
Tìm hiểu kiến trúc Text2Speech nổi danh một thời -Tacotron (Phần 1)
Bài đăng này đã không được cập nhật trong 4 năm
Trong bài Một số kiến thức cơ bản về Text2Speech , mình cùng các bạn đã điểm qua các kiến thức cơ bản về Xử lý giọng nói như cách con người tạo ra âm thanh, các phép toán biến đổi Fourier, ... Hôm nay, mình chia sẻ về một kiến trúc đã từng làm mưa làm gió một thời trong lĩnh vực Text2Speech - Tacotron trong bài báo TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS
I. Tổng quan
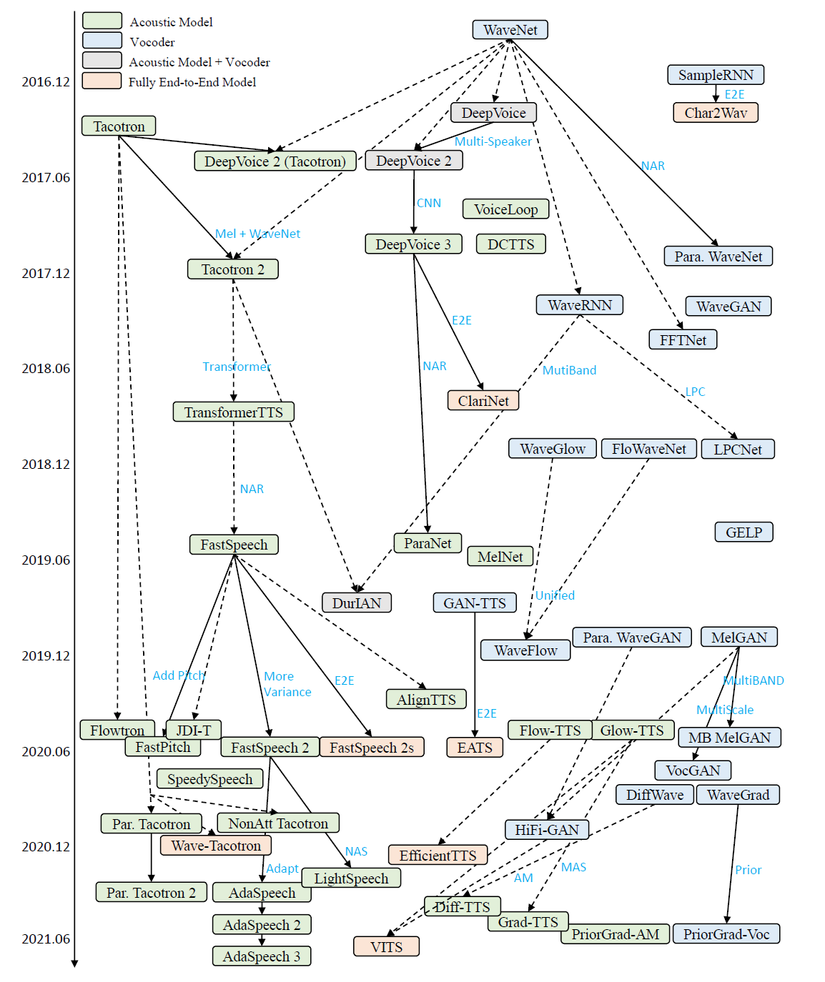 Source: A Survey on Neural Speech Synthesis
Source: A Survey on Neural Speech Synthesis
Các hệ thống text-to-speech đã được xây dựng nghiên cứu cách đây rất lâu về trước. Ví dụ như mô hình STATISTICAL PARAMETRIC SPEECH SYNTHESIS tuy nhiên những mô hình này đòi hỏi người phát triển có những kiến thức chuyên sâu về xử lý giọng nói và rất mất công để thiết kế. Mô hình này gồm có một bộ phận gọi là text frontend trích xuất đặc trưng ngôn ngữ, một mô hình trường độ, một mô hình dự đoán đặc trưng âm thanh và một mô hình sinh tín hiệu tạo âm thanh. Mỗi mô hình nhỏ trong đây được huấn luyện một cách độc lập nên khó kiểm soát lỗi trên toàn bộ hệ thống. Và đó là lý do các kiến trúc sau này như Tacotron được sinh ra.
II. Kiến trúc mô hình
Tacotron nhận dữ liệu huấn luyện bao gồm các cặp <text, audio> sinh ra Linear Spectrogram. Sau đó dùng giải thuật Griffin-Lim đóng vai trò như một Vocoder sinh waveform từ Linear Spectrogram thu được từ ở bước trước.
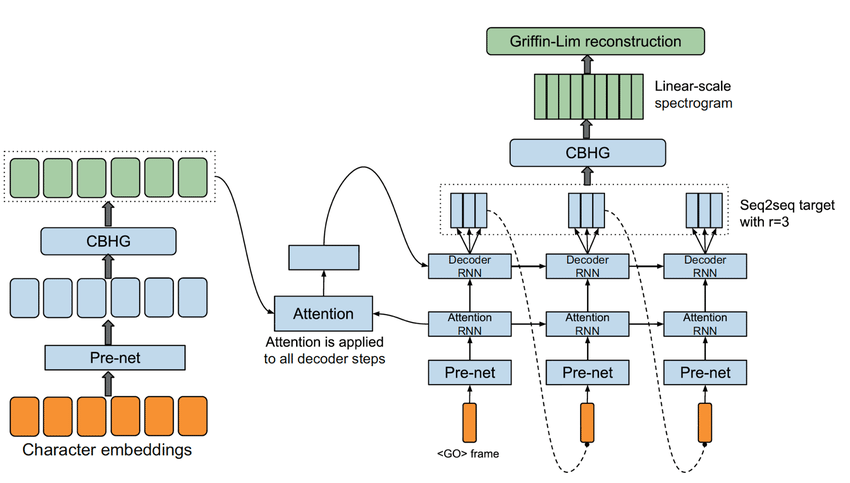 Kiến trúc Tacotron có dạng giống như kiến trúc seq2seq kết hợp với attention được sử dụng nhiều trong các bài toán về OCR bao gồm 3 phần:
Kiến trúc Tacotron có dạng giống như kiến trúc seq2seq kết hợp với attention được sử dụng nhiều trong các bài toán về OCR bao gồm 3 phần:
- Encoder
- Attention-based decoder
- Post-processing net
1. Highway Networks
Highway Networks lấy nguồn cảm hứng từ cơ chế điều khiển lượng thông tin vào ra bằng cổng trong bài báo Long Short Term Memory recurrent neural networks cho phép hỗ trợ tạo ra các mô hình sâu hơn hơn bằng cách truyền thông tin đi qua nhiều lớp nhưng không làm giảm lượng thông tin truyền đi ban đầu. Đó cũng là lý do tác giả đặt tên cho kiến trúc là highway-network.
Giả sử bây giờ ta có một plain feedforward neural network bao gồm L lớp nhận đầu vào là và đầu ra là . Lớp thứ l có sử dụng một biến đổi phi tuyến nhận đầu vào là và đầu ra là lớp .
Khi chuyển đổi sang highway networks, công thức (1) thành như sau:
trong đó T ở đây thường là phép toán sigmoid do đó giá trị phép toán T nằm trong khoảng [0, 1]. Như vậy trong một số trường hợp đặc biệt:
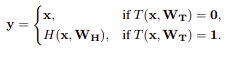
Cá nhân mình đánh giá cơ chế này khá giống với cơ chế của skip-connection được sử dụng trong mô hình ResNet với chức năng tương tự. Khác nhau ở điểm lượng thông tin được mang tới các lớp về sau linh hoạt hơn như hàm sigmoid.
2. CBHG module
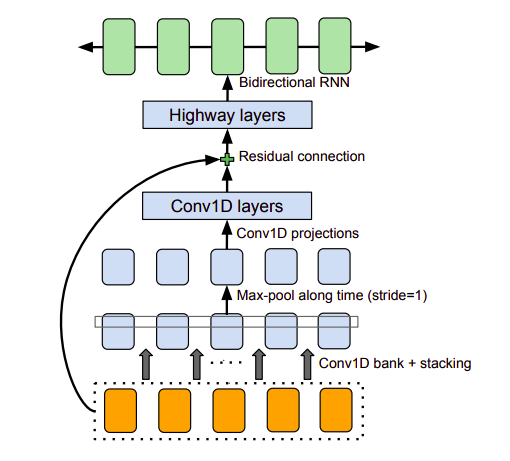 CBHG module
CBHG module
CBHG là module có chức năng trích xuất biểu diễn từ một chuỗi bao gồm 1 tập các lớp 1-D convolution, highway networks và một GRU 2 chiều. Chuỗi đầu vào trước tiên được nhân tích chập với K tập hợp các lớp convolution 1-D trong đó tập hợp thứ k chứa lớp với kích thước k (k = 1, 2, ..., K). Các lớp convolution đóng vai trò mô hình hóa thông tin ngữ cảnh và địa phương. Kết quả đầu ra các lớp convolution này sau đó được ghép nối với nhau và cho qua lớp Max-pool along time để tăng tính local invariance (từ này mình không biết giải nghĩa tiếng Việt là gì 😓). Sau đó kết quả sau pooling được cho qua lớp conv 1-D với kích thước cố định. Chú ý tác giả dùng stride bằng 1 ở đây nhằm giữ nguyên độ phân giải đầu vào. Trước khi đi vào highway network, tác giả có thực hiện bổ sung thôn tin bằng cách cộng thêm vào đầu ra của lớp Conv1D với chuỗi ban đầu. Đây chính là residual connection được đề cập trong hình minh họa CBHG module phía trên.
3. Encoder
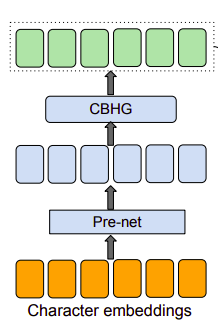 Encoder
Encoder
Như mình đã đề cập ở phần trên, Encoder là một trong 3 module chính trong kiến trúc seq2seq. Nhiệm vụ của encoder ở đây để trích xuất biểu diễn thông tin dưới dạng chuỗi của text đầu vào như trong các bài toán OCR. Đầu vào của encoder là chuỗi các kí tự trong đó mỗi kí tự được biểu diễn dưới dạng one-hot vector và được embedded về dạng continous vector. Tiếp theo, tác giả dùng một tập hợp các biến đổi phi tuyến cho các continous vector gọi là pre-net gồm có các bottleneck layer và dropout. Theo nghiên cứu việc sử dụng prenet giúp mô hình hội tụ nhanh hơn và tăng tính tổng quát.
4. Decoder
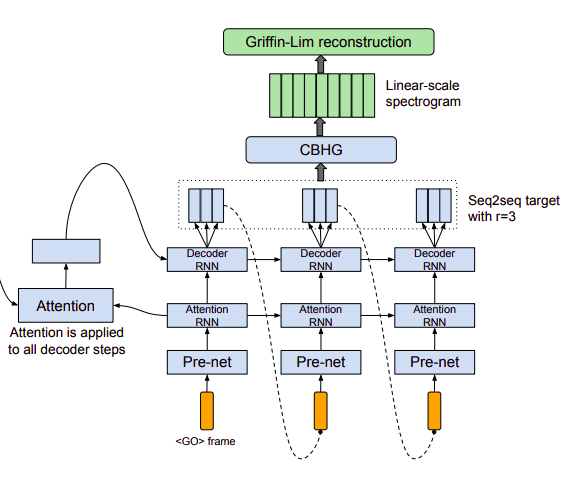 Attention based decoder
Attention based decoder
Trong kiến trúc Tacotron, tác giả sử dụng content-based tanh attention decoder trong đó recurrent layer sinh ra các truy vấn attention tới mỗi decoder step. Đầu vào của decoder RNN bao gồm context vector và output của attention RNN. Trong các bài toán OCR mà chúng ta đã gặp, cũng là kiến trúc seq2seq với attention tuy nhiên target của decoder trực tiếp là các chuỗi kí tự mong muốn đầu ra. Tuy nhiên với bài toán text2speech lại khá khác nhau vì để sinh ra audio waveform, lượng thông tin từ text là chưa đủ (phase, ...) vì thế chúng ta cần một biếu diễn trung gian như linear spectrogam, mel spetrogram, ... Các bạn chưa biết spetrogam là gì thì có thể xem lại bài Một số kiến thức cơ bản về Text2Speech của mình nhé.
Ở đây tác giả bật mí cho chúng ta một kĩ thuật đó là việc dự đoán nhiều frame khác nhau và tất nhiên không trùng nhau ở mỗi decoder step sẽ giúp giảm kích thước model, thời gian huấn luyện cũng như thời gian dự đoán. Lý do ở đây là các frame gần nhau thường liên quan đến nhau và một từ được phát âm ra tương ứng với nhiều frame.
5. Post-processing net và waveform synthesis.
Ở trong bài báo này, tác giả sử dụng Griffin-Lim như một synthesizer sinh âm thanh từ linear spectrogram được dự đoán ở decoder. Tuy nhiên thuật toán này hiện này đã không còn hiệu quả so với các thuật toán như Waveflow, WaveNet, .... Mình sẽ dành hẳn vài bài sắp tới để giới thiệu cho các bạn về các kiến trúc synthesizer như này.
III. Kết qủa
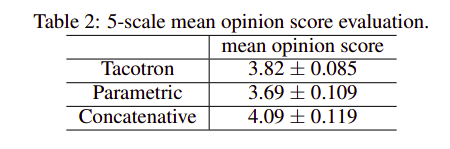
Tacotron đạt MOS 3.82 vượt trội hơn các phương pháp trước đây như Paramtric hay Concatnative trên trong ngôn ngữ tiếng Anh. Điều này đã khiến Tacotron trở thành phương pháp hiệu quả nhất trong lĩnh vực Text2Speech lúc bấy giờ.
Tài liệu tham khảo
All rights reserved
