
Tổng quan Search Engine và Vector Database [Part 1]
Bài đăng này đã không được cập nhật trong 2 năm
Hiện nay, các công cụ Vector Search Engine như Elastic Search, Azure Cognitive Search vừa lưu trữ data vừa có tính năng search trong khi các Vector database như supabase,... cũng hỗ trợ cả hai tính năng đó. Điều này đôi khi khiến chúng ta khó phân biệt giữa hai khái niệm này. Trong chuỗi bài viết này, mình sẽ cùng các bạn tìm hiểu về hai khái niệm này cũng như phân biệt giữa chúng.
A. Một số khái niệm cần biết
1. Embedding Vector
Embedding vector là vector thường có nhiều chiều giúp biểu diễn thông tin đặc trưng cho một đối tượng đầu vào như ảnh, một câu, một đoạn âm thanh,.... Chúng được sinh ra bởi các mô hình AI hay còn gọi là embedding model được huấn luyện trên rất nhiều dữ liệu. Nếu bạn chưa có tìm hiểu nhiều kiến thức về học máy, bạn có thể đơn giản hình dung cách embedding vector được sinh ra như một black box dưới đây
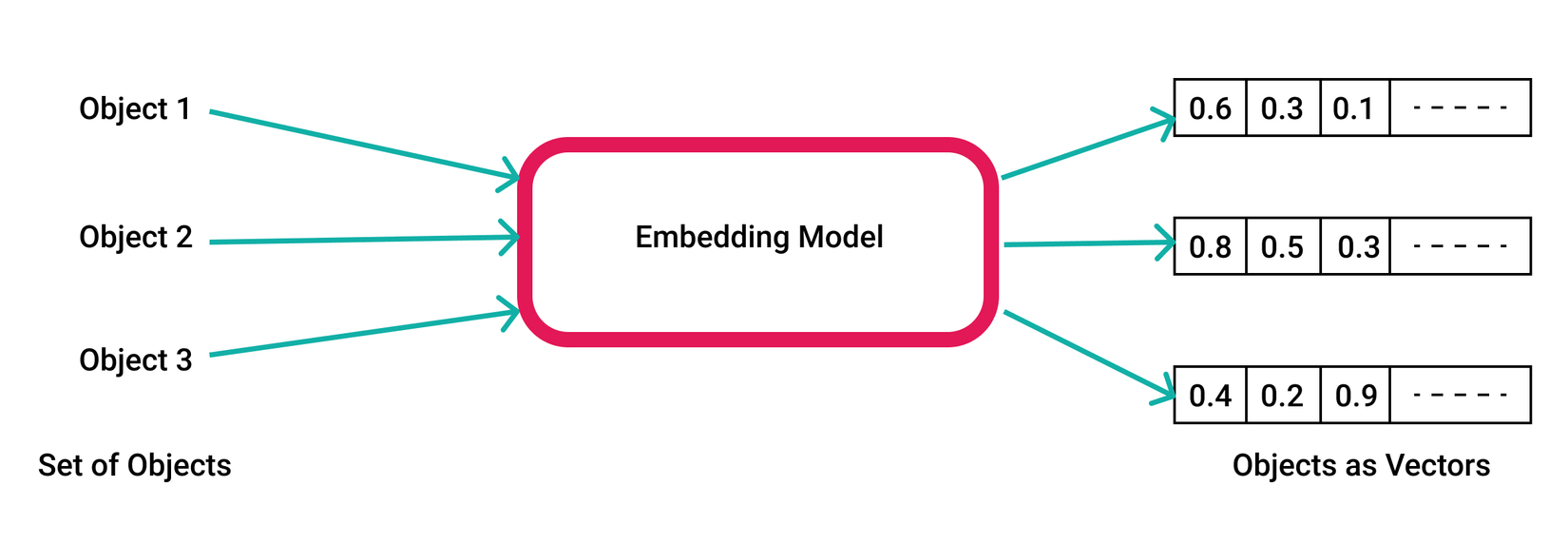
Tham khảo: https://www.pinecone.io/learn/vector-embeddings/
Do embedding vector biểu diễn đặc trưng của một đối tượng đầu vào nên các đối tượng giống nhau hoặc cùng thể loại, có mối liên hệ gần với nhau sẽ có khoảng cách giữa các vector gần nhau.
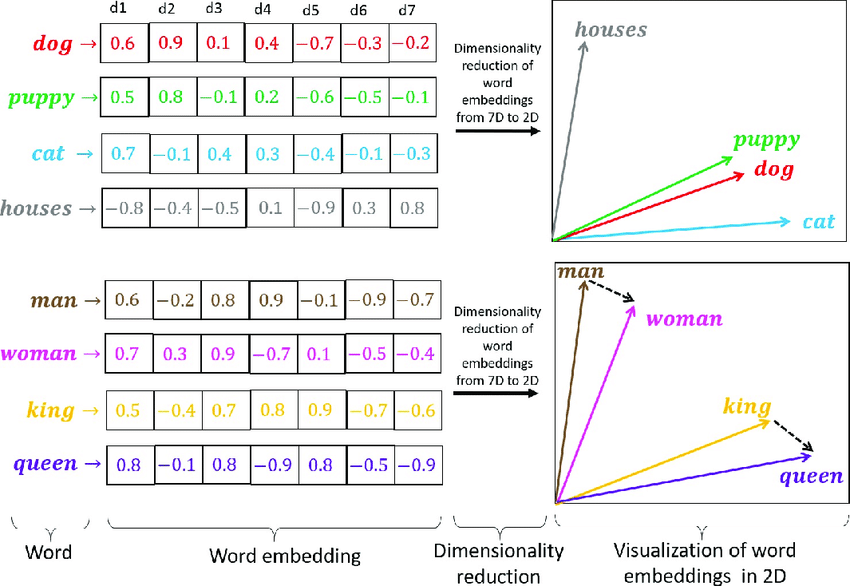
2. Vector Search
Vector Search là phương thức tìm kiếm dữ liệu có liên quan tới câu truy vấn đầu vào dựa trên độ tương tự giữa các embedding vector thay vì chỉ dựa trên tương tự về mặt từ ngữ. Nhờ tận dụng ưu điểm của embedding vector là có thể biểu diễn đặc trưng ngữ nghĩa, vector search có thể khắc phục nhiều nhược điểm của các công cụ tìm kiếm truyền thống
Document 1: Theo quy định về bảo hiểm y tế trẻ em, trẻ nhỏ từ khi sinh ra đã được tham gia BHYT
Document 2: Theo quy định về bảo hiểm y tế cho người lớn hơn 18 tuổi,.....
Question: Cho tôi hỏi về bảo hiểm cho bé
Như ta có thể thấy độ tương tư question với 2 document như trên có thể không khác nhau nhiều với phương pháp tìm kiếm truyền thống dựa trên tìm kiếm từ tương ứng. Nhưng với vector search biết được từ bé và trẻ em gần giống nhau do đó độ tương tự giữa hai vector question và document 1 sẽ gần nhau sẽ cho ra kết quả tốt hơn.
3. Vector Database
Vector Database giống với các database truyền thống khác có hỗ trợ thêm lưu trữ, quản lý vector embedding. Một số vector db có sẵn bản open source chúng ta có thể trải nghiệm như là Supabase, Weaviate, ....
B. Vector Search vs Vector Database
Ở trong bài viết này, tôi chọn một số khía cạnh tiêu biểu đại diện cho sự khác nhau giữa hai khái niệm
1. Loại dữ liệu lưu trữ
Vector Search Engine chỉ lưu trữ embedding vector và thường không lưu cùng các thông tin liên quan. Những thông tin liên quan này cần được lưu trữ ở hệ thống lưu trữ thứ hai
Vector Database lưu trữ cả thông tin liên quan và vector
2. CRUD support
CRUD bao gồm các hoạt động create, read, update, delete trên dữ liệu
Vector Search Engine không hỗ trợ CRUD do dữ liệu sau khi tạo của search engine không thể xóa hay thay đổi.
Vector Database giải quyết được hạn chế này của search engine, chúng cho phép cập nhật, xóa sau khi được tạo
3. Real-time search
Vector Database cho phép query, xóa và cập nhật dữ liệu khi quá trình nhập dữ liệu đang diễn ra. Khi chúng ta upload hàng triệu đối tượng, chúng ta không thể chờ quá trình import hoàn tất mới có thể tiến hành truy vấn. Còn điều này là hạn chế đối với Vector Search
C. Vector Search Engine - Azure Cognitive Search
Trong phần này tôi xin giới thiệu vector search engine qua một công cụ có tên là Cognitive Search - một sản phẩm của nhà Microsoft. Azure Cognitive Search hay còn được biết đến với cái tên Azure Search là một dịch vụ search trên nền tảng cloud giúp anh em dev chúng ta triển khai, vận hành cũng như dễ dàng tích hợp với hệ sinh thái Azure.
Azure Cognitive Search là công cụ search cho phép chúng ta có nhiều phương thức tìm kiếm:
- Full-text search
- Vector search
- Hybrid search (Full-text search + Vector search)
- Semantic search
Nhưng trước khi đến với từng phương thức tìm kiếm cụ thể, chúng ta sẽ đi qua luồng hoạt động và các thành phần tổng quát của công cụ tìm kiếm Full-text search, đây cũng là phương thức tìm kiếm cơ bản có độ phức tạp cao nhất
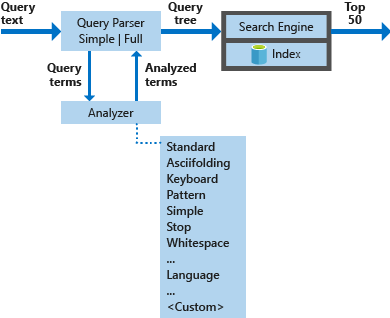
Tham khảo: https://learn.microsoft.com/en-us/azure/search/search-lucene-query-architecture
I. Azure Full-text search
Azure Full Text Search hay các công cụ search engine khác về tổng quan không có nhiều sự khác biệt về luồng hoạt động bao gồm 4 phần chính:
-
Query parsers: Tiền xử lý câu lệnh đầu vào như chia nhỏ thành các query term dựa trên query operator gửi đến analyzer xử lý tạo thành các analyzed term kết hợp với các thông tin khác gửi đến search engine.
-
Analyzer: Có nhiệm vụ xử lý ngôn ngữ tùy thuộc vào ngôn ngữ được cấu hình trước đó
-
Indexer: Có nhiệm vụ lưu dữ liệu vào đơn vị cấu trúc dữ liệu có chức năng lưu và tổ chức phần thông tin phục vụ trong quá trình search có tên là index
-
Search Engine: tìm kiếm dữ liệu dựa trên matching score. Phần score này tôi sẽ đề cập riêng khi giới thiệu đến từng loại search ở bên dưới.
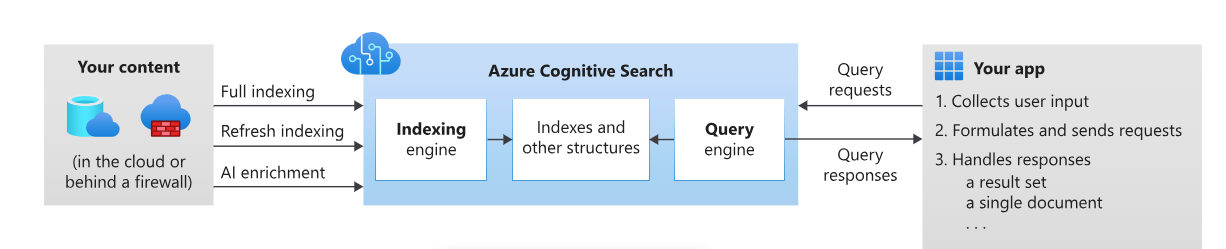 Để hình dung dễ hơn, chúng ta có thể lấy bối cảnh bài toán tìm kiếm thông tin trên kho dữ liệu gồm hai dịch vụ:
Để hình dung dễ hơn, chúng ta có thể lấy bối cảnh bài toán tìm kiếm thông tin trên kho dữ liệu gồm hai dịch vụ:
- Đẩy dữ liệu vào trong search engine
- Tìm kiếm thông tin
Ở phần đẩy dữ liệu, dữ liệu của chúng ta từ bên dịch vụ lưu trữ thứ hai đi qua analyzer rồi qua index được lưu trữ trong search engine. Ở phần tìm kiếm thông tin, chúng ta tạo ra câu lệnh truy vấn. Câu lệnh này sẽ đi qua lần lượt query parser, analyzer rồi đến search engine. Chi tiết thêm về từng module mình sẽ giải thích ở phần dưới
1. Query Parser
Câu lệnh truy vấn của Azure Full Text Search có cú pháp dựa trên Query lucene syntax. Trong đó câu lệnh đầu vào (query) được chia nhỏ thành câu lệnh nhỏ hơn (sub-queries) bởi các thành phần được gọi là các separate operators được biểu diễn dưới dạng các ký tự đặc biệt như *, + .
Azure search hồ trợ ba dạng sub-queries là:
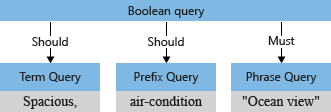
- Term query: cho những từ đơn lẻ
- Phrase query cho những cụm từ
- Prefix term dành cho phần prefix
Tùy vào các separate operator đi kèm với sub-query đó mà search engine sẽ hiểu được mức độ quan trọng của chúng là must, should be, etc
Ví dụ với câu lệnh truy vấn như dưới đây
"search": "Spacious, air-condition* +\"Ocean view\"",
Và kết quả tương ứng
2. Analyzer (Lexical analysis)
Analyzer được xem như là một module tiền xử lý ngôn ngữ giúp tối ưu hiệu quả hoạt động của các search engine ở trong hai bước indexing và query execution. Do là bộ tiền xử lý ngôn ngữ là cách thức chúng hoạt động cũng tùy thuộc vào ngôn ngữ mà bạn mong muốn xử lý và cấu hình.
Ví dụ trong tiếng Anh một số bước xử lý analyzer thực hiện như sau:
- Loại bỏ stopwords như is, and, etc
- Chia nhỏ các cụm từ hoặc từ nối thành các thành phần nhỏ hơn
- Viết thường hóa toàn bộ câu đầu vào
- Chuyển các từ về dạng nguyên thủy như swimming -> swim
Chúng ta cũng có thể viết lại các phần xử lý analyzer này theo hướng dẫn dưới đây How to customize analyzer. Có một lưu ý là analyzer chỉ thực hiện trên những trường được cấu hình là Searchable.
3. Indexer
Indexer là module có nhiệm vụ lưu trữ dữ liệu cần thiết cho quá trình tìm kiếm vào các đơn vị cấu trúc dữ liệu gọi là index. Index bao gồm các đơn vị nhỏ hơn gọi là document. Cấu trúc của document được định nghĩa bởi index schema gồm các trường, định dạng dữ liệu cũng như các thông tin khác. Cấu trúc một document có thể được hình dung như sau:
{
"name": "name_of_index, unique across the service",
"fields": [
{
"name": "name_of_field",
"type": "Edm.String | Collection(Edm.String) | Edm.Int32 | Edm.Int64 | Edm.Double | Edm.Boolean | Edm.DateTimeOffset | Edm.GeographyPoint",
"searchable": true (default where applicable) | false (only Edm.String and Collection(Edm.String) fields can be searchable),
"filterable": true (default) | false,
"sortable": true (default where applicable) | false (Collection(Edm.String) fields cannot be sortable),
"facetable": true (default where applicable) | false (Edm.GeographyPoint fields cannot be facetable),
"key": true | false (default, only Edm.String fields can be keys),
"retrievable": true (default) | false,
"analyzer": "name_of_analyzer_for_search_and_indexing", (only if 'searchAnalyzer' and 'indexAnalyzer' are not set)
"searchAnalyzer": "name_of_search_analyzer", (only if 'indexAnalyzer' is set and 'analyzer' is not set)
"indexAnalyzer": "name_of_indexing_analyzer", (only if 'searchAnalyzer' is set and 'analyzer' is not set)
"synonymMaps": [ "name_of_synonym_map" ] (optional, only one synonym map per field is currently supported)
}
],
"suggesters": [ ],
"scoringProfiles": [ ],
"analyzers":(optional)[ ... ],
"charFilters":(optional)[ ... ],
"tokenizers":(optional)[ ... ],
"tokenFilters":(optional)[ ... ],
"defaultScoringProfile": (optional) "...",
"corsOptions": (optional) { },
"encryptionKey":(optional){ }
}
}
Các bạn có thể tìm hiểu kĩ hơn về index ở trang sau What is an index
Có một điều quan trọng các bạn cần chú ý rằng Azure giới hạn index size khi index vector. Azure cấp phát vector index size dựa trên số partition mà các bạn cấu hình. Mỗi partition được thêm vào thì gia tăng thêm vector index size. Khi vector index size vượt cấu hình được qui định, chúng ta không thể index thêm bất cứ request nào nữa.
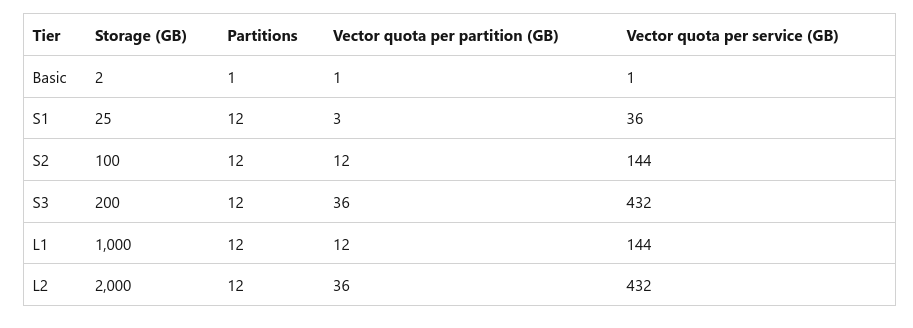
Có rất nhiều các yếu tố ảnh hưởng đến vector index size như kích thước ban đầu của data, phát sinh chi phí của thuật toán indexing, chi phí phát sinh khi xóa sửa document trong index.
Tạm kết
Ở phần 1 chúng ta đã đi nhanh qua về các khái niệm cần biết như embedding vector, vector search, vector database cũng như đi qua một phần cách hoạt động của search engine thông qua ví dụ về Azure Cognitive Search. Trong phần tiếp theo, chúng ta sẽ tìm hiểu về các phương thức search cũng như các tính score của từng loại search. Hẹn gặp lại bạn trong các bài viết tiếp theo 😄
Tham khảo
All rights reserved
