
Tối ưu quá trình huấn luyện với tf.data API
Bài đăng này đã không được cập nhật trong 3 năm
A. Tensorflow data pipelines

Theo định nghĩa từ trang chủ Tensorflow , tf.data API cho phép bạn xây dựng đầu vào dữ liệu cho các mô hình từ đơn giản tới phức tạp. Nhưng cho dù đơn giản hay phức tạp, data pipeline cũng thường có 3 bước như sau:
- Extract
- Transform
- Load
import tensorflow as tf
import tensorlfow_datasets as tfds
# extract phase
dataset = tfds.load(name="mnist", split="train")
# transform phase
dataset = dataset.shuffle(NUM_SAMPLES)
dataset = dataset.repeat(NUM_EPOCHS)
dataset = dataset.map(lambda x: ....)
dataset = dataset.batch(BATCH_SIZE)
# load phase
iterator = dataset.take(10)
for data in iterator:
# access data and use it
Do chủ đề bài viết hôm nay không phải về tf.data API nên mình cũng không đi sâu vào cách sử dụng mà tập trung vào một số phương pháp để tối ưu hơn.
B. Tối ưu data pipeline với tf.data API
Như chúng ta đã biết, một số phần cứng chuyên dụng như GPU hay TPU giúp chúng ta có thể giảm thời gian thực thi. Tuy nhiên vấn đề tối ưu data pipeline cũng là một vấn đề rất quan trọng để giúp hiệu năng trong lúc huấn luyện có thể đạt mức độ tốt nhất. Bạn tưởng tưởng xem, GPU bạn đang rất rảnh rỗi chờ dữ liệu CPU xử lý. Vì vậy chúng ta cần một qui trình tối ưu hóa cả việc sử dụng CPU và GPU.

Ngoài ra trong bài toán thực tế, chúng ta phải đối mặt với khá nhiều vấn đề khác. Ví dụ như với lượng dữ liệu khổng lồ, dữ liệu không thể ở trên một máy mà cần ở trên nhiều máy khác nhau. Các vấn đề như:
- Network traffic
- Distributed training
- Cơ chế phức tạp hơn
- ...
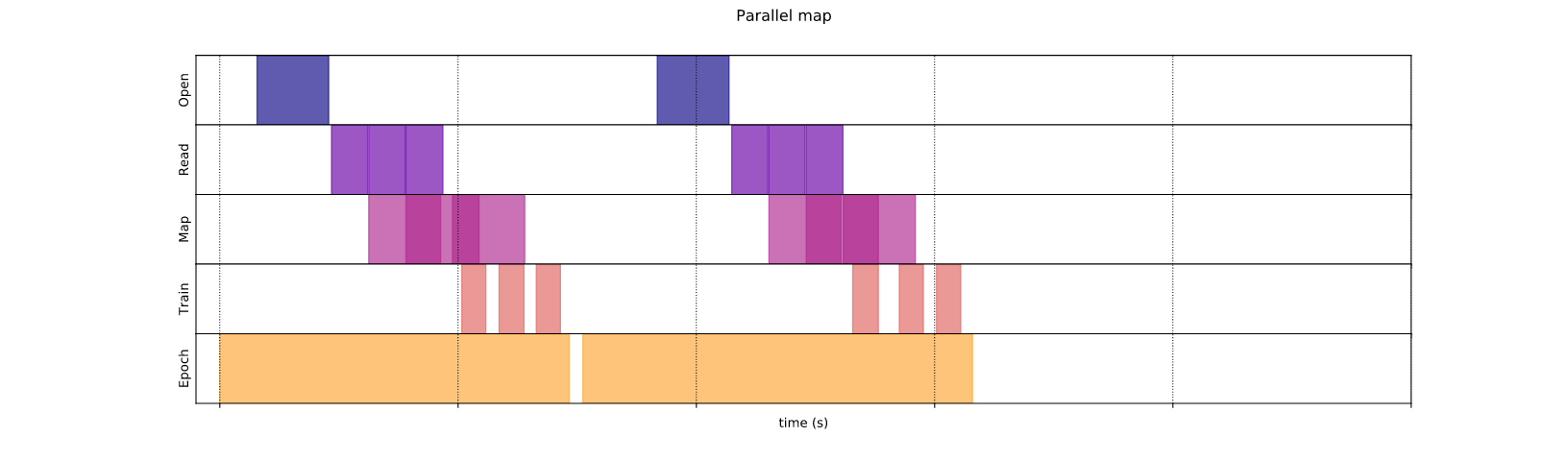
1. Phương pháp tuần tự.
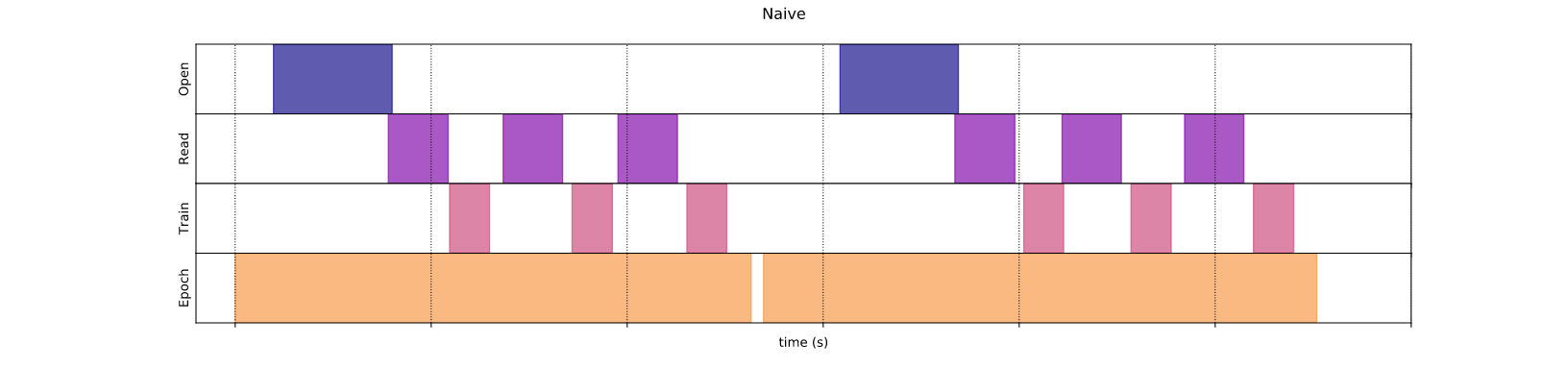
Phương pháp tuần tự là phương pháp xử lý các bước một cách tuần tự trong một epoch (tương ứng phần màu vàng):
- Mở file nếu file chưa được mở
- Kéo dữ liệu từ file
- Thực hiện các bước biến đổi nếu có và huấn luyện
Như hình trên bạn dễ dàng nhìn thấy trong khi mô hình đang training (tím hồng) thì phần xử lý dữ liệu (tím đậm) không làm gì. Và chính điều này đã đẩy tổng thời gian mở, đọc và huấn luyện trở nên nhiều hơn.
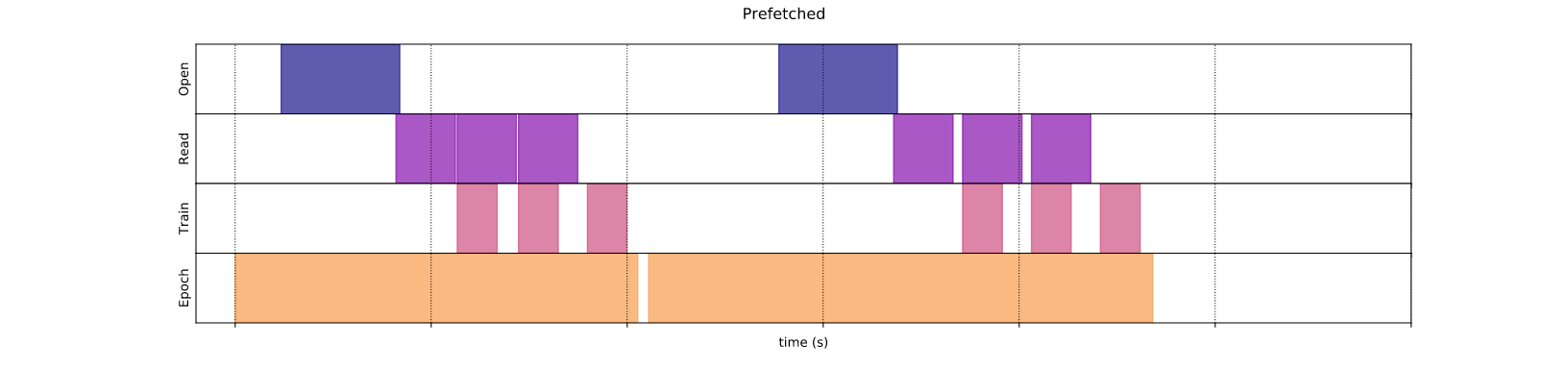
2. Prefetching (parallelize reading + training)
Để khắc phục vấn đề phương pháp tuần tự bên trên, Prefetching xử lý đồng thời một phần quá trình đọc và huấn luyện mô hình. Ví dụ trong khi mô hình đang huấn luyện dữ liệu ở bước s, dữ liệu ở bước s+1 vẫn được đọc và đẩy vào quá trình huấn luyện nếu proccessor sẵn sàng. Nhờ vậy giúp giảm được tổng thời gian huấn luyện.
tf.data API cung cấp một hàm tf.data.Dataset.prefetch giúp chúng ta thực hiện điều đó. Về bản chất, hàm này sử dụng một thread ngầm kéo một lượng dữ liệu của bước tiếp theo lưu vào trong buffer. Lượng dữ liệu này thường bằng hoặc lớp hơn số lượng dữ liệu được dùng trong một batch.
3. Parallelizing data extraction (parallelize multiple file reading)
Ồ ngon xử lý đồng thời được quá trình lấy dữ liệu và quá trình huấn luyện rồi, nhưng bây giờ dữ liệu thực tế ở phân tán trên nhiều nơi như Google Cloud hay HDFS hoặc đọc một lúc nhiều file từ một nơi thì xử lý kiểu gì nhể ?
Đó cũng là một vấn đề nhức nhối trong huấn luyện mô hình thực tế bởi dữ liệu lưu trên một nơi và ở nhiều nơi có sự khác biệt đáng kể:
- Time-to-first byte: Đọc được byte đầu tiên trong file từ remote storage mất thời gian lâu hơn từ local storage
- Read throughput: Remote storage thường cung cấp băng thông lớn trong khi đọc một file chỉ chiếm số lượng nhỏ của băng thông đó.
Để giải quyết vấn đề này, tf.data API cung cấp phương thức interleave giúp song song hóa bằng cách đan xen lượng dữ liệu từ các dataset từ các máy khác nhau. Phương thức interleave có hai tham số là cycle_length là lượng dữ liệu cần lấy, num_parallel_calls là mức độ song song hóa.
3.1. Sequential interleave
Phương thức này sẽ lấy dữ liệu từ các dataset có sẵn xen kẽ tuần tự nhau.
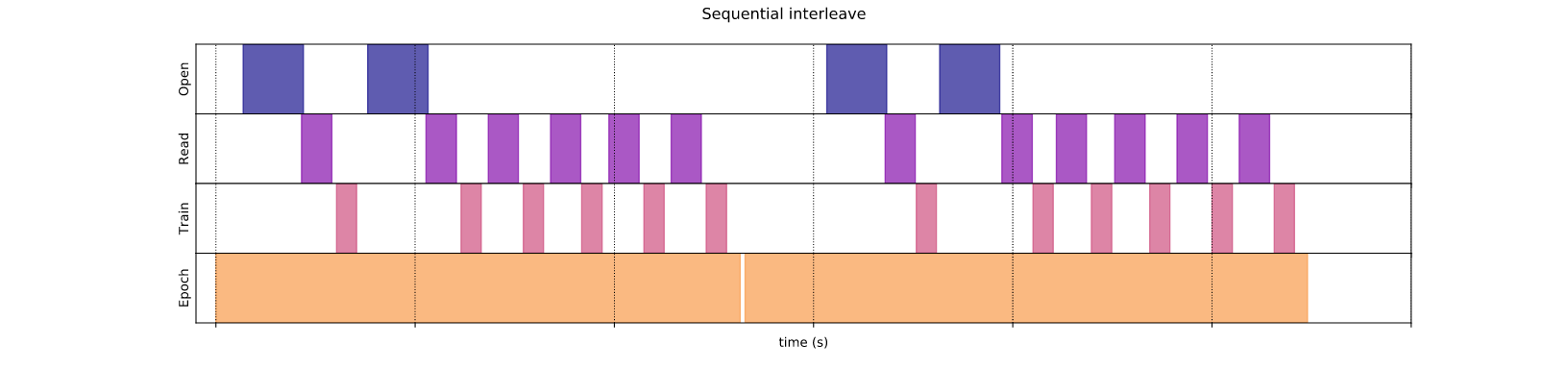
Từ hình trên quan sát thấy trong giai đoạn đầu, chỉ có duy nhất một file được mở trong khi file thứ hai cần chờ mất rất nhiều thời gian để có thể đọc được dữ liệu, thời gian để chờ khá lớn do vậy cách này không thực sự hiệu quả
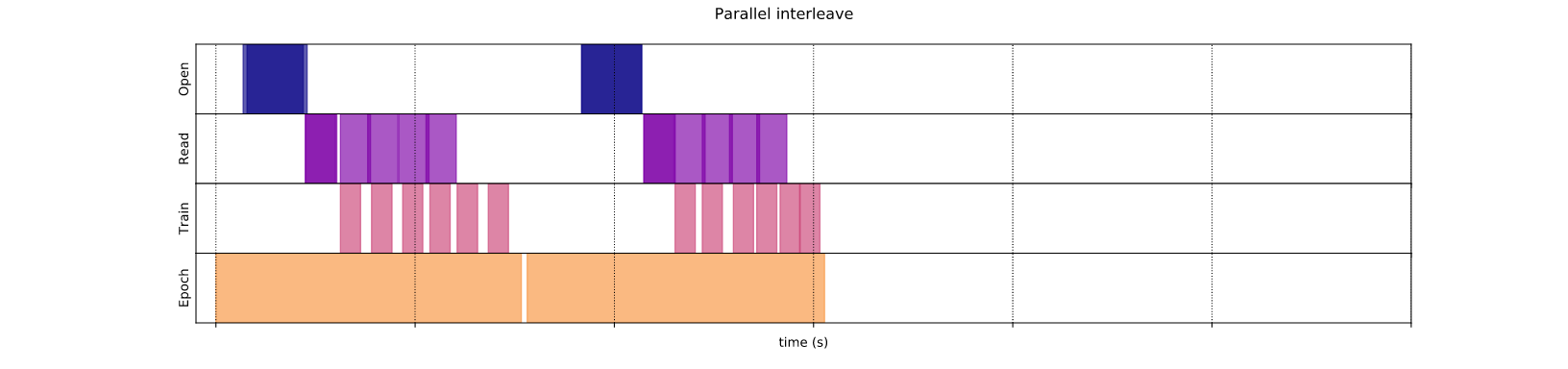
3.3. Parallel interleave
Với num_parrallel_calls cho phép load nhiều dataset một cách song song giảm tải thời gian chờ như bên trên.
4. Parallelizing data transformation (parallelize mapping)
Như đề cập ở phần A, data pipeline có bước Transform. Ở đây chúng ta thực hiện các phép biến đổi với dữ liệu đầu vào như augment, etc.
4.1. Parallel mapping
Tương tư như interleave và prefetch, map cũng sử dụng tham số num_parrallel_calls để tăng mức độ song song hóa xử lý nhiều mẫu trên nhiều CPU cores.
4.2. Caching
Ở các hình bên trên, các bạn có thể thấy mỗi khi bất đầu một epoch mới, thao tác mở file cần lặp lại liên tục. Để hạn chế điều đó ta có lưu lại bằng phương thức tf.data.Dataset.cache giúp lưu dữ liệu vào trong bộ nhớ hoặc ổ đĩa.
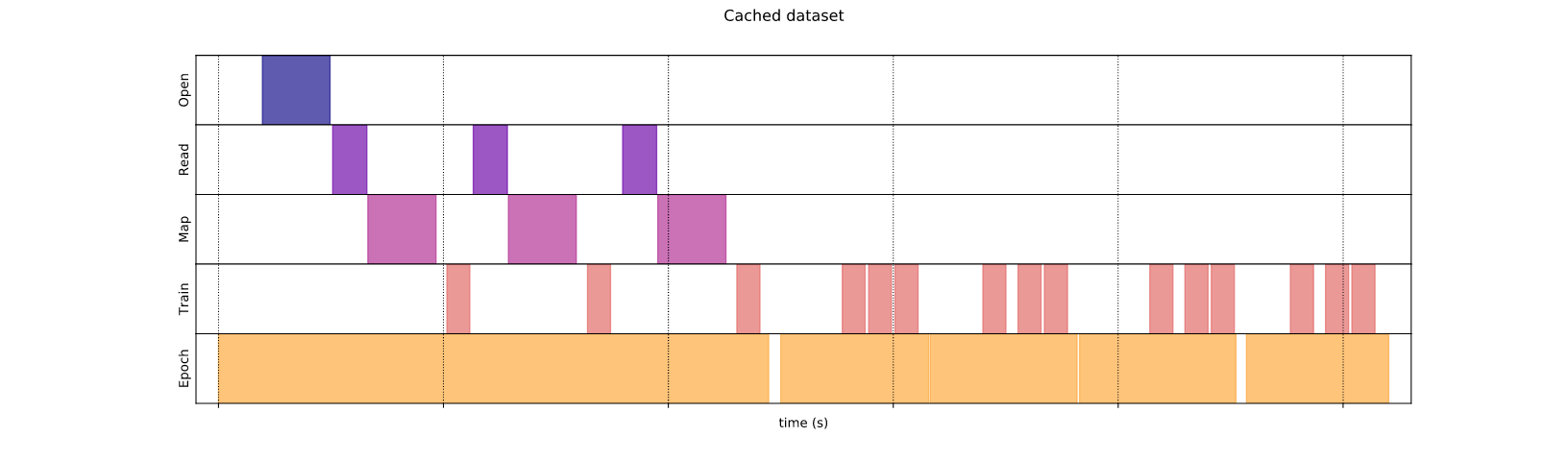
Như hình trên, phương thức cache được thực hiện sau bước map nên các bước open, read, map chúng ta chỉ thực hiện duy nhất một lần.
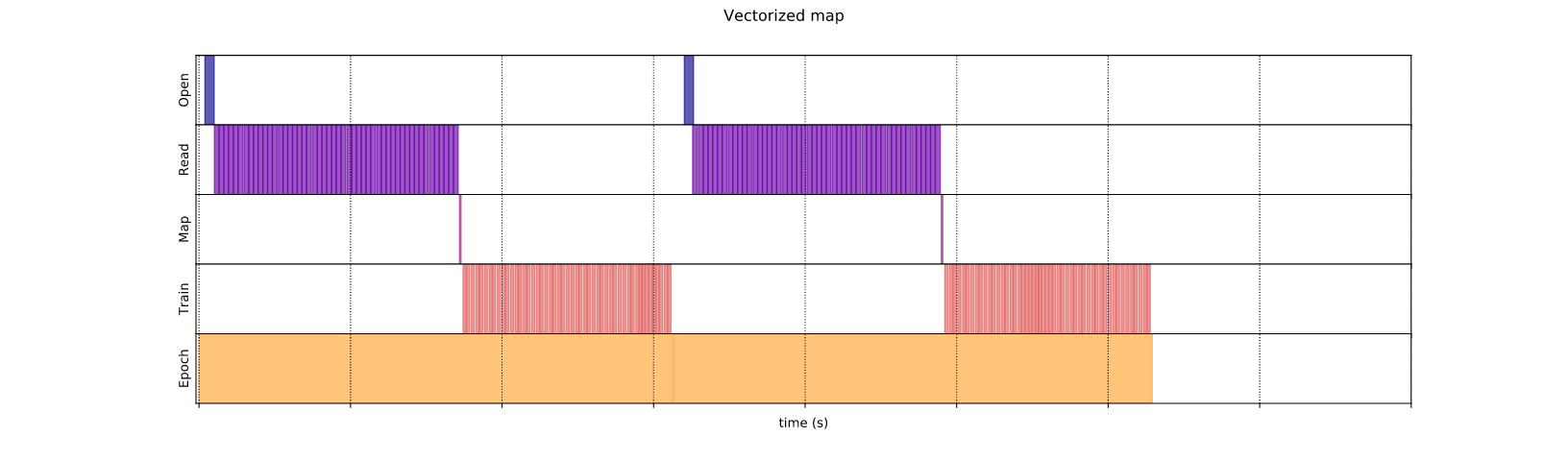
4.3. Vectorizing mapping
Tương tư như huấn luyện mô hình theo batch, ta cũng có thể thực hiện mapping theo batch.
Tài liệu tham khảo:
All rights reserved
