
CenterNet: Keypoint Triplets for Object Detection - Hướng đi mới trong bài toán Object Detection
Bài đăng này đã không được cập nhật trong 5 năm
I. Giới thiệu
Chắc hẳn các bạn đã nghe nhiều đến bài toán Object Detection trong Computer Vision. Các mô hình đang được sử dụng rộng rãi hiện nay như: Yolo, Single Shot Detector, Faster-RCNN,... đều đang sử dụng chung một kĩ thuật anchor boxes để xác định kích thước đối tượng trên ảnh đầu vào. Tuy nhiên để sử dụng kĩ thuật này, chúng ta cần sinh ra một lượng lớn bounding boxes dựa trên tập anchor boxes được định sẵn cùng với các chỉ số offset được điều chỉnh một cách thủ công (offset- ở đây các bạn có thể hiểu đơn giản là tham số điều chỉnh độ dài rộng của anchor boxes), sau đó loại đi những bounding box thừa thãi dựa trên chỉ số IoU. Vậy một câu hỏi đặt ra Tại sao không thiết kế một mô hình sinh ít bounding box thôi để giảm bớt thời gian xử lý nhưng vẫn tăng được độ chính xác ?.
Và CenterNet sinh ra để giải quyết câu hỏi này. Một chú ý khá hay ho là: Có hai paper cùng tên CenterNet cùng giải quyết bài toán Object Detection, cùng được công bố năm 2019, cùng một hội nghị. Đó là : CenterNet: Objects as Points
và CenterNet: Keypoint Triplets for Object Detection. Cả hai phương pháp này đều dựa trên keypoint để sinh ra các bounding box để xác định đối tượng. Tuy nhiên trong giới hạn bài hôm nay, mình chỉ đề cập tới paper CenterNet: Keypoint Triplets for Object Detection do có độ chính xác trong báo cáo cao hơn cả.
II. CenterNet: Keypoint Triplets for Object Detection.
Thực ra ý tưởng nhận diện đối tượng bằng keypoint không phải mới. Trước đây, đã có một số nghiên cứu trong đó nổi bật nhất là Corner-Net giải quyết bài toán object detection dựa trên phương pháp này. Mỗi đối tượng được Corner-Net xác định dựa trên hai keypoint đặc trưng hai góc bottom right và top left. Tuy nhiên chính việc xác định đối tượng dựa trên hai góc khá nhạy cảm, dễ bị nhầm với các đặc trưng cạnh nếu có trong ảnh đầu vào. Hơn nữa, khả năng xác định hai keypoint đó có là hai góc của cùng một đối tượng (object) hay không cũng gặp nhiều vấn đề. Do khả năng học yếu các thông tin toàn cục và các keypoint góc thường nằm bên ngoài đối tượng do đó rất khó khăn để nhóm hai góc là cùng của một đối tượng. Để giải quyết vấn đề này, CenterNet đã học thêm những global information và một trong những cách đó là thêm một keypoint cho điểm trung tâm(center) của đối tượng. Như vậy, CenterNet xác định đối tượng dựa trên ba keypoint: Top left, Bottom right và Center. Và đây cũng là lý do cho cái tên Keypoint Triplets (3 keypoints).
1. Tổng quan kiến trúc Centernet
 Hình 1: Kiến trúc mạng CenterNet
Hình 1: Kiến trúc mạng CenterNet
Centernet dựa trên kiến trúc CornerNet làm cơ sở. Đi qua một backbone CNN trích xuất các đặc trưng từ ảnh, sau đó sử dụng hai lớp pooling đặc biệt để sinh ra các heatmap cho Corner và Center keypoint. Hai lớp đó là : Cascade Corner Pooling và Center Pooling. Chính hai lớp này giúp cho mô hình cải thiện về cả độ chính xác và FD(false discovery so với CornerNet nhờ vào khắc phục nhược điểm CornerNet mình đã nêu bên trên.
Trong bài tác giả có đề cập đến khái niệm FD(false discovery) và Heatmap(bản đồ nhiệt).
- Nếu như AP(average precision là giá trị đánh giá độ chính xác của mô hình xác định đối tượng (object detector) như SSD, Faster-RCNN,... ở IoU = [0.05:0.05:0.5] trên một tập dataset cụ thể như MS-COCO,...Ngược lại, FD là giá trị đo lường số lượng bounding box không chính xác hay có tỉ lệ IoU dưới ngưỡng cho trước. Ví dụ : CornerNet đạt 32.7% ở IoU = 0.05. Điều đó có ý nghĩa là cứ 100 object thì lại có 32.7 object có tỉ lệ IoU dưới 0.05.
 Hình 2: Minh họa bản đồ nhiệt (Heatmap).
Hình 2: Minh họa bản đồ nhiệt (Heatmap).
Ảnh gốc các bạn có thể xem ở đây nhé.
- Heatmap hay bản đồ nhiêt. Mỗi điểm trên bản đồ nhiệt tương ứng với một keypoint cùng với score là xác suất keypoint là tâm của một đối tượng . Ví dụ với một ảnh đầu vào có kích thước là (W, H, 3). Sau khi đi qua một mạng backbone có stride = R thì ta sẽ có một bản đồ nhiệt có kích thước (W/R, H/R, C). Nếu một điểm trên heatmap có giá trị bằng 1 tương ứng với một keypoint, còn bằng 0 tương ứng với một điểm background.
Nắm sơ sơ thế rồi, nào mình cùng khám phá sâu bên trong kiến trúc của CenterNet nào. Let's go 
1.1. Center Pooling
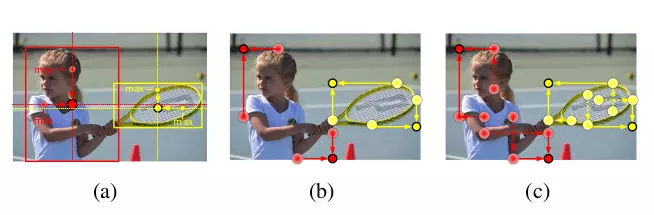 Hình 3: Center Pooling Layer (ảnh a )
Hình 3: Center Pooling Layer (ảnh a )
Điểm giữa của một đối tượng không thể ba gồm toàn bộ đặc điểm nhận dạng của đối tượng đó. Ví dụ : Điểm giữa của con người thường nằm ở phần thân trong khi phần đầu mà là phần quan trọng nhất giúp ta nhận ra đối tượng. Để giải quyết vấn đề này, tác giá đã đề xuất ra lớp Center Pooling giúp mô hình có thể học nhiều hơn thông tin toàn bộ đối tượng. Lớp pooling này nhận đầu vào là feature map được trích xuất qua một mạng CNN, sau đó nếu xác định một pixel nào là một điểm center keypoint, ta sẽ cộng với giá trị này với giá trị lớn nhất theo cả chiều dọc và ngang từ pixel đó. Chính nhờ việc cộng thêm giá trị lớn nhất đã giúp mô hình học thêm đặc trưng của cả đối tượng.
Bây giờ ta tận dụng các center keypoint được xác định theo các bước sau đây :
- Sinh ra k bounding boxes bằng thuật toán sử dụng trong paper CornerNet
- Chọn k center keypoints có score xác suất cao nhất
- Sử dụng các offset tương ứng với các keypoint đó để xác định các center keypoints đó trên ảnh đầu vào
- Xác định một vùng nằm giữa mỗi bounding box
- Kiểm tra nếu center keypoint nằm ở trong vùng này thì giữ nguyên bounding box, còn nếu không thỉ bỏ. Độ chính xác của mỗi bounding box này bằng trung bình độ chính xác của ba keypoint xác định nó. Lưu ý : Kích thước của vùng giữa mỗi bounding box ảnh hưởng đến kết quả của việc detection. Nếu vùng giữa nhỏ trong một bounding box nhỏ dễ dẫn đến hiện tượng lower recall do center keypoint dễ nằm bên ngoài vùng này. Còn vùng giữa lớn đối với những bounding box lớn thì dễ dẫn tới hiện tượng low precision do các keypoint không phải là center keypoint cũng nằm trong vùng này nên được giữ lại.
Sau bước này ta thu được keypoint center cùng với các bounding boxes. Tuy nhiên các bounding boxes này chưa thực sự chính xác và cần được chỉnh lại bằng kết hợp với Cascade Corner Pooling.
1.2. Cascade Corner Pooling
Hình 4: Cascade Corner Pooling (ảnh c )
Cascade Corner Pooling sinh ra để khắc phục khả năng học thông tin toàn cục yếu của lớp Corner Pooling trong CornerNet. Lớp pooling này tìm keypoint góc bằng cách tìm giá trị lớn nhất trên một đường viền (boundary). Sau đó dọc theo giá trị lớn nhất đó nhìn vào trong đối tượng để tìm giá trị lớn nhất nội bộ (internal maximum value), sau đó cộng hai giá trị lớn nhất này lại với nhau. Ví dụ nếu đang xét ở topmost boundary thì nhìn dọc xuống bottom, ở leftmost boundary thì dọc sang phải,..... Nhờ cách này mà góc chứa cả thông tin trên đường viền (boundary infomation) và thông tin của đối tượng
2. Loss function
2.1. Focal Loss
Focal loss thực chất được cải tiến từ cross entropy loss với cải tiến nhằm hạn chế sự mất cân bằng giữa hai class positive( bounding box chứa object) và negative (bounding box chứa background). Vì thông thường số lượng negative lớn hơn số lượng positive rất nhiều.
Ta có thể thấy điều đó qua công thức hàm cross entropy loss:
CE =
Trong đó:
- M: số class
- p: xác suất dự đoán đối tượng o thuộc class c
- y: 0 nếu class c đúng là lớp của đối tượng o
Công thức cross entropy loss coi một đối tượng quan tâm (positive object) hay không quan tâm (negative object) là giống nhau. Do đó nó dễ dàng học được các negative object do có số lượng nhiều hơn positive object rất nhiều nên ảnh hưởng mạnh lên hàm loss. Để khắc phục sự mất cân bằng này, người ta có đề xuất một hàm loss mới là Balanced Cross Entropy:
CE =
Trong đó = , là tần suất của class c. Ở đây có thêm a dương rất nhỏ để tránh trường hợp mẫu bằng 0.
Sử dụng hàm này thì những classes xuất hiện ít hơn vẫn tác động tới loss function lớn hơn so với cross entropy truyền thống. Tuy nhiên, cách này vẫn chưa thực sự triệt để. Do đó Focal loss đã ra đời. Để thuận tiện cho việc tính toán, đặt = .
Công thức Focal Loss : FL() = -
Do những object chiểm đa số, xác suất dự đoán p thường cao do gradient descent có xu hướng học tập điều đó. Tuy nhiên nhờ việc thêm nhân tử (1 - nên những object như vậy dường như không tác động lên nhiều lên hàm loss.
2.2. CenterNet Loss
Ở paper lần này, tác giả định nghĩa một hàm loss để train mô hình :
L = + + + + ( + )
trong đó:
- và là focal loss dùng để xác định corner và center keypoint
- là "push" loss dùng để tối đa khoảng cách tối đa cho những embedding vector của những object khác nhau.
- là "pull" loss dùng để tối ưu khoảng cách của các embedding vector cho cùng một object.
- và là L1 loss dùng để dự đoán những chỉ số cho center và corner keypoint tương úng với các chỉ số tùy vào loss function tương ứng.
III Lời kết
CenterNet là một ý tưởng khá mới mẻ bên cạnh những mô hình dựa trên anchor đã xuất hiện từ lâu. Ở paper này, tác giá đề xuất xác định đối tượng dựa trên ba keypoint: hai corner và một center keypoint và đã đạt được độ chính xác vượt trội so với các phương pháp khác. Cảm ơn các bạn đã theo dõi bài của mình. Có thắc mắc gì các bạn cứ comment bên dưới nhé.
Tài liệu tham khảo
All rights reserved
