
CycleGAN cho bài toán image-to-image translation
Bài đăng này đã không được cập nhật trong 5 năm
Introduction
Image-to-image translation là một lớp bài toán computer vision mà mục tiêu là học một ánh xạ giữa ảnh input và ảnh output. Bài toán này có thể áp dụng vào một số lĩnh vực như style transfer, tô màu ảnh, làm nét ảnh, sinh dữ liệu cho segmentation, face filter,...



Thông thường để huấn luyện một mô hình Image-to-image translation, ta sẽ cần một lượng lớn các cặp ảnh input và label. Ví dụ như: ảnh màu và ảnh grayscale tương ứng với nó, ảnh mờ và ảnh đã được làm nét, ....Tuy nhiên, việc chuấn bị dataset theo kiểu này có thể khá tốn kém trong một số trường hợp như: style transfer ảnh từ mùa hè sang mùa đông (kiếm được ảnh phong cảnh trong các điều kiện khác nhau), biến ngựa thường thành ngựa vằn (khó mà kiếm được ảnh của 1 con ngựa thường và ảnh của nó nhưng là ngựa vằn  ).
).
Do các bộ dataset theo cặp gần như là không tồn tại nên mới nảy sinh như cầu phát triển một mô hình có khả năng học từ dữ liệu unpaired. Cụ thể hơn là có thể sử dụng bất kỳ hai tập ảnh không liên quan và các đặc trưng chung được trích xuất từ mỗi bộ sưu tập và sử dụng trong quá trình image translation. Đây được gọi là bài toán unpaired image-to-image translation.
Một cách tiếp cận thành công cho unpaired image-to-image translation là CycleGAN.
CycleGAN architecture
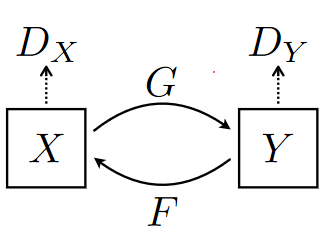
CycleGAN được thiết kế dựa trên Generative Adversarial Network (GAN). Kiến trúc GAN là một cách tiếp cận để huấn luyện một mô hình sinh ảnh bao gồm hai mạng neural: một mạng generator và một mạng discriminator. Generator sử dụng một vector ngẫu nhiên lấy từ latent space làm đầu vào và tạo ra hình ảnh mới và Discriminator lấy một bức ảnh làm đầu vào và dự đoán xem nó là thật (lấy từ dataset) hay giả (được tạo ra bởi generator). Cả hai mô hình sẽ thi đấu với nhau, Generator sẽ được huấn luyện để sinh ảnh có thể đánh lừa Discriminator và Discriminator sẽ được huấn luyện để phân biệt tốt hơn hình ảnh được tạo.
CycleGAN là một mở rộng của kiến trúc GAN cổ điển bao gồm 2 Generator và 2 Discriminator. Generator đầu tiên gọi là G, nhận đầu vào là ảnh từ domain X (ngựa vằn) và convert nó sang domain Y (ngựa thường). Generator còn lại gọi là Y, có nhiệm vụ convert ảnh từ domain Y sang X. Mỗi mạng Generator có 1 Discriminator tương ứng với nó
- : phân biệt ảnh lấy từ domain Y và ảnh được translate G(x).
- : phân biệt ảnh lấy từ domain X và ảnh được translate F(y).
Generator
Generator của CycleGAN dựa trên được lấy từ paper này, bao gồm 3 thành phần: encoder, transformer và decoder
 Phần encoder bao gồm 3 lớp tích chập, 2 lớp sau có stride = 2 để làm giảm kích thước đầu vào của ảnh và tăng số channel. Output của encoder được sử dụng làm đầu vào cho transformer bao gồm 6 khối residual như trong resnet. Lớp batch normalization trong khối residual được thay bằng instance normalization. Cuối cùng phần decoder bao gồm 3 lớp transposed convolution sẽ biến đổi ảnh về kích thước ban đầu và số channel phụ thuộc vào domain đầu ra.
Phần encoder bao gồm 3 lớp tích chập, 2 lớp sau có stride = 2 để làm giảm kích thước đầu vào của ảnh và tăng số channel. Output của encoder được sử dụng làm đầu vào cho transformer bao gồm 6 khối residual như trong resnet. Lớp batch normalization trong khối residual được thay bằng instance normalization. Cuối cùng phần decoder bao gồm 3 lớp transposed convolution sẽ biến đổi ảnh về kích thước ban đầu và số channel phụ thuộc vào domain đầu ra.
Discriminator
Discriminator sử dụng kiến trúc PatchGAN. Thông thường trong bài toán classification, output của mạng sẽ là một giá trị scalar - xác suất thuộc class nào đó. Trong mô hình CycleGAN, tác giả thiết kế Discriminator sao cho output của nó là một feature map . Có thể xem là Discriminator sẽ chia ảnh đầu vào thành 1 lưới và giá trị tại mỗi vùng trên lưới sẽ là xác suất để vùng tương ứng trên ảnh là thật hay giả.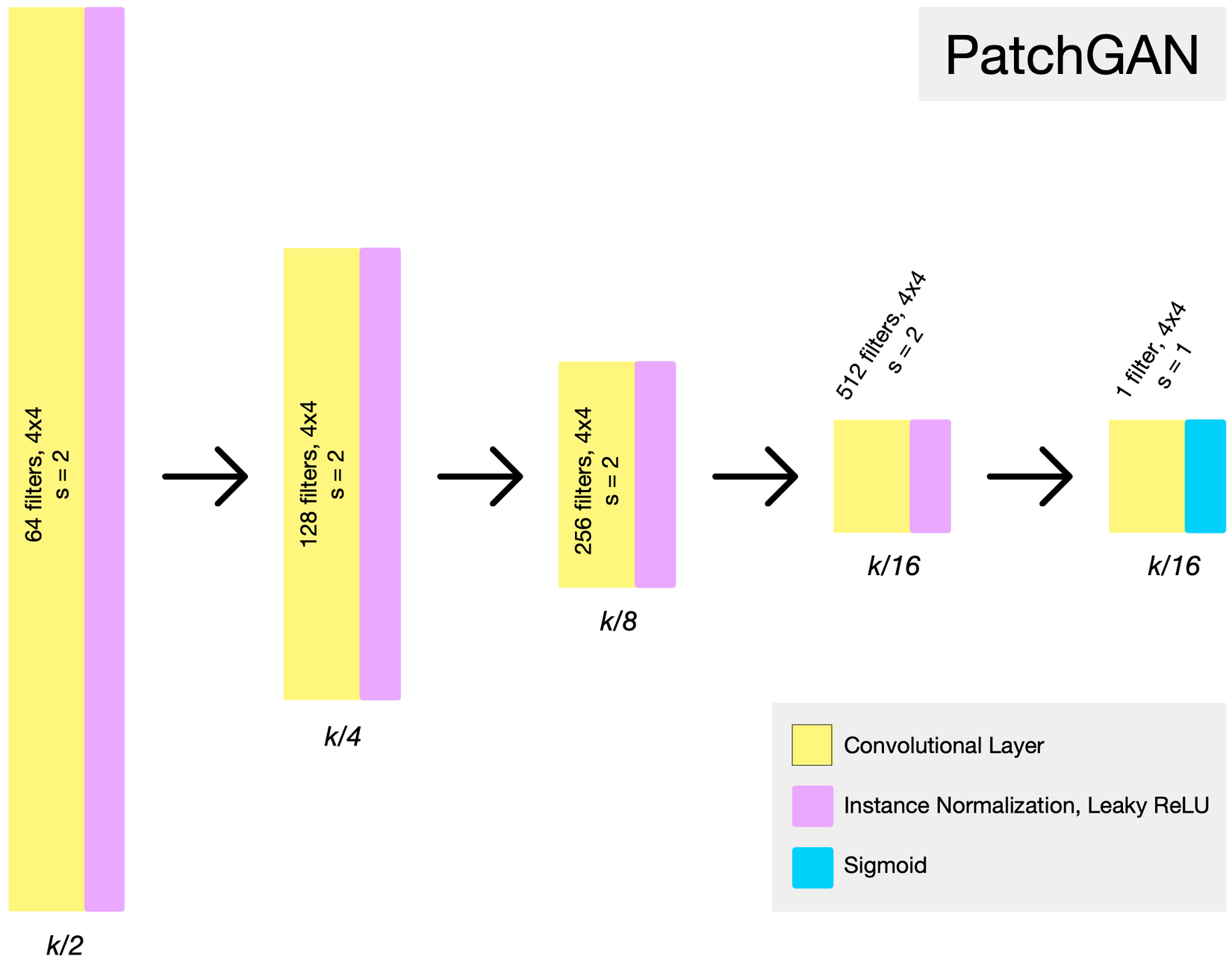
Loss function
Adversarial loss
Trong quá trình huấn luyện, generator G cố gắng tối thiểu hóa hàm adversarial loss bằng cách translate ra ảnh G(x) (với x là ảnh lấy từ domain X) sao cho giống với ảnh từ domain Y nhất, ngược lại Discriminator cố gắng cực đại hàm adversarial loss bằng cách phân biệt ảnh G(x) và ảnh thật y từ domain
Adversarial loss được áp dụng tương tự đối với generator F và Discriminator
Cycle consistency loss
Chỉ riêng adversarial loss là không đủ để mô hình cho ra kết quả tốt. Nó sẽ lai generator theo hướng tạo ra được ảnh output bất kỳ trong domain mục tiêu chứ không phải output mong muốn. Ví dụ với bài toán biến ngựa vằn thành ngựa thường, generator có thể biến con ngựa vằn thành 1 con ngựa thường rất đẹp nhưng lại không có đặc điểm nào liên quan tới con ngựa vằn ban đầu.
Để giải quyết vấn đề này, cycle consistency loss được giới thiệu. Trong paper, tác giả cho rằng nếu ảnh x từ domain X được translate sang domain Y và sau đó translate ngược lại về domain Y lần lượt bằng 2 generator G, F thì ta sẽ được ảnh x ban đầu:
Full loss
trong đó là siêu tham số và được chọn là 10.
Một số kết quả
Style transfer tranh vẽ sang ảnh chụp

Ngựa vằn sang ngựa thường

Táo thành cam

Mặt người thành búp bê


References
All rights reserved
