
Tổng hợp kiến thức từ YOLOv1 đến YOLOv5 (Phần 3)
Bài đăng này đã không được cập nhật trong 4 năm
Mở đầu
Đây là bài viết cuối cùng trong chuỗi series giải thích họ nhà YOLO, lần này tập trung vào YOLOv4 và YOLOv5. Bài viết này gồm rất nhiều những kiến trúc, ý tưởng mới nên có chỗ nào khó hiểu, mình highly recommend các bạn nên đọc paper về phần đấy để có thể nắm được rõ nhất. Phần này sẽ tóm tắt và phân tích ngắn gọn về những thay đổi trong kiến trúc (backbone + neck), các kĩ thuật xử lý data, loss function và các kĩ thuật training khác.
Về các bài phân tích trước, các bạn có thể đọc ở đây:
- Phần 1 (YOLOv1): https://viblo.asia/p/tong-hop-kien-thuc-tu-yolov1-den-yolov5-phan-1-naQZRRj0Zvx
- Phần 2 (YOLOv2 + YOLOv3): https://viblo.asia/p/tong-hop-kien-thuc-tu-yolov1-den-yolov5-phan-2-V3m5WRDblO7
YOLOv4
YOLOv4 là sự lắp ghép có chọn lọc của các nghiên cứu trong Object Detection lại với nhau. Mình sẽ trình bày những thay đổi được áp dụng vào YOLOv4 và chi tiết của từng thay đổi.
Về kiến trúc, YOLOv4 sử dụng
- Backbone: CSPDarkNet53
- Neck: SPP, PAN
- Head: y nguyên YOLOv3 nên mình sẽ không trình bày
Backbone
CSPBlock

Ý tưởng chính của CSPBlock được thể hiện như Hình 1, áp dụng vào Residual Block. Thay vì chỉ có một đường đi từ đầu tới cuối, CSPBlock chia thành 2 đường đi. Nhờ việc chia làm 2 đường như vậy, ta sẽ loại bỏ được việc tính toán lại gradient (đạo hàm), nhờ đó có thể tăng tốc độ trong training. Hơn nữa, việc tách làm 2 nhánh, với mỗi nhánh là một phần được lấy từ feature map trước đó, nên số lượng tham số cũng giảm đi đáng kể, từ đó tăng tốc trong cả quá trình inference chứ không chỉ trong training.
CSPDarkNet53
YOLOv4 áp dụng ý tưởng của CSPBlock, thay thế Residual Block thông thường của YOLOv3 thành CSPResBlock, đồng thời đổi activation function từ LeakyReLU thành Mish, tạo nên CSPDarkNet53 (Hình 2).


DropBlock
Trong các bài Classification, ở layer cuối ta thường hay sử dụng DropOut để làm giảm hiện tượng Overfitting. Nhưng trong Convolution thì việc bỏ đi random một số vị trí ở trong feature map có vẻ không hợp lý lắm. Vì các vị trí ở cạnh nhau trong feature map có tương quan cao với nhau, nên việc bỏ đi các vị trí một cách random dường như sẽ không đem lại nhiều hiệu quả. DropBlock sẽ bỏ đi nhóm vị trí trong feature map thay vì chỉ bỏ đi một vị trí (Hình 7).

Neck
Cũng giống YOLOv3, YOLOv4 có thêm neck để thực hiện phát hiện vật thể ở trên những scale khác nhau.
YOLOv4 sử dụng 2 thành phần cho neck: SPP và PAN
PAN
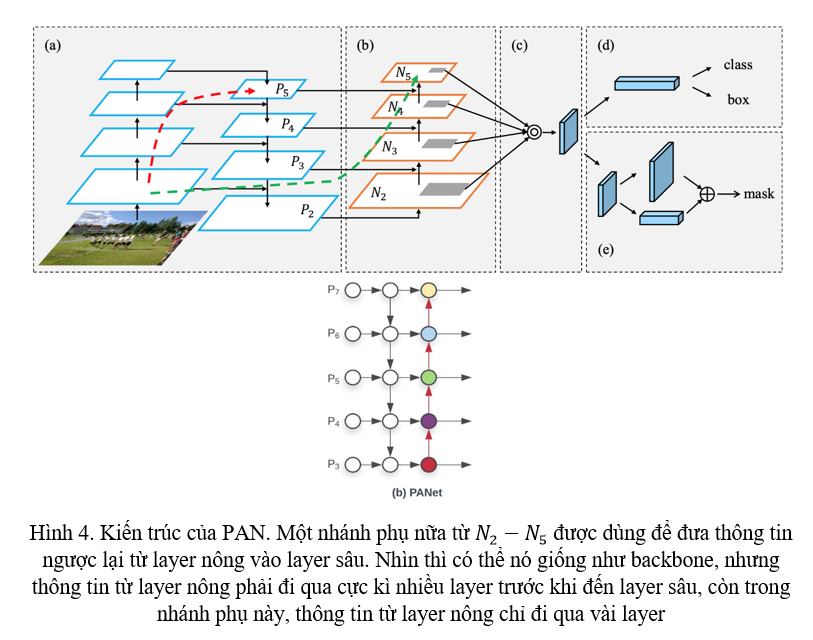
PAN chính là FPN on steroid. Nhớ lại trong FPN, một nhánh phụ được tạo ra để đưa thông tin từ các feature ở các layer sâu vào feature ở các layer nông. Nhưng FPN lại thiếu một việc đó chính là đưa feature từ các layer nông ngược lại vào các layer sâu. Vì vậy, PAN tạo ra thêm một nhánh phụ nữa, kiến trúc được giải thích cụ thể ở Hình 4.
SPP
SPP lần đầu được giới thiệu vào năm 2014, thời đó khi mà Object Detection vẫn còn đang sử dụng các lớp Fully-Connected ở đầu ra. Với một feature map đầu ra từ backbone, trước khi đưa vào lớp Fully-Connected để thực hiện detect, ta áp dụng 3 lần Max Pooling lên feature map đó như Hình 5.
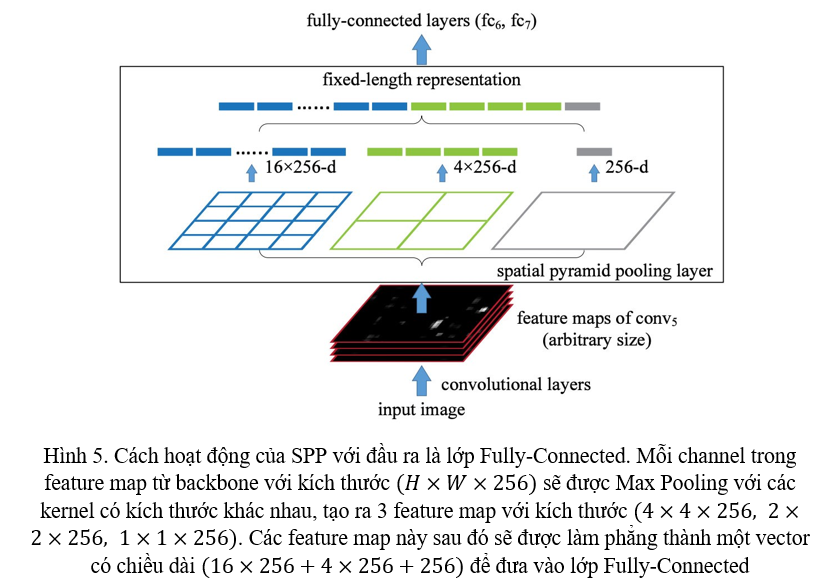
Thông thường, với các mạng có lớp Fully-Connected, kích thước ảnh đầu vào cần phải được giữ nguyên. Tuy nhiên, với sự xuất hiện của SPP, ảnh đầu vào đã có thể có kích thước đa dạng hơn mà không cẩn phải giữ nguyên nữa, một vector có độ dài cố định vẫn được sinh ra khi đi qua SPP. Hơn nữa, SPP sử dụng các kernel có kích thước khác nhau, làm tăng cường Receptive Field. Nếu các bạn chưa hiểu Receptive Field là gì và vì sao nó lại quan trọng, các bạn có thể đọc thêm về bài viết phân tích Receptive Field ở đây: https://viblo.asia/p/receptive-field-la-gi-tai-sao-no-lai-quan-trong-doi-voi-cnn-V3m5WRkQlO7
Nhưng từ YOLOv2, chúng ta đã không còn sử dụng lớp Fully-Connected cho đầu ra nữa. Vì vậy, YOLOv4 đã thay đổi SPP đi một chút. YOLOv4 đổi kích thước của các kernel của Max Pooling, thay vì đưa ra các feature map có kích thước , , , YOLOv4 đưa ra 4 khối feature map có kích thước (cùng kích thước với feature map lấy từ backbone), mỗi khối feature map này được tạo ra từ Max Pooling với kernel có kích thước . Sau đó, chúng được concatenate lại với nhau, tạo thành một khối feature map (Hình 6).

SPP được gắn vào cuối của backbone như hình bên dưới

Các thay đổi khác
Loại bỏ Grid Sensitivity
Nhớ lại trong YOLOv3, Bounding Box được tính theo công thức ở Hình 8
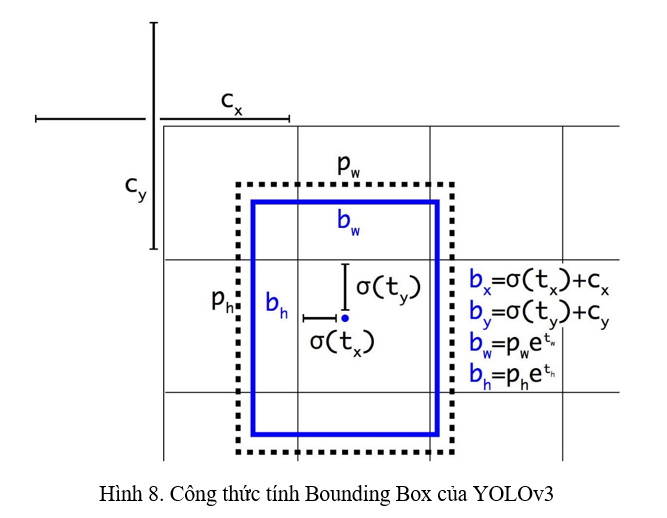
Với trường hợp và , thì giá trị của , do tính chất của sigmoid, phải có giá trị âm hoặc giá trị dương cực kì lớn. Do vậy, ta sẽ nhân với một hệ số . Cụ thể, công thức của Bounding Box sẽ trở thành: 
Sử dụng nhiều anchors cho một ground truth Bounding Box
Ở trong YOLOv3, chỉ anchor có IoU lớn nhất với ground truth Bounding Box mới được chọn làm positive anchor. Những anchors mà có IoU với ground truth Bounding Box dưới một ngưỡng (cụ thể là 0.5 ở trong các phiên bản YOLO) thì sẽ chọn là negative anchors. Còn những anchors mà có IoU lớn hơn 0.5, nhưng lại k phải là positive anchor được nói ở trên thì sẽ không có ảnh hưởng trong quá trình tính loss, ta gọi đây là những anchors bị thừa.
Tuy nhiên trong YOLOv4, những anchors bị thừa sẽ được chọn làm positive anchors, có ảnh hưởng trong quá trình tính loss thay vì bỏ đi.
Tác dụng của việc này vẫn chưa được làm rõ trong YOLOv4, tuy nhiên, mình có một giả thuyết rằng điều này làm giảm đi vấn đề class imbalanced giữa background và foreground thường thấy trong các mô hình Object Detection, được nói cụ thể trong Focal Loss.
Xử lý data
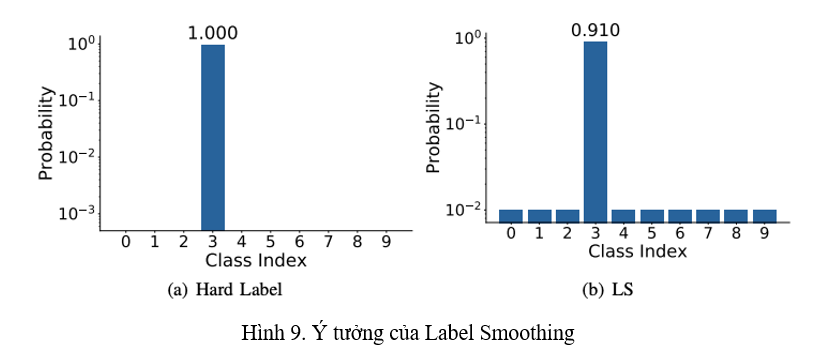
YOLOv4 áp dụng Label Smoothing trong việc classfication cho vật thể. Ý tưởng về Label Smoothing lần đầu được giới thiệu trong Inception-v2, ý tưởng được thể hiện trong Hình 9. Việc này làm giảm sự tự tin thái quá của model khi dự đoán một class, từ đó giảm nhẹ overfitting của model. Mình đã có phân tích cách thức và ảnh hưởng của Label Smoothing, các bạn có thể xem ở đây
YOLOv4 sử dụng 2 kĩ thuật Data Augmentation mới: Mosaic Augmentation và Self-Adversarial Training (SAT). Về Mosaic Augmentation, mình cũng đã nói qua tại đây. Khi được áp dụng Mosaic Augmentation, ta sẽ có một ảnh như bên dưới.

Còn tại đây, mình sẽ nói qua về SAT. Thông thường, khi ta thực hiện một forward pass của một ảnh qua model, tiếp theo ta sẽ thực hiện backward pass, cập nhật weights của model để có thể phát hiện object tốt hơn. Tuy nhiên, trong SAT, ở backward pass, ta sẽ thay đổi ảnh đầu vào của model để giảm khả năng phát hiện object của model. Không giống như các kĩ thuật Data Augmentation thông thường, ảnh được thay đổi trong SAT sẽ rất khó để mắt thường có thể nhận ra được. Sau đó, ảnh này sẽ được sử dụng trong việc training model. Ảnh được tạo ra trong quá trình SAT có thể được hình dung ở bên dưới.

Để hiểu rõ hơn về Adversarial Training, các bạn có thể đọc thêm trong bài về Semi-Supervised Training của một senpai trong team mình tại đây.
Cosine learning rate schedule
YOLOv4 sử dụng Cosine learning rate schedule, một kĩ thuật thay đổi learning rate trong training mà mình đã có phân tích ở đây. Để thuận tiện thì các bạn có thể xem hình dưới để hiểu cách mà learning rate được thay đổi.

Giải thuật di truyền để chọn hyper-parameters tối ưu
Một senpai trong team mình đã có một bài phân tích khá là kĩ về vấn đề này, các bạn có thể tìm đọc ở đây.
Regression Loss mới
Ở YOLOv3, Regression Loss sử dụng squared loss, các bạn có thể xem lại ở đây. Tuy nhiên, nhược điểm của squared loss được nêu ra ở trong GIoU Loss, được đề cập ở Hình 10 bên dưới.
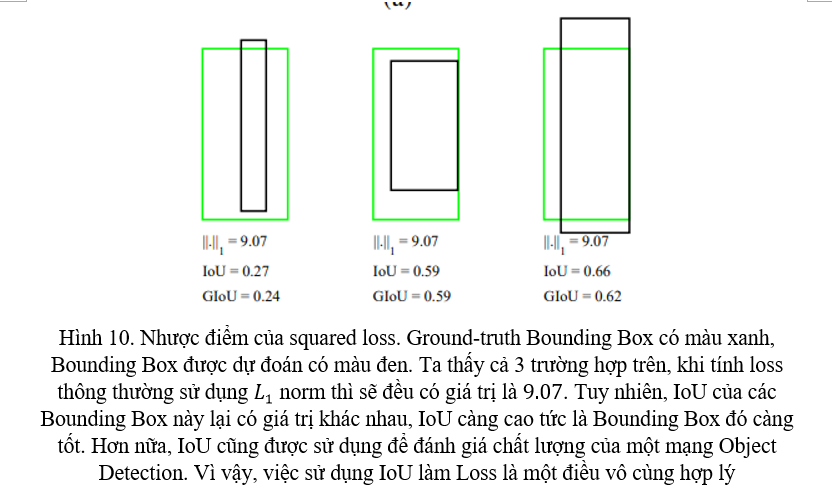
YOLOv4 sử dụng CIoU Loss, một phiên bản nâng cấp của GIoU Loss, giúp cải thiện thời gian training của model một cách đáng kể.
Tổng kết YOLOv4
Kiến trúc của YOLOv3 nâng cấp lên YOLOv4 được tóm tắt như sau:
- Backbone: DarkNet53 --> CSPDarkNet53, áp dụng thêm DropBlock
- Neck: FPN --> SPP + PAN
- Head: Giữ nguyên từ YOLOv3
Các thay đổi khác trong YOLOv4 bao gồm:
- Data Augmentation: Mosaic Augmentation, Self-Adversarial Training
- Loss function: Regression Loss từ squared loss --> CIoU Loss
- Anchor Box: 1 anchor --> nhiều anchors
- Label Smoothing
- Loại bỏ Grid Sensitivity
- Cosine Learning Rate schedule
YOLOv5
YOLOv5 không có quá nhiều thay đổi so với YOLOv4. Một số đóng góp từ tác giả của YOLOv5 (Glenn Jocher) đã trao đổi với tác giả của YOLOv4 và áp dụng luôn vào trong YOLOv4. YOLOv5 tập trung vào tốc độ và độ dễ sử dụng.
Hiện tại, với phiên bản 6.0, các thay đổi trong YOLOv5 như sau.
Backbone
C3 module
YOLOv5 cải tiến CSPResBlock của YOLOv4 thành một module mới, ít hơn một lớp Convolution gọi là C3 module. Chi tiết được thể hiện ở hình bên dưới.

Activation function
YOLOv4 sử dụng Mish hoặc LeakyReLU cho phiên bản nhẹ, còn sang YOLOv5, activation function được sử dụng là SiLU.
Neck
SPPF
YOLOv5 áp dụng một module giống với SPP, nhưng nhanh hơn gấp đôi và gọi đó là SPP - Fast (SPPF). Kiến trúc của SPPF được thể hiện ở Hình 12.
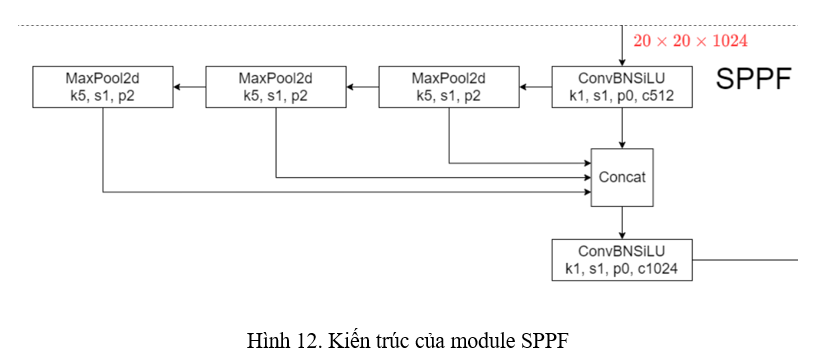
Thay vì sử dụng MaxPooling song song như trong SPP, SPPF của YOLOv5 sử dụng MaxPooling tuần tự. Hơn nữa, kernel size trong MaxPooling của SPPF toàn bộ là 5 thay vì là như SPP của YOLOv4.
Các thay đổi khác
Loại bỏ Grid Sensitivity
Vấn đề này đã được giải quyết ở YOLOv4 vừa nêu ở trên. Tuy nhiên, YOLOv5 lại sử dụng một công thức khác để giải quyết Grid Sensitivity, được nêu ở dưới:

Xử lý data
Các kĩ thuật Data Augmentation được áp dụng trong YOLOv5 bao gồm:
-
Mosaic Augmentation
![image.png]()
-
Copy-paste Augmentation
![image.png]()
-
Random Affine transform
![image.png]()
-
MixUp Augmentation
![image.png]()
-
Và các thay đổi về màu sắc cũng như là Random Flip của Albumentations



EMA Weight
Thông thường, khi training, ta sẽ ngay lập tức cập nhất weight của model trong quá trình backward pass. Tuy nhiên, trong EMA, ta tạo ra một model y hệt với model chúng ta sử dụng trong training, nhưng cách cập nhật weight sẽ tuân theo công thức Exponential Moving Average (EMA). Để hiểu rõ hơn thì các bạn có thể đọc bài phân tích cực kì kĩ về EMA weight tại đây
Loss scaling
YOLOv5 có sử dụng 3 đầu ra từ PAN Neck, để phát hiện objects tại 3 scale khác nhau. Tuy nhiên, Glenn Jocher nhận thấy rằng sự ảnh hưởng của các object tại mỗi scale đến Objectness Loss là khác nhau, do đó, công thức của Objectness Loss được thay đổi như sau:
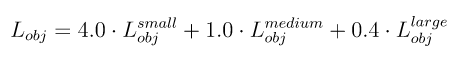
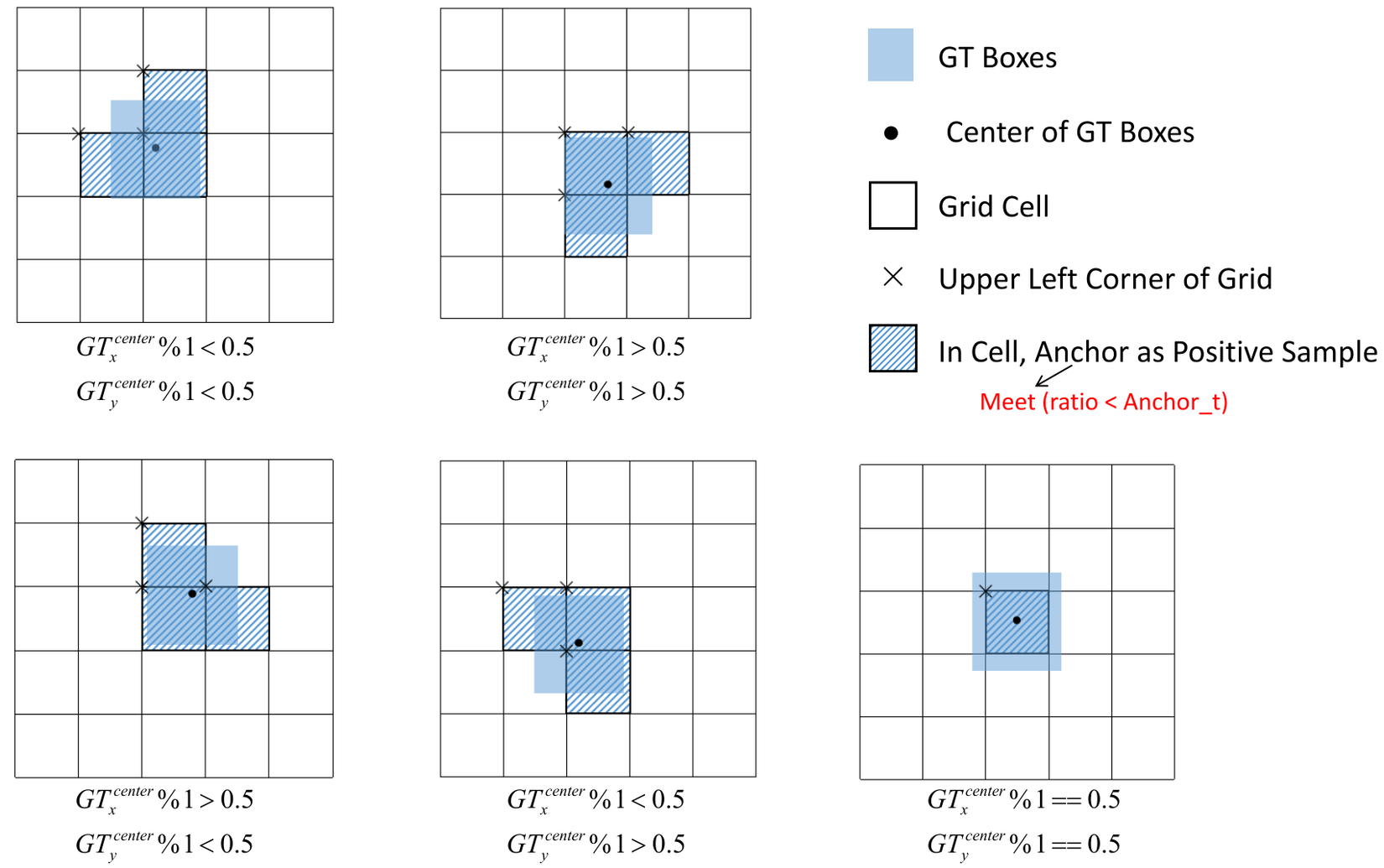
Anchor Box
Anchor Box trong YOLOv5 nhận được 2 sự thay đổi lớn.
Đầu tiên là sử dụng Auto Anchor, một kĩ thuật áp dụng giải thuật di truyền (GA) vào Anchor Box ở sau bước k-means để Anchor Box hoạt động tốt hơn với những custom dataset của người dùng, chứ không còn hoạt động tốt ở mỗi COCO nữa. Về GA, các bạn có thể đọc bài phân tích tại đây để hiểu rõ hơn về việc áp dụng GA vào Anchor Box.
Thứ hai đó chính là offset tâm của object để lựa chọn nhiều Anchor Box cho một object. Ý tưởng được thể hiện trong hình dưới:
Tổng kết YOLOv5
Kiến trúc của YOLOv4 nâng cấp lên YOLOv5 được tóm tắt như sau:
- Backbone: CSPResidualBlock --> C3 module
- Neck: SPP + PAN --> SPPF + PAN
- Head: Giữ nguyên từ YOLOv3
Các thay đổi khác trong YOLOv5 bao gồm:
- Data Augmentation: Mosaic Augmentation, Copy-paste Augmentation, MixUp Augmentation
- Loss function: Thêm hệ số scale cho Objectness Loss
- Anchor Box: Auto Anchor sử dụng GA
- Loại bỏ Grid Sensitivity nhưng công thức khác
- EMA Weight
All rights reserved
