
Bài toán phát hiện chữ (Text Detection) và mô hình DB (Phần 1)
Bài đăng này đã không được cập nhật trong 4 năm
I. Tổng quan bài toán phát hiện chữ
 Ảnh 1: Minh họa ứng dụng phát hiện chữ trong thực tế
Ảnh 1: Minh họa ứng dụng phát hiện chữ trong thực tế
Bài toán phát hiện chữ trong ảnh là bài toán xác định vị trị vùng có chữ trong ảnh đã trở nên phổ biến cả về mặt ứng dụng và nghiên cứu vì khả năng ứng dụng của nó . Đến hiện tại, bài toán phát hiện chữ trong ảnh thường được tiếp cận theo các hướng: mô hình phát hiện chữ dựa trên cơ chế hồi quy, mô hình phát hiện chữ dựa trên cơ chế phân đoạn, mô hình phát hiện chữ end-to-end.
1. Mô hình phát hiện chữ dựa trên cơ chế hồi quy (Regression based method)
Mô hình này giống như các mô hình dùng để phát hiện vật thể trong ảnh (object detector) và vật thể ở đây là chữ. Tuy nhiên do chữ có kích thước và hình dáng đa dạng như chữ cong, chữ ngiêng. Do đó các mô hình phát hiện chữ dựa trên mô hình hồi quy như SSD, YOLO, Faster RCNN ... đều gặp hạn chế trong biểu diễn tất cả các trường hợp có thể gặp trong thực tế.
2. Mô hình phát hiện chữ dựa trên cơ chế phân đoạn (Segmentation based method)
Mô hình này hoạt động dựa trên phương pháp phân đoạn ý nghĩa trong hình ảnh (segmentation), dự đoán các pixel ở cùng một đối tượng rồi sử dụng các thuật toán hậu xử lý để lấy ra vị trí các đối tượng vì vậy có thể xử lý tốt đối với độ đa dạng về hình dạng cũng như kích thước của chữ. Có rất nhiều các phương pháp đã được nghiên cứu như phương pháp dự đoán trên mức kí tự CRAFT hay dự đoán trên mức từ DB, Multi-scale FCN và PixelLink. Việc sử dụng trên mức kí tự sẽ không phải quan tâm nhiều tới vấn đề các từ sẽ được chia tách như thế nào vì việc chia tách dựa trên nhiều tiêu chí như ngữ nghĩa, khoảng cách, màu sắc, ... nhưng lại gặp nhược điểm là việc chuẩn bị dữ liệu cho mức kí tự khá khó khăn.
3. Mô hình phát hiện chữ end-to-end
Phương pháp end-to-end kết hợp cả hai mô hình phát hiện và nhận dạng chữ do đó có thể tăng cường độ chính xác của mô hình phát hiện chữ thông qua kết quả của mô hình nhận dạng chữ. Có một số mô hình đã được nghiên cứu như FOST, ...
II. Tư tưởng thiết kế mô hình DB
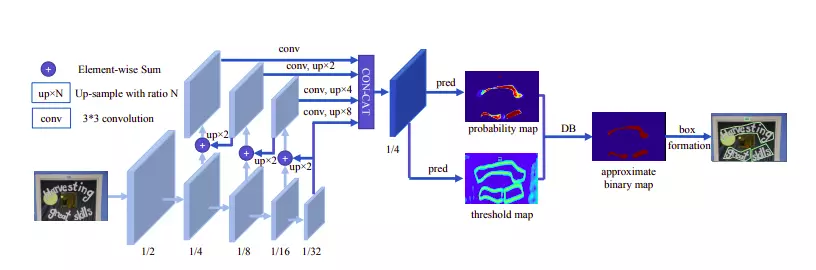 Ảnh 2: Kiến trúc mô hình DB
Ảnh 2: Kiến trúc mô hình DB
Các mô hình trong bài toán phát hiện chữ được nghiên cứu trước đây có quá trình hậu xử lý rất phức tạp để lấy được các thông tin vị trí của đối tượng trong ảnh. Các phương pháp này sẽ đặt một ngưỡng cố định để phân biệt đâu là điểm ảnh nền đâu là điểm ảnh đối tượng từ bản đồ xác suất được mô hình sinh ra. Việc đặt một ngưỡng cố định làm cho mô hình kém linh động và mất nhiều thời gian thử nghiệm để tìm ngưỡng phù hợp. Mô hình DB đã đế xuất một ý tưởng cho mô hình học luôn cách đặt giá trị ngưỡng này thông qua việc huấn luyện.
Kiến trúc mô hình được mô tả trên hình 2. Mô hình sẽ nhận ảnh đầu vào và cho qua một bộ trích xuất đặc trưng sinh ra bản đồ đặc trưng . Trong quá trình huấn luyện, bản đồ đặc trưng này sau đó được dùng để dự đoán bản đồ xác suất P và bản đồ ngưỡng T. Cuối cùng, sử dụng hai bản đồ này để tính ra bản đồ nhị phân được dùng cho quá trình hậu xử lý để lấy được dự đoán vị trí chữ trong ảnh sau này. Còn trong quá trình suy luận, chúng ta có thể lấy trực tiếp thông tin vị trí qua bản đồ xác xuất hoặc bản đồ nhị nhân.
Kiến trúc mô hình DB có hai ưu điểm nổi bật so với các kiến trúc khác cùng dựa trên mô hình phân đoạn:
- Kiến trúc DB có thể đạt độ chính xác cao với những bộ trích xuất đặc trưng nhẹ như ResNet18 như trong bài báo.
- Có thể học được cách đặt ngưỡng động trên phương pháp gọi là Differentiable binarization.
1. Standard binarization
Standard binarization hay còn gọi là phương pháp nhị phân hóa chuẩn được rất nhiều mô hình phát hiện chữ sử dụng. Phương pháp này nhận đầu vào là một bản đồ xác suất được sinh ra bởi bộ trích xuất đặc trưng và sinh ra bản đồ nhị phân có kích thước bằng với bản đồ xác xuất (H, W lần lượt chỉ chiều cao và chiều rộng của bản đồ). Thuật toán của phương pháp này nhận vào các giá trị điểm ảnh của bản đồ xác suât. Các giá trị điểm ảnh nào lớn hơn một ngưỡng cố định thì giá trị điểm ảnh trên bản đồ nhị phân tương ứng nhận giá trị 1 thể hiện điểm ảnh đó thuộc về đối tượng chữ, còn 0 thì điểm ảnh đó không phải đối tượng chữ.
Ở đây t là một ngưỡng cố định, (i, j) là tọa độ vị trí điểm ảnh trên bản đồ.
Phương pháp này có nhược điểm này giá trị ngưỡng bị đặt cố định cho tất cả vị trí trên bản đồ. Do đó về mặt chủ quan sẽ gây nhẫm lần ở các điểm ảnh mà giá trị ngưỡng cần thấp hoặc cao hơn và mất thời gian để tìm ra một ngưỡng phù hợp cho bài toán.
2. Differentiable binarization
Để giải quyết vấn đề của phương pháp Standard binarization, bài báo đề xuất phương pháp Differentiable binarization. Do phương pháp mới này có thể thực hiện tính toán giá trị đạo hàm nên có thể tích hợp trực tiếp vào mô hình học sâu.
trong đó là bản đồ nhị phân, T bản đồ ngưỡng động được học từ mô hình, k là một chỉ số khuyếch đại. Công thức \ref{eq:differ_binarization} giống với công thức standard_binarization nhưng có thể đạo hàm do đó có thể tối ưu cùng với mô hình. Phương pháp này kết hợp sử dụng ngưỡng động được trình bày phần tiếp theo không chỉ giúp phát hiện đối tượng so với nền mà còn giúp tách các vùng chữ bị ghép liền vào với nhau.
3. Ngưỡng động (Adaptive threshold)
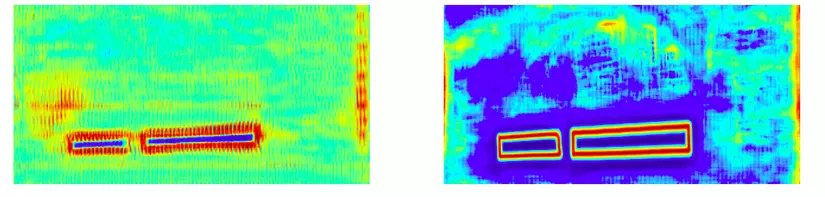 Ảnh 3: Bản đồ ngưỡng động
Ảnh 3: Bản đồ ngưỡng động
4. Hàm mất mát
Hàm mất mát tác giả sử dụng là tổng có trọng số của ba hàm mất mát cho bản đồ xác suất , bản độ nhị phân và bản đồ ngưỡng :
trong đó lần lượt là trọng số ưu tiên của hàm mất mát cho bản đồ xác suất và bản đồ ngưỡng.
Do số lượng các điểm ảnh không phải chữ thường chiếm rất nhiều trong một ảnh nên để giảm hiện tượng mất cân bằng giữa các lớp, bài báo đề xuất sử dụng hàm mất mát binary cross-entropy (BCE) đồng thời hạn chế số lượng đối tượng không phải chữ được đưa vào hàm mất mát. Tập hợp các đối tượng không phải chữ được cho vào mất mát được gọi là :
Hàm mất mát cho bản đồ ngưỡng được tính bằng tổng khoảng cách L1 giữa nhãn và dự đoán.
trong đó là tập hợp các vị trí bên trong vùng chữ, là nhãn cho bản đồ ngưỡng.
III. Tổng kết
Nhờ các thiết kế bên trên, mô hình đã đạt kết quả tốt trên nhiều bộ dữ liệu trong khi tốc độ suy luận được cải thiện rất nhiều so với phương pháp trước đó như CRAFT, ... Gần đây đã xuất hiện một phiên bản cải thiện của DB là bài báo DB++. Trong bài viblo tiếp theo, tôi sẽ giới thiệu mọi người chi tiết thêm về bài báo này. Cảm ơn mọi người đã đọc bài viết.
Tài liệu tham khảo
All rights reserved
