hay nhìn thấy (unseen data), để chuẩn bị cho bước tiếp theo, bước đánh giá độ chính xác thực sự của mô hình.
Chia dataset thành 2 phần, 80% cho training và 20% như một validation dataset.
# Split-out validation dataset
array = dataset.values
X = array[:,0:4]
Y = array[:,4]
validation_size = 0.20
seed = 7
X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split(X, Y, test_size=validation_size, random_state=seed)
5.2 Build Models
Thử đánh giá qua 6 thuật toán phổ biến:
- Logistic Regression (LR)
- Linear Discriminant Analysis (LDA)
- K-Nearest Neighbors (KNN).
- Classification and Regression Trees (CART).
- Gaussian Naive Bayes (NB).
- Support Vector Machines (SVM).
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma='auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=10, random_state=seed)
cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
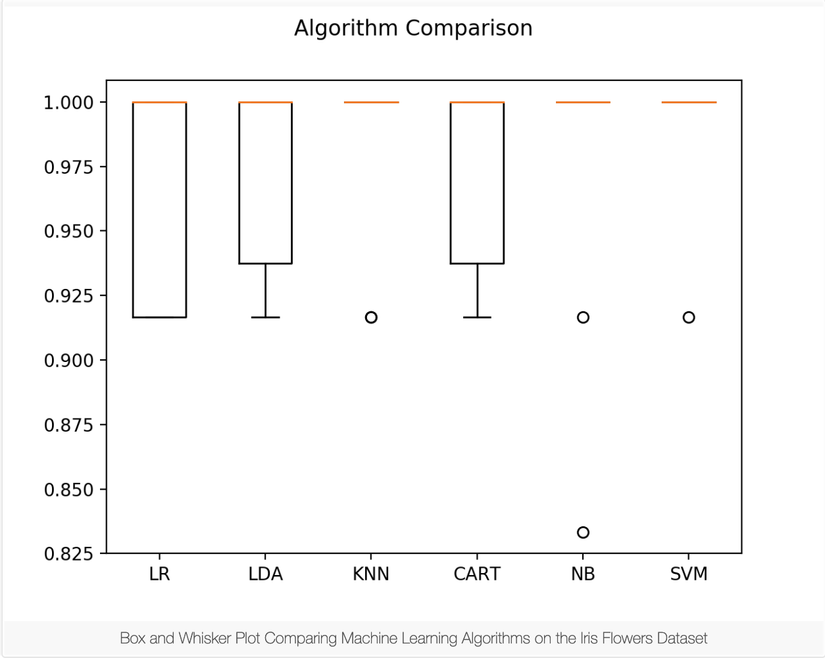
5.3 Select Best Model
Bây giờ chúng ta đang có 6 models và ước lượng độ chính xác cho từng cái, việc cần làm là so sánh chúng với nhau và chọn ra cái tốt nhất.
Chạy câu lệnh bên trên, chúng ta sẽ có được kết quả:
LR: 0.966667 (0.040825)
LDA: 0.975000 (0.038188)
KNN: 0.983333 (0.033333)
CART: 0.975000 (0.038188)
NB: 0.975000 (0.053359)
SVM: 0.991667 (0.025000)
Ở đây, chúng ta có thể dễ dàng thấy rằng thuật toán SVM có được độ chính xác cao nhất.
Tiếp theo, thử build một mô hình đánh giá kết quả, và so sánh về khả năng spread cũng như độ chính xác trung bình của mỗi model thuật toán.
# Compare Algorithms
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
6. Make Predictions
Chúng ta sẽ thử với thuật toán KNN, thì đây là thuật toán rất đơn giản và phổ biến, để xem độ chính xác của mô hình trên tập dữ liệu test thế nào.
Đây là một bước độc lập cuối cùng để biết xem mô hình mình xây dựng trên tập dữ liệu training, có chính xác với tập dữ liệu test hay không, vì có một vài trường hợp như overfitting trên tập dữ liệu training or data leak.
# Make predictions on validation dataset
knn = KNeighborsClassifier()
knn.fit(X_train, Y_train)
predictions = knn.predict(X_validation)
print(accuracy_score(Y_validation, predictions))
print(confusion_matrix(Y_validation, predictions))
print(classification_report(Y_validation, predictions))
Kết quả:
0.9
[[ 7 0 0]
[ 0 11 1]
[ 0 2 9]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.85 0.92 0.88 12
Iris-virginica 0.90 0.82 0.86 11
micro avg 0.90 0.90 0.90 30
macro avg 0.92 0.91 0.91 30
weighted avg 0.90 0.90 0.90 30
Summary
Ở bài này mình đã đi qua từ đầu đến cuối cho một bài toán nhỏ như "Hello world" trong machine learning, hi vọng nó sẽ có ích với mọi người. Thks for reading!.
All rights reserved
