
Tổng hợp kiến thức từ YOLOv1 đến YOLOv5 (Phần 1)
Bài đăng này đã không được cập nhật trong 4 năm
Mở đầu
Object Detection là một bài toán phổ biến trong Computer Vision. Mục tiêu của Object Detection là xác định và phân loại các object (vật thể) tồn tại trong ảnh, là một bài toán multi-task, thực hiện Classification và Regression (Localization) đồng thời. Ở những thời kì đầu tiên trong lĩnh vực này, các nghiên cứu tập trung vào việc sử dụng các hand-crafted feature (đặc điểm nhận dạng do con người nghĩ ra) như SIFT, HOG. Tuy nhiên, cách làm như vậy khá là hạn chế về độ chính xác và khả năng áp dụng lên đa dạng các object cần nhận dạng.
Từ năm 2012, CNN nổi lên như một thế lực trong các bài toán về Classification sử dụng đầu vào là ảnh, và cũng dần dần được đưa vào sử dụng trong Object Detection. Một phương pháp khá nổi tiếng đó chính là Sliding Window (cửa sổ trượt) (Hình 1). Sử dụng một cửa sổ , trượt dần trên ảnh đầu vào. Ảnh lấy ra nằm trong vùng có cửa sổ trượt sẽ được đưa qua một mạng Classification để nhận diện xem trong vùng vừa lấy ra có object nào. Cách làm này vừa chậm mà Bounding Box của vật thể trong ảnh còn không tốt.

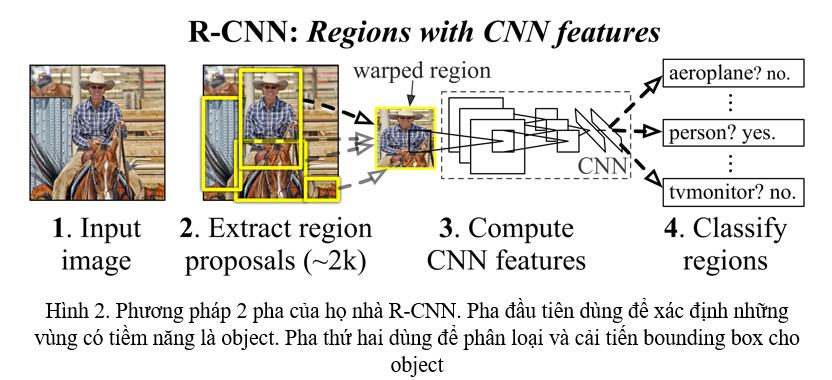
Năm 2013 đánh dấu sự ra đời của một mạng nơ-ron cực kì nổi tiếng trong Object Detection: R-CNN. Trước tiên R-CNN sẽ xác định các vùng có tiềm năng tồn tại object, các vùng có tiềm năng này sau đó sẽ được đưa vào một CNN để thực hiện Classification xem vùng đó là object nào, đồng thời cải thiện Bounding Box cho object (Hình 2). Họ nhà R-CNN tiếp tục phát triển mạnh mẽ với 2 nghiên cứu sau đó là Fast R-CNN và Faster R-CNN, cải thiện tốc độ cũng như là độ chính xác của mô hình. Tuy nhiên, họ nhà R-CNN vẫn khá là chậm với phương pháp hai pha: 1 pha xác định vùng có tiềm năng là object, 1 pha phân loại và cải tiến Bounding Box của object.
Vì vậy, YOLO ra đời với mục tiêu là một mạng Object Detection có tốc độ cực nhanh với phương pháp một pha của mình. Dưới đây sẽ là những chia sẻ của mình về họ nhà YOLO, nếu có gì sai mong mọi người góp ý ạ 
YOLOv1
Phương pháp một pha
YOLO sẽ đưa ảnh đầu vào qua một CNN, tạo ra một feature map , gọi là grid. YOLO thực hiện detect object tại mỗi cell (ô) trong grid đó. Tức là, thay vì có một bước tìm ra các vùng có khả năng tồn tại object, thì YOLO sẽ thực hiện detect trên toàn bộ ảnh, khỏi tìm ra vùng gì cả.
Một cell sẽ predict ra Bounding Box và xác suất cho class. Một Bounding Box sẽ mang 5 thông tin: tâm của Bounding Box (, ), chiều dài và rộng của Bounding Box (, ) và độ tự tin. Độ tự tin dùng để xác định xem trong Bounding Box đó có tồn tại object hay không. Nếu trong Bounding Box đó không tồn tại object, ta bỏ qua luôn toàn bộ giá trị prediction khác của Bounding Box và Classification, nhằm bỏ qua những nơi không tồn tại object. Việc sử dụng thông tin độ tự tin này cũng phần nào giống pha thứ nhất trong phương pháp hai pha, lọc ra những nơi tồn tại object.
Vậy, trong một cell, ta sẽ predict ra một tensor có phần tử, với là số lượng Bounding Box, là 5 thông tin trong Bounding Box gồm: trung tâm box, chiều dài rộng box và độ tự tin và là số class. Và trong một feature map gồm cell, tensor dự đoán từ mạng sẽ có độ dài
Kiến trúc mạng
Kiến trúc mạng của YOLOv1 không có gì đáng nói, được thể hiện toàn bộ ở Hình 3.

Loss function
Một hàm loss thì luôn tồn tại ít nhất 2 yếu tố để có thể tính được: prediction (sự dự đoán của mạng) và target (cái chúng ta cần đạt được). Ta đã biết được prediction của YOLOv1 gồm những gì, trình bày ở phần "Phương pháp một pha" phía trên. Ta sẽ tìm hiểu YOLOv1 gồm những hàm loss gì, và target của chúng được chọn như nào.
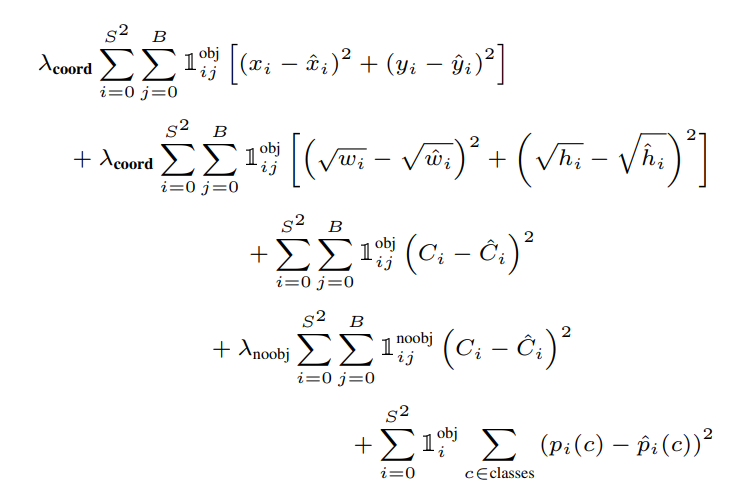
Phía trên là toàn bộ hàm loss của YOLOv1, nhìn có vẻ rất đáng sợ nhưng ta hãy cùng chia nhỏ nó ra.
Confidence Loss
Xét Confidence Loss (hàm loss dành cho độ tự tin):
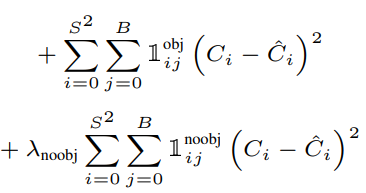
Đây là loss của độ tự tin trên toàn bộ tấm ảnh, gồm cell và mỗi cell gồm Bounding Box. Ta sẽ chia nhỏ hàm loss này hơn nữa. Xét một Bounding Box trong một cell, ta sẽ thu được hàm loss: . Target cho hàm loss này, , sẽ là giá trị IoU của Bounding Box được dự đoán so với ground truth Bounding Box.
Tại sao Confidence Loss lại gồm 2 phần? Xét phần trên của Confidence Loss, phần này sẽ phụ trách cho cell thứ mà tồn tại object trong cell đó. Một cell thì gồm Bounding Box, lặp qua toàn bộ Bounding Box được dự đoán trong cell thứ , nếu Bounding Box thứ cho kết quả IoU với ground truth Bounding Box là lớn nhất thì , còn lại thì . Xét phần dưới. Phần dưới của Confidence Loss, phần này sẽ phụ trách cho cell thứ mà không tồn tại object trong cell đó, còn lại thì tương tự như phần trên.
Ta có thể dễ dàng thấy là số cell không tồn tại object sẽ nhiều hơn rất nhiều so với số cell tồn tại object, vì vậy, phần loss cho cell không tồn tại object sẽ lớn hơn nhiều và lúc này, đóng vai trò là một hệ số làm nhỏ đi phần loss cho cell không tồn tại object xuống.
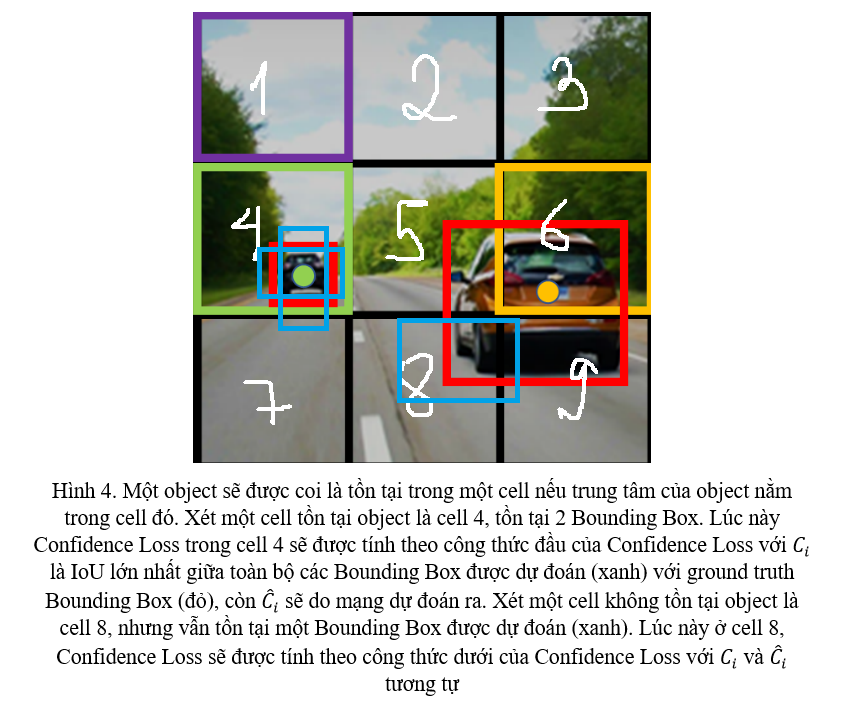
Các bạn có thể nhìn vào Hình 4 để hiểu rõ hơn về Confidence Loss.
Classification Loss
Công thức của Classification Loss như sau:
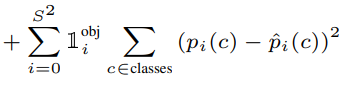
Classification target của hàm loss sẽ là một vector one-hot, giống như các bài toán Classification thông thường khác. Tuy nhiên, Classification Loss chỉ được tính khi cell đó tồn tại object, còn nếu cell không tồn tại object thì Classification Loss sẽ
Localization (Regression) Loss
Công thức của Regression Loss như sau:
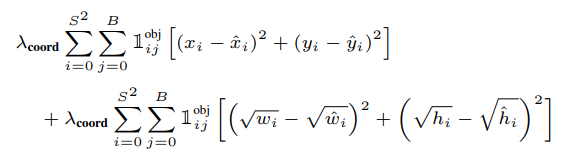
Phần này thì cũng giống như Confidence Loss thôi, lặp qua từng cell và từng Bounding Box trong cell, nếu cell đó tồn tại object thì thực hiện tính Loss, còn không thì Loss . Điều thú vị ở đây là căn bậc 2 ở trong phần Loss dành cho chiều dài và chiều rộng của Bounding Box. Ý tưởng của việc này nằm ở việc Bounding Box có độ lớn khác nhau thì nên được đối xử khác nhau. Tức là, việc sai một vài pixel ở Bounding Box to sẽ không nghiêm trọng bằng việc sai một vài pixel ở Bounding Box nhỏ.
Lấy ví dụ lần nữa cho dễ hiểu nhé. Xét 1 ground truth Bounding Box có chiều rộng là 500, Bounding Box từ dự đoán của model là 505, lúc này, loss tại chiều rộng sẽ là 5. Xét tiếp 1 ground truth Bounding Box có chiều rộng là 20, Bounding Box từ dự đoán của model là 25, lúc này, loss tại chiều rộng vẫn là 5. Với một Bounding Box có chiều rộng tới tận 500, việc lệch đi 5 không nên có sự ảnh hưởng ngang với việc một Bounding Box có chiều rộng là 20 và lệch đi 5. Vì vậy, lấy căn bậc 2 của giá trị này sẽ làm giảm độ ảnh hưởng của Bounding Box lớn khi có lệch nhỏ.
Hạn chế của YOLOv1
- YOLOv1 chỉ có thể predict được một object trong một cell, nếu có 2 object tồn tại trong cùng một cell, hoặc nếu phải predict từng object trong một nhóm object, YOLOv1 sẽ gặp rất nhiều khó khăn.
- Với việc chỉ sử dụng 2 Bounding Box, YOLOv1 sẽ gặp khó khăn với những object có tỉ lệ khác so với trong training.
- Regression Loss của YOLOv1 chưa tốt, dẫn đến việc đưa ra Bounding Box không tốt.
Tổng kết
Trong bài viết này, mình đã trình bày những hiểu biết của mình về YOLOv1, cụ tổ trong họ nhà YOLO. Đóng góp lớn nhất của YOLOv1 chính là phương pháp một pha để cải thiện tốc độ của các mạng nơ-ron trong Object Detection, nên bài này mình tập trung trình bày về phương pháp và hàm loss, bỏ qua những thứ như cấu trúc mạng nơ-ron, thông số training. Nếu có gì sai sót, mong mọi người có thể góp ý cho mình .
Các bạn có thể đọc phần 2 của series này ở đây: https://viblo.asia/p/tong-hop-kien-thuc-tu-yolov1-den-yolov5-phan-2-V3m5WRDblO7
All rights reserved
