
[Deep Learning]: Break 1 hệ thống captcha dễ hay khó?
Bài đăng này đã không được cập nhật trong 6 năm
I. Introduction
Xin chào mọi người, chúng ta vẫn tiếp tục sống trong những ngày tháng nhàn nhã nhất trong lịch sử do ảnh hưởng của virus corona, người work remotely, người study online, người tận dụng thời gian này để có 1 kỳ nghỉ holiday, cũng có người chọn cách nâng cao khả năng ngoại ngữ của mình...tớ chọn cách đọc sách và viết viblo nhiều hơn. Sau bài trước về việc làm thế nào để xây dựng 1 hệ thống Recommendation from scratch nhận được tín hiệu khá tích cực, thì ở bài này t sẽ chuyển sang chủ đề về Image Processing và Deep Learning: Làm thế nào để break 1 hệ thống captcha, làm thế nào để tự mình xây dựng 1 thuật toán deep learning từ những bước đầu tiên, từ việc code 1 script annotate data bằng cách tận dụng 1 vài thuật toán xử lý ảnh thay vì phải annotate hand-by-hand,.. Sẽ có nhiều thứ hay ho ở bài này để chúng ta cùng chia sẻ và bàn luận, tớ sẽ không vòng vo nữa, vào việc luôn đi cho nó nóng này!
- Có gì ở đây:
- Building the whole deeplearning model from scratch
- Data annotation by using script
- Using fine-tuning technique to enhance accuracy
- Evaluation model
- Improvement and Future work
II. What is captcha
Captcha là gì? Có lẽ nhiều người đã quen thuộc rồi và cũng gặp nhiều rồi, là 1 hệ thống dùng để xác thực trước khi các request được thực hiện, có thể hiểu nó như một phương thức security làm tăng tính bảo mật, tránh spams requests... cho một hệ thống nào đó, ví dụ:
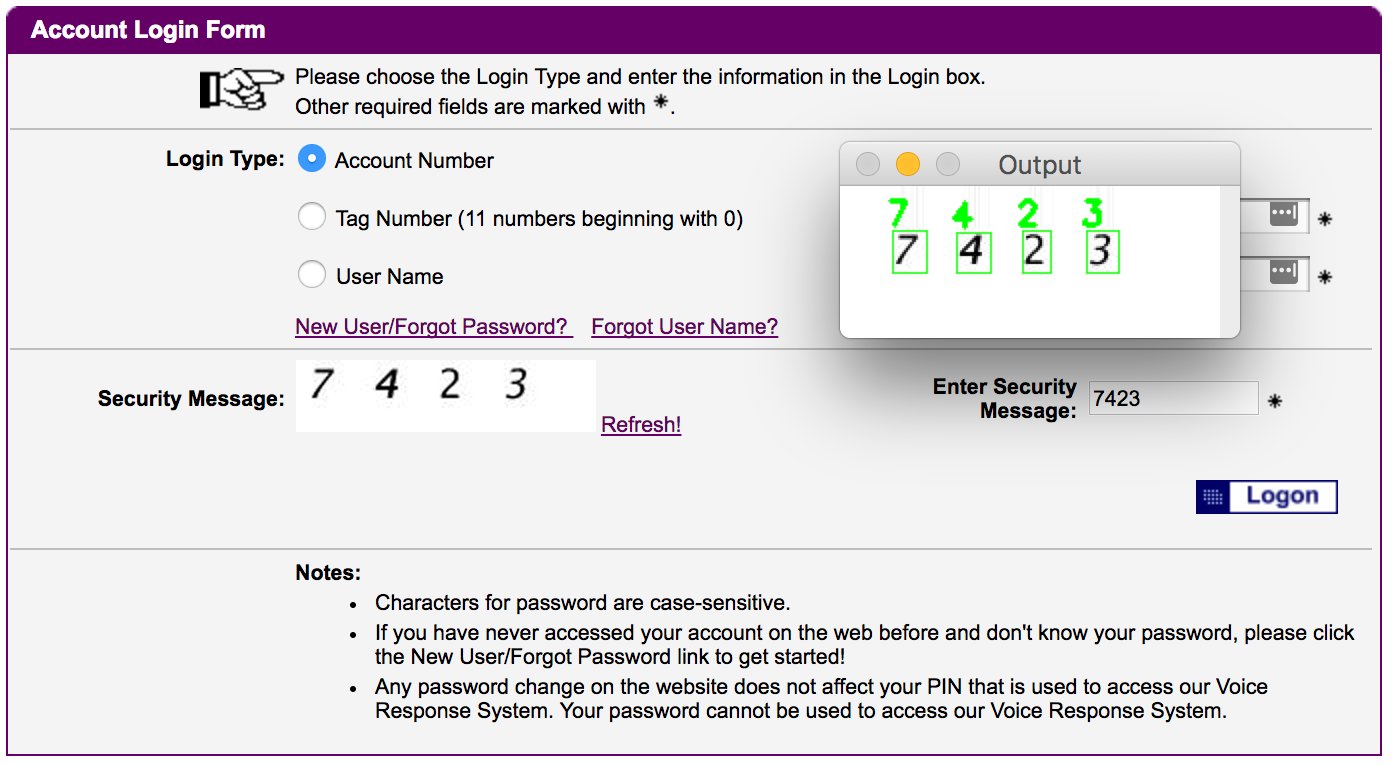
Captcha thường là 1 hình ảnh chứa các kí tự (4, 6, 8 kí tự...) hoặc cũng có thể là 1 ô checkbox thôi tuỳ vào từng hệ thống set up ra sao, nhiệm vụ của chúng ta là phải điền chính xác vào các ô này thì 1 request vào hệ thống mới được gửi đi và process...có thể thấy nó khá nhiều ở các giao dịch internet banking. Để hiểu hơn chúng ta cùng tìm hiểu về dataset nhé.
PS: Bài viết này tớ nhằm mục đích chia sẻ và học hỏi, không có ý định cổ vũ hoặc hướng dẫn cho những ai có mục đích xấu nha  , hãy tôn trọng đạo đức nghề nghiệp.
, hãy tôn trọng đạo đức nghề nghiệp.
III. Dataset
Dataset về captcha thì có trên mạng rồi, mọi người có thể lên google search là ra nếu không muốn dùng dataset của tớ, ở đây tớ dùng bộ dataset này, cùng xem qua xem nó có gì nhé.
Load image đã nhé:
def load_images(data_path):
image_paths = []
for sub_fol in os.listdir(data_path):
if sub_fol == ".DS_Store": continue
sub_fol_path = os.path.join(data_path, sub_fol)
if os.path.isfile(sub_fol_path): continue
for img in os.listdir(sub_fol_path):
if img == ".DS_Store": continue
img_path = os.path.join(sub_fol_path, img)
image_paths.append(img_path)
return np.array(image_paths)
image_paths = load_images(DATA_DIR)
Sau đó thì plot lên nào:


Có thể thấy ở đây nhiệm vụ của chúng ta là cần nhận diện ra những ký tự bao gồm các số từ 1-9 và các chữ cái từ A-Z, cách tiếp cận sẽ là như thế nào, làm thế nào để mô hình có khả năng generalize ra những ký tự này thì tớ sẽ trình bày ở bước tiếp theo đây.
3.1 Data Annotation
Cách tiếp cận là chúng ta sẽ đi break từng ký tự này ra rồi nhận diện từng ký tự 1, vậy chúng ta cần xây dựng 1 bộ dataset gồm, 1 bên là ảnh của từng ký tự, 1 bên là label là annotation của từng ảnh đó.
Có thể nói 1 trong thời đại AI nổi như bây giờ, data là cực kỳ quan trọng và thường chúng ta thường mất rất nhiều thời gian, công sức, con ngừoi để có được 1 bộ data phục vụ cho 1 bài toán AI. Nhưng ở bài này chúng ta có thể tận dụng được các phương pháp xử lý ảnh để có thể xây dựng được 1 bộ label phục vụ cho việc training bằng cách bạn chỉ cần bỏ ra từ 2-3 hours. Tớ sẽ show code example:
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.copyMakeBorder(gray, 8, 8, 8, 8, cv2.BORDER_REPLICATE)
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
plt.imshow(thresh, cmap="gray")
Ở đây, trước khi đến bước annotate, tớ chuyển hết ảnh về ảnh xám và add thêm 8 điểm pixel vào borders để xử lý cho những ảnh có chữ bị chèn vào viền, sao đó áp dụng threshold, cùng xem kết quả:

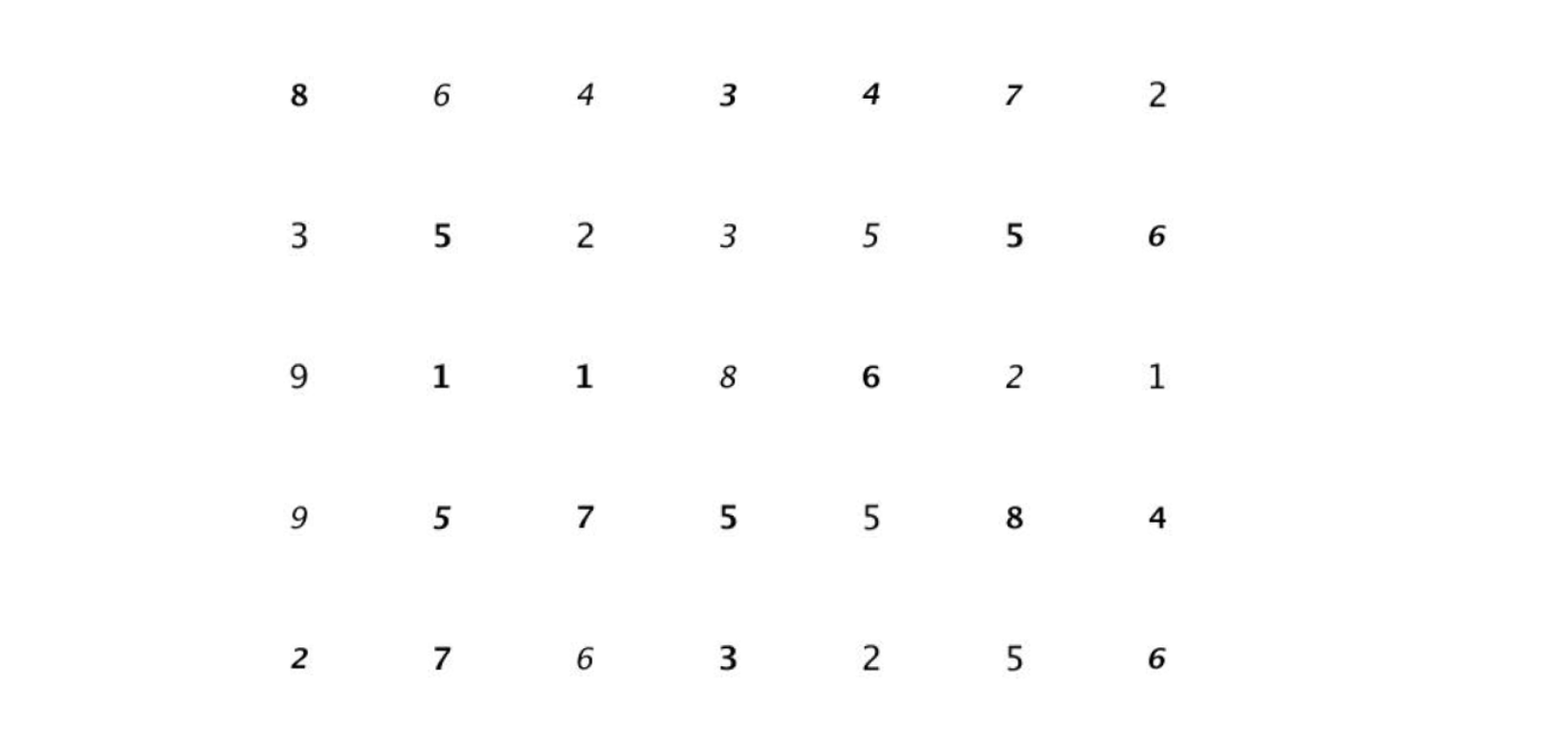
Bước tiếp theo cần làm là đi tìm contours cho từng con số này rồi tách chúng ra, thi thoảng chúng ta sẽ gặp phải những ký tự hơi sát và chèn vào nhau dẫn đến coutour sẽ bao gồm cả 2, vì vậy tớ sẽ kiểm tra xem nếu contour nào có chiều width quá lớn, tớ sẽ tách đôi.
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:4]
for c in cnts:
(x, y, w, h) = cv2.boundingRect(c)
if w > 40:
roi = gray[y-5:y+5+h, x-5:x + int(w/2)]
roi_2 = gray[y-5:y+5+h, x + int(w/2):x+5+int(w/2)]
rois = [roi, roi_2]
else:
roi = gray[y-5:y+5+h, x-5:x+5+w]
rois = [roi]
for roi in rois:
cv2.imshow("ROI", imutils.resize(roi, width=28))
key = cv2.waitKey(0)
Cùng xem kết quả nhá, example thế này cho dễ hiểu thui naz.
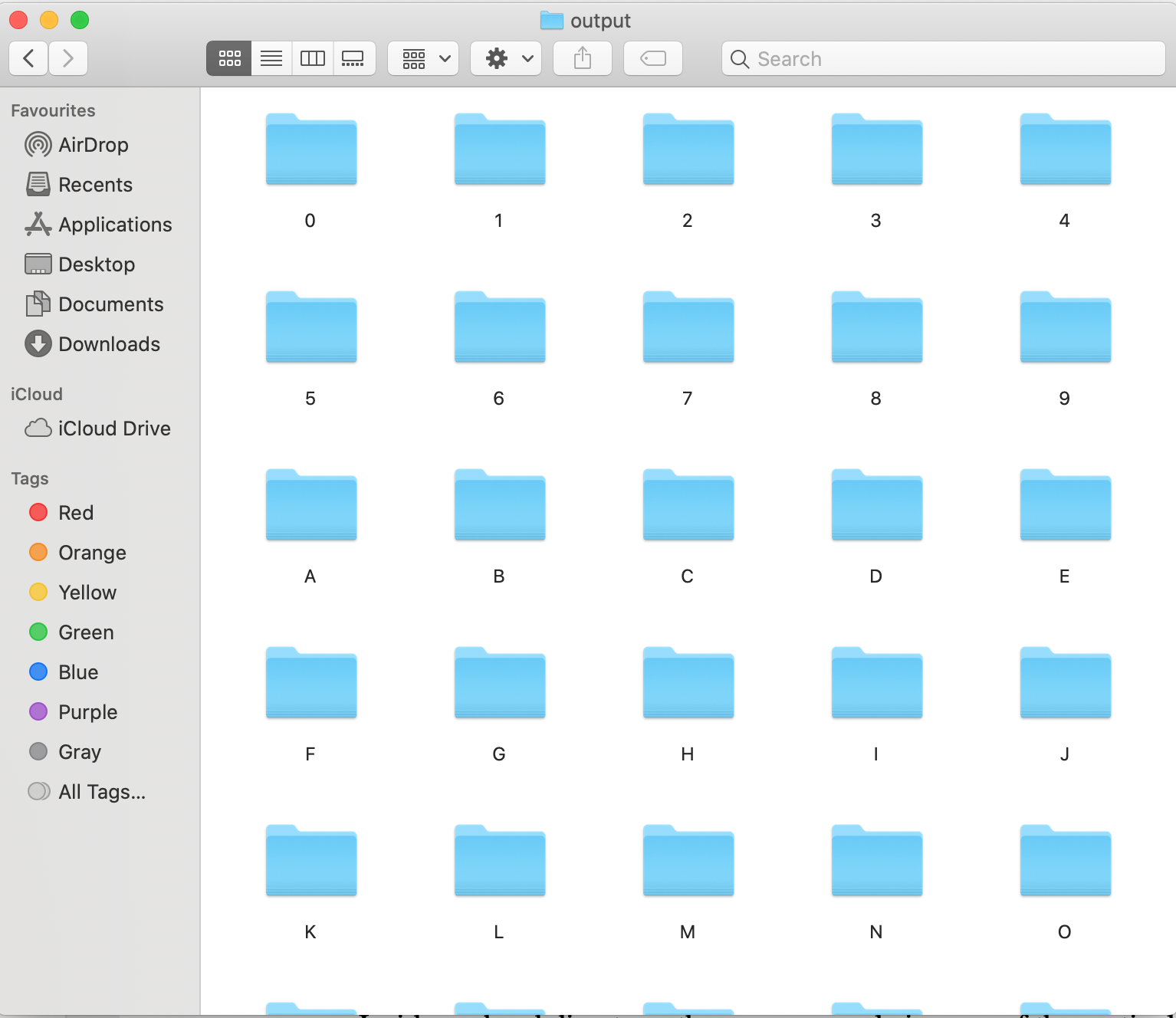
Bước cuối cùng là save các ký tự này vào từng file chứa từng ký tự riêng biệt:
if key == ord("`"):
print("[INFO] ignoring character")
continue
key = chr(key).upper()
dir_path = os.path.join(OUTPUT_DIR, key)
if not os.path.exists(dir_path):
os.mkdir(dir_path)
count = counts.get(key, 1)
p = os.path.join(dir_path, "{}.png".format(str(count).zfill(6)))
cv2.imwrite(p, roi)
counts[key] = count + 1
Đây là kết quả file annotation của tớ:
3.2 Image Preprocess
Trước khi đưa vào mô hình training, việc tiền xử lý dữ liệu là rất quan trọng, thường thì mỗi model sẽ require một kích thước xác định của ảnh và thường là ảnh vuông, nhưng trong thực tế thì chiều của các bức ảnh là vô cùng đa dạng. Cách đơn giản nhất ở đây chỉ là resize về đúng kích thước cần, nhưng đó không phải là 1 ý tưởng hay, vì sao, vì nó làm mất đi ratio của ảnh, làm ảnh méo mó khiến model phải học khó hơn rất nhiều. Ở đây t sẽ build 1 hàm giúp giải quyết việc này, cùng xem code nhé:
def preprocessing_image(self, image):
h, w, c = image.shape
d_w = 0
d_h = 0
if w > h:
image = imutils.resize(image, height=HEIGHT)
d_w = int((image.shape[1] - WIDTH)/2)
else:
image = imutils.resize(image, width=WIDTH)
d_h = int((image.shape[0] - HEIGHT)/2)
image = image[d_h:image.shape[0]-d_h, d_w:image.shape[1]-d_w]
image = cv2.resize(image, (HEIGHT, WIDTH), interpolation=cv2.INTER_AREA)
return image
Đó vậy là xong bước tiền xử lý oy, giờ qua bước tiếp theo là xây dựng 1 cái DataGeneration, thì tại sao cần cái này t sẽ nói rõ.
3.3 Data Generation
Hầu như dataset trong các bài toán chúng ta cần giải quyết là rất lớn, sẽ là 1 cách không hay nếu ta load thẳng chúng vào memory để train và không phải ai trong chúng ta cũng có phần cứng tốt để xử lý cho vấn đề này, đó là lý do vì sao người ta sinh ra việc train theo batch, các thuật toán gradient descent theo batch... Tớ sẽ show 1 đoạn code mẫu về việc gen batch ra sao nhé:
def next_train(self):
if self.current_train + self.batch_size > len(self.train_X_paths):
self.current_train = 0
self.train_X_paths, self.train_y = shuffle(self.train_X_paths, self.train_y, random_state=42)
batch_img_paths = self.train_X_paths[self.current_train:self.current_train + self.batch_size]
batch_imgs = self.load_image(batch_img_paths)
batch_labels = self.train_y[self.current_train:self.current_train+self.batch_size]
self.current_train += self.batch_size
return batch_imgs, batch_labels
def next_test(self):
if self.current_test+ self.batch_size > len(self.test_X_paths):
self.current_test = 0
self.test_X_paths, self.test_y = shuffle(self.test_X_paths, self.test_y, random_state=42)
batch_img_paths = self.test_X_paths[self.current_test:self.current_test + self.batch_size]
batch_imgs = self.load_image(batch_img_paths)
batch_labels = self.test_y[self.current_test:self.current_test+self.batch_size]
self.current_test += self.batch_size
return batch_imgs, batch_labels
def get_batch(self, s="train"):
while True:
if s == "train":
batch_X, batch_y = self.next_train()
else:
batch_X, batch_y = self.next_test()
yield (batch_X, batch_y)
Đó thế thui, đơn giản mà nhỉ, nếu có chỗ nào nhầm lẫn hoặc không hiểu các bạn cứ comment bên dưới nhé. Bước tiếp theo chúng ta cần làm là xây dựng model nhở =))
IV. Model Architecture
Đến đây có 3 cách chúng ta có thể dùng, 1 là tự xây dựng 1 model theo cách riêng của từng cá nhân, cách 2 là sử dụng feature extraction bằng cách sử dụng 1 model extract ra các features của từng ảnh rồi build on top 1 thuật toán classification như Logistic Regression,... Nhưng tớ chọn cách cuối cùng: Fune-tuning, lý do là nó tốt, nó cho accuracy tốt thui, còn vì sao nó tốt thì có lẽ nếu có time t sẽ chia sẻ ở những bài sau nhé.
Ở đây tớ dùng VGG-16 làm base model, weights được train trên tập imagenet. Load nó lên rồi bỏ tầng Fully-Connected đi:
base_model = VGG16(weights="imagenet", include_top=False, input_shape=(HEIGHT, WIDTH, CHANNEL))
Cách thực hiện fine-tuning với 1 model là loại bỏ đi 1 cơ số các tầng rồi lắp thêm vào chúng 1 bộ tầng mới, như kiểu bỏ cái đầu cũ rồi thêm 1 cái đầu mới. Chúng ta có thể bỏ ở bất kỳ đâu, tuy nhiên hầu hết, phần lớn, best choice là loại bỏ đi từ tầng Fully-connected.
Đối với fine-tuning, các base model thường đã được train trên 1 tập dataset lớn, đa dạng nên nếu chúng ta sau khi lắp 1 bộ head model mới vào và thực hiện training ngay có thể phá hỏng đi các weight đã được học từ trước ở base_model, vì vậy chúng ta cần 1 bước gọi là làm nóng "Warm-up", giúp khởi động các Fully-connected rồi mới thực hiện training trên toàn bộ model. Thì đầu tiên, tốt hơn cả chúng ta cần đóng băng tất cả các tầng ở base_model lại:
for layer in base_model.layers:
layer.trainable = False
Rồi xây dựng một cái đầu mới cho base_model như thế này:
class FCHeadNet:
@staticmethod
def build(base_model, classes, D):
head_model = base_model.output
head_model = Flatten(name="Flatten")(head_model)
head_model = Dense(D, activation="relu")(head_model)
head_model = Dropout(0.5)(head_model)
head_model = Dense(classes, activation="softmax")(head_model)
return head_model
head_model = FCHeadNet.build(base_model, len(le.classes_), 256)
model = Model(inputs=base_model.input, outputs=head_model)
model.summary()
Xong rồi, giờ xem qua xem kiến trúc model mới xem sao nhé:
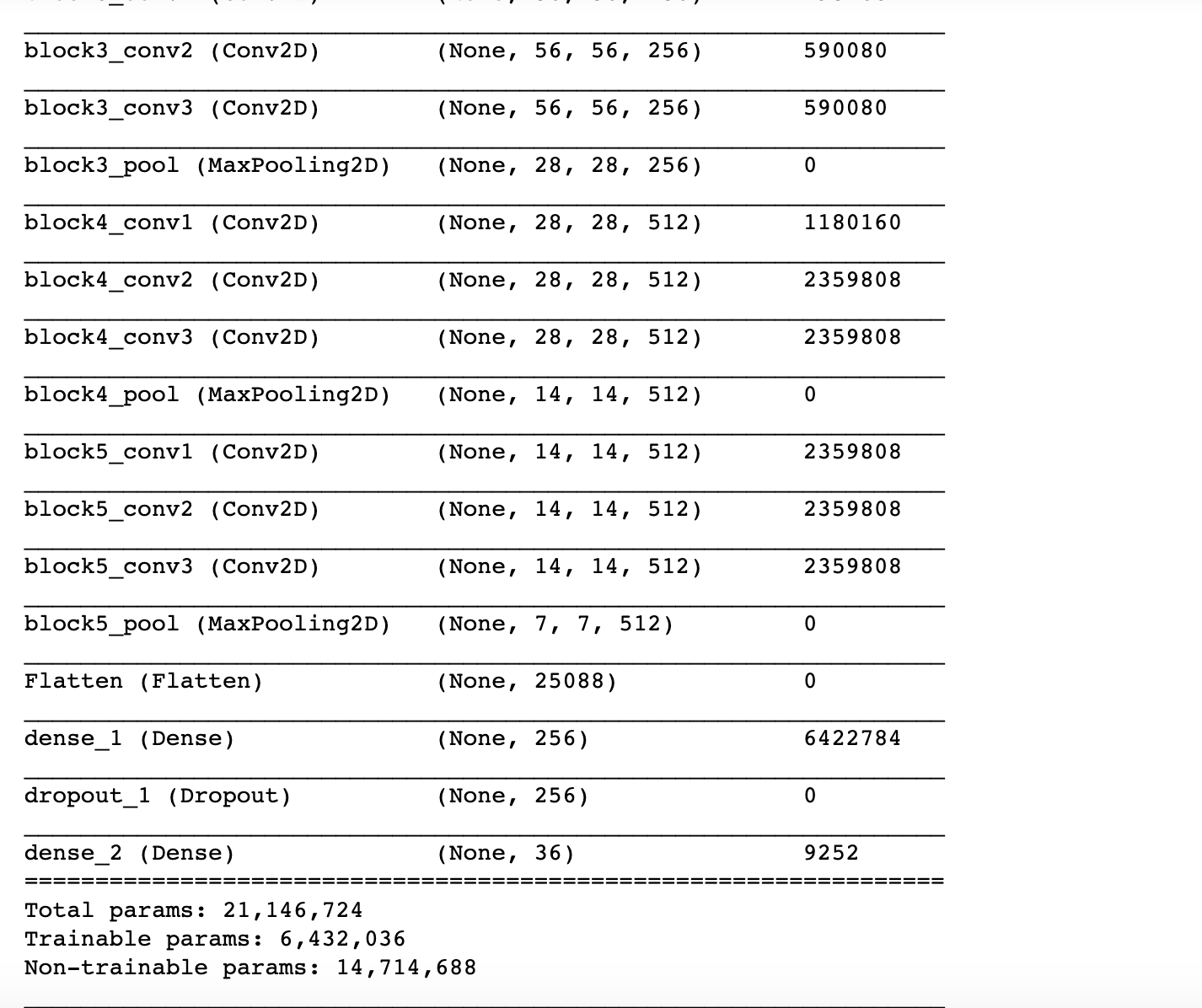
Có thể dê dàng nhận thấy tổng số lượng params và số lượng params có thể tuning là khác hẳn nhau, nguyên nhân là do chúng ta đã đóng băng hết tất cả layers ở tầng base model rồi. Okie giờ, có model và có datagenerator rồi, thì fit vào train thui. Bước trên này nhằm mục đích warm-up, vì vậy chúng ta chỉ train trên 1 lượt epochs nhỏ thui, và mình nhận được lời khuyên từ các books mình đã từng đọc là từ 10-30 epochs tuỳ thuộc vào từng dataset khác nhau.

Kết quả sau 25 epochs đầu tiên, cũng khá ổn, mọi người có thể nhận thấy val_acc cao hơn so với train_acc, thì khả năng cao là các case model phải học ở tập train là khó hơn so với ở tập validate. Điều này chứng minh là model đang đi đúng hướng, tiếp theo chúng ta mở 1 số layers ra rồi train thêm 100 epochs nữa nhé (của mình là mở từ layer 15 trở đi vì mô hình VGG đã rất sâu rồi nên mình chỉ mở đến đây thôi):
for layer in model.layers[15:]:
layer.trainable = True
Thực hiện train tiếp:
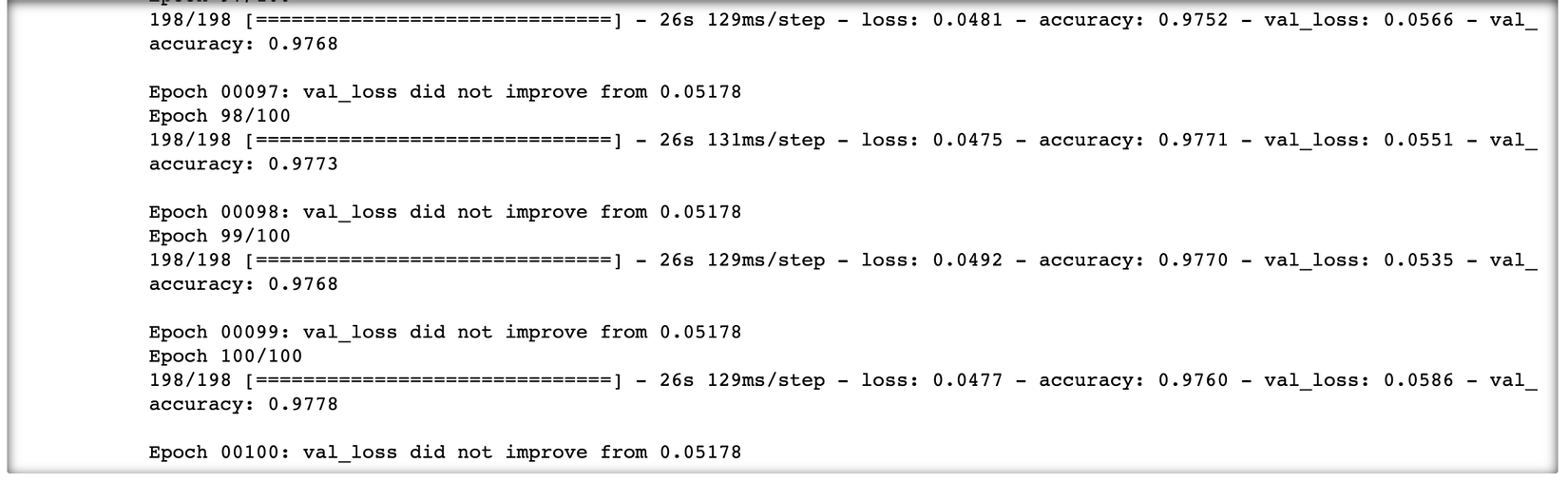
Đây là kết quả cuối cùng sau 100 epochs, chúng ta sẽ plot quá trình training lên để hiểu rõ hơn về sự biến đổi, quá trình hội tụ của model xem sao nhé:
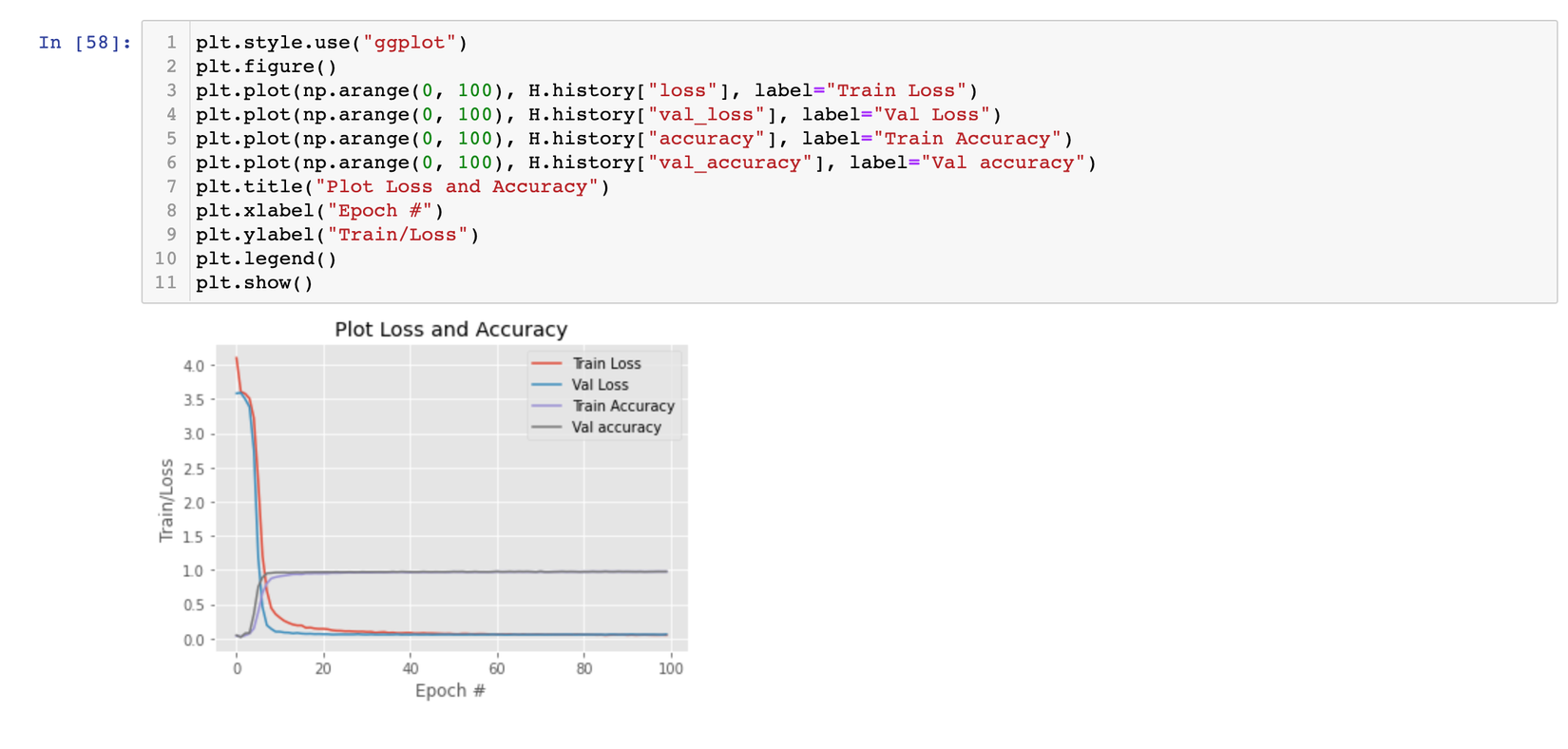
Có vẻ như là rất tốt, model đạt được cả train accuracy và val accuracy là khá cao. Xem qua thống kê 1 chút nào:

Bây giờ cùng nhau thực hiện vài prediction xem sao nhé:


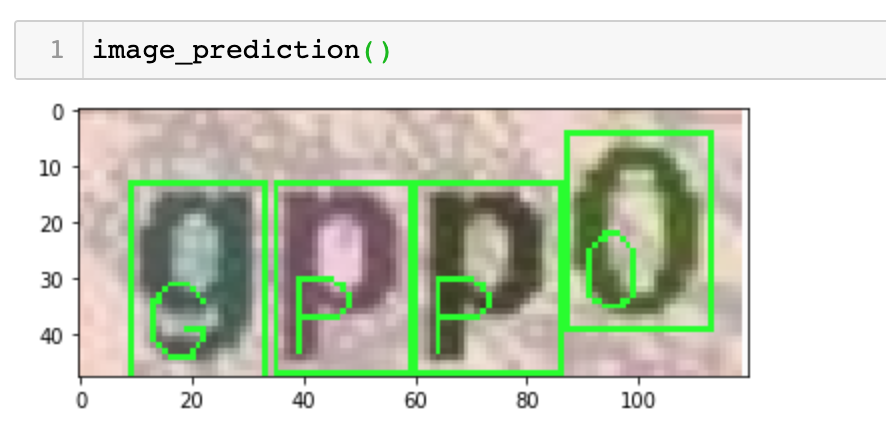
Ổn quá phải không nào =)) tuy nhiên chúng ta vẫn chưa nên hài lòng về kết quả này, làm sao để có kết quả tốt hơn nữa, làm sao để model predict nhanh hơn mà vẫn cho accuracy cao, thì tiếp theo mình cùng bàn luận ở bước tiếp theo nhé.
V. Improvement and Future Work
Đến đây, tớ vẫn chưa thực sự hài lòng về tốc độ predict, lý do là bởi vì mạng vgg là khá sâu và lượng tham số mô hình là rất lớn => giảm tốc độ predict của mô hình, cách làm là chúng ta có thể thay thế mô hình mạng cổ điển như VGG bằng các mạng khác như MobileNet, ResNet, Xception. Việc tại sao MobileNet lại nhanh mà vẫn cho được kết quả tốt là bởi có sự ra đời của Separable convolution (mọi người đọc thêm bài của tớ ở đây nhé, tớ đã giải thích rất rõ).
Tiếp theo đó là việc apply Data augmentation, change optimizer mới như ADam chẳng hạn hoặc là apply 1 learning rate scheduler, tiền xử lý data nhiều hơn cho những case khó như các case chèn vào nhau, overlap.
Về phạm vi bài này, chúng ta đang làm đó là recognize ra những ký tự captcha, chúng ta hoàn toàn có thể apply cách tiếp cận này cho những bài toán khác như nhận diện biển số xe (Plate Recognition), hoặc các bài toán có cách xử lý tương tự.
VI. References
https://viblo.asia/p/recommendation-system-tu-con-so-0-den-hoan-chinh-co-gi-gDVK2640KLj
https://cs231n.github.io/transfer-learning/
http://cs231n.stanford.edu/reports/2017/pdfs/300.pdf
All rights reserved
