Paper Reading | ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Bài đăng này đã không được cập nhật trong 3 năm
1. Động lực
Các bài toán Computer Vision ngày càng đạt hiệu suất cao nhờ sự phát triển về kiến trúc mô hình và các framework hiện đại. Tuy được thiết kế theo hướng supervised learning trên tập ImageNet đã được gán nhãn nhưng các model này vẫn có tiềm năng cải thiện hơn nữa theo cách tiếp cận self-supervised learning ví dụ như Masked autoencoders (MAE). Tuy nhiên, nhóm tác giả nhận thấy là kết hợp 2 cách tiếp cận này làm cho hiệu suất của mô hình giảm về mức trung bình. Một vấn đề là MAE thiết kế bộ encoder - decoder được tối ưu cụ thể cho khả năng xử lý tuần tự của Transformer, cho phép bộ encoder tập trung vào các patch và do đó giảm chi phí pretrained. Thiết kế này không tương thích với ConvNet sử dụng các dense sliding window. Ngoài ra, nếu mối quan hệ giữa kiến trúc và training objective không được xem xét thì không rõ liệu có thể đạt được hiệu suất tối ưu hay không. Trên thực tế, nghiên cứu trước đây đã chỉ ra rằng việc train ConvNet bằng cách tiếp cận mask-based self-supervised learning có thể khó khăn và bằng thực nghiệm cho thấy rằng Transformer và ConvNet có các hành vi feature learning khác nhau có thể ảnh hưởng đến chất lượng feature representation.
2. Đóng góp
Trong bài báo, nhóm tác giả đề xuất một fully convolutional masked autoencoder framework và một layer mới Global Response Normalization (GRN) được thêm vào cấu trúc ConvNeXt nhằm tăng cường tính cạnh tranh feature giữa các kênh (inter-channel feature competition). Mục tiêu là thực hiện cách tiếp cận mask-based self-supervised learning cho mô hình ConvNext mà vẫn đạt được kết quả tương đương như sử dụng mô hình Transformers trên các recognition benchmark khác nhau, bao gồm ImageNet classification, COCO detection, and ADE20K segmentation.
3. Phương pháp
3.1. Fully Convolutional Masked Autoencoder
Cách tiếp cận rất đơn giản giống như các masked model trước đây. Đó là mask ngẫu nhiên ảnh đầu vào với một tần suất lớn và để model dự đoán phần còn thiếu dựa trên context còn lại.
Masking. Tỉ lệ masking là 60%. Vì mô hình convolutional có thiết kế phân cấp, trong đó các feature được lấy mẫu ở các stage khác nhau, masking được tạo ở stage cuối và được upsample theo cách đệ quy cho đến khi đạt độ phân giải tốt nhất.
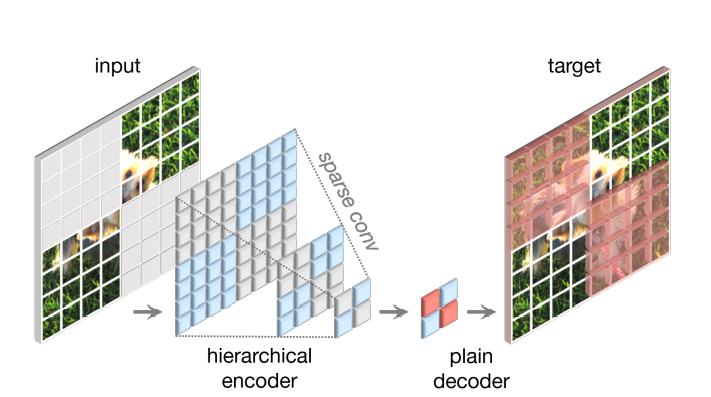
Thiết kế encoder. Nhóm tác giả sử dụng ConvNeXt làm encoder. Để làm cho masked image modeling hiệu quả thì cần phải ngăn không cho model "copy paste" thông tin từ các vùng bị che (masked regions). Việc này tương đối đơn giản khi thực hiện trên các transformer-based model bằng cách bỏ đi các patch là input của encoder. Tuy nhiên, việc này lại khá khoai đối với ConvNets vì cấu trúc ảnh 2D phải được giữ nguyên. Để giải quyết vấn đề này, ta sẽ masked image như là một phối cảnh dữ liệu thưa thớt (sparse data perspective). Hiểu đơn giản là giờ đây masked image được biểu diễn như một mảng hai chiều thưa thớt các pixel (2D sparse array of pixels). Nhóm tác giả đề xuất chuyển đổi các lớp conv thông thường thành submanifold sparse conv cho phép model chỉ thao tác trên visible data points. Sparse conv layer có thể convert ngược lại sang conv tiêu chuẩn tại finetuning stage mà không cần phải xử lý gì thêm.
Thiết kế decoder. Nhóm tác giả sử dụng ConvNeXt block nhẹ, đơn giản làm decoder. Điều này cho ta một kiến trúc encoder-decoder bất đối xứng vì encoder nặng hơn và có kiến trúc phân tầng. Nhóm tác giả cũng xét các decoder phức tạp hơn nhưng ConvNeXt block vẫn đảm bảo hiệu suất tốt và giảm thời gian pretraining đi đáng kể 

Reconstruction target. Nhóm tác giả tính Mean squared error (MSE) giữa reconstructed image và target image.
FCMAE. Fully Convolutional Masked AutoEncoder được tổng hợp từ các thành phần đã mô tả ở trên
Dưới đây là kết quả finetuning accuracy khi sử dụng Sparse conv và không sử dụng Spare conv.
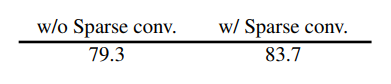
3.2. Global Response Normalization
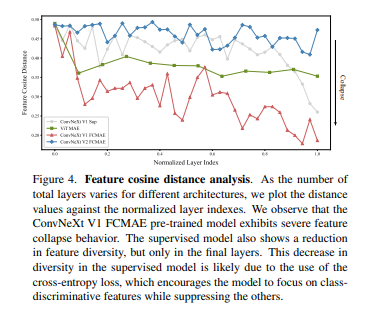
Feature collapse. Nhóm tác giả thực hiện phân tích định tính trong feature space và nhận thấy rằng, trong mô hình FCMAE pretrained ConvNeXt-Base có hiện tượng "feature collapse" (sự sụp đổ đặc trưng), có nhiều feature map biến mất hoặc bị bão hòa (trong hình dưới).

Feature cosine distance analysis. Để phân tích được rõ ràng hơn quan sát định tính trên, nhóm tác giả thực hiện phân tích feature consine distance. Ý tưởng là với cho một activation tensor
Trong đó,
là feature map của channel thứ i.
Ta tính trung bình pair-wise consine distance của các channel.
Giá trị càng lớn thì càng nói lên rằng feature càng đa dạng, ngược lại giá trị càng nhỏ thì thể hiện rằng feature đang bị dư thừa. Kết quả thực nghiệm của nhóm tác giả trên 1000 ảnh với các class khác nhau trong bộ ImageNet-1K như sau.
Cách tiếp cận. Nhóm tác giả giới thiệu một layer chuẩn hóa phản hồi mới (response normalization layer) được gọi là Global response normalization (GRN) với mục tiêu tăng mức độ tương phản (contrast) và chọn lọc (selectivity) của các kênh. Cho 1 input feature
GRN sẽ thực hiện 3 bước:
-
Tổng hợp global feature
-
Feature normalization
-
Hiệu chuẩn feature (feature calibration)
Đầu tiên, ta sẽ tổng hợp một spatial feature map thành một vector như sau
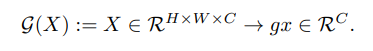
Nhóm tác giả nhận thấy rằng sử dụng norm-based feature aggregation đặc biệt là L2-norm cho kết quả tốt nhất.

Tiếp theo đó, nhóm tác giả sử dụng response normalization function cho giá trị được tổng hợp ở trên.
Phương trình trên tính giá trị "quan trọng tương đối" (relative importance) so sánh với các kênh khác. Bước này tạo ra sự cạnh tranh feature giữa các kênh bằng cách ức chế lẫn nhau (mutual inhibition). Nhóm tác giả cũng thử các cách normalization khác nhau và có kết quả như hình dưới.

Cuối cùng, nhóm tác giả hiệu chuẩn input response ban đầu sử dụng computed feature normalization scores:
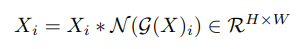
GRN được implement rất đơn giản như sau:

Để dễ dàng tối ưu, nhóm tác giả thêm 2 tham số learnable, và và khởi tạo chúng với giá trị 0. Nhóm tác giả cũng thêm một residual connection giữa input và output của GRN layer. Vậy ta có GRN block cuối cùng là:
Cách cài đặt này cho phép GRN layer ban đầu thực hiện một chức năng nhận diện và dần dần thích nghi trong quá trình đào tạo. Mức độ quan trọng của residual connection được thể hiện trong bảng dưới.

Nhóm tác giả kết hợp GRN layer vào ConvNeXt block gốc và nhận thấy rằng LayerScale sẽ không cần thiết nữa nếu như đã sử dụng GRN.

Nhóm tác giả so sánh với các phương pháp feature normalization trước đó và nhận thấy rằng GRN tốt hơn so với các normalization còn lại. Local Response Normalization (LRN) thiếu global context vì nó chỉ tương phản các kênh trong các lân cận. Batch Normalization (BN) chuẩn hóa không gian theo batch, điều này là không phù hợp với masked input. Layer Normalization khuyến khích việc cạnh tranh feature thông qua việc chuẩn hóa global mean và variance nhưng nó không tốt bằng GRN.
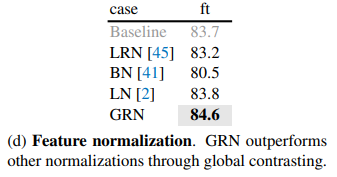
Một cách để nâng cao cạnh tranh giữa các neuron là sử dụng các phương pháp dynamic feature gating. Trong bảng dưới ta có Squeeze and excite (SE) và Convolutional block attention module (CBAM). SE tập chung vào channel gating, CBAM tập trung vào spatial gating. Cả 2 phương pháp này đều tăng mức độ tương phản giữa các kênh nhưng GRN đơn giản và hiệu quả hơn vì nó không yêu cầu các tham số layer bổ sung (như MLPs).

Nhóm tác giả kiểm tra mức độ quan trọng của GRN trong pretraining và finetuning. Nhóm tác giả thực hiện thao tác thêm và xóa GRN trong quá trình finetuning. Dù bằng cách nào, ta cũng thấy rằng sự suy giảm hiệu suất đáng kể, cho thấy rằng việc duy trì GRN trong cả quá trình pretraining và finetuning là rất quan trọng.

4. Thực nghiệm
4.1. ImageNet
Bảng dưới so sánh các kết quả của model đề xuất với các model masked image trước đó. Pretraining data là IN-1K training set. Tất cả các phương pháp self-supervised được benchmark bằng hiệu suất finetuning trên ảnh có kích thước 224 * 224.
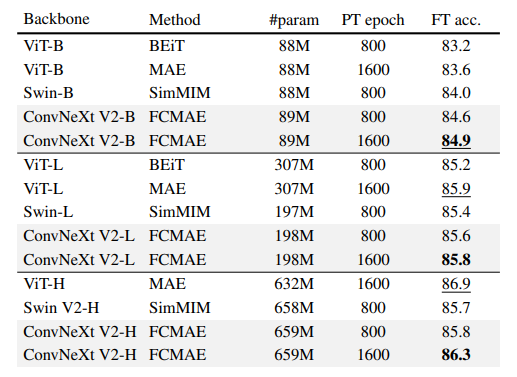
Dưới đây là kết quả finetuning ImageNet-1K sử dụng IN-21K labels. ConvNeXt Huge model với FCMAE pretraining đạt kết quả SOTA so với các phương pháp chỉ sử dụng public data.
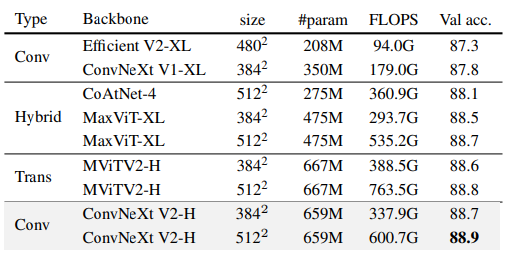
4.2. Transfer learning
Với Object detection và segmentation trên COCO.

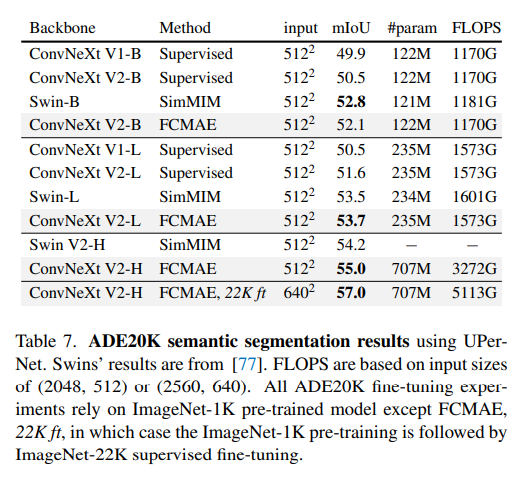
Semantic segmentation trên ADE20K.
5. Kết luận
Trong bài báo, nhóm tác giả giới thiệu một dòng mô hình ConvNet mới có tên là ConvNeXt V2 bao gồm phạm vi phức tạp rộng hơn. Mặc dù kiến trúc có những thay đổi tối thiểu, nhưng nó được thiết kế đặc biệt để phù hợp hơn cho self supervised learning. Bằng cách sử dụng fully convolutional masked autoencoder pre-training, nhóm tác giả cải thiện đáng kể hiệu suất của ConvNets thuần túy trên downstream task khác nhau, bao gồm ImageNet classification, COCO object detection và ADE20K segmentation.
6. Tham khảo
[1] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
©️ Tác giả: Trần Quang Hiệp từ Viblo
All rights reserved
