
SQL Query Antipatterns and Solution (Part 2)
Bài đăng này đã không được cập nhật trong 3 năm
Tiếp tục Seri về SQL Antipatterns, ở phần 1 mình đã giới thiệu với các bạn khái niệm về Antipatterns và một số Antipatterns đơn giản. Trong phần này chúng ta sẽ tiếp tục đi sâu vào những vấn đề phức tạp hơn. Cùng bắt đầu nào.
Một số SQL Antipatterns phổ biến (tiếp)
5. Tối ưu các công cụ tìm kiếm
Đặt vấn đề
Khi bạn muốn thực hiện tìm kiếm toàn văn bản, bạn sử dụng các toán tử khớp mẫu (ví dụ: LIKE, REGEXP).
LIKE hỗ trợ ký tự %. Sử dụng ký tự này trước hoặc sau một từ khóa để tìm kiếm những hàng liên quan đến từ đó. Ký tự đứng trước, toán tử sẽ khớp với bất kỳ văn bản nào đứng trước từ đó và ngược lại nó sẽ khớp với bất kỳ văn bản nào theo sau từ đó.
Select * From Bugs Where description Like '%crash%'
Còn với REGEXP thì không cần kí tự hỗ trợ nào, chúng ta chỉ cần gán thẳng từ cần tìm vào
SELECT * FROM Bugs WHERE description REGEXP 'crash'
Nhược điểm quan trọng nhất của các toán tử so khớp mẫu là chúng có hiệu năng kém. Nó phải quét mọi hàng trong bảng. Vì vậy so sánh một mẫu với một cột chuỗi là một hoạt động khá tốn kém, tổng chi phí quét bảng cho tìm kiếm này là rất cao. Một vấn đề thứ hai của việc so khớp mẫu đơn giản bằng cách sử dụng LIKE hoặcREGEXPy là nó có thể tìm thấy các kết quả khớp ngoài ý muốn.
Giải pháp
Tốt nhất là sử dụng công nghệ công cụ tìm kiếm chuyên biệt, thay vì SQL. Một giải pháp thay thế khác là giảm chi phí tìm kiếm định kỳ bằng cách lưu kết quả. Bạn không nhất thiết phải sử dụng SQL để giải quyết mọi vấn đề.
Mỗi nhà cung cấp đều có giải pháp cho việc này. Nguyên lý chung sẽ là thêm Full-text-search cho các cột văn bản rồi áp dụng công cụ riêng của từ nhà cung cấp:
-
MySQL
ALTER TABLE Bugs ADD FULLTEXT INDEX bugfts (summary, description) SELECT * FROM Bugs WHERE MATCH(summary, description) AGAINST ('crash') -
Oracle
CREATE INDEX BugsText ON Bugs(summary) INDEXTYPE IS CTSSYS.CONTEXT; SELECT * FROM Bugs WHERE CONTAINS(summary, 'crash') > 0 -
Microsoft SQL Server
EXEC sp_fulltext_catalog 'BugsCatalog', 'create' EXEC sp_fulltext_table 'Bugs', 'create', 'BugsCatalog', 'bug_id' SELECT * FROM Bugs WHERE CONTAINS(summary, '"crash"') -
PostgreSQL
CREATE TABLE Bugs (bug_id SERIAL PRIMARY KEY, summary VARCHAR(80), description TEXT, ts_bugtext TSVECTOR) CREATE INDEX bugs_ts ON Bugs USING GIN(ts_bugtext) SELECT * FROM Bugs WHERE ts_bugtext @@ to_tsquery('crash') -
SQLite
CREATE VIRTUAL TABLE BugsText USING fts3(summary, description) INSERT INTO BugsText (docid, summary, description) SELECT b.* FROM BugsText t JOIN Bugs b ON (t.docid = b.bug_id) WHERE BugsText MATCH 'crash';
Ngoài ra chúng ta có thể sử dụng công cụ của bên thứ 3 như Sphinx Search, Apache Lucene.
6. Thay đổi thói quen sử dụng cột ẩn
Đặt vấn đề
Hãy bắt đầu với một ví dụ trước:
Một lập trình viên chạy câu lệnh sau:
SELECT * FROM Books b JOIN Authors a ON (b.author_id = a.author_id)
Truy vấn này trả về tất cả tên sách là null. Lạ lùng hơn nữa, khi anh ta chạy một truy vấn khác mà không Join bảng Authors, kết quả lại bao gồm các tên sách thật như mong đợi. Vậy lí do là gì? Sau khi tìm hiểu, anh ta nhận ra là cả 2 bảng đều có cột title và cột title bên author đa số là null. Và đây là cách khắc phục:
SELECT b.title, a.title AS salutation
FROM Books b JOIN Authors a ON (b.author_id = a.author_id)
Quay trở lại vấn đề của antipattern này, rất nhiều người đang dùng SQL đều sẽ sử dụng các lệnh tắt: Select * thay vì Select + tên cột. Điều này giúp giảm thời gian nhập code, đoạn truy vấn nhìn gọn nhẹ hơn.
Tuy nhiên điều này sẽ tạo ra một số mối nguy hiểm:
Giả sử bạn có 1 câu lệnh Insert
INSERT INTO Accounts VALUES (DEFAULT, 'bkarwin', 'Bill', 'Karwin', 'bill@example.com', SHA2('xyzzy'), NULL, 49.95)
Bình thường câu lệnh vẫn hoạt động trơn tru nhưng rồi 1 thời gian sau, có ai đó add thêm 1 cột mới vào trong bảng. Lúc này câu lệnh sẽ báo lỗi vì bạn chỉ đưa vào list là 10 giá trị thay vì 11 như mong đợi.
Nhưng may mắn trong trường hợp này chúng ta còn phát hiện ra lỗi để sửa chữa. Hãy đến 1 ví dụ khác:
<?php
$stmt = $pdo->query("SELECT * FROM Bugs WHERE bug_id = 1234");
$row = $stmt->fetch();
$hours = $row[10];
Bạn có 1 đoạn lệnh như trên để lấy ra giá trị về thời gian. Rồi sau đó, cũng có 1 người khác thêm 1 cột vào bảng, lúc này cột 10 không còn là cột hour nhưng không có lỗi được báo về, giá trị vẫn được lấy ra và truyền xuống bước khác dẫn đến 1 tình huống sai theo dây chuyền khiến bạn phải mò từng đoạn code để kiểm tra.
Ngoài ra, việc sự dụng cột ẩn, Select * có thể gây hại cho hiệu suất và khả năng mở rộng. Truy vấn của bạn tìm nạp càng nhiều cột thì càng có nhiều dữ liệu phải truyền qua mạng giữa ứng dụng của bạn và máy chủ cơ sở dữ liệu khiến gia tăng chi phí ẩn không cần thiết.
Giải pháp
Trong trường hợp này chỉ có 1 yêu cầu duy nhất là các bạn cần thay đổi thói quen sử dụng cột ẩn, đặt tên cột rõ ràng giữa các bảng, khai báo cụ thể tên cột trong các phần truy vấn. Tiết kiệm chút thời gian viết code nhưng có thể sẽ mất rất nhiều thời gian để khắc phục về sau.
Khi cải thiện được điều này, lợi ích bạn thu về được sẽ là:
- Nếu một cột đã được thay đổi vị trí trong bảng, nó sẽ không thay đổi vị trí trong một kết quả truy vấn.
- Nếu một cột đã được thêm vào bảng, cột đó sẽ không xuất hiện trong kết quả truy vấn.
- Nếu một cột đã bị xóa khỏi bảng, truy vấn của bạn sẽ phát sinh lỗi, nhưng đó là một lỗi tốt vì bạn được dẫn trực tiếp đến đoạn code mà bạn cần sửa, thay vì phải tìm kiếm nguyên nhân gốc rễ.
7. Truy vấn spaghetti
Đặt vấn đề
Bạn có thể hoàn thành rất nhiều việc trong một truy vấn hoặc câu lệnh. Nhưng điều đó không có nghĩa là bắt buộc khi tiếp cận mọi nhiệm vụ với giả định rằng nó phải được thực hiện trong một dòng lệnh. Một hậu quả ngoài ý muốn phổ biến của việc tạo ra tất cả kết quả của bạn trong một truy vấn là tích Đề các. Điều này xảy ra khi hai trong số các bảng trong truy vấn không có điều kiện hạn chế mối quan hệ của chúng. Nếu không có hạn chế như vậy, phép nối của hai bảng sẽ ghép nối từng hàng trong bảng đầu tiên với mọi hàng trong bảng khác. Mỗi cặp như vậy sẽ trở thành một hàng của tập hợp kết quả và bạn sẽ có nhiều hàng hơn bạn mong đợi.
Cùng xem một ví dụ sau:
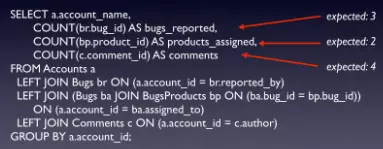
Chúng ta viết 1 câu lệnh truy vấn để thực hiện 3 nhiệm vụ:
- Đếm số bug đã được báo cáo
- Đếm số sản phẩm
- Đếm số comments
Và đây là kết quả thu được:

Giải pháp
Tách một truy vấn spaghetti phức tạp thành nhiều truy vấn đơn giản hơn.
Như ở ví dụ trên, với 3 nhiệm vụ chúng ta có thể tách riêng thành 3 truy vấn để đảm bảo độ chính xác

Tuy phần truy vấn sẽ dài hơn đôi chút nhưng có thể giám sát dễ dàng và dễ dàng sửa nếu gặp lỗi. Trong trường hợp thực sự cần 3 kết quả trong cùng 1 bảng chúng ta có thể sử dụng thêm hàm UNION và UNION ALL
Một ví dụ về cách sử dụng:
(SELECT p.product_id, f.status, COUNT(f.bug_id) AS bug_count
FROM BugsProducts p
LEFT OUTER JOIN Bugs f ON (p.bug_id = f.bug_id AND f.status = 'FIXED')
WHERE p.product_id = 1
GROUP BY p.product_id, f.status)
UNION ALL
(SELECT p.product_id, o.status, COUNT(o.bug_id) AS bug_count
FROM BugsProducts p
LEFT OUTER JOIN Bugs o ON (p.bug_id = o.bug_id AND o.status = 'OPEN')
WHERE p.product_id = 1
GROUP BY p.product_id, o.status)
ORDER BY bug_count;
Một số phương pháp để tránh bị truy vấn spaghetti:
-
Giảm số lần Join: Quá nhiều Join là dấu hiệu của các truy vấn spaghetti phức tạp. Cân nhắc chia nhỏ truy vấn phức tạp thành nhiều truy vấn đơn giản hơn và giảm số lần Join.
-
Loại bỏ các điều kiện DISTINCT không cần thiết: Quá nhiều điều kiện DISTINCT là dấu hiệu của các truy vấn spaghetti phức tạp. Cân nhắc chia nhỏ truy vấn phức tạp thành nhiều truy vấn đơn giản hơn và giảm số lượng điều kiện DISTINCT. Có thể điều kiện DISTINCT không có tác dụng nếu cột khóa chính là một phần của tập hợp cột kết quả.
-
Cân nhắc loại bỏ mệnh đề HAVING: Viết lại mệnh đề HAVING của truy vấn bằng các chỉ mục khác trong quá trình xử lý truy vấn.
Ví dụ
SELECT s.cust_id,count(s.cust_id) FROM SH.sales s GROUP BY s.cust_id HAVING s.cust_id != '1660' AND s.cust_id != '2'có thể được viết lại như sau:
SELECT s.cust_id,count(cust_id) FROM SH.sales s WHERE s.cust_id != '1660' AND s.cust_id !='2' GROUP BY s.cust_id -
Bỏ lồng các truy vấn phụ: Viết lại các truy vấn lồng nhau dưới dạng joins thường dẫn đến thực thi hiệu quả hơn và tối ưu hóa hiệu quả hơn.
Ví dụ
SELECT * FROM SH.products p WHERE p.prod_id = (SELECT s.prod_id FROM SH.sales s WHERE s.cust_id = 100996 AND s.quantity_sold = 1 )có thể được viết lại như sau:
SELECT p.* FROM SH.products p, sales s WHERE p.prod_id = s.prod_id AND s.cust_id = 100996 AND s.quantity_sold = 1 -
Cân nhắc sử dụng một IN khi truy vấn thay vì OR
Ví dụ
SELECT s.* FROM SH.sales s WHERE s.prod_id = 14 OR s.prod_id = 17có thể được viết lại như sau:SELECT s.* FROM SH.sales s WHERE s.prod_id IN (14, 17) -
Cân nhắc sử dụng UNION ALL thay vì UNION: Không giống như UNION loại bỏ các bản sao, UNION ALL cho phép các bộ dữ liệu trùng lặp. Nếu bạn không quan tâm đến các bộ dữ liệu trùng lặp, thì sử dụng UNION ALL sẽ là một tùy chọn nhanh hơn.
-
Cân nhắc sử dụng truy vấn phụ với EXISTS thay vì DISTINCT: Từ khóa DISTINCT loại bỏ các bản sao sau khi sắp xếp các bộ dữ liệu. Thay vào đó, hãy cân nhắc sử dụng truy vấn phụ với từ khóa EXISTS, bạn có thể tránh phải trả lại toàn bộ bảng.
Ví dụ
SELECT DISTINCT c.country_id, c.country_name FROM SH.countries c, SH.customers e WHERE e.country_id = c.country_idcó thể được viết lại thành:
SELECT c.country_id, c.country_name FROM SH.countries c WHERE EXISTS (SELECT 'X' FROM SH.customers e WHERE e.country_id = c.country_id)
Kết luận
Qua seri này mình đã trình bày sơ lược về các Antipatterns trong truy vấn SQL và cách tối ưu chúng. Hi vọng seri này sẽ giúp mọi người tránh được những sai lầm không đáng có. Rất mong nhận được góp ý từ mọi người. Cảm ơn vì đã dành thời gian đọc bài viết ^^.
Reference
https://www.r-5.org/files/books/computers/languages/sql/style/Bill_Karwin-SQL_Antipatterns-EN.pdf
All rights reserved
