
Tổng hợp kiến thức từ YOLOv1 đến YOLOv5 (Phần 2)
Bài đăng này đã không được cập nhật trong 4 năm
Mở đầu
Ở bài viết lần trước, mình đã trình bày về YOLOv1: Lý do tại sao YOLO lại ra đời, đồng thời phân tích ý tưởng chính và hàm Loss của YOLOv1. Tiếp tục với series phân tích YOLO, lần này mình sẽ trình bày về 2 phiên bản khác trong họ nhà YOLO, cụ thể là YOLOv2 và YOLOv3. Mình sẽ tập trung phân tích về kiến trúc mạng, những thay đổi trong quá trình training, cách sử dụng Anchor Box cũng như là hàm Loss và so sánh các phiên bản YOLO với nhau.
Các bạn có thể đọc phần 1 của series này ở đây: https://viblo.asia/p/tong-hop-kien-thuc-tu-yolov1-den-yolov5-phan-1-naQZRRj0Zvx
YOLOv2
Sau khi error analysis cho YOLOv1, nhóm tác giả nhận thấy rằng YOLOv1 gặp vấn đề về localization khá nhiều (Bounding Box không tốt), hơn nữa, Recall của YOLOv1 cũng khá là thấp (Phát hiện được ít vật thể), đã đề cập đến ở phần 1 của series. Vì vậy, trong YOLOv2 nhóm tác giả tập trung vào cải thiện 2 vấn đề này mà vẫn giữ được độ chính xác tốt.
Kiến trúc mạng
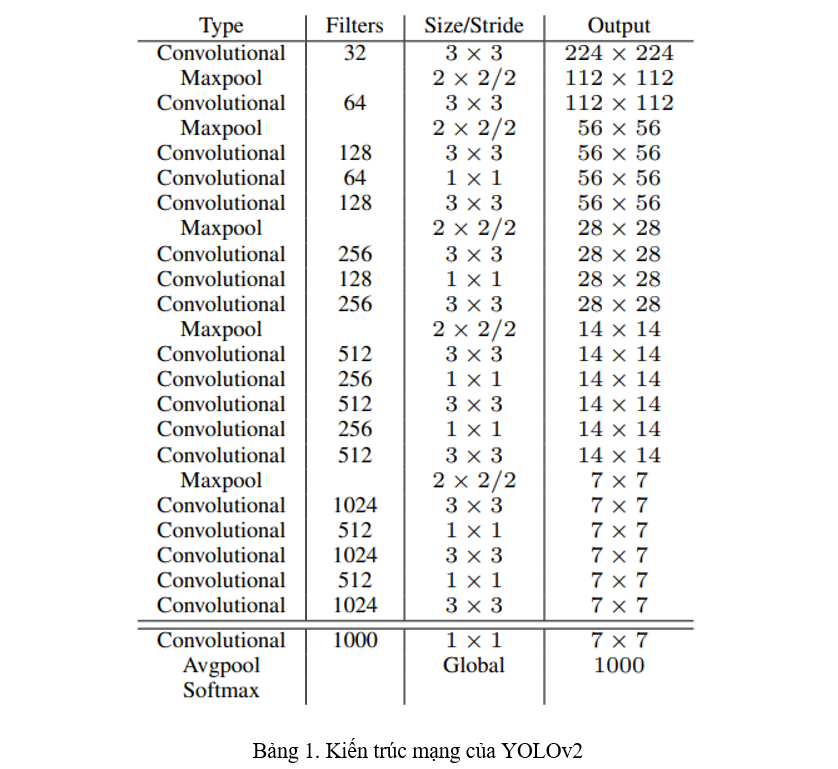
Darknet-19. Kiến trúc mạng của YOLOv2 được thể hiện ở bảng 1, được gọi là Darknet-19 vì có 19 lớp Convolution (Conv). Phần này mình sẽ nói về những thay đổi trong kiến trúc cũng như là cách training của YOLOv2.
Batch Norm. Kiến trúc của YOLOv2 đã được thêm vào đó những lớp BatchNorm để việc training nhanh hơn và ổn định hơn. Với việc thêm vào BatchNorm, DropOut được loại bỏ khỏi model mà không sợ bị overfitting.
High-res Classifier. Backbone của YOLOv2 được pretrained trên ImageNet. Trong YOLOv1, backbone được train trên ImageNet với kích thước ảnh , lúc train detection với toàn bộ model thì lại sử dụng kích thước ảnh . Việc chuyển đột ngột như vậy khiến model phải vừa học Object Detection lại còn vừa phải thích ứng với kích thước ảnh mới. Vì vậy, trong YOLOv2, backbone trước tiên được finetune trên ImageNet với kích thước ảnh trong vòng 10 epochs, rồi mới chuyển sang dạng Object Detection.
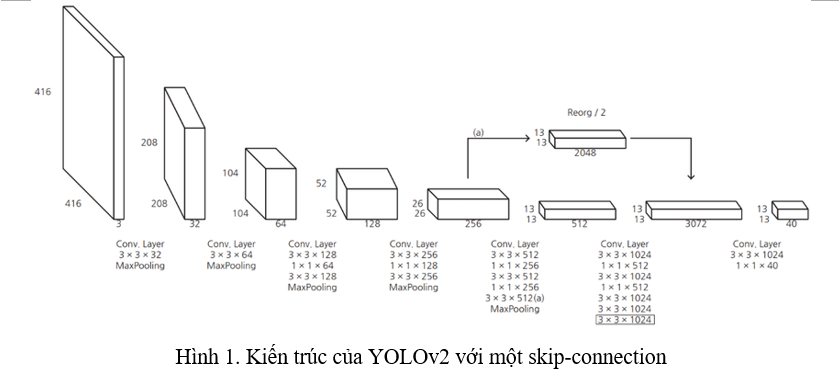
Fine-grained Features. Thay vì predict trên grid feature map như YOLOv1 thì YOLOv2 predict trên một grid feature map, việc này sẽ khiến YOLOv2 predict những object nhỏ tốt hơn. Hơn nữa, YOLOv2 cũng sử dụng một skip-connection để kết hợp thông tin từ feature map ở layer trước đó vào feature map cuối (Hình 1).
Multi-scale training. Trước đó, YOLOv2 chỉ train với kích thước ảnh . Sau khi áp dụng Anchor Box (sẽ nói ở phần sau), YOLO đổi kích thước ảnh thành . Tuy nhiên, YOLOv2 muốn model có thể detect tốt với nhiều kích thước ảnh khác nhau, vì vậy, cứ mỗi 10 batches, YOLOv2 lại thay đổi kích thước ảnh đầu vào một lần. Sở dĩ điều này có thể thực hiện được vì kiến trúc mạng của YOLOv2 hoàn toàn tạo từ các lớp Conv và có hệ số suy giảm là 32. Do đó, kích thước ảnh đầu vào của YOLOv2 thay đổi với kích thước là bội số của 32, được lấy trong khoảng .
Những thay đổi khác
Áp dụng Anchor Box. Trong YOLOv2, tác giả áp dụng Anchor Box được sử dụng trong Faster R-CNN. Lúc này, kích thước ảnh đầu vào được chuyển từ thành vì tác giả muốn feature map thu được ở lớp cuối cùng là số lẻ (với kích thước ảnh thì feature map ở lớp cuối là ) để luôn có một ô trung tâm của feature map. Ý tưởng này đến từ việc các ảnh trong dataset COCO thường có một vật ở giữa ảnh, vì vậy, việc có một ô trung tâm của feature map để Anchor Box có thể dễ dàng lấy được luôn vật đó. Sử dụng Anchor Box, YOLOv2 bị giảm đi 0.3 mAP nhưng bù lại, Recall tăng lên. Tức là việc sử dụng Anchor Box khiến YOLOv2 phát hiện được nhiều vật thể hơn, nhưng bù lại, khả năng phát hiện chính xác lại kém đi.
Trong các mô hình 2 pha (họ nhà R-CNN), việc Anchor Box hoạt động rất tốt vì pha thứ nhất đã bao gồm việc tối ưu vị trí cho Bounding Box từ Anchor Box, còn trong YOLO thì không có. Do vậy, việc có các Anchor Box đẹp được sinh ra ngay từ lúc đầu khá là quan trọng. YOLOv2 đã thêm vào bước chọn các chỉ số cho Anchor Box được sinh ra ngay từ lúc đầu thông qua thuật toán k-means.
Thêm vào đó, việc tối ưu vị trí Bounding Box từ Anchor Box sinh ra được sử dụng trong Faster R-CNN đó chính là: model sẽ dự đoán độ dịch chuyển của Anchor Box gọi là để suy ra vị trí của tâm Bounding Box thông qua một công thức biến đổi.
YOLOv2 nhận thấy việc này là không phù hợp, nên đã thêm vào một số giới hạn. YOLOv2 cũng vẫn dự đoán độ dịch chuyển và Objectness Score , nhưng, lúc này, bị giới hạn giá trị của chúng trong khoảng , việc này giới hạn vị trí tâm của Bounding Box khi thực hiện phép biến đổi với , tức là khi predict tại một grid cell sẽ không khiến cho tâm bị ra ngoài grid cell đó. Nếu vẫn còn khó hiểu, các bạn có thể xem Hình 2 để hiểu rõ hơn công thức giới hạn được áp dụng cho của YOLOv2. Nếu vẫn chưa hiểu, hãy đọc tiếp đến YOLOv3 bên dưới.

Tổng kết
Những cải tiến của YOLOv2 bao gồm 2 phần chính:
- Sử dụng một kiến trúc mạng mới và cách training mới.
- Áp dụng và thay đổi Anchor Box cho phù hợp.
YOLOv3
YOLOv3 là một bản nâng cấp đáng giá của YOLOv2 đồng thời giải thích những gì còn chưa rõ của YOLOv2
Kiến trúc mạng
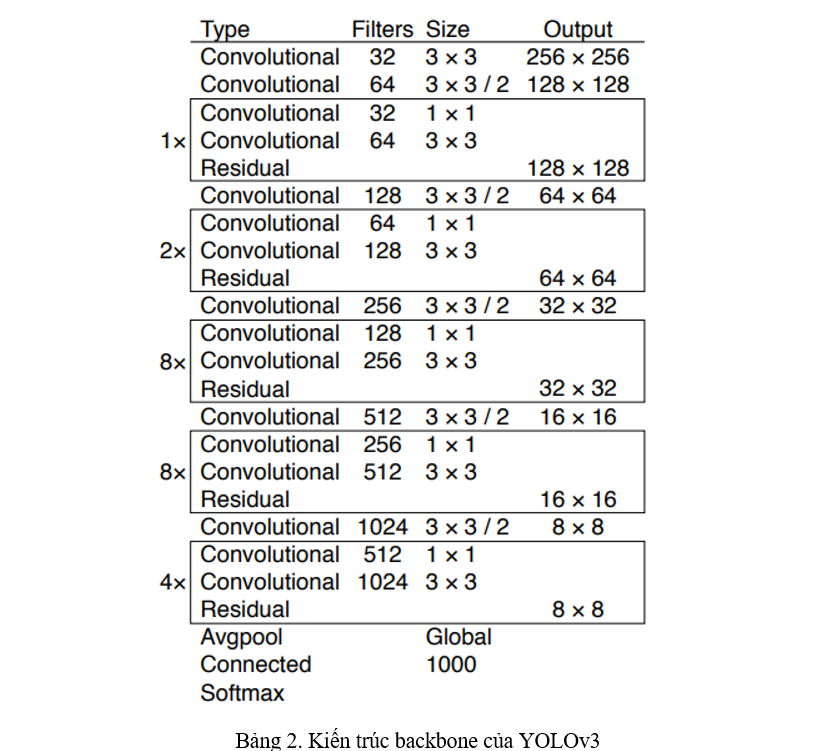
Backbone. YOLOv3 xây dựng một backbone mới, gọi là Darknet-53. Backbone của YOLOv1 thì sử dụng Convolution (gọi là Bottleneck) của Inception Network, lên YOLOv2 thì áp dụng thêm BatchNorm, sang YOLOv3 thì áp dụng thêm skip-connection từ ResNet, gọi là một Residual Block (Bảng 2).
Neck. Từ các phiên bản YOLO trước, phát hiện vật thể nhỏ luôn là một điểm yếu. Dù trong YOLOv2 đã sử dụng skip-connection từ layer trước đó để đưa thông tin từ feature map có kích thước lớn hơn vào feature map đằng sau, nhưng điều đó là không đủ. YOLOv3 là một sự nâng cấp cho vấn đề này, áp dụng Feature Pyramid Network, thực hiện phát hiện object ở 3 scale khác nhau của feature map (Hình 3).
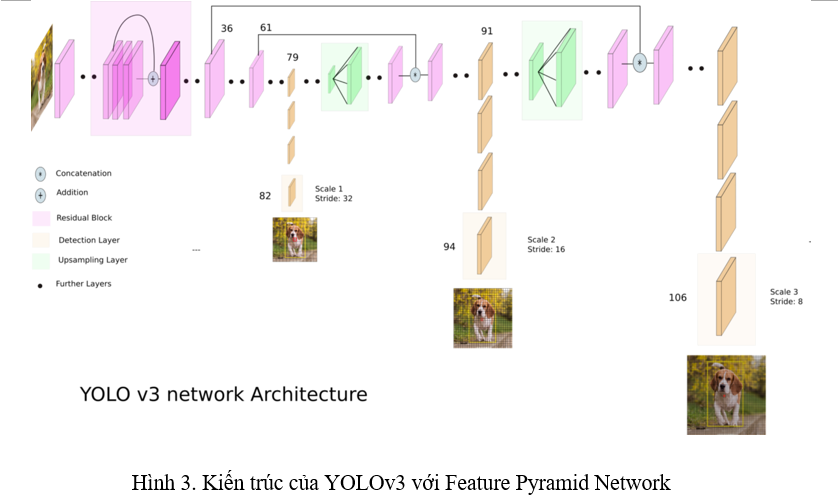
Thật ra lúc đầu nhìn hình kiến trúc bên trên thì mình vẫn chưa hiểu cái Feature Pyramid Network của nó lắm, nên là mình có làm thêm một cái hình bên dưới để mọi người dễ hình dung hơn.
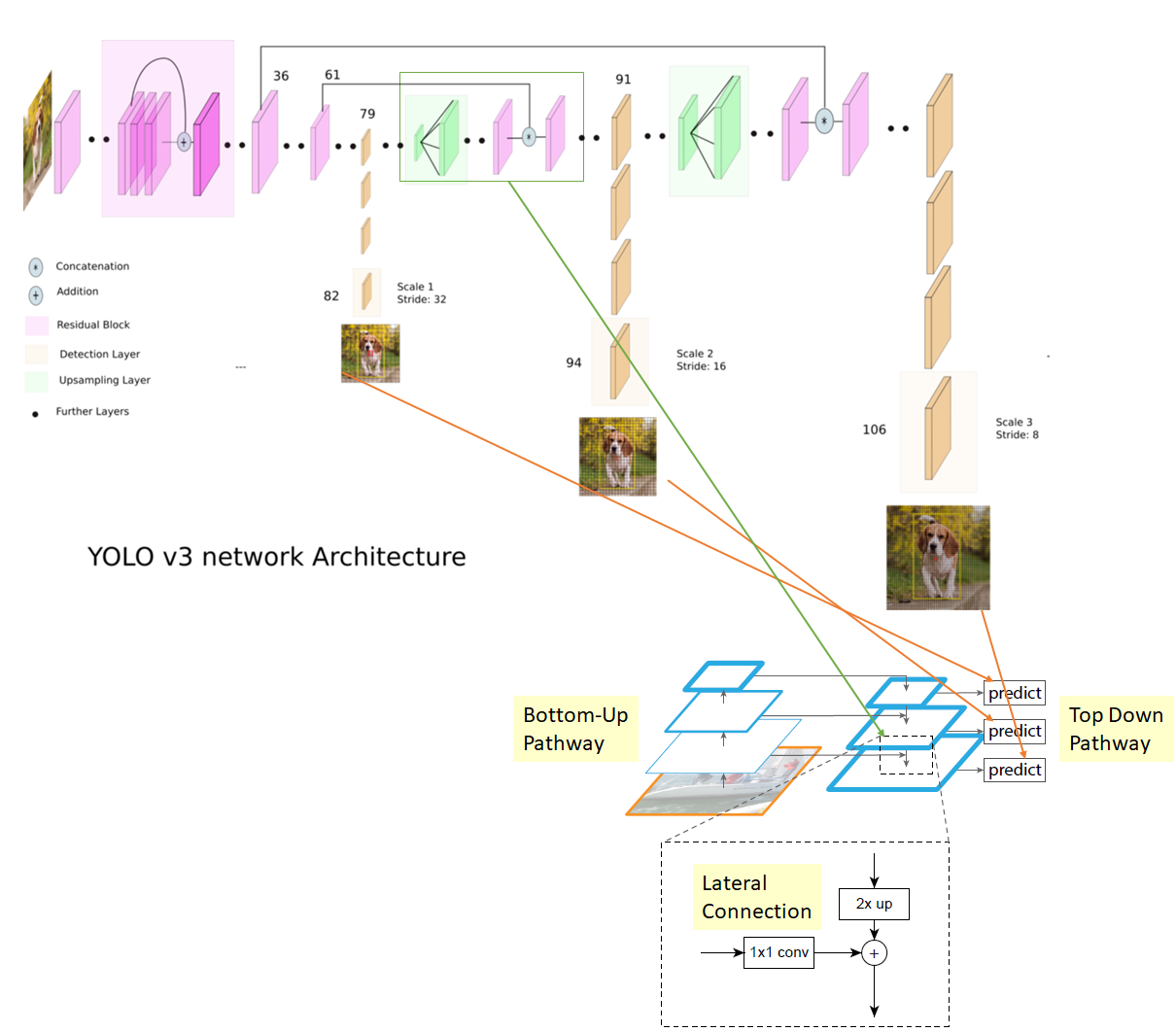
Những thay đổi khác
Xét một grid cell trong feature map, vector dự đoán của YOLO sẽ dự đoán với là tổng số class.
Classification prediction. Các phiên bản YOLO trước sử dụng hàm softmax ở output của classification. Nhưng từ YOLOv3, output của classification được chuyển thành sigmoid. Điều này là vì với một số dataset, ví dụ như Open Images Dataset, có một số object sẽ được phân tới tận 2 class (class person và class woman).
Bounding Box prediction. Giữ nguyên ý tưởng Anchor Box với k-means từ YOLOv2, YOLOv3 làm rõ cách chọn Anchor Box của mình. Ở một grid cell trong feature map, YOLOv3 tạo ra 9 Anchor Box (YOLOv2 là 5), cứ mỗi 3 Anchor Box sẽ thuộc về một scale. Ở YOLOv2 có nhắc đến hàm biến đổi để biến đổi Anchor Box được tạo ra thành Bounding Box cho object. Mình sẽ làm rõ công thức đấy ở đây.
Gọi 4 giá trị dịch chuyển mà YOLOv3 predict ra là . Như đã nói ở trên, YOLOv2 giới hạn ở trong khoảng , việc giới hạn này được áp dụng sử dụng hàm sigmoid . Xét một grid cell () trong feature map, Anchor Box được sinh ra có chiều dài, chiều rộng là (), với các giá trị dự đoán , công thức biến đổi có dạng:
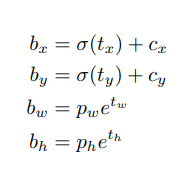
với là tâm của Bounding Box, là chiều dài, chiều rộng của Bounding Box. Nếu các bạn chưa hiểu tại sao chúng ta phải giới hạn thì một lần nữa hãy nhìn lại Hình 2 ở trên. Với và , nếu không giới hạn thì sẽ khiến tâm của Bounding Box vượt ra ngoài cái grid cell đó, sang hẳn grid cell .
Loss function. Loss function của YOLOv3 khá là khác so với các phiên bản YOLO trước nhưng lại không hề được đề cập đến trong paper. Mình khuyến khích nên so sánh với Loss function của YOLOv1 mình đã viết tại đây để có thể dễ dàng hiểu được các sự thay đổi.
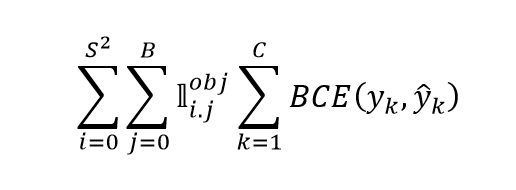
Xét Classification Loss, với việc áp dụng sigmoid trong classification, Classification Loss của YOLOv3 sẽ áp dụng Binary Cross Entropy chứ không còn là squared loss nữa. Tiếp tục thực hiện chia nhỏ hàm loss này cho dễ hiểu nhé. Xét một grid cell có tồn tại object, lặp qua giá trị trong vector Classification, tính BCE Loss giữa classification target và classification prediction . Xét toàn bộ Anchor Box () ở trên toàn bộ grid cell (), ta sẽ có được công thức của Classification Loss như trên.
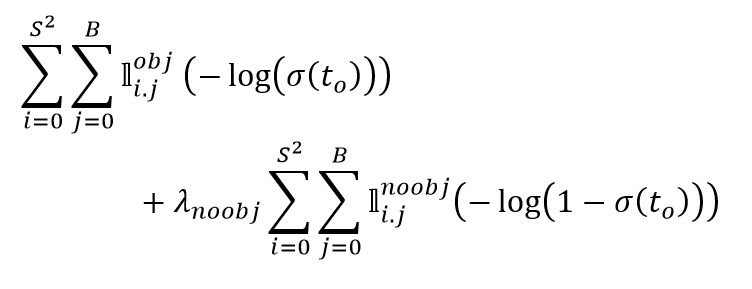
Xét Confidence Loss, ta có thể thấy thay vì là squared loss như YOLOv1, YOLOv3 đã áp dụng Binary Cross Entropy Loss. Nhưng không chỉ mỗi hàm loss là thay đổi, cả Confidence target cũng thay đổi. Confidence target trong YOLOv1 là IoU score giữa Bounding Box được dự đoán và ground truth Bounding Box, còn trong YOLOv3, confidence target nếu IoU score giữa một Anchor Box trong số 9 Anchor Box sinh ra với ground truth Bounding Box là lớn nhất, và được đưa vào vế trên của Confidence Loss để tính. Với những Anchor Box mà có IoU score giữa chúng với ground truth Bounding Box nhỏ hơn một threshold là thì chúng sẽ được đưa vào đưa vào vế dưới của Confidence Loss. Còn những Anchor Box mà có IoU score lớn hơn threshold nhưng lại không phải là Anchor Box được chọn ở trong vế trên thì chúng sẽ không được đưa vào hàm loss.
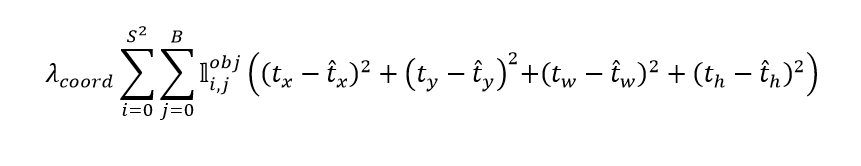
Còn Regresion Loss thì gần như tương đương, chỉ bỏ đi căn bậc 2 khi ở phần chiều dài và chiều rộng.
Tổng kết
Những cải tiến của YOLOv3 bao gồm:
- Một backbone mới: kết hợp skip-connection vào trong backbone, tăng số lớp Convolution lên.
- Thêm Feature Pyramid Network, thực hiện predict tại 3 scale
- Hàm loss mới
Kết
Bài này đã trình bày hiểu biết của mình về YOLOv2 và YOLOv3, đồng thời so sánh chúng với nhau để các bạn có thể thấy được sự khác biệt. Nếu có gì sai sót, mong mọi người có thể góp ý cho mình.
All rights reserved
