
[Paper Explain]:Spatial Dual-Modality Graph Reasoning - Bài toán trích xuất thông tin với mô hình Graph
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu chung
Trích xuất thông tin chính từ tài liệu văn bản như CV, hóa đơn, biên lai, ... là điều tối quan trọng trong tự động hóa văn phòng. Thông thường các phương pháp tiếp cận đều chỉ tập trung vào một số template cố định nên không thể tổng quát hóa tốt cho các tài liệu mà không theo 1 định dạng cho trước. Khi gặp các template chưa từng xuất hiện thì kết quả trích xuất sẽ rất tệ. Trong paper này, bài toán được đưa ra sẽ thách thức hơn, yêu cầu đăt ra sẽ là trích xuất thông tin từ các tài liệu văn bản nhưng tập train và tập test sẽ khác nhau về bố cục và định dạng.
Thực tế cũng đã có vài model trước đây xử lý bài toán như này , ví dụ như model Named Entity Recognition (NER) trong paper CloudSan.
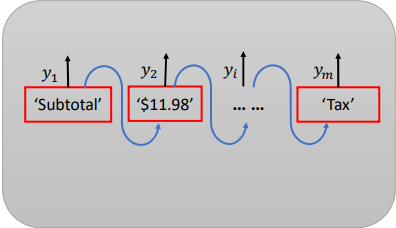
Trong bài báo này, tác giả đề xuất một model Spatial Dual-Modality Graph Reasoning (SDMGR) để trích xuất thông tin chính từ tài liệu không có cấu trúc. Ý tưởng là sử dụng dữ liệu cả về mặt hình ảnh và về text; các nút trong đồ thị được mã hóa cả các đặc trưng trực quan và đặc trưng văn bản về các vùng text được phát hiện; các cạnh của chúng đại diện cho không gian quan hệ giữa các vùng văn bản lân cận.
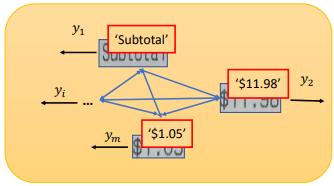
Để đánh giá được độ hiệu quả của model so với các model khác, chung ta cần 1 bộ dữ liệu đủ tốt và có sự khác nhau về tập train và test nhưng hiện nay các model đều sử dụng những bộ dữ liệu private hoặc có public thì lại quy mô khá nhỏ và ít trường, ví dụ như bộ SROIE. Vì vấn đề này, 1 bộ dữ liệu mới được xây dựng cho mục đích của bài toán. Bộ dữ liệu mới WildReceipt bao gồm 25 trường , với 50000 text boxes, lớn hơn khoảng 2 lần so với bộ SROIE.
Tổng quát hóa bài báo
Bài báo sẽ bao gồm 3 đóng góp chính, đó là:
- Đề xuất 1 model mới spatial dual-modality graph reasoning (viết tắt là SDMG-R), mô hình vẫn dựa trên mô hình graph nhưng sử dụng đồng thời cả đặc trưng hỉnh ảnh và đặc trưng văn bản.
- Xây dựng 1 bộ dự liệu tiêu chuẩn mới WildReceipt, số lượng dữ liệu lớn gấp đôi các bộ dữ liệu tương tự. Mục tiêu của nó là đánh giá quá trình trích xuất thông tin với bài toán có bộ dữ liệu training và bộ dữ liệu test khác nhau tương đối về template, điều này rất ít xuất hiện trong các bộ dữ liệu trước đó.
- So sánh tính hiệu quả của model trên 2 bộ dữ liệu tiêu chuẩn là SROIE và WildReceipt.
Triển khai bài toán
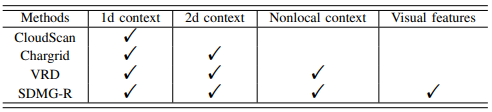
Key information extraction. Khá nhiều paper đã sử dụng phương pháp template matching hay rule-base nhưng thực sự không hiệu quả với các tài liệu có định dạng mới. Sau đó CloudScan đã lập mô hình trích xuất thông tin NER nhưng chỉ sử dụng không gian 1 chiều, tổng hợp văn bản dưới dạng chuỗi. Chargrid đã encode dưới dạng 2 chiều nhưng không thể sử dụng nonlocal khi mà chỉ khai thác được những vùng text ngắn. Gần đây, VRD (Visually Rich Documents) đã encode ngữ cảnh 2 chiều của các đọan văn bản, kết hợp thêm encode dữ liệu dạng text 1 cách đầy đủ. Khác với VRD, mô hình SDMG-R được đề xuất ngoài dữ liệu về text còn kết hợp thêm các đặc trưng về hình ảnh. Đây là mô hình đầu tiên sử dụng cả đặc trưng văn bản lẫn đặc trưng về hình ảnh. Đến hiện nay đã có thêm 1 vài mô hình sử dụng cả 2 đặc trưng, ví dụ như LayoutLM.
Mạng Graph. thời gian gần đây, mạng Graph là 1 chủ đề mới được mọi người sử dụng khá nhiều. Một số lượng khá đáng kể mô hình đã được nghiên cứu trong các lĩnh vực như nhận dạng hành động con người, phân tích liên kết mạng xã hội, nhận dạng hình ảnh đa nhãn, trả lời câu hỏi tự động, truy xuất dữ liệu, ... Những công việc này tạo ra các đồ thị mô hình hóa các mối quan hệ giữa các đối tượng hoặc vùng hình ảnh. Ngược lại, tác giả việc sử dụng đồ thị để thể hiện quan hệ không gian giữa các text box và áp dụng nó vào lĩnh vực khai thác thông tin quan trọng. Đối với mỗi text box được phát hiện, nó có thể tự động khai thác cấu trúc bố cục hữu ích trong các khu vực lân cận.
Trong bài viết này, mình sẽ không đề cập sâu vào mạng Graph, mọi người có thể tìm hiểu thêm chi tiết ở trong bài viết này của anh Phạm Huy Hoàng: https://viblo.asia/p/deep-learning-graph-neural-network-a-literature-review-and-applications-6J3ZgP0qlmB
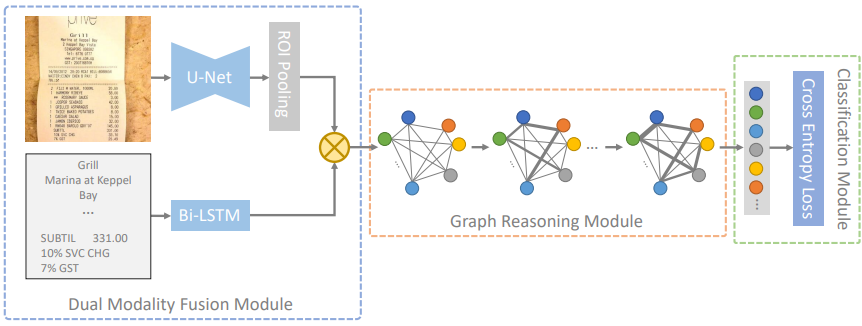
Như hình ảnh trên, các đặc trưng trực quan được trích xuất qua U-Net và ROIPooling trong khi các đặc trưng văn bản được trích xuất qua Bi-LSTM. Sau đó, Các đặc trưng được kết hợp bởi tích Kronecker, điều này được thực hiện bên trong Mô-đun kết hợp không gian kép trước khi được đưa vào Mô-đun Graph, nơi các đặc trưng của nút được tinh chỉnh và tổng hợp, đồng thời trọng số cạnh được học động. Các đặc trưng của nút cuối cùng được phân loại nhãn trong mô-đun phân loại.
Đầu vào sẽ là hình ảnh tài liệu I có kích thước HxW, cùng với các vùng chữ được nhận diện , với trong đó và lần lượt là tọa độ góc trên bên trái, chiều cao, chiều rộng và chuỗi văn bản được nhận diện; mục đích của bài toán là phân loại từng vùng văn bản được nhận diện thành một trong tập hợp danh mục được định nghĩa từ trước Y. Việc trích xuất thông tin văn bản được coi như là bài phân loại nút trong đồ thị sử dụng các đặc trưng về không gian kép, cụ thể là đặc trưng hình ảnh và đặc trưng văn bản. Mô hình sẽ bao gồm mô đun tích hợp không gian kép (Dual Modality Fusion Module), mô đun suy luận đồ thị (Graph Reasoning Module) và mô đun phân loại, như ở trong hình 3.
(*) Xét ma trận và ma trận . Tích Kronecker của hai ma trận A và B, được kí hiệu là A B được xác định như ma trận sau:
A. Mô đun kết hợp không gian kép
Cho một hình ảnh với các vùng văn bản , trích xuất lấy vector đặc trưng đại diện cho từng vùng văn bản thông qua mô-đun tổng hợp kép.
Đặc trưng hình ảnh thu được từ thông qua lớp RoI Pooling ( Region of Interest - tổng hợp vùng quan tâm ) với các vùng box trên feature maps đầu ra của lớp cuối cùng của 1 trình trích xuất CNN. Trong bài báo, tác giả sử dụng U-net nhưng mọi người hoàn toàn có thể thay thế bằng model khác phù hợp hơn cho bài toán của mình.
Kế tới là đặc trưng về văn bản từ thông qua layer Bi-LSTM. Mỗi kí tự của chuỗi sẽ được biểu diễn thành 1 one-hot vector với kích thước là số kí tự trong danh sách được định nghĩa. Vector sau đó được chiếu vào không gian nhỏ hơn rồi đưa tuần tự vào mô-đun Bi-LSTM để thu được kết quả biểu diễn văn bản ứng với mỗi vùng văn bản .
trong đó là ma trận hình chiếu của các vector . Đặc trưng hình ảnh và đặc trưng văn bản sẽ được kết hợp với nhau bằng tích Kronecker như sau:
là tích Kronecker. là một phép biến đổi tuyến tính có thể học được và là tính năng sau cùng thu được. Tuy nhiên số lượng các tham số phát triển tuyến tính với kích thước của các đặc trưng trực quan,của những đặc trưng văn bản và của những biến số sinh ra khi tích hợp dẫn đến nặng bộ nhớ và chi phí tính toán. Để giảm độ phức tạp của bộ nhớ và tính toán, trước tiên tác giả định dang lại phương trình thành dạng tensor:
trong đó là 1 tensor định dạng lại , là mode-j product, là chuyển vị của x. Tiếp đó, tác giả giới thiệu phương pháp phân rã block để phân tách T như sau:
(*) mode-j product là phép nhân mà trong đó tất cả các chiều sẽ đuọc khóa cứng và chỉ thực hiện trên chiều thứ j.
ở đó là tích chéo theo block với R là số block và là kích thước của block, và . Vì được chia nhỏ thành các block nên và R được đặt là 1 hằng số khá nhỏ. Do đó, số tham số tensor phân rã trong công thức ban đầu là rất lớn được thu về nhỏ hơn tenxơ ban đầu trong phương trình
Ngoài ra, tác giả cũng thử nghiệm với 2 phương pháp khác mà mọi người có thể cân nhắc sử dụng:
LinearSum. các đặc trưng trực quan và đặc trưng văn bản được chiếu tuyến tính vào 1 không gian chung thông qua 1 MLP 3 lớp và sau đó thêm phần tử phù hợp để hợp nhất thành .
ConcatMLP. các đặc trưng trực quan và đặc trưng văn bản được concat với nhau và theo sau đó là 1 MLP 3 lớp.
B. Mô đun Graph
Thực hiện mô hình hóa các hình ảnh tài liệu dưới dạng đồ thị trong đó = {} với là vector đặc trưng ứng với mỗi node và ={} với là cạnh liên kết giữa node và node . Encode mỗi quan hệ giữa và thông qua một cơ chế chú ý động. Đầu tiên cần xác định quan hệ không gian giữa node và node như sau:
Quan hệ vị trí không gian giữa các node:
Quan hệ tỷ lệ giữa các node:
Sau cùng tổng hợp các mỗi quan hệ lại:
trong đó và là khoảng cách nằm ngang và dọc một giữa hai box chứa văn bản và tương ứng. d là một hằng số chuẩn hóa, là phép nối 2 giá trị lại vs nhau. Mối quan hệ vị trí không gian giữa hai box văn bản đóng một vai trò chủ chốt trong việc khai thác thông tin quan trọng. encode khoảng cách vị trí không gian tương đối giữa node và node . Số hạng đầu tiên và hai số hạng sau trong Công thức tính quan hệ tỷ lệ lần lượt encode tỷ lệ khung hình của và thông tin hình dạng tương đối tương ứng.
2 mối quan hệ trên có tác dụng scale lại các box để có độ tương đồng về tỷ lệ, giúp model dễ học hơn.
Tiến hành embeding thông tin về quan hệ giữa các node thành trọng số cạnh như sau:
trong đó là một phép biến đổi tuyến tính embed thông tin quan hệ không gian thành một biểu diễn -chiều. là phương thức chuẩn hóa , được đưa vào nhằm mục địch ổn định quá trình training. đại diện cho cạnh kết nối biểu thị quan hệ giữa và . M là 1 MLP biến đổi sang vô hướng.
Graph reasoning. Tinh chỉnh lặp lại các đặc trưng {} của đồ thị L lần:
trong đó, biểu thị đặc trưng của node thứ i tại bước thứ l. là hàm biến đổi tuyến tính tại bước l. đại diện cho hợp nhất liên kết của và tại bước l như ở công thức (1). là hàm RELU phi tuyễn. là trọng số cạnh chuẩn hóa giữa nút i và j tại bước l, theo công thức:
trọng số của đồ thị G sẽ thay đổi động trong quá trình suy luận từ bước này sang bước khác.
Vì được tổng hợp từ đặc trưng của cạnh và cả nút nên cần phải được chuẩn hóa qua trọng số sau đó mới mới được tổng hợp vào đặc trưng qua các vòng lặp .
C. Hàm loss
Đầu ra của mô đun suy luận sẽ được đưa vào mô đun phân loại để đánh nhãn cho từng vùng văn bản theo danh mục ban đầu. Hàm loss được tác giả định nghĩa là:
trong đó là danh mục ground truth, CE là hàm cross entropy.
Tuy nhiên trong trường hợp số lượng dữ liệu cho từng classs được phân bổ không đều, dẫn tới hiện tượng Imbalanced , để giải quyết vấn đề này tôi đề xuất sử dụng hàm loss là weighted cross entropy thay vì cross entropy. Lúc này các class sẽ được đánh trọng số để cân bằng lại sự chênh lệch về dữ liệu giúp cho việc training được hiệu quả hơn.
Bộ dữ liệu WildReceipt
Bộ dữ liệu sẽ gồm dữ liệu dạng biên lai như ở bộ SROIE vì những lí do: (1) Các biên lai là ẩn danh, phú hợp làm bộ dữ liệu public, không gây rò rỉ thông tin; (2) hóa đơn mỗi công ty, cửa hàng là khác nhau nên phù hợp để đánh giá bài toán; (3) các biên lai dễ dàng thu thâp vì ở đâu cũng dùng; (4) thông tin từ hóa đơn có thể dùng cho nhiều mục đích thiết yếu như sổ sách thanh toán, hoàn trả phí, ...
Quá trình xây dựng bộ dữ liệu:
- Thu thập dữ liệu: Tìm kiếm hình ảnh trên các công cụ tìm kiếm theo từ khóa. Từ đó thu thập được 4300 hình ảnh.
- Làm sạch dữ liệu: Xóa những hình ảnh có nhiều hóa đơn, không phải hóa đơn, những hình bị mờ , không đủ hoặc không phải tiếng anh.
- Gán nhãn dữ liệu: Đầu tiên là chia box cho từng text sau đó gán nhãn cho từng box, tổng số là 25 trường.
![image.png]() Hình 4. Dữ liệu mẫu trên tập WildReceipt. Bên trái là clean-data đã được gán nhãn, bên phải là dữ liệu bị loại bỏ.
Sau cùng thu được bộ dữ liệu bao gồm 1740 hình ảnh với 68975 text boxes. Trung bình mỗi hình ảnh có khoảng 39 box, trong đó có 25 danh mục thông tin chính gồm 12 là từ khóa, 12 là các giá trị tương ứng, 1 là các giá trị khác. WildReceipt lớn gấp 2- lần so với SROIE [7] về số ảnh và số danh mục. Bên cạnh đó, nó chứa các danh mục thông tin chính chi tiết, tất cả đều liên quan đến số liệu nên sẽ khó phân biết với nhau nếu chỉ dùng mỗi dữ liệu bản mà bỏ qua thông tin hình ảnh.
Hình 4. Dữ liệu mẫu trên tập WildReceipt. Bên trái là clean-data đã được gán nhãn, bên phải là dữ liệu bị loại bỏ.
Sau cùng thu được bộ dữ liệu bao gồm 1740 hình ảnh với 68975 text boxes. Trung bình mỗi hình ảnh có khoảng 39 box, trong đó có 25 danh mục thông tin chính gồm 12 là từ khóa, 12 là các giá trị tương ứng, 1 là các giá trị khác. WildReceipt lớn gấp 2- lần so với SROIE [7] về số ảnh và số danh mục. Bên cạnh đó, nó chứa các danh mục thông tin chính chi tiết, tất cả đều liên quan đến số liệu nên sẽ khó phân biết với nhau nếu chỉ dùng mỗi dữ liệu bản mà bỏ qua thông tin hình ảnh.

Lấy mẫu ngẫu nhiên 1268 và 472 hình ảnh để làm tập train.Trong quá trình lấy mẫu, đẩm bảo bộ train và test có sự khác nhau về định dạng. Do đó, WildReceipt phù hợp để đánh giá mô hình trích xúâ thông từ tài liệu văn bản mà không biết trước định dạng tập mẫu. Hiệu suất trên WildReceipt được đánh giá bằng điểm F1
Thực nghiệm
Tiến hành thiết lập các giá trị đầu vào cho mô hình SDMG-R như , , , , ... So sánh SDMG_R với các phương tiếp cận bài toán tương tự mới ra gần đây như :
- Chargrid : Mô dình hóa tài liệu dưới dạng 2 chiều và đưa vào 1 mạng CNN để dự đoán.
- Chargrid-UNet: Sử dụng mạng U-net làm backbone cho Chatgrid trong khi vẫn giữ nguyên những thứ khác.
- VRD: Nó mô hình hóa các tài liệu với các text box dưới dạng đồ thị, sau đó được đưa vào một CRF. Kết quả thử nghiệm được thể hiện trong bảng bên dưới:

Có thể thấy rằng SDMG-R vượt trội hơn tất cả các model còn lại. Cụ thể, SDMGR đạt F1-score tính trung bình trên 12 loại giá trị trên WildReceipt lớn hơn 11,8%, 9,7% và 3% so với Chargrid, Chargerid-UNet và VRD tương ứng. Hơn nữa, SDMG-R đạt F1-score cao nhất cho 10 trong số 12 hạng mục. SDMG-R vượt trội hơn rất nhiều so với Chargerid-UNet,đó là do sự liên kết giữa các text xa nhau được học thông qua đồ thị.
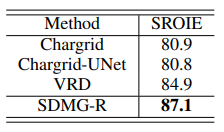
Tác giả cũng so sánh phương pháp của mình với các phương pháp khác trên bộ dữ liệu SROIE. Tương tự như WildReceipt, rõ ràng SDMG-R hoạt động tốt hơn các model khác.
Tiếp sau đó họ tiến hành cắt bỏ chi tiết để đánh giá độ hiệu quả của từng phần trong SDMG-R:
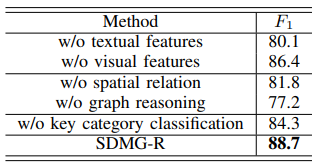
Effects of visual and textual features. SDMGR giảm 8,6% trên WildReceipt về F1-score khi không có tính năng văn bản. Tương tự, nó giảm 2,3% khi không có các tính năng trực quan. Người ta đã chỉ ra rằng cả các đặc điểm văn bản và hình ảnh, đặc biệt là các đặc điểm văn bản, đều đóng góp rất nhiều vào việc khai thác thông tin chính.
Effects of spatial relation. SDMG-R giảm F1-score xuống 81,8% trên WildReceipt.Quan sát thấy rằng các mối quan hệ không gian giữa hai text box đóng một vai trò quan trọng trong việc trích xuất thông tin chính và rõ ràng có thể tăng hiệu suất của model.
Effects of graph reasoning. Nếu không có Graph, tác giả phải trực tiếp tiến hành phân loại các tính năng hình ảnh và văn bản hợp nhất, dẫn đến sự suy giảm hiệu suất lớn. Cụ thể, điểm số F1 tuyệt đối giảm 11,5% trên WildReceipt.
Kết luận
Có thể thấy model SDMG-R được đề xuất trong paper là 1 hướng tiếp cận mới nhưng lại có độ hiệu quả tương đối ấn tượng. Việc sử dụng cả 2 loại đặc trưng về hình ảnh và văn bản rồi kết hợp chúng qua tích Krobecker là một phương pháp rất hay. Model này có thể được vận dụng vào giải quyết một số bài toán đặc thù một cách hiệu quả, rát đáng để mọi người áp dụng. Bài biết này trình bày sơ lược về mô hình Spatial Dual-Modality Graph Reasoning (SDMG-R) , cảm ơn các bạn đã đọc bài, nếu có góp ý cho bài viết, các bạn vui lòng để ở phần comment.
All rights reserved
