
Sơ lược về Azure OpenAI Realtime và cách sử dụng nó
1. Giới thiệu chung
Ngày nay việc sử dụng các mô hình ngôn ngữ lớn tiêu biểu như ChatGPT của OpenAI đã trở nên cực kì phổ biến. Thông thường mọi người chỉ dùng chức năng nhắn tin để hỏi đáp với các model như gpt3.5, gpt4o. Các mô hình này hoạt động rất tốt và phản hồi tương đối nhanh nếu xét trên phương diện nhắn tin, nhưng nếu chúng ta muốn việc tương tác trở nên thuận tiện hơn nữa bằng việc hỏi đáp liên tục thì cần mô hình tốt hơn nữa. Việc yêu cầu mô hình phải phàn hồi ngay lập tức, streaming liên tục chính là nguyên nhân cho sự ra đời của gpt-4o realtime.
Một số chức năng nổi bật của gpt-4o realtime:
- Hỗ trợ tương tác đàm thoại "lắng nghe và trả lời liên tục" có độ trễ thấp
- Hoạt động với tin nhắn văn bản, function-calling và nhiều khả năng hiện có khác như nhiều mô hình các với việc trả lời text.
- Rất phù hợp với các vai trò hỗ trợ, trợ lý, biên dịch viên và các trường hợp sử dụng khác cần phản hồi qua lại cao với người dùng.
Gpt-4o realtime được xây dựng trên API WebSockets để tạo điều kiện cho giao tiếp phát trực tuyến hoàn toàn không đồng bộ giữa người dùng cuối và mô hình. Nó được thiết kế để sử dụng trong bối cảnh của một dịch vụ trung gian đáng tin cậy quản lý cả kết nối với người dùng cuối và kết nối điểm cuối mô hình.
2. WebSockets
2.1. WebSockets là gì?
WebSocket (WS) là một giao thức truyền thông mạng cho phép kết nối hai chiều giữa client và server. Khác với HTTP, nơi phải thiết lập một kết nối mới cho mỗi yêu cầu, WebSocket cho phép duy trì một kết nối duy nhất, giúp trao đổi dữ liệu trong thời gian thực.
2.2. Lợi ích của WebSockets
Truyền thông hai chiều: Cho phép cả client và server gửi và nhận dữ liệu bất kỳ lúc nào. Giảm độ trễ: Không cần thiết lập lại kết nối cho mỗi yêu cầu, giảm thiểu độ trễ. Tiết kiệm băng thông: Chỉ cần một kết nối duy nhất, giúp tiết kiệm tài nguyên mạng.
2.3. Cách hoạt động của WebSockets
Quá trình kết nối WebSocket bắt đầu bằng một yêu cầu HTTP từ client đến server. Nếu server hỗ trợ WebSocket, nó sẽ phản hồi bằng mã trạng thái 101 (Switching Protocols), và một kết nối WebSocket sẽ được thiết lập.
2.4. Ví dụ sử dụng WebSockets với Python
Cài đặt thư viện
Để sử dụng WebSockets trong Python, bạn có thể sử dụng thư viện websockets. Cài đặt thư viện này bằng pip:
pip install websockets
Tạo server WebSocket
Dưới đây là một ví dụ đơn giản về cách tạo một server WebSocket với Python:
import asyncio
import websockets
async def echo(websocket, path):
async for message in websocket:
await websocket.send(f"Bạn đã gửi: {message}")
start_server = websockets.serve(echo, "localhost", 8765)
asyncio.get_event_loop().run_until_complete(start_server)
asyncio.get_event_loop().run_forever()
Chạy server:
python server.py
Tạo client WebSocket
Dưới đây là ví dụ về một client WebSocket:
import asyncio
import websockets
async def hello():
uri = "ws://localhost:8765"
async with websockets.connect(uri) as websocket:
await websocket.send("Xin chào, server!")
response = await websocket.recv()
print(f"Phản hồi từ server: {response}")
asyncio.get_event_loop().run_until_complete(hello())
Chạy client để tương tác vs server:
python client.py
2.5. Tổng quan
Qua phần giới thiệu trên, chúng ta có thể hiểu được nguyên lý hoạt động của WebSocket và từ đó cũng hiểu được phần nào lý do gpt-4o realtime chọn xây dựng trên API WebSocket. Giờ chúng ta sẽ đi vào phần chính là nguyên lý hoạt động và cách sử dụng gpt-4o realtime.
3. Gpt-4o Realtime
3.1. Cách thức hoạt động
Sau khi phiên kết nối WebSocket tới gpt realtime được thiết lập và xác thực, tương tác chức năng diễn ra thông qua việc gửi và nhận tin nhắn WebSocket. Mỗi tin nhắn này đều có dạng đối tượng JSON. Tin nhắn có thể được gửi và nhận song song và các ứng dụng thường sẽ xử lý chúng đồng thời và không đồng bộ. Thông qua việc nhận các tin nhắn từ gpt, chúng ta sẽ biết tiến trình xử lý request đến đâu và có thể đưa ra các quyết định là phải hồi lại bên client hay gửi tiếp các yêu cầu khác.
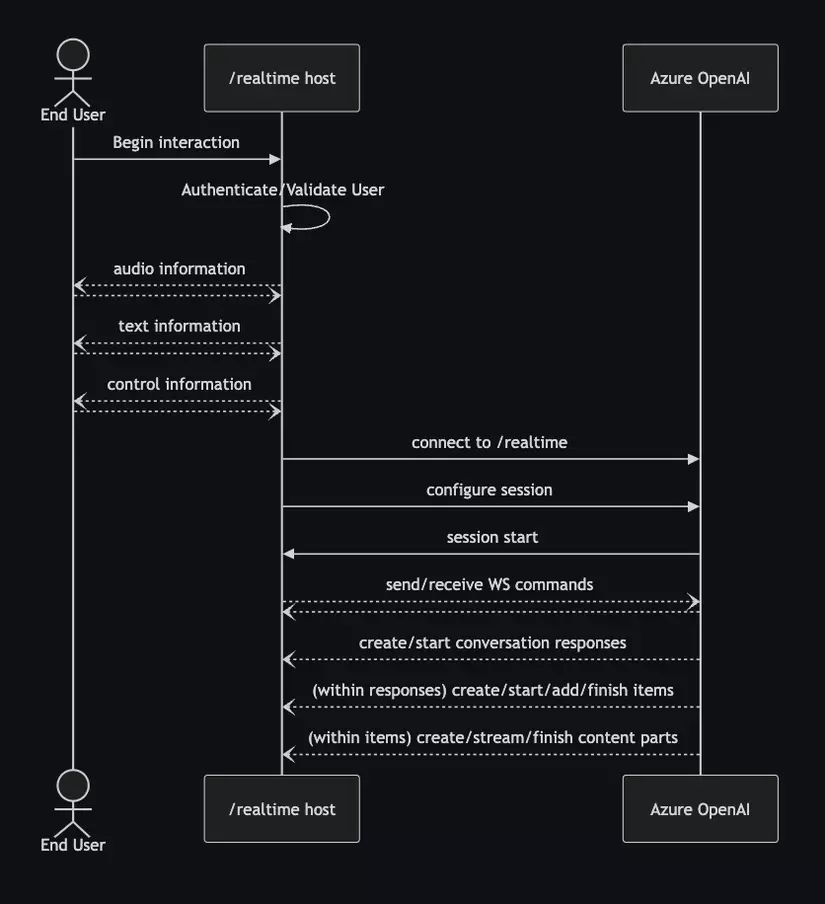
Một số khái niệm cần biết:
- Khi người gọi thiết lập kết nối ws đến gpt realtime sẽ bắt đầu phiên mới
- Phiên có thể được cấu hình để tùy chỉnh âm thanh đầu vào và đầu ra: thiết lập cài đặt cho việc phát hiện giọng nói trong audio đầu vào và các cài đặt về tốc độ, ngữ điệu trong audio đầu ra
- Phiên tự động tạo cuộc hội thọai mặc định (cuộc hội thoại để lưu trữ các câu hỏi của user và dùng làm context cho các câu hỏi phía sau)
- Lưu ý: trong tương lai, nhiều cuộc hội thoại đồng thời có thể được hỗ trợ -- hiện tại tính năng này không khả dụng. Mỗi khi 1 phiên mới được tạo thì cuộc hội thoại cũng sẽ được reset.
- Cuộc hội thoại lưu trữ liên tục audio đầu vào và transcript tương ứng cho đến khi phản hồi được bắt đầu, thông qua lệnh trực tiếp của người gọi hoặc tự động bằng phát hiện lượt dựa trên giọng nói
- Các tin nhắn nhận về từ ws bao gồm một hoặc nhiều mục, có thể nhiều mục đích như: phản hồi câu hỏi, function calling hoặc thông tin khác
- Khi response đang được gpt phản hồi, nếu bên gpt phát hiện có audio đầu vào mới sẽ tự ngắt response cũ nên cần thiết kế hệ thống phù hợp để không bị ngắt câu trả lời không mong muốn.
3.2. Cấu hình phiên và chế độ xử lý lượt
Thông thường, lệnh đầu tiên do người gọi gửi trên phiên của mới thiết lập sẽ là tải trọng session.update. Lệnh này thiết lập một tập hợp rộng các cấu hình đầu vào và đầu ra, sau đó có thể ghi đè thông qua các thuộc tính response.create, nếu muốn.
Một trong những thiết lập chính của toàn phiên là turn_detection, thiết lập này kiểm soát cách xử lý luồng dữ liệu giữa người gọi và mô hình:
- Server_vad sẽ đánh giá âm thanh người dùng đến (được gửi qua input_audio_buffer.append) bằng thành phần phát hiện hoạt động giọng nói (VAD) và tự động sử dụng âm thanh đó để bắt đầu tạo phản hồi cho các cuộc trò chuyện có thể áp dụng khi phát hiện thấy kết thúc giọng nói. Có thể cấu hình phát hiện im lặng cho VAD khi chỉ định chế độ phát hiện server_vad.
- Việc phiên âm âm thanh đầu vào của người dùng được chọn thông qua thuộc tính input_audio_transcription; việc chỉ định mô hình phiên âm (whisper-1) trong cấu hình này sẽ cho phép phân phối các sự kiện conversation.item.audio_transcription.completed.
Sau đây là ví dụ về session.update cấu hình một số khía cạnh của phiên, bao gồm các công cụ. Lưu ý rằng tất cả các tham số phiên đều là tùy chọn; không phải mọi thứ đều cần được cấu hình!
{
"type": "session.update",
"session": {
"voice": "alloy",
"instructions": "Call provided tools if appropriate for the user's input.",
"input_audio_format": "pcm16",
"input_audio_transcription": {
"model": "whisper-1"
},
"turn_detection": {
"threshold": 0.4,
"silence_duration_ms": 600,
"type": "server_vad"
},
"tools": [
{
"type": "function",
"name": "get_weather_for_location",
"description": "gets the weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": [
"c",
"f"
]
}
},
"required": [
"location",
"unit"
]
}
}
]
}
}
3.3. Handle các event khi dùng gpt realtime
3.3.1. Các event gửi sang gpt realtime
- session.update: Cấu hình cho toàn phiên hội thoại như xử lý đầu vào âm thanh và các đặc điểm tạo phản hồi chung. Thông thường, thông tin này được gửi ngay sau khi kết nối nhưng cũng có thể được gửi tại bất kỳ thời điểm nào trong phiên để cấu hình lại sau khi phản hồi hiện tại (nếu đang diễn ra) hoàn tất.
- input_audio_buffer.append: Thêm dữ liệu âm thanh cho đầu vào của người dùng. Âm thanh này sẽ không được xử lý cho đến khi phát hiện kết thúc lời nói trong chế độ server_vad turn_detection hoặc cho đến khi gửi response.create thủ công (trong bất kỳ cấu hình turn_detection nào).
- input_audio_buffer.clear: Xóa bộ đệm đầu vào âm thanh hiện tại. Lưu ý rằng thao tác này sẽ không ảnh hưởng đến các phản hồi đang diễn ra.
- input_audio_buffer.commit: Cam kết trạng thái hiện tại của bộ đệm đầu vào của người dùng với các cuộc hội thoại đã đăng ký, bao gồm cho phép thông tin này làm thông tin cho phản hồi tiếp theo.
- conversation.item.create: Chèn một mục mới vào cuộc hội thoại, tùy chọn được định vị theo previous_item_id. Điều này có thể cung cấp đầu vào mới, không phải âm thanh từ người dùng (như tin nhắn văn bản), phản hồi cho function calling hoặc thông tin lịch sử từ tương tác khác để tạo thành lịch sử hội thoại trước khi tạo.
- conversation.item.delete: Xóa một mục khỏi cuộc hội thoại hiện có
- conversation.item.truncate: Rút ngắn thủ công nội dung văn bản và/hoặc âm thanh trong tin nhắn, có thể hữu ích trong các tình huống mà việc tạo response nhanh hơn thời gian thực tạo ra do dữ liệu bổ sung đáng kể sau đó bị bỏ qua do gián đoạn.
- response.create: Khởi tạo quá trình xử lý đầu vào hội thoại chưa được xử lý, biểu thị kết thúc lượt logic của người gọi. Lưu ý: response.create phải được gọi sau lệnh response.done.
- response.cancel: Hủy phản hồi đang thực hiện.
3.3.2. Các event nhận về từ gpt realtime
- session.created: Được gửi ngay khi kết nối được thiết lập thành công. Cung cấp ID cụ thể cho kết nối có thể hữu ích để gỡ lỗi hoặc ghi nhật ký.
- session.updated: Được gửi để phản hồi sự kiện session.update, phản ánh những thay đổi được thực hiện đối với cấu hình phiên.
- conversation.item.created: Xác nhận rằng một mục hội thoại mới đã được chèn vào cuộc hội thoại.
- conversation.item.deleted: Xác nhận rằng một mục hội thoại hiện có đã bị xóa khỏi cuộc hội thoại.
- conversation.item.truncated: Xác nhận rằng một mục hiện có trong cuộc hội thoại đã bị cắt bớt.
- response.created: Thông báo rằng một phản hồi mới đã bắt đầu cho một cuộc hội thoại. Cho đến khi response.done biểu thị kết thúc của phản hồi, phản hồi có thể tạo các mục thông qua response.output_item.added sau đó được điền thông qua các lệnh delta.
- response.done: Thông báo rằng việc tạo phản hồi đã hoàn tất cho một cuộc hội thoại.
- rate_limits.updated: Được gửi ngay sau response.done, thông tin này cung cấp thông tin giới hạn tốc độ hiện tại phản ánh trạng thái đã cập nhật sau khi sử dụng phản hồi vừa hoàn tất.
- response.output_item.added: Thông báo rằng một mục hội thoại mới do máy chủ tạo đang được tạo; nội dung sau đó sẽ được điền thông qua các thông báo add_content với lệnh response.output_item.done cuối cùng biểu thị việc tạo mục đã hoàn tất.
- response.output_item.done: Thông báo rằng một mục hội thoại mới đã hoàn tất việc thêm vào hội thoại. Đối với các thông báo do mô hình tạo, lệnh này sẽ được thực hiện trước lệnh response.output_item.added và delta để bắt đầu và điền thông tin vào mục mới.
- response.content_part.added: Thông báo rằng một phần nội dung mới đang được tạo trong một mục hội thoại trong phản hồi đang diễn ra. Cho đến khi response_content_part_done đến, nội dung sau đó sẽ được cung cấp thông qua các lệnh delta thích hợp.
- response.content_part.done: Báo hiệu rằng phần nội dung mới tạo đã hoàn tất và sẽ không nhận thêm bất kỳ bản cập nhật nào nữa.
- response.audio.delta: Cung cấp bản cập nhật cho phần nội dung dữ liệu âm thanh nhị phân do mô hình tạo ra.
- response.audio.done: Báo hiệu rằng các bản cập nhật của phần nội dung âm thanh đã hoàn tất.
- response.audio_transcript.delta: Cung cấp bản transcript cho bản ghi âm thanh liên quan đến nội dung âm thanh đầu ra do mô hình tạo ra.
- response.audio_transcript.done: Báo hiệu rằng bản cập transcript cho bản ghi âm thanh của âm thanh đầu ra đã hoàn tất.
- response.text.delta: Cung cấp bản cập nhật cho phần nội dung văn bản trong mục tin nhắn hội thoại.
- response.text.done: Báo hiệu rằng các bản cập nhật cho phần nội dung văn bản đã hoàn tất.
- response.function_call_arguments.delta: Cung cấp bản cập nhật cho các arguments của lệnh function calling.
- response.function_call_arguments.done: Báo hiệu rằng các arguments của lệnh function_call_arguments.delta đã hoàn tất và giờ đây có thể sử dụng toàn bộ các arguments đã tích lũy.
- input_audio_buffer.speech_started: Khi sử dụng chức năng phát hiện hoạt động giọng nói được cấu hình, lệnh này thông báo rằng đã phát hiện thấy sự bắt đầu của giọng nói của người dùng trong bộ đệm âm thanh đầu vào.
- input_audio_buffer.speech_stopped: Khi sử dụng chức năng phát hiện hoạt động giọng nói được cấu hình, lệnh này thông báo rằng đã phát hiện thấy sự kết thúc của giọng nói của người dùng trong bộ đệm âm thanh đầu. Điều này sẽ tự động kích hoạt việc tạo phản hồi khi được cấu hình.
- conversation.item.input_audio_transcription.completed: Thông báo rằng có phiên âm bổ sung cho bộ đệm âm thanh đầu vào của người dùng.
- conversation.item_input_audio_transcription.failed: Thông báo rằng phiên âm âm thanh đầu vào không thành công.
- input_audio_buffer_committed: Cung cấp xác nhận rằng trạng thái hiện tại của bộ đệm âm thanh đầu vào của người dùng đã được gửi đến các cuộc hội thoại đã đăng ký.
- input_audio_buffer_cleared: Cung cấp xác nhận rằng bộ đệm âm thanh đầu vào của người dùng đang chờ xử lý đã được xóa.
3.4. Luồng sử dụng gpt realtime
Việc sử dụng gpt có thể coi là việc handle các event từ gpt trả về và gửi đi các lệnh hợp lý cho gpt. Sau đây là luồng đơn giản để sử dụng gpt realtime:
Nếu không sử dụng function calling:
- Đầu tiên sử dụng WebSocket kết nối đến Gpt Realtime.
- Sử dụng event session.update để cập nhật system prompt.
- Thiết cập vòng lặp để nhận và xử lý tin nhắn trả về Gpt Realtime liên tục.
- Khi bắt đầu có giọng nói từ mic, gửi liên tục sang audio sang Gpt Realtime thông qua event input_audio_buffer.append.
- Gpt Realtime sẽ tự động nhận diện khi nào kết thúc câu hỏi và tiến hành phản hồi câu trả lời.
- Hứng event response.audio.delta liên tục từ GPT, trích xuất dữ liệu nhị phân trong đó rồi trả về audio cho user.
Khi không sử dụng function calling, hệ thống của bạn sẽ chỉ như 1 chatbot đơn giản sử dụng những kiến thức sẵn có và phản hồi với tốc độ cao.
Nếu muốn sử dụng function calling:
Luồng cơ bản sẽ gần giống như bên trên, điểm khác biệt là:
- Sau khi kết nối tới Gpt Realtime, ở phần update session, ngoài cập nhật system prompt còn cần update danh sách các functions trong hệ thống cho GPT. Trong đó, chúng ta cần mô tả chi tiết nhiệm vụ và vai trò của từng functions và các required arguments của chúng.
- Sau khi nhận diện được kết thúc câu hỏi người dùng, Gpt Realtime sẽ đưa ra quyết định dùng functions (tools) nào để lấy thêm thông tin cho câu hỏi.
- Các evnet liên quan đến function_call_arguments sẽ được trả về, hệ thống cần bắt được toàn bộ các event đó, truy xuất được tên function và các arguments. Từ đó gọi đến function đó để lấy thêm thông tin rồi trả ngược về GPT thông qua event conversation.item.create.
- Nhận được thông tin bổ sung, GPT sẽ bắt đầu tạo response. Nhiệm vụ còn lại sẽ giống luồng bên trên.
Tổng kết
Trong bài viết trên, tôi đã trình bày sơ lược về nguyên lý hoạt động của WebSocket cũng như Gpt-4o Realtime. Có thể thấy việc sử dụng tương đối khác so với sử dụng các mô hình GPT khác vì sẽ cần thời gian thử nghiệm để có thể hoàn toàn làm chủ về các event của mô hình. Đồng thời tôi cũng có trình bày một số cách đơn giản về việc sử dụng Gpt-4o Realtime.
Trên đây là toàn bộ kiến thức về Gpt-4o Realtime mà tôi tìm hiểu và trải nghiệm được trong quá trình làm dự án. Nếu có phần nào chưa được chính xác hay có điều gì mọi người muốn đóng góp, hãy để lại ý kiến của mình ở comment. Cảm ơn đã dành thời gian đọc bài viết của tôi!
All rights reserved
