
SVTR NET - Lời giải hoàn hảo cho bài toán OCR ?
Bài đăng này đã không được cập nhật trong 3 năm
I. Tổng quan
 Ứng dụng bài toán Text Recognition (ảnh mạng)
Ứng dụng bài toán Text Recognition (ảnh mạng)
Bài toán nhận dạng chữ đến nay đã thu hút rất nhiều học giả nghiên cứu vì tính thách thức cũng như khả năng ứng dụng thực tế của bài toán này. Bài toán này có nhiệm vụ chuyển vùng chữ được xác định bởi mô hình phát hiện chữ ở dạng ảnh về dạng chữ. Bài toán nhận dạng chữ có thể phân thành hai loại: nhận dạng chữ thông thường (regular text recognition) và nhận dạng chữ có sự biến dạng (irregular text recognition).
1. Regular text recognition
Trước đây có một số phương pháp nhận dạng chữ thông thường bằng các phát hiện vị trí từng kí tự và nhận dạng từng kí tự bằng quy hoạch động và thuật toán tìm kiếm được đề cập trong bài báo End-to-End Scene Text Recognition. Các phương pháp này có hạn chế do không khai thác được mối quan hệ về mặt ngữ nghĩa giữa các kí tự. Sau này có một số phương pháp khắc phục được hạn chế này bằng cách coi ảnh đầu vào và chữ đầu ra là hai chuỗi và xử lý như bài toán sequence-to-sequence đã đạt độ chính xác cao trên nhiều bộ dữ liệu. Mô hình này sử dụng kiến trúc RNN hoặc Transformer kết hợp với CNN để biểu diễn mối quan hệ giữa các kí tự. Mô hình RNN có nhược điểm tính toán tùân tự nên thời gian huấn luyện sẽ bị đẩy lên rất lâu và học phụ thuộc xa đối với những câu dài kém hơn. Trong khi đó mô hình Transformer có khả năng phụ thuộc xa tốt hơn nhưng việc tính toán trên các thiết bị cpu chậm hơn đáng kể.
2. Irregular text recognition
Chữ biến dạng có thế là các chữ nghiêng, chữ cong hoặc bị mờ, méo do nhiều yếu tố. Để giải quyết vấn đề này, bài báo Learning to Read Irregular Text with Attention Mechanisms đã đề xuất một mạng bổ trợ phát hiện kí tự hay bài báo Robust scene text recognition with automatic rectification giải quyết vấn đề này bằng cách kết hợp một mạng học khả năng xoay ảnh đầu vào là Spatial Transformer Network
II. SVTR-NET - Giải pháp hoàn hảo cho bài toán OCR?
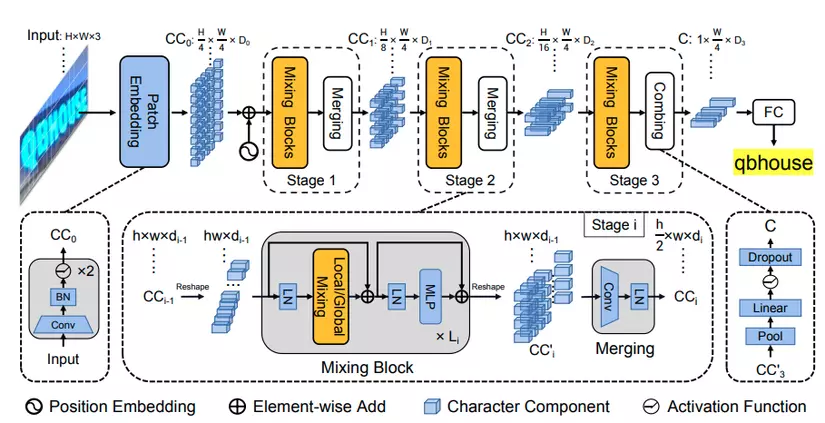 Kiến trúc SVTR (ảnh trong paper)
Kiến trúc SVTR (ảnh trong paper)
Như đã trình bày phía trên, các phương pháp cho mô hình Text Recogntion phổ biến nhất bao gồm 2 phần. Phần một là kiến trúc CNN đóng vai trò như một bộ trích xuất đặc trưng. Phần hai là kiến trúc chuyển bản đồ đặc trưng thành dạng chuỗi. Phần hai này có thể dùng các lớp mạng RNN hoặc Transformer. Tuy nhiên cả hai mô đun CNN, RNN hoặc Transformer đều có những ưu nhược điểm nhất định. CNN thì biểu diễn tốt cho mối liên hệ địa phương (local correlation) còn Transformer lại có thể biễu diễn tốt cho những mối liên hệ toàn cục. Để kết hợp ưu điểm của cả hai kiến trúc này, SVTR NET được đề xuất trong bài báo SVTR: Scene Text Recognition with a Single Visual Model vào tháng 5 năm 2022 giúp phần nào giải quyết điều đó.
Tổng quan, kiến trúc SVTR nhận đầu vào là ảnh sau đó cho qua một lớp Patch Embedding chia nhỏ ảnh đầu vào thành dạng chuỗi. Tư tưởng phần này tương tự mô đun Patch Embedding được đề cập trong mô hình Vision Transformer. Vision Transformer là một dạng kiến trúc Transformer được ứng dụng xử lý cho đầu vào là ảnh. Các bạn chưa tìm hiểu về mô hình này có thể tham khảo bài viết Vision Transformer - An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale . Việc chia nhỏ ảnh thành các phần tử nhỏ hơn giúp chúng ta dễ dàng xử lý ở dạng chuỗi như các thuật toán trong bài toán xử lý ngôn ngữ thông thường. Các phần tử này sau đó được cho qua 3 tầng. Mỗi tầng gồm hai mô đun chính là Mixing block và Merging. Hai mô đun đóng vai trò quan trọng tạo nên hiệu quả của mô hình. Các tầng được thiết kế để trích xuất thông tin đặc trưng trên nhiều scale khác nhau, ngăn ngừa hiện tượng biểu diễn thừa thông tin qua các tầng. Để hiểu sâu hơn, ta cùng đi vào chi tiết để giải thích hơn kiến trúc và ý nghĩa từng mô đun này.
1. Patch Embedding
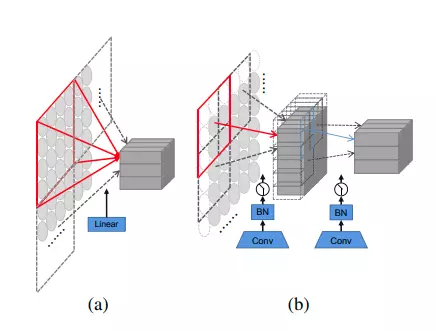 Kiến trúc mô đun Patch Embedding (ảnh trong paper)
Kiến trúc mô đun Patch Embedding (ảnh trong paper)
Mô đun Patch Embedding nhận đầu vào là ma trận ảnh có kích thước và chuyển thành phần tử có . Mỗi phần tử đóng vai trò như các kí tự trong các bài toán xử lý ngôn ngữ. Kiến trúc Pathc Embedding bao gồm 2 lớp convolution có kernel , stride 2 theo sau đó là lớp Batch Normalization. Theo nghiên cứu tác giả, các chiến thuật Patch Embedding khác nhau sẽ ảnh hưởng đến hiệu quả của mô hình.
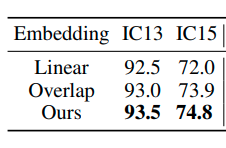 So sánh ảnh hưởng của Patch Embedding tới hiệu quả mô hình
So sánh ảnh hưởng của Patch Embedding tới hiệu quả mô hình
2. Mixing Blocks
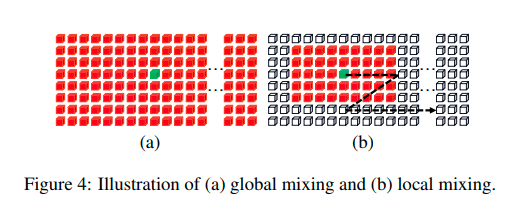
Mixing Blocks gồm có hai loại là:
- Local mixing block
- Global mixing block
Động lực của hai mô đun này xuất phát từ 2 ý tưởng: một mô hình nhận diện chữ tốt ngoài biểu diễn được mối liên hệ giữa các chữ tức là thông tin toàn cục như các phương pháp CRNN+Attention đang làm thì còn phải biểu diễn tốt tương quan giữa các chi tiết trong cùng một kí tự. Khác nhau giữa các nét chấm, phẩy cũng tạo nên khác nhau giữa các chữ cái. Ví dụ chữ o, ơ, ô, ố, ...
Global mixing dùng để biểu diễn quan hệ giữa các phần tử non-text và text qua đó biểu diễn phụ thuộc xa giữa các kí tự với nhau. Biễu diễn phụ thuộc xa tác giả sử dụng kiến trúc kiến trúc self-attention kết hợp với một số lớp như LayerNorm và MLP.

Local mixing dùng để biểu diễn mối quan hệ giữa các nét trong cùng một kí tự. Điều này đặc biệt ý nghĩa đối với các chữ có kí tự phức tạp như tiếng Nhật. Như hình trên bạn có thể thấy chỉ một chút khác nhau về độ dài ngắn giữa các nét cũng đã đủ tạo ra một chữ khác. Locall mixing cũng sử dụng cơ chế window slide trượt trên các vùng kích thước và tính toán mối liên hệ giữa các phần tử trong vùng cửa sổ đó. Chú ý một chút các phần tử ở đây chính là các phần tử được chia qua lớp Patch Embedding được trình bày bên trên.
Kiến trúc có thể biểu diễn tốt sự khác biệt giữa các chữ đến từng chi tiết nhỏ sẽ giúp cho quá trình phân biệt bằng CTC Loss trở nên tốt hơn sau này.
3. Merging và Combining
Kiến trúc Merging này có chức năng trích xuất đặc trưng trên nhiều các scale khác nhau loại bỏ hiện tượng biểu diễn thừa thông tin. Để thực hiện điều này, sau mỗi lớp Mixing Blocks, tác giả sử dụng một lớp convolution có kích thước kernel , bước nhảy 2 theo chiều cao và 1 theo chiều rộng. Như vậy với một đầu vào có kích thước sẽ cho ra đầu ra có kích thước . Chiều cao sẽ được giảm đi một nửa tuy nhiên chiều rộng bản đồ đặc trưng sẽ được giữ nguyên giúp giảm chi phí tính toán và các lớp ở các tầng khác nhau không biểu diễn cùng một thông tin. Điều này có ý nghĩa vì các ảnh cho bài toán nhận dạng chữ có kích thước chiều rộng lớn hơn chiều cao rất nhiều.
Kiến trúc Combining được sử dụng ở tầng cuối cùng của mô hình thay thế cho kiến trúc Merging đưa kích thước chiều cao về 1 bằng lớp Poopling. Theo sau đó là lớp fully connected và activation. Việc sử dụng lớp Combining ở cuối thay vì Merging giúp tránh việc sử dụng lớp tích chập đối với các ma trận đặc trưng quá nhỏ gây mất đặc trưng ban đầu.
III. Ứng dụng
 Tôi đã ứng dụng mô hình SVTR trong các sản phẩm xử lý tiếng Nhật và cho về các kết quả tốt hơn hẳn so với các phương pháp truyền thống như CRNN+Attention hay Transformer OCR trên cả phương diện về độ chính xác cũng như tốc độ xử lý.
Tôi đã ứng dụng mô hình SVTR trong các sản phẩm xử lý tiếng Nhật và cho về các kết quả tốt hơn hẳn so với các phương pháp truyền thống như CRNN+Attention hay Transformer OCR trên cả phương diện về độ chính xác cũng như tốc độ xử lý.
IV. Tổng kết
Ở bài này mình đã giới thiệu cho các bạn về kiến trúc SVTR cũng như các đột phá về ý tưởng. Cảm ơn các bạn đã theo dõi và hẹn gặp lại các bạn trong các bài viết tiếp theo.
Tài liệu tham khảo
All rights reserved
