
SQL Query Antipatterns and Solution (part 1)
Bài đăng này đã không được cập nhật trong 3 năm
SQL là một ngôn ngữ không còn xa lạ với mọi lập trình viên và đối với với lập trình viên backend việc làm chủ được SQL là một điều rất quan trọng. Trong quá trình làm việc của mình với SQL mình đã tham khảo rất nhiều nguồn để tìm hiểu các lỗi hay mắc phải, các giải quyết/tối ưu nó. Bài viết này mình sẽ chia sẻ những kỹ thuật mình đang sử dụng để tối ưu hệ thống của mình với SQL.
Antipatterns là gì ?
Thuật ngữ "antipatterns" do lập trình viên máy tính Andrew Koenig đặt ra vào năm 1995 , được lấy cảm hứng từ cuốn sách Design Patterns (trong đó nêu bật một số mẫu thiết kế trong phát triển phần mềm mà các tác giả của nó cho là có độ tin cậy và hiệu quả cao) và nó được phổ biến nhờ cuốn sách AntiPatterns năm 1998.
Antipatterns là là một quy trình, cấu trúc hoặc mẫu hành động thường được sử dụng, mặc dù thoạt đầu có vẻ là một phản ứng phù hợp và hiệu quả đối với một vấn đề, nhưng lại gây ra nhiều hậu quả xấu hơn là hậu quả tốt. AntiPattern có thể là kết quả của việc người quản lý hoặc nhà phát triển không biết điều gì tốt hơn, không có đủ kiến thức hoặc kinh nghiệm trong việc giải quyết một loại vấn đề cụ thể hoặc đã áp dụng một mẫu hoàn toàn tốt trong ngữ cảnh sai.
Một số SQL Antipatterns phổ biến
1. Sử dụng sai/Hiểu lầm về NULL
Vai trò của giá trị NULL và những lỗi thường gặp khi sử dụng NULL
Giá trị Null thường để biểu diễn các giá trị chưa được xác định hoặc các sự kiện chưa xảy ra nhắm giúp kiểm soát và truy vấn dễ dường hơn.
Lỗi sai phổ biến nhất khi sử dụng giá trị Null là coi nó như 1 giá trị thông thường:
-
Sử dụng Null với các thuật toán thông thường dẫn đến giá trị không xác định
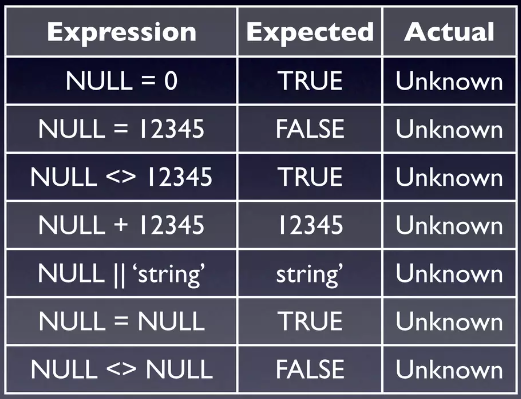
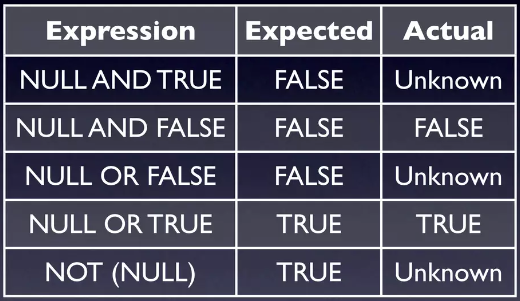
- Null không phải giá trị 0:
Select Null + 10-> Unknown - Null không phải 1 chuỗi rỗng:
Select "Bill"||Null-> Unknown - Null không phải giá trị False:
Select False or Null-> Unknown
- Null không phải giá trị 0:
-
Trái ngược với Null vẫn là Null:
Select * From Bugs Where create_by = 123Select * From Bugs Where not (create_by = 123)Cả 2 câu lệnh trên đều sẽ không lấy được trường hợp có Null
Giải pháp
- Hiểu rõ về Null trong các toán tử để không xảy ra trường hợp nhận về giá trị không mong muốn
-
SQL hỗ trợ hàm Is Null để kiểm tra các giá trị là Null, kết quả trả về là True hoặc False
Select * From Bugs Where create_by Is Null -
Thay thế bằng các giá trị khác, vd: -1, ...
Update Bugs Set create_by = -1 Where create_by Is NullCần lưu ý khi dùng với các hàm tính tổng (sum), hoặc tính trung bình (avg)
-
thay đổi Null thành giá trị thông thường theo yêu cầu với Coalesce()
2. Sử dụng Group 1 cách mơ hồ
Đặt vấn đề
Hãy cùng xem 1 vài ví dụ:
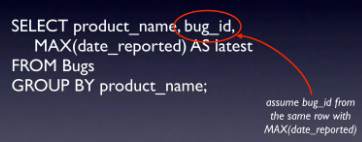
Trường hợp đầu tiên là kết quả trả về bug_id liệu có tương ứng với date ?
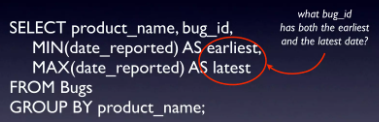
Trường hợp thứ 2 là querry cả ngày sớm nhất và muộn nhất thì sẽ phải trả về bug_id ứng với ngày nào ?

Trường hợp thứ 3 là không tìm được bug_id match với giá trị date
Trên đây là một vài lỗi thường gặp khi sử dụng Group by. Khi sử dụng hàm này chúng ta sẽ cần phải tuân theo một vài quy tắc gọi là Single-Value Rule:
- Phải là giá trị từ các hàm tổng hợp
- Là giá trị nằm trong hàm Group By
- Là giá trị phụ thuộc chức năng với giá trị nằm trong hàm Group By
Cần phải thỏa mãn ít nhất 1 điều kiên trên mới có thể querry khi dùng hàm Group By.
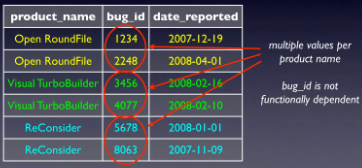
Có thể thấy cột bug_id không thỏa mãn các điều kiện trên
Vậy với các trường hợp ở ví dụ trên thì chúng ta sẽ có những phương án nào để xử lý.
Giải pháp
- Solution 1: Chỉ sử dụng các giá trị phụ thuộc
Chúng ta sẽ loại bỏ cột bug_id ở phần Select
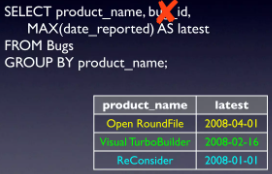
Qua đó ta sẽ thu được các giá trị chính xác. Nhưng nếu bắt buộc cần giá trị bug_id thì chúng ta có thể đến tiếp các phương án sau đây.
- Solution 2: Tạo thêm 1 bảng trích dẫn
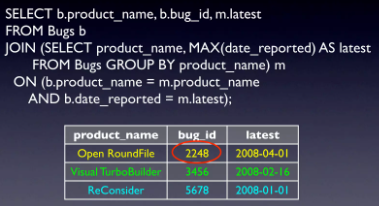
Tạo 1 bảng mới chỉ chứa các giá trị date_reported gần đây nhất sau đó join bảng này với bảng gốc, chỉ lấy giao của 2 bảng sẽ thu được các bug_id ứng với date tương ứng.
- Solution 3: Sử thêm 1 hàm tổng hợp

Có 1 lưu ý là phương án này chỉ cho ra kết quả đúng khi các bug_id sẽ tăng dần theo thời gian tạo. Nếu không, phương án này sẽ không khả dụng.
- Solution 4: Sử dụng hàm Group_concat()
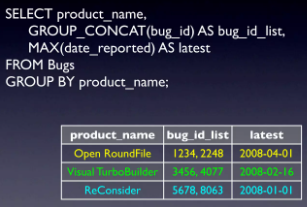
Ở phương án này giá trị bug_id được trả về sẽ không phải id tương ứng với date bên cạnh mà sẽ là 1 list các bug_id của product đó. Phương án này sẽ phù hợp với các bài toán muốn giữ nguyên tất cả các id và chỉ muốn lọc thời gian report.
3. Lấy giá trị ngẫu nhiên từ bảng
Bài toán đặt ra là lấy ngẫu nhiên 1 hàng trong bảng ở database ra.
Phương án nhiều người nghĩ ngay đến sẽ là sắp xếp cả bảng 1 cái ngẫu nhiên sau đó lấy ra hàng đầu tiên. Đây cũng là phương án dễ viết querry nhất nhưng cũng sẽ tốn tài nguyên nhất.

Nếu như bảng nhỏ thì việc sắp xếp cả bảng sẽ không quá ảnh hưởng nhưng nếu dữ liệu nhiều, việc sắp xếp tất cả sẽ tốn chi phí không cần thiết. Không những vậy, chúng ta sắp xếp cả bảng nhưng lại chỉ lấy 1 hàng đầu tiên và bỏ phí tất cả chỗ đằng sau. Việc này là không cần thiết. Hãy đến 1 vài phương án giúp tối ưu bài toán này hơn.
- Solution 1: Lấy ra list id, chọn ngẫu nhiên 1 giá trị và querry theo giá trị đó
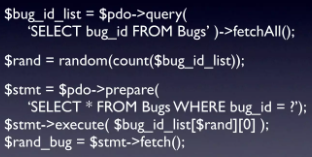
Trên đây là 1 đoạn code theo ngôn ngữ php. Đầu tiên chúng ra querry để lấy về list chứa tất cả các giá trị ở cột bug_id, sau đó lấy ngẫu nhiên 1 giá trị từ trong list đó. Cuối cùng chỉ cần tìm hàng có bug_id trùng với giá trị đó trong bảng database.
Một lưu ý là với những siêu dữ liệu thì list id nhận về cũng sẽ có kích thước lớn gây ra tốn chi phí lưu trữ.
- Solution 2: Chọn 1 giá trị bất kì từ 1 đến giá trị id lớn nhất trong bảng, dùng giá trị đó làm id để querry.
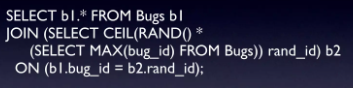
Ở đoạn code trên, chúng ta sẽ tìm ra Max của bug_id sau đó lấy random từ 1 đến max sau đó hàng có bug_id trùng với giá trị đó trong bảng database. Có thể thấy đây là 1 phương án khá đơn giản nhưng nó cũng có 1 điểm yếu lớn là chỉ có thể áp dụng nếu giá trị id ở các hàng là liền mạch, nối tiếp nhau, không có sự ngắt quãng.

Để khắc phục điểm yếu này, 1 phương án nâng cấp từ phương án này đã được đề xuất.
- Solution 3: Ý tưởng vẫn giống phương án 2 nhưng sau khi lấy ra 1 id ngẫu nhiên chúng ta sẽ tìm ra giá trị id nhỏ nhất mà lớn hơn id ngẫu nhiên kia sau đó mới querry hàng tương ứng.
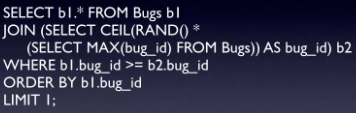
Phương án này khắc phục được hoàn toàn khuyết điểm của phương án trên nhưng vì phải có thêm 1 bước so sánh nên sẽ chậm hơn 1 chút. Vì vậy vẫn nên thử dùng phương án 2 trước, nếu không khả thì thì chuyển sang 3.
- Solution 4: Chọn 1 số ngẫu nhiên trong tổng số các hàng sau đó dùng hàm Offset để truy vấn bắt đầu từ hàng số đó.
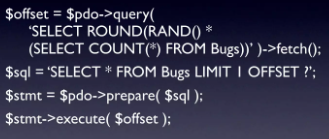
Phương án này có thể coi là phương án tối ưu nhất nhưng sẽ cần phải thực hiện truy vấn 2 lần.
4. Join hợp lý hơn
Đặt vấn đề
Có 3 lỗi/hiểu lầm thường gặp khi xử dụng Join:
- Join một cách vô tri, thừa thãi, nhiều cột không được dùng đến
- Phân tách ra quá nhiều lần Join (Join decomposition bị lạm dụng)
- Dùng hàm Join có khiến quá trình truy vấn bị chậm đi ?
Lí do sử dụng Join decomposition:
- Bộ nhớ cache và sử dụng lại các kết quả trước đó
- Giảm khóa trên nhiều bảng
- Phân phối bảng trên các máy chủ
- Tận dụng tối ưu hóa IN()
- Giảm các hàng dư thừa (tập hợp kết quả không chuẩn hóa)
Nhưng trong nhiều trường hợp thì nó đang bị lạm dụng quá đà gây giảm hiệu suất.
Giải pháp
Hãy cùng xem một vài ví dụ về antipattern này:

Chúng ta có thể thấy ở đây có 1 truy vấn khá là phức tạp và lặp lại nhiều bước không hợp lý. Với Join chúng ta có thể khiến nó đơn giản hơn.
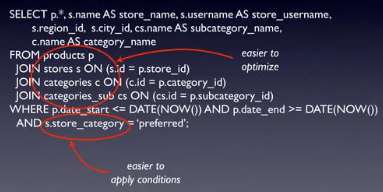
Một ví dụ khác:
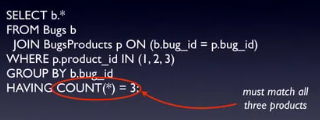 s
Đoạn truy vấn trên tuy có vẻ đơn giản nhưng sẽ tốn rất nhiều tài nguyên tính toán và ta có thể tối ưu nó khi dùng hàm Join
s
Đoạn truy vấn trên tuy có vẻ đơn giản nhưng sẽ tốn rất nhiều tài nguyên tính toán và ta có thể tối ưu nó khi dùng hàm Join

Ở cả 2 ví dụ trên ta đều có thể thấy nhiều hàm Join được dùng cạnh nhau. Nhưng nó vẫn là phương án tối ưu hơn các phương án trước đó. Từ đó ta có thể đưa ra một vài kết luận khi sử dụng Join:
- Join trong SQL cũng như While() đối với các ngôn ngữ khác.
- Quy tắc one-size-fit-all (Joins are slow) không chính sác, nó còn tuy thuộc vào các điều kiện Join và kích thước các bảng được Join
- Tối ưu hóa truy vấn khi dùng Join, hạn chế sử dụng Join lồng nhau, Join vừa đủ số lượng cần sử dụng. • Sử dụng các phương án thay thế (ví dụ: Join decomposition) như các trường hợp ngoại lệ, không nên lạm dụng.
Trên đây là một vài Antipatterns đơn giản và các xử lý chúng, ở phần sau của seri này mình sẽ chia sẻ tiếp những bài toán phức tạp hơn. Rất mong sẽ được mọi người đón nhận và góp ý.
Reference
https://www.r-5.org/files/books/computers/languages/sql/style/Bill_Karwin-SQL_Antipatterns-EN.pdf
All rights reserved
