
[Paper Explain] Ứng dụng Semi-Supervised cho bài toán về Semantic Segmentation
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu
Trong những năm trở lại đây semi-supervised learning đã và đang trở thành chủ đề được ứng dụng và nghiên cứu trong nhiều lĩnh vực khác nhau(xử lý hình ảnh, xử lý ngôn ngữ, tiếng nói ..vv). Trong đó việc ứng dụng semi-supervised learning để cải thiện hiệu quả cho các bài toán về segmentation đang được xem là một trong số những xu hướng nghiên cứu những năm gần đây. Trong bài viết lần này mình sẽ trình bày bài báo “Semi-Supervised Semantic Segmentation with Cross-Consistency Training” là một trong những nghiên cứu mô tả phương pháp tiếp cận và cải thiện bài toán semantic segmentation bằng phương pháp semi-supervised learning.
Một số đóng góp chính trong bài báo
- Đề xuất một phương pháp cross-consistency training (CCT)
- Thử nghiệm một số loại perturbations khác nhau
- Mở rộng cách tiếp cận để sử dụng dữ liệu weak-label và khai thác các pixel level labels trên các miền dữ liệu khác nhau Chúng ta hãy cùng làm rõ các tư tưởng và các đóng góp chính của bài báo nhé.
Phương pháp tiếp cận
Cluster Assumption in Semantic Segmentation
- Giả định rằng nếu các điểm nằm trong cùng một phân cụm, chúng có khả năng thuộc cùng một lớp. Có thể có nhiều cụm tạo thành một lớp duy nhất. Một cách đơn giản để kiểm tra giả định cụm (cluster assumption) là ước tính local smoothness bằng cách đo các local variations giữa giá trị của mỗi pixel và các điểm ảnh lân cận cục bộ của nó. Để thực hiện, họ tính toán khoảng cách Euclid trung bình tại mỗi vị trí pixel và 8 điểm lân cận trung gian của nó, cho cả đầu vào và các hidden representation level.

- Họ nhận thấy rằng giả định cụm bị vi phạm ở input level do các vùng mật độ thấp (low density regions) không phù hợp với ranh giới lớp (class boundaries).
- Đối với đầu ra của bộ mã hóa, giả định cụm được duy trì trong đó các ranh giới lớp có khoảng cách trung bình cao, tương ứng với các vùng mật độ thấp. Những quan sát này giúp họ phảt biểu rằng phương pháp tiếp cận bằng cách áp dụng nhiễu cho đầu ra của bộ mã hóa thay vì đầu vào thì sẽ mang lại hiệu quả cao hơn cho bài toán về segmentation.
Cross-Consistency Training
Mô tả tổng quan của phương pháp, cũng như là tư tưởng chính của bài báo
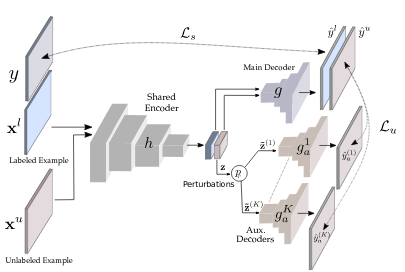
- đại diện cho n sample có nhãn và đại diện cho m sample chưa được gắn nhãn. Trong đó ( số lượng class) tương ứng là pixel-level label.
- Kiến trúc mạng được thiết kế với một share encoder và main decoder tạo thành sementation networks và các khối auxiliary decoders với
- Trong khi segmentation network được huấn luyện với dữ liệu đã được gắn nhãn , trong khi đó auxiliary networks được huấn luyện với dữ liệu chưa được gắn nhãn bằng cách tính consistency giá trị dự đoán giữa main decoder và các auxiliary decoders. Với mỗi auxiliary decoder ứng với một cách biến đổi khác nhau của giá trị đầu ra của encoder (cách biến đổi này sẽ được trình bày ở phần perturbation functions) trong khi đó main decoder sử dụng trực tiếp representation được tạo từ encoder. Bằng cách này thì các biểu diễn học được từ encoder sẽ tốt hơn nhờ sử dụng dữ liệu chưa được gắn nhãn.
- Với mỗi sample và pixel_level label mạng sẽ được huấn luyện với hàm loss là Cross Entropy. Tác vụ này gọi là supervised loss
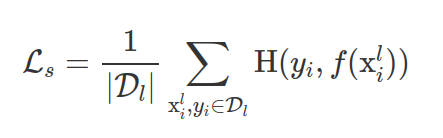
- Mục tiêu huấn luyện là tối ưu hàm unsupervised loss , giảm thiểu sự khác biệt giữa đầu ra của main decoder và các auxiliary decoder. Cùng một mẫu dữ liệu chưa được gắn nhãn sẽ qua share encoder tạo thành representation . Xem như các hàm perturbation (các hàm biến đổi giá trị đầu ra của khối encoder) là một phần của các khối auxiliary decoders tương ứng ( khi đó sẽ thành ). Khi đó là giá trị dự đoán của main decoder và là các giá trị dự đoán của K auxiliary decoders.
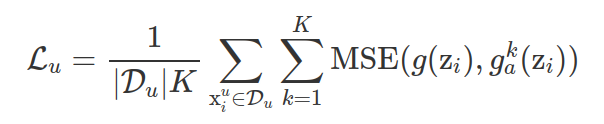
- Trong đó là số lượng các auxiliary decoders, MSE (mean squared error)
Perturbation Functions
Họ đề xuất 3 loại perturbation functions , vì mình chỉ tập chung và phần tư tưởng của bài báo nên phần perturbation functions này mình chỉ nêu ra mang tính giới thiệu, các bạn có thể tìm hiểu và đọc kỹ hơn nhé.
- Feature-based
- F-Noise: Lấy nhiễu có cùng kích thước với . ta có
- F-Drop: Lấy mẫu đồng nhất một ngưỡng Họ tạo ra một mask = {z^' <= } được sử dụng để tính
- Prediction-based
- Chiến lược thêm nhiễu động dựa trên dự đoán của main_decode
- Guided Masking
- Guided Cutout (G_Cutout)
- Intermediate VAT (I-VAT)
- Random (DropOut)
Triển khai thực tế
- Trong quá trình huấn luyện với mỗi interation họ sample một số lượng dữ liệu có nhãn và chưa được gắn nhãn như nhau. Tuy nhiên do dữ liêu có nhãn nhỏ hơn nhiều so với tập dữ liệu chưa được đánh nhãn nên số lần lặp của dữ liệu có nhãn sẽ nhiều hơn trong quá trình huấn luyện, nguy cơ cao là sẽ bị overfit trên tập dữ liệu có nhãn. Để khắc phục thì họ đề xuất một hàm loss bootstrapped-CE
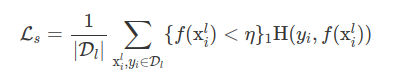
- Với tức là họ sẽ tính supervised loss trên những pixels với probability thấp hớn một ngưỡng . Giá trị ngưỡng này sẽ tằng từ tới 0.9 với C là số lượng class.
Exploiting weak-label
-
Họ nói rằng trong trường hợp mà họ được cung cấp một bộ dữ liệu đánh nhãn kém (wealy labeled dataset) thì làm sao để họ tận dụng được thông tin này để những biểu diển được tạo ra bởi encoder tốt hơn.
-
Theo những nghiên cứu mà họ có đề cập trong bài báo thì từ pretrained encoder và một nhánh classification được thêm vào thì họ có thể tạo ra peseudo pixel-levels labels . Khi đó hàm loss
![image.png]()
-
trong đó loss của weaky labeled sample, giống với supervised loss của dữ liệu có nhãn tuy nhiên thì cần làm rõ thêm phần tạo pesudo pixel-levels labels
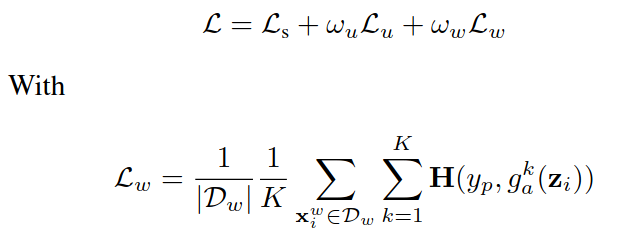
Cross-Consistency Training on Multiple Domains
- Để mở rộng bài toán cho nhiều bộ dataset, ví dụ 2 bộ , với mỗi tập dữ liệu sẽ có một phân dữ liệu không nhãn và có nhãn .Khi đó mô hình sẽ được add thêm các auxiliary decoders tương ứng với từng domains của mỗi bộ dữ liệu.

Tài liệu tham khảo
[1] Semi-Supervised Semantic Segmentation with Cross-Consistency Training
All rights reserved
