
GraphRel: A way of using graph neural network for relation extraction, pros and cons.
Bài đăng này đã không được cập nhật trong 5 năm
Trong phần 1 của bài này tôi sẽ giới thiệu về relation extraction và challenges của bài toán.
Relation extraction
Relation extraction (trích xuất mối quan hệ) và relation classification (phân loại mối quan hệ).
Khi tìm hiểu bài toán này, tôi khá confused vì 2 cái tên trên, chúng nói về cùng một bài toán hay khác nhau .
- Khi nghe relation extraction, tôi có cảm giác như input của bài sẽ là một sequence , các entities chứa trong , và một set các relations mà ta đang quan tâm tới. Nhiệm vụ là tìm các tuples trong đó là các entities và
- Còn relation classification thì setup sẽ giống như trên, có thể khác ở 2 điểm sau: Các cặp có mỗi quan hệ với nhau sẽ được cho sẵn và Output sẽ là các cặp đó có mối quan hệ nào trong
Nếu phân biệt như vậy thì các datasets có thể được construct khác nhau như sau:
- Input có cho sẵn các entities hay không
- Nếu cho sẵn entities thì tất cả các entities có trong sequence đều được annotated hay chỉ các cặp entities có relations thuộc mới được annotated.
Nhưng tôi vẫn chưa tìm được literature nào phân biệt hai khái niệm trên tôi sẽ tạm coi chúng là như nhau. Và trong bài viết này, tôi sẽ tập trung vào bài toán các entities không được cho sẵn dưới dạng input đầu vào của model mà sẽ chỉ có ở labels.
Các thách thức trong bài toán này
Imbalanced relation classification : số lượng các relation trong datasets chênh lệch nhau lớn, khiến cho việc dự toán relation và generalize trở nên khó hơn, vấn đề trở nên nghiêm trọng hơn khi size của dataset nhỏ.
Long-distance relations: các entities có quan hệ có vị trí cách xa nhau (số token giữa 1 cặp entities (DG-SpanBert) như các sequences sau (TARED Stanford) .
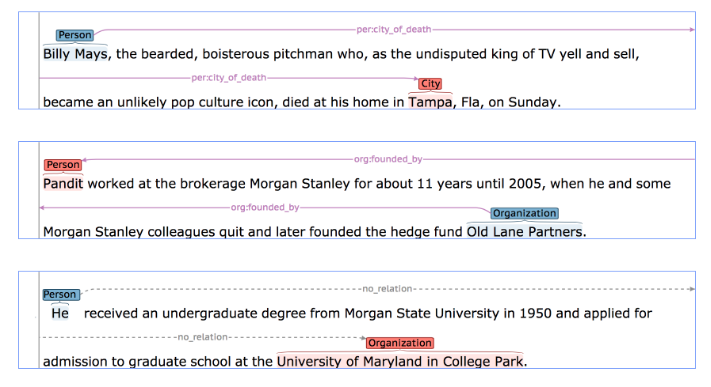
Paper DG-SpanBert claim rằng Bert-based model cũng không effective trong việc capture long-range syntactic relations nhưng không giải thích tại sao. Đây cũng là một điểm rất không ổn của nhiều paper mà tôi từng đọc: không trích dẫn hoặc có chứng minh/ giải thích rõ ràng về claims mình đưa ra, khiến người đọc thực sự khó cả đánh giá độ tin cậy lẫn tiếp thu kiến thức mới : ((
Overlapping: Có hai dạng chính là Entities Pair Overlap (EPO) và Single-entity Overlap (SEO) . Ví dụ đơn giản như sau: Bakso is a food found in Indonesia where the capital is Jakarta and the leaders are Jusuf Kalla and Joko Widodo .
- EPO: (Bakso, Indonesia, region) ; (Bakso, Indonesia, country)
- SEO: (Indonesia, Jakarta, captital) ; (Indonesia, Jusuf Kalla, learde rname), (Indonesia, Joko Widodo, learde rname)
Overlapping gây khó khăn trong việc design objective function cho bài toán (vì nhiều bài toán assume rằng mỗi cặp entites chỉ liên quan với nhau bằng một quan hệ và extreme hơn nữa là mỗi câu chỉ có 1 label ) và một side effect của hầu hết các objective functions mà tôi từng đọc được là gây highly imbalanced classification giữa positive (có quan hệ) và negative (không có quan hệ) pairs. Để hiểu rõ hơn, ở đoạn này tôi sẽ nói kĩ hơn về một vài objective như sau:
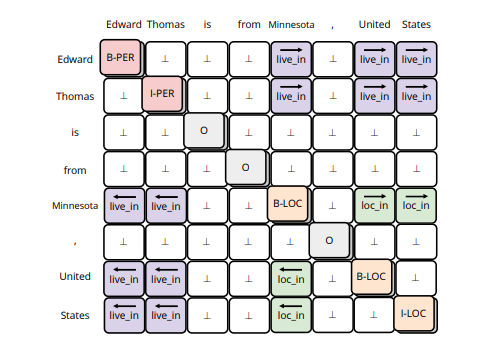
Ma trận trên là output của model. Trong đó, diagonal entries thể hiện xem từng tokens có phải là entities không. Entities tagging có được annotated dưới dạng BIOES ( Ví dụ: Edward Thomas is from Minesota, United States ; thì Edward: B-PER (bắt đầu tên một người), Thomas: E-PER (kết thúc tên một người), is: O (không thuộc entites), from : O; Minesota : S-Loc (Entity nơi chốn, chỉ gồm 1 từ)). Các cách tagging khác các bạn có thể tham khảo ở wiki.
Còn lại các entries khác của ma trận sẽ chứa thông tin relation giữa các tokens trong câu. Ví dụ hình trên. Vậy mỗi cặp token , , ta có thể coi như đây là bài multi- labels classification, output là ( là non-relation). Objective kiểu này cũng có thể được define bởi, thay vì một matrix ta sẽ output một tensor 3D trong đó dimension thứ 3 là số relation (không tính non-relation). Mỗi matrix có các sẽ có các giá trị hoặc ở các non-diagonal entries, thể hiện các cặp token có quan hệ mà ta đang xét đến không (binary classification). Objctive này phù hợp với cả cách thức joint training (train cả Name entites reconition (NER) và relation extraction) và chỉ training relation extraction không thôi.
Objects predicting (CasRel paper)
Thay vì nhìn bài toán theo dạng từ một cặp entites, hãy predict xem giữa chúng có quan hệ gì với nhau () thì bây giờ, từ một entites/subjects, ta xét từng relation một và tìm xem đâu là objects của entities đó, nếu có với quan hệ đang xét.
Một hạn chế của cách design này là bỏ qua thông tin về entities type của các entitities. Entities types quan trọng vì nó giúp mô hình dễ dàng nhận biết mối quan hệ giữa các entities hơn. Ví dụ Rachel Green (PER) và America (LOC) không thể có mối quan hệ ‘is_captital_of ’ với nhau được.
Link prediction (GraphRel)
Phương pháp này được sử dụng trong paper GraphRel, trong đó, các từ trong câu được biểu diễn thành các node, còn graph thì được xây dựng dựa trên Dependency tree( sẽ được nêu rõ hơn ở phần sau). Mục tiêu tổng quát của model là học embeddings của các nodes (các token) sau đó dự đoán entities tagging của các node (node classification) và dự đoán relation của từng cặp nodes (l***ink prediction*** mà không cần biết node đó có được đoán là entities hay không).
Nhìn chung cách design objective để khắc phục được vấn đề overlapping rất đa dạng, nhưng tôi nghĩ các cách này vẫn chỉ là nhìn bài toán relation extraction trên nhiều perspective chứ không hẳn là có sự khác biệt rõ rệt về mặt objective design. Vì cả object prediction hay link prediction cũng hoàn toàn có thể đưa về table filling nếu đã biết token/nodes/span representation. (Ví dụ như United States là một span)
Các dạng objectives trên đều về lý thuyết có thể giải quyết được vấn đề EPO, SEO (vì cả 3 cách đều rất linh hoạt về số lượng các cặp entitites có thể có mối quan hệ với nhau và số lượng mối quan hệ trong mỗi cặp cũng không giới hạn). Tuy nhiên chúng đều share nhược điểm mà tôi đã nói ở trên là extremely imbalanced về số lượng negative examples và positive examples.
Để khắc phục điều này, nhiều paper sử dụng hard negative sampling (select nhưng example khó phân biệt - classification confidence score thấp, để làm negative examples.) Mà trong relation extraction thì , intuitively, những non-relation giữa các entities thì khó đoán hơn là các non-relation giữa các cặp từ/ span mà một trong hai hoặc cả hai đều không phải là entitties.
Ví dụ, The 1 Decembrie 1918 University is located in Alba Iulia, Romania. The capital of the country is Bucharest... được annotated là (is country of:Romania, Alba Iulia), (is capital of:Bucharest, Romania). Chú ý ở đây các entities không có mối quan hệ mà ta đang quan tâm sẽ không được annotated. Như vậy hard negative example trong ví dụ này sẽ được sample từ .
Nếu sử dụng hard negative sampling thì joint training NER và RE sẽ trở thành multi-task learning. Vì đầu ra của NER model thực chất sẽ không được dùng làm input cho RE model. Ngoài ra, chúng ta hoàn toàn có thể sử dụng các cách khác để overcome imbalanced như focal loss. Trong 3 cách design objective trên, tôi không nhận thấy sự vượt trội về mặt idea của bất cứ cách nào.
Khó khăn tiếp theo là span representation/ feature embeddings.
Paper What does BERT learn about the structure of language? chỉ ra rằng syntactic features thường được represented nhiều nhất qua các intermidiate layers của Bert-based models. Vậy việc sử dụng highest layer’s token represenation cho NER và RE liệu có hiệu quả không?
Bert-based models được train trên masked language task, tức là che đi random tokens , rồi dùng các token còn lại để đoán xem token bị che là gì. Tuy nhiên paper LUKE có chỉ ra rằng đây không phải ý hay vì nó không biểu diễn tốt spans (Hà Nội). Nếu che đi chữ Nội thì với chữ Hà ta có thể dễ đoán chữ bị che là chứ Nội thay vì che cả chữ Hà Nội và cố đắng đoán span đó dựa vào các dữ kiện khác trong câu.
Như vậy trong bài này tôi đã giới thiệu qua về task relation extraction và một vài challenges trong task này. Phần 2 của bài viết sẽ phân tích paper GraphRel và các ưu điểm , nhược điểm của mô hình joint training NER, RE trong paper này.
All rights reserved
