
[Paper Explain] JoJoGAN for One Shot Face Stylization
Bài đăng này đã không được cập nhật trong 4 năm
 Style transfer là một bài toán thuộc lĩnh vực computer vision nhận được sự chú ý của nhiều nhà nghiên cứu bởi tính ứng dụng cao trong các ứng dụng chỉnh sửa ảnh áp dụng công nghệ AI. Việc huấn luyện một mạng nơ ron để thực hiện style transfer là rất khó khăn bởi vấn đề tìm kiếm dữ liệu. Paper JoJoGAN mà mình sẽ giới thiệu ở đây đã đề xuất một thủ tục để finetune mạng Generator của StyleGAN để thực hiện style transfer chỉ với duy nhất 1 ảnh reference.
Style transfer là một bài toán thuộc lĩnh vực computer vision nhận được sự chú ý của nhiều nhà nghiên cứu bởi tính ứng dụng cao trong các ứng dụng chỉnh sửa ảnh áp dụng công nghệ AI. Việc huấn luyện một mạng nơ ron để thực hiện style transfer là rất khó khăn bởi vấn đề tìm kiếm dữ liệu. Paper JoJoGAN mà mình sẽ giới thiệu ở đây đã đề xuất một thủ tục để finetune mạng Generator của StyleGAN để thực hiện style transfer chỉ với duy nhất 1 ảnh reference.
Một số khái niệm cần biết
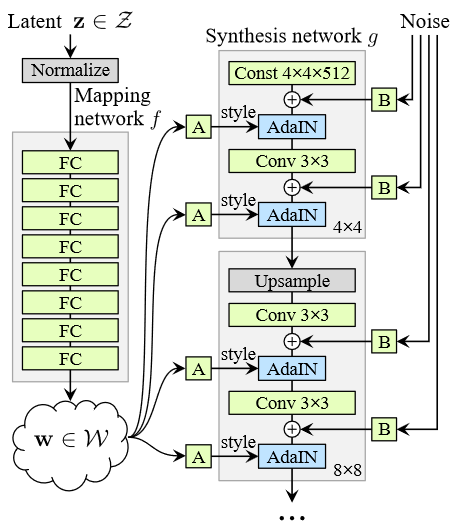
StyleGAN generator
Mạng generator của stylegan có 1 chút khác biệt với các mô hình GAN truyền thống. Thay vì nhận đầu vào trực tiếp là vector latent thì vector sẽ được đưa qua một mạng MLP 8 lớp để tạo ra vector với cùng số chiều. Vector được dùng để kiểm soát style của ảnh thông qua lớp Adaptive Instance Normalization. Một phép biến đối affline (học thông qua một lớp fully connected - ký hiệu A trong hình dưới) được áp dụng lên trước khi đưa vào mạng generator.
GAN inversion
Mạng generator của GAN sẽ tạo ra ảnh từ một vector latent . GAN inversion là quá trình ngược lại, từ ảnh đầu vào tìm vector latent tương ứng của nó.
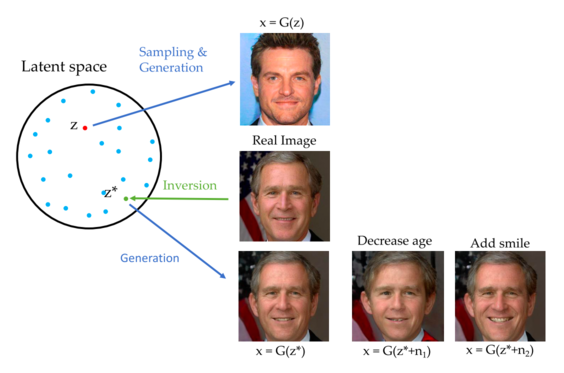
Một số cách tiếp cận cho GAN inversion
- Optimization based: sử dụng gradient descent để tối ưu vector sao cho ảnh khôi phục giống với ảnh thật nhất.
Do quá trình tối ưu diễn ra lúc inference nên chi phí tính toán khá là tốn kém. Một số paper dựa trên cách tiếp cận này:
-
Encoder based: sử dụng 1 mạng encoder được huấn luyện trên nhiều ảnh được tạo ra bởi mạng generator với các latent vector tương ứng.
Một số paper:
-
https://arxiv.org/abs/2104.02699 Ở Việt Nam thì gần đây cũng có một paper của VinAI về chủ để này: HyperInverter: Improving StyleGAN Inversion via Hypernetwork
-
Hybrid based: vector được sinh ra bởi mạng encoder được dùng để khởi tạo cho quá trình gradient descent và tiếp tục được finetune.
JoJoGAN
Workflow chính
 Workflow bao gồm 4 bước. Ký hiệu:
Workflow bao gồm 4 bước. Ký hiệu:
- : ánh xạ GAN inversion
- : generator của StyleGAN
- : style parameter (output của biến đổi affline - các khối chữ A trong generator)
- : trọng số generator của StyleGAN.
Bước 1: GAN inversion. Một quan sát của tác giả trong quá trình inversion là với 1 ảnh style reference thì ảnh sau khi reconstruct lại trông khá là thật thay vì có nét stylized kiểu hoạt hình (step 1 trong hình trên). Nguyên nhân có thể do các mạng encoder trong GAN inversion được huấn luyện để tạo ra latent vector cho ảnh thật hơn là ảnh được stylized. Output của quá trình là vector trong không gian và một tập style parameter tương ứng
Bước 2: Tạo tập training. Dùng thu được ở bước 1 để tìm 1 tập style parameter khác gần giống với . Việc tìm kiếm tập được thực hiện thông qua cơ chế style mixing của StyleGAN. Trong lúc huấn luyện StyleGAN, một phần ảnh trong tập training được tạo ra bằng cách sample 2 latent vector và thay vì một. Trong quá trình forward của mạng generator, ta lựa chọn ngẫu nhiên một điểm trong mạng để chuyển sử vector style sang .
Style mixing trong JoJoGAN: Với kiến trúc StyleGAN2 gồm 26 modulation layer (Adaptive instance normalization), ta sẽ có style parameter kích thước . Ký hiệu:
và vector mask; FC là lớp mạng mapping ; . Tập style parameter mới được tính bằng công thức:
Lựa chọn vector M khác nhau sẽ dẫn đến các hiệu ứng khác nhau

Bước 3: Finetuning mạng generator để có
trong đó hàm mất mát L được sử dụng là perceptual loss. Thông thường perceptual loss được tính bằng backbone VGG được train trên ảnh kích thước , còn StyleGAN lại sinh ảnh kích thước . Một hướng để xử lý là down sample ảnh sau khi sinh xuống để tính loss nhưng cách xử lý này sẽ dẫn tới mất mát đặc trưng ảnh. Hướng thứ 2 được sử dụng trong paper này là tính perceptual loss dựa trên activation của mạng discriminator. Quá trình training của StyleGAN giúp discriminator tính toán các feature map mà không bỏ qua các chỉ tiết nhỏ.
Bước 4: Inference. Với ảnh input , Ảnh được stylized được tính bằng . Ta cngx có thể tạo ra ảnh ngẫu nhiên với style chỉ định bằng cách sample từ phân phối và đưa qua generator.
Một số biến thể
Controling identity
Một số ảnh style reference khiển ảnh input không giữ được identity (mất đi nhiều đặc trưng về structure). Trong trường hợp này, tác giả có sử dụng thêm hàm identity loss để bảo toàn thông tin về nhận dạng.
trong đó là khoảng cách cosine và là mô hình arcface pretrained.

Kiểm soát style intensity bằng feature interpolation
Sử dụng feature interpolation cho phép ta kiểm soát cường độ của style được transfer sang input. Ký hiệu là feature map thứ của generator gốc và là feature map của generator sau khi fine tune. Feature map mới được tính bằng công thức

Extreme Style References
Khi muốn transfer style với một ảnh reference out of distribution (ví dụ ảnh chó mèo trong khi StyleGAN train trên ảnh mặt người), thay vì sử dụng trực tiếp để xây dựng tập style parameter, tác giả sử dụng mean style code để làm ước lượng cho cho ảnh out of distribution.

Lựa chọn GAN inversion
Theo quan sát của tác giả, mếu thủ tục GAN inversion tạo ra ảnh realistic từ ảnh reference, JoJoGAN sẽ được train để ánh xạ sang ảnh được stylized với cường độ mạnh. Ngược lại nếu GAN inversion tạo ra ảnh được stylized JoJoGAN sẽ ánh xạ sang ảnh stylized nhưng với cường độ nhẹ hơn và giữ lại nhiều đặc trưng của input hơn.

Như đã nhắc đến ở phần Extreme Style References, mean style code là ước lượng tốt nhất của với ảnh out of distribution. Điều này cũng đúng khi áp dụng với một GAN inverter không tốt. Tác giả tạo ra một virtual inverter bằng cách cộng latent vector từ GAN inversion với mean style code bằng thủ tục ở bước 3 với các vector M khác nhau. Vector M được lựa chọn sao cho có các đặc trưng mong muốn (VD: output có mắt của ảnh reference thì phải có mắt trông thật.

Qualitative result
Một số kết quả so sánh về mặt hình ảnh


Reference
All rights reserved
