Machine Learning thật thú vị (2): Tạo sách văn học và game Mario
Bài đăng này đã không được cập nhật trong 4 năm
Trong phần 1, chúng ta đã đề cập đến việc Học Máy đã sử dụng các thuật toán chung chung để tìm ra những điều thú vị về dữ liệu bạn có mà không cần phải viết những dòng mã cụ thể để giải quyết bài toán của bạn.
Trong phần này, chúng ta sẽ dành thời gian tìm hiểu một thuật toán làm được những điều rất thú vị - tạo nên một trò chơi thực sự giống như được tạo bởi con người. Chúng ta sẽ xây dựng một mạng nơron tự tạo văn bản từ tập văn bản khác hay thậm chí cả game Mario từ một tập hợp game có sẵn cho trước

Đưa ra những dự đoán thông minh hơn
Trong phần 1, chúng ta đã tạo một thuật toán đơn giản để dự đoán giá trị của một ngôi nhà dựa trên các đặc điểm của nó. Ví dụ về một ngôi nhà với những thông tin sau:
| Số phòng ngủ | Diện tích | Khu đô thị | Giá bán |
|---|---|---|---|
| 3 | 2000 | Royal City | ??? |
Giống như phần 1, chúng ta viết một hàm lượng giá cơ bản sau:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 0.123
# and a big pinch of that
price += sqft * 0.41
# maybe a handful of this
price += neighborhood * 0.57
return price
Chúng ta đã ước lượng giá trị của ngôi nhà dựa trên trọng số của các thuộc tính của ngôi nhà. Đồ thị sau sẽ biểu diễn chức năng này:
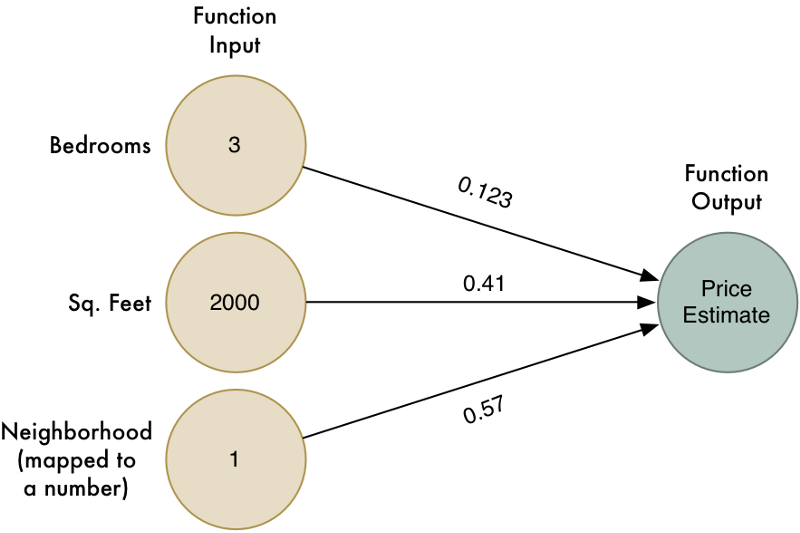 Tuy nhiên thuật toán này chỉ có thể hoạt động với những vấn đề đơn giản mà kết quả có mối quan hệ tuyến tính với dữ liệu đầu vào. Điều gì sẽ xảy ra nếu giá ngôi nhà thực sự không đơn giản như vậy. Ví dụ, khu vực lân cận có ảnh hưởng nhiều với những ngôi nhà có kích thước to hay nhà bé, nhưng lại không ảnh hưởng tới những ngôi nhà có kích thước trung bình. Làm thế nào chúng ta có thể nắm bắt được những loại chi tiết phức tạo trong mô hình của chúng ta.
Tuy nhiên thuật toán này chỉ có thể hoạt động với những vấn đề đơn giản mà kết quả có mối quan hệ tuyến tính với dữ liệu đầu vào. Điều gì sẽ xảy ra nếu giá ngôi nhà thực sự không đơn giản như vậy. Ví dụ, khu vực lân cận có ảnh hưởng nhiều với những ngôi nhà có kích thước to hay nhà bé, nhưng lại không ảnh hưởng tới những ngôi nhà có kích thước trung bình. Làm thế nào chúng ta có thể nắm bắt được những loại chi tiết phức tạo trong mô hình của chúng ta.
Để thuật toán thông minh hơn, chúng ta có thể chạy thuật toán này nhiều lần với nhiều trọng số khác nhau:
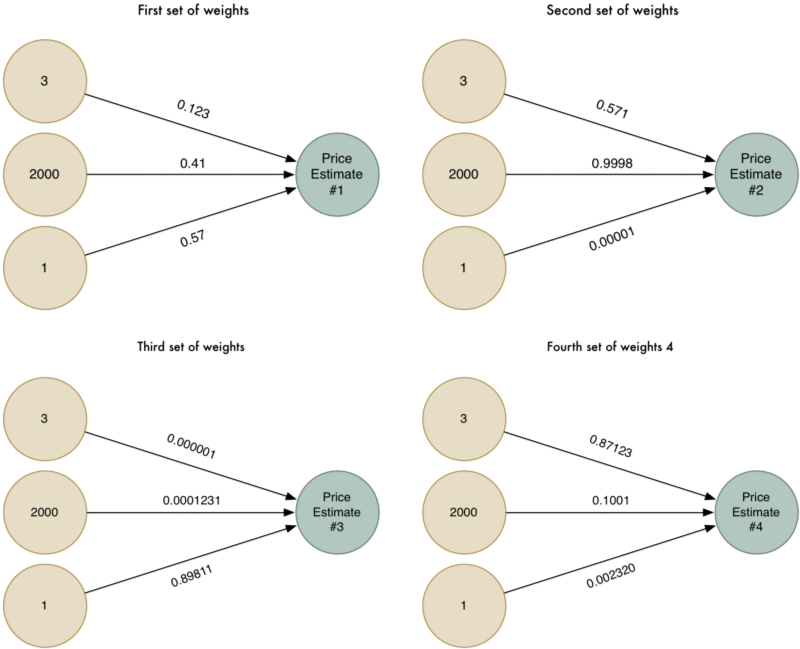 Giờ chúng ta có 4 giá trị ước lượng khác nhau. Chúng ta lại chạy lại thuật toán ban đầu cho 4 giá trị mới này để tìm trọng số cho những biến mới này và tạo ra kết quả cuối cùng.
Giờ chúng ta có 4 giá trị ước lượng khác nhau. Chúng ta lại chạy lại thuật toán ban đầu cho 4 giá trị mới này để tìm trọng số cho những biến mới này và tạo ra kết quả cuối cùng.
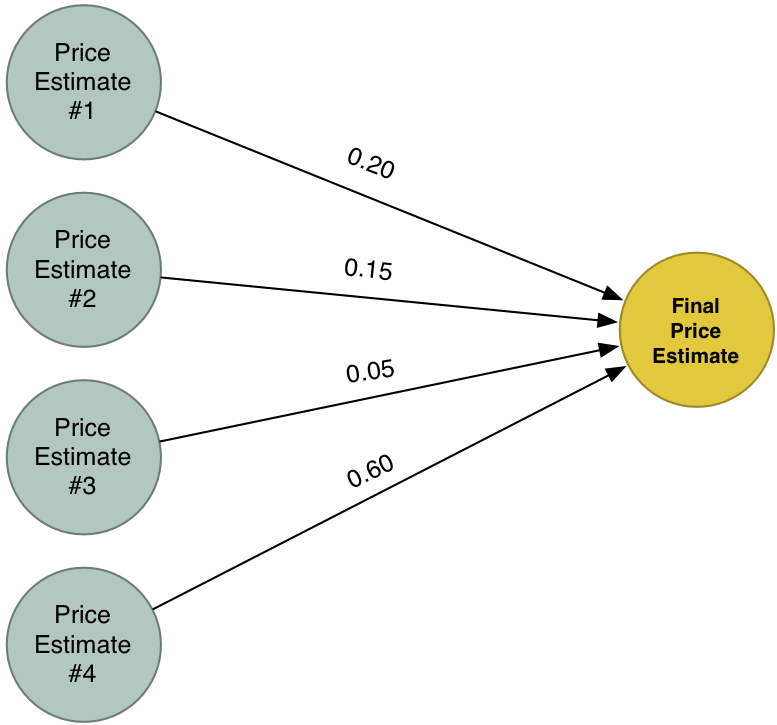 Kết quả cuối cùng này tổng hợp kết quả từ 4 mô hình khác nhau để giải quyết vấn đề. Mô hình nhiều lớp áp dụng thuật toán như này có thể giải quyết những bài toán khó hơn
Kết quả cuối cùng này tổng hợp kết quả từ 4 mô hình khác nhau để giải quyết vấn đề. Mô hình nhiều lớp áp dụng thuật toán như này có thể giải quyết những bài toán khó hơn
Mạng nơron thần kinh là gì?
Kết nối toàn bộ quy trình trên ta có đồ thị kết hợp như sau:
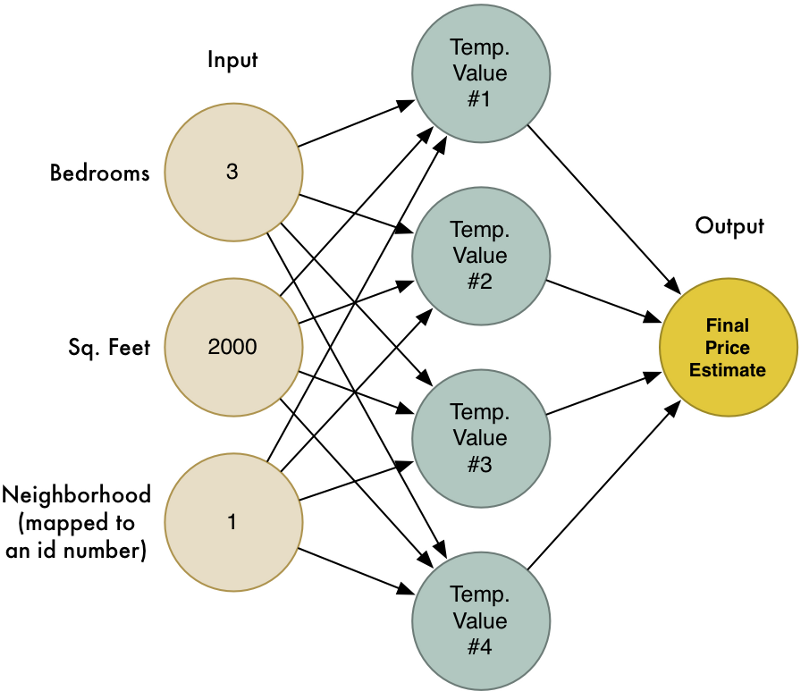
Đây chính là mạng nơron thần kinh!
Mỗi nơron sẽ chứa các giá trị đầu vào, áp dụng trọng số cho chúng và tính toán được kết quả đầu ra. Bằng cách kết nối nhiều tầng nơron với nhau, chúng ta có thể mô hình hóa các chức năng phức tạp.
Ý tưởng đơn giản trên có thể được diễn đạt lại theo cách sau:
- Chúng ta tạo nên những hàm dự đoán đơn giản, thực hiện tính toán bằng cách nhân giá trị mỗi nơron với trọng số tương ứng của nó. Mỗi hàm đơn giản này được gọi là một tế bào thần kinh.
- Kết nối nhiều tế bào thần kinh đơn giản lại với nhau, chúng ta xây đựng được một mạng thần kinh để mô hình hóa nhiều bài toán phức tạp mà một tế bào thần kinh không làm được.
Tư tưởng trên giống như bộ ghép hình LEGO. Chúng ta không thể tạo mô hình với chỉ 1 mảnh ghép, nhưng bằng cách kết hợp nhiều mảnh ghép với nhau, ta có thể tạo nên robot, máy bay, xe tăng...
Tự động tạo văn bản mới
Cung cấp bộ nhớ cho mạng thần kinh (NN)
Mạng thần kinh trên luôn luôn trả về kết quả giống nhau với những tập dữ liệu đầu vào giống nhau. Nó không có bộ nhớ. Trong thuật ngữ lập trình, đó là một thuật toán phi trạng thái.
Trong nhiều trường hợp (giống như ước lượng giá trị ngôi nhà), đó chính xác là điều bạn mong muốn. Nhưng một việc mà loại mô hình này không thể làm là đáp ứng với các mô hình dữ liệu theo thời gian.
Tưởng tượng tôi đưa cho bạn một bàn phím và yêu cầu bạn viết một câu chuyện. Nhưng trước khi bạn bắt đầu, tôi sẽ dự đoán ký tự đầu tiên bạn sẽ gõ. Tôi nên đoán đó là chữ gì?
Tôi có thể sử dụng kiến thức về tiếng Anh của mình để nâng cao tỉ lệ đoán đúng của tôi. Ví dụ, bạn có thể chọn gõ một ký tự thông dụng. Nếu tôi đã xem qua những câu chuyện bạn viết trước đó, tôi có thể dựa trên xác suất những từ bạn thường sử dụng đầu câu chuyện để thu hẹp tập kết quả dự đoán hơn, và xây dựng một mạng thần kinh để mô hình hóa khả năng bạn sẽ bắt đầu một lá thư với ký tự nào.
Mô hình của tôi có thể như sau:
 Nhưng giờ hãy làm vấn đề này khó khăn hơn. Làm sao để tôi có thể dự đoán ký tự tiếp theo bạn sẽ gõ tại bất kỳ thời điểm nào trong câu chuyện của bạn. Đây quả là một vấn đề thú vị hơn nhiều.
Nhưng giờ hãy làm vấn đề này khó khăn hơn. Làm sao để tôi có thể dự đoán ký tự tiếp theo bạn sẽ gõ tại bất kỳ thời điểm nào trong câu chuyện của bạn. Đây quả là một vấn đề thú vị hơn nhiều.
Thử lấy ví dụ về câu văn của Hemingway như sau:
Robert Cohn was once middleweight boxi
Ký tự nào sẽ xuất hiện tiếp theo?
Bạn có thể sẽ đoán chữ "n" - có vẻ như là chữ boxing. Chúng ta dự đoán điều này dựa trên từ ngữ trong câu và hiểu biết của chúng ta về ngôn ngữ trong tiếng Anh. Hơn nữa, từ middleweight cũng cung cấp thêm gợi ý là chúng ta đang nói về boxing.
Nói một cách khác, thật dễ để đoán ký tự tiếp theo nếu chúng ta biết chuỗi ký tự trước đó.
Recurrent Neural Network - mạng nơron hồi quy
Để giải quyết vấn đề này với mạng thần kinh, chúng ta cần đặt thêm trạng thái vào mô hình của chúng ta. Mỗi lần sử dụng mạng thần kinh, chúng ta có thể lưu trữ kết quả tính toán và tái sử dụng chúng vào những lần tiếp theo như là một dữ liệu đầu vào. Bằng cách đó, mô hình của chúng ta sẽ điều chỉnh dự đoán dựa trên những đầu vào gần đây.
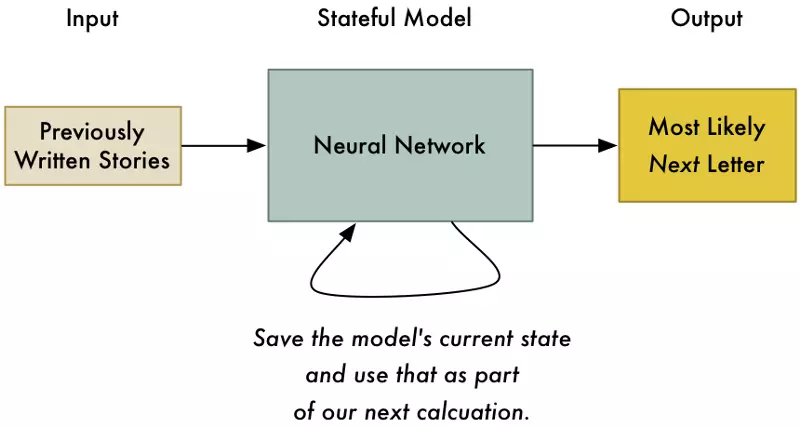 Việc đặt thêm trạng thái vào trong mô hình của chúng ta không chỉ giúp dự đoán chữ cái đầu tiên khả thi nhất trong câu chuyện, mà còn có khả năng dự đoán chữ cái có khả năng xuất hiện tiếp theo dựa trên tất cả các chữ cái đã xuất hiện trước đó.
Việc đặt thêm trạng thái vào trong mô hình của chúng ta không chỉ giúp dự đoán chữ cái đầu tiên khả thi nhất trong câu chuyện, mà còn có khả năng dự đoán chữ cái có khả năng xuất hiện tiếp theo dựa trên tất cả các chữ cái đã xuất hiện trước đó.
Đây là ý tưởng cơ bản về Recurrent Neural Network (RNN - mạng nơron hồi quy). Chúng ta cập nhật trạng thái mỗi khi chúng ta sử dụng mạng. Điều này cho phép mạng cập nhật các dự đoán dựa trên những trạng thái gần nhất. Mạng hồi quy thậm chí có thể mô hình hóa các khuôn mẫu theo thời gian, miễn là chúng ta cung cấp đủ bộ nhớ.
Vai trò của một ký tự?
Việc dự đoán ký tự tiếp theo trong một câu chuyện dài có vẻ như khá ít ứng dụng. Nhưng mục đích ở đây là gì? Một ứng dụng khá thú vị là tự động dự đoán các ký tự sẽ được gõ trên màn hình điện thoại.
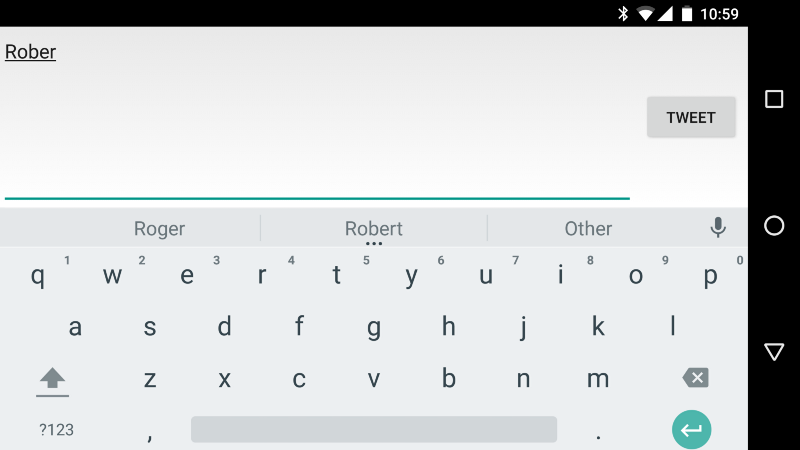
Nhưng ý tưởng tuyệt vời ở đây là: Nếu, nếu chúng ta có thể tạo ra mô hình dự đoán từ ngữ tiếp theo liên tục, lặp đi lặp lại mãi mãi. Liệu chúng ta có thể tạo ra một câu chuyện hoàn chỉnh?
Viết ra một câu chuyện
Trước đó chúng ta đã bắt đầu với việc dự đoán một ký tự tiếp theo trong một câu văn của Hemingway. Bây giờ hãy thử sức để tạo nên một câu chuyện hoàn chỉnh theo phong cách Hemingway.
Để làm được điều này, chúng ta sẽ sử dụng cài đặt mạng nơron hồi quy được viết bởi Andrej Karpathy - một nhà nghiên cứu về Deep Learning ở Stanford.
Deep Learning
Deep Learning là một trong những mảng phát triển nhất của Machine Learning. Có thể hiểu đơn giản Deep Learning là mạng nơron đa lớp có cấu trúc đặc biệt.
Recurrent Neural Network - RNN (mạng nơron hồi quy), Convolutional Neural Network- CNN (mạng tích chập) hay Deep Convolutional Generative Adversarial Networks - DCGANs (mạng đối kháng sinh mẫu tích chập đa lớp) đều là các thuật toán trong Deep Learning
Ở mạng nơron đa lớp thường, giá trị đầu ra của lớp này là đầu vào của lớp tiếp theo, và các lần chạy mạng với các giá trị truyền vào độc lập với nhau. Ở mạng RNN, mạng nơron ở mỗi lần chạy được lưu trạng thái, và sử dụng ở lần chạy tiếp theo. Ở mạng CNN, các đặc trưng của giá trị truyền vào được trích lọc bằng chuỗi phương pháp như tích chập, giảm mẫu, kết nối mạng trước khi phân nhóm.
Chúng ta sẽ tạo nên một mô hình từ một văn bản hoàn thiện "The Sun Also Rise" - 362.239 ký tự, sử dụng 84 ký tự khác nhau (bao gồm cả dấu chấm câu, chữ hoa, chữ thường, ...). Tập dữ liệu này vẫn nhỏ khi so sánh với các dứng dụng thực tế điển hình. Để tạo ra một mô hình thực sự tốt theo phong cách của Hemingway, sẽ tốt hơn nếu chúng ta có lượng dữ liệu gấp vài lần như trên. Nhưng từng đó cũng khá ổn cho ví dụ chúng ta đang tiến hành.
Khi chúng ta mới bắt đầu huấn luyện RNN, nó dự đoán các ký tự không tốt. Dưới đây là những gì nó tạo ra sau 100 vòng huấn luyện.
hjCTCnhoofeoxelif edElobe negnk e iohehasenoldndAmdaI ayio pe e h’e btentmuhgehi bcgdltt. gey heho grpiahe. Ddelnss.eelaishaner” cot AAfhB ht ltny ehbih a”on bhnte ectrsnae abeahngy amo k ns aeo?cdse nh a taei.rairrhelardr er deffijha
Bạn có thể thấy RNN nhận ra rằng một vài từ có khoảng trống, và mới chỉ được như vậy thôi.
Sau 1000 vòng lặp huấn luyện, kết quả thu được trông rất hứa hẹn:
hing soor ither. And the caraos, and the crowebel for figttier and ale the room of me? Streat was not to him Bill-stook of the momansbed mig out ust on the bull, out here. I been soms inick stalling that aid. “Hon’t me and acrained on .Hw’s don’t you for the roed,” In’s pair.” “Alough marith him.”
Mô hình đã bắt đầu xác định được các khuôn mẫu của một cấu trúc câu cơ bản. Các dấu chấm câu đã được tạo ra, thậm chí cả những trích dẫn. Tuy nhiên, nhiều từ vẫn còn chưa có nghĩa.
Nhưng sau vài nghìn lần huấn luyện lặp lại, kết quả thu được thực sự rất tốt:
He went over to the gate of the café. It was like a country bed. “Do you know it’s been me.” “Damned us,” Bill said. “I was dangerous,” I said. “You were she did it and think I would a fine cape you,” I said. “I can’t look strange in the cab.” “You know I was this is though,” Brett said. “It’s a fights no matter?” “It makes to do it.” “You make it?” “Sit down,” I said. “I wish I wasn’t do a little with the man.” “You found it.” “I don’t know.” “You see, I’m sorry of chatches,” Bill said. “You think it’s a friend off back and make you really drunk.”
Ở thời điểm này, thuật toán đã tìm ra cấu trúc những mẫu hội thoại ngắn của Hemingway. Một vài câu thậm chí còn có ý nghĩa
Thử so sánh với một đoạn văn thực tế trong cuốn sách:
There were a few people inside at the bar, and outside, alone, sat Harvey Stone. He had a pile of saucers in front of him, and he needed a shave. “Sit down,” said Harvey, “I’ve been looking for you.” “What’s the matter?” “Nothing. Just looking for you.” “Been out to the races?” “No. Not since Sunday.” “What do you hear from the States?” “Nothing. Absolutely nothing.” “What’s the matter?”
Thậm chí, chỉ bằng việc nhìn vào từng ký tự một, thuật toán đã có thể tạo ra các câu khá ổn. Đây là một điều hết sức tuyệt vời.
Và chúng ta cũng không cần phải tạo ra một văn bản ngay từ ký tự đầu tiên. Chúng ta có thể cung cấp cho thuật toán một vài chữ cái đầu tiên và để chúng tự hoàn thiện phần tiếp theo.
Hãy thử tạo nên một bìa sách từ thuật toán trên dựa trên cuốn sách chính cuốn sách của Hemingway và các ký tự ban đầu là: "Er", "He" và "The S":
 Kết quả không tồi phải không!
Kết quả không tồi phải không!  )
)
Nhưng phần tuyệt diệu nhất là thuật toán có thể tìm ra mẫu cấu trúc trong bất kỳ dữ liệu nào, không chỉ ở trong ngôn ngữ mà thậm chí cả trong những trò chơi quen thuộc nữa.
Tự sáng tạo trò chơi Mario
Xử lý dữ liệu
Năm 2015, Nintendo công bố Super Mario Maker cho hệ thống trò chơi Wii U.
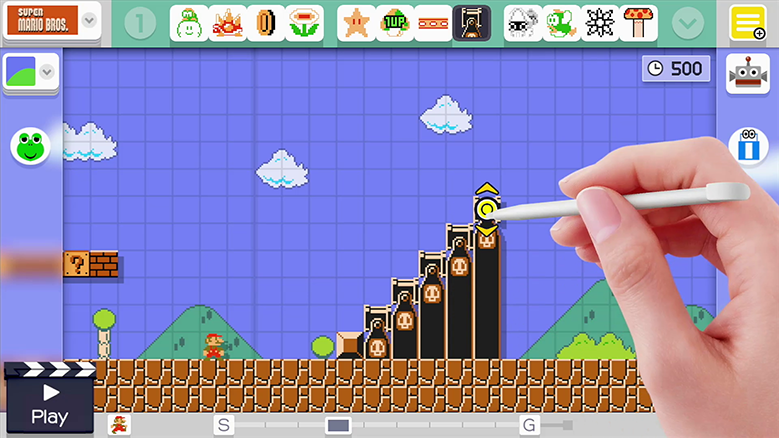 Hệ thống này cho phép bạn tự vẽ ra những mức độ của game Mario trên máy tính bảng, upload chúng lên internet và chia sẻ với bạn bè. Nó giống như bộ LEGO ảo cho mọi người để dựng lên các level Mario như ý.
Hệ thống này cho phép bạn tự vẽ ra những mức độ của game Mario trên máy tính bảng, upload chúng lên internet và chia sẻ với bạn bè. Nó giống như bộ LEGO ảo cho mọi người để dựng lên các level Mario như ý.
Liệu chúng ta có thể sử dụng mô hình đã tạo ra những đoạn văn bản Hemingway và tạo ra trò chơi Mario?
Đầu tiên, chúng ta cần dữ liệu đào tạo cho mô hình. Ta cùng nhau sưu tập tất cả mức độ từ trò chơi Mario nguyên bản từ năm 1985:
 .
.
Thế hệ nguyên bản này có 32 mức độ và khoảng 70% có cùng một lối thoát giống nhau. Để lấy được thiết kế của mỗi mức độ, tôi sao chép bản gốc và viết một chương trình lấy tất cả thiết kế từ bộ nhớ trò chơi.
Đây là mức độ đầu tiên trong trò chơi (và chắc bạn vẫn sẽ nhớ, nếu bạn đã từng chơi game Mario):
 Nếu chúng ta nhìn kĩ hơn, chúng ta có thể thấy mỗi mức độ là mạng lưới những vật thể:
Nếu chúng ta nhìn kĩ hơn, chúng ta có thể thấy mỗi mức độ là mạng lưới những vật thể:
 Chúng ta có thể dễ dàng chuyển mạng lưới này thình chuỗi các ký tự với mỗi ký tự đại diện cho một vật thể
Chúng ta có thể dễ dàng chuyển mạng lưới này thình chuỗi các ký tự với mỗi ký tự đại diện cho một vật thể
--------------------------
--------------------------
--------------------------
#??#----------------------
--------------------------
--------------------------
--------------------------
-##------=--=----------==-
--------==--==--------===-
-------===--===------====-
------====--====----=====-
=========================-
Màu sắc không có sự liên quan ở đây, do mình để chế độ code nên ký tự tự động chuyển màu
Chúng ta đã thay thế mỗi vật thể bằng 1 ký tự khác nhau
- "-" là một khoảng trống
- "=" là một khối đá
- "#" là một khối đã có thể đập vỡ
- "?" là một khối chứa tiền
- Các ký tự khác đại diện cho các vật thể khác nữa

Nhìn vào tập ký tự, bạn có thể thấy rằng các mức độ Mario không thật sự có nhiều cấu trúc nếu bạn đọc chúng từng dòng một

Cấu trúc ở mỗi mức độ thực sự thay đổi nếu bạn nghĩ mỗi mức độ là tập hợp của các cột

Vì thế, để tạo ra thuật toán tìm cấu trúc phù hợp, chúng ta cần truyền dữ liệu vào theo cột. Tìm ra cách hữu hiệu nhất để đại diện cho tập dữ liệu (Feature Selection - lựa chọn đặc trưng) là một trong những yếu tố quyết định để tạo ra thuật toán tốt.
Để đào tạo cho mô hình, tôi cần quay tập ký tự một góc 90 độ. Điều đó giúp cho các ký tự được truyền vào tập dữ liệu theo chiều có thể dễ dàng nhận thấy đặc trưng của dữ liệu.
-----------=
-------#---=
-------#---=
-------?---=
-------#---=
-----------=
-----------=
----------@=
----------@=
-----------=
-----------=
-----------=
---------PP=
---------PP=
----------==
---------===
--------====
-------=====
------======
-----=======
---=========
---=========
Đào tạo mô hình
Như chúng ta đã thấy khi tạo ra mô hình Hemingway, một mô hình sẽ tốt lên khi chúng ta đào tạo nó.
Sau một vài lần đào tạo, mô hình của chúng ta tạo ra một mớ hỗn độn:
--------------------------
LL+<&=------P-------------
--------
---------------------T--#--
-----
-=--=-=------------=-&--T--------------
--------------------
--=------$-=#-=-_
--------------=----=<----
-------b
-
Chương trình đã có ý tưởng rằng "-" và "=" nên hiển thị rất nhiều, nhưng đó là toàn bộ những gì mạng nơron hồi quy (RNN) biết. RNN vẫn chưa tìm ra được cấu trúc rõ ràng.
Sau vài nghìn lần đào tạo, một số cấu trúc đã hình thành:
--
-----------=
----------=
--------PP=
--------PP=
-----------=
-----------=
-----------=
-------?---=
-----------=
-----------=
Mô hình đã nhận ra rằng mỗi dòng nên có cùng độ dài, thậm chí tìm ra nguyên lý của Mario: Những ống Mario luôn có độ dài 2 ký tự, rộng 2 ký tự. Vì thế, ký tự "P" luôn luôn ở cùng vùng 2x2. Mọi thứ đã bắt đầu thú vị hơn.
Cùng với rất nhiều lần đào tạo nữa, mô hình cuối cùng cũng đã tạo được dữ liệu chuẩn gần như hoàn hảo.
--------PP=
--------PP=
----------=
----------=
----------=
---PPP=---=
---PPP=---=
----------=
Dưới đây là một mức độ Mario được tạo ra hoàn toàn từ mô hình rồi quay ngang:
 Thật là vi diệu! Có một số điểm rất đáng chú ý. Mô hình đã:
Thật là vi diệu! Có một số điểm rất đáng chú ý. Mô hình đã:
- đưa Lakitu (quái vật trên mây) ở ngay khởi điểm của mức độ - giống như trò chơi Mario thật vậy
- biết các ống phải nổi trên mấy hoặc nằm trên khối đá
- đặt quái vật ở những vị trí hợp lý
- không tạo ra bất cứ cản trở nào mà người chơi không thể tiếp tục
- có thể cảm nhận như là một trò chơi thực sự từ game Mario
Giờ là lúc chúng ta chuyển những ký tự thành hình khối chuẩn:
 Và chơi trên chính mô hình chúng ta đã tạo ra:
Và chơi trên chính mô hình chúng ta đã tạo ra:
Trò chơi và những ứng dụng thực tế
Mạng nơron hồi quy (RNN) ta dùng để huấn luyện mô hình cũng giống với những loại thuật toán mà các công ty trên thực tế sử dụng để giải quyết các vấn đề khó như: nhận dạng giọng nói và dịch ngôn ngữ. Điều phân tách mô hình giữa trò chơi hay ứng dụng thực tế là dữ liệu đào tạo.
Nếu chúng ta có thể truy cập vào hàng trăm ngàn mức độ Mario mà người sử dụng đã tạo ra, chúng ta có thể tạo ra một mô hình tuyệt diệu. Nhưng không, Nintendo sẽ không cho phép chúng ta truy cập chúng. Công ty lớn không cho không dữ liệu của họ.
Khi học máy trở nên quan trọng hơn trong các lĩnh vực, sự khác biệt giữa một chương trình tốt và không tốt sẽ là lượng dữ liệu được cung cấp để huấn luyện các mô hình. Đó cũng là lý do vì các công ty như Gooogle, Facebook rất cần dữ liệu từ chính bạn.
Ví dụ, Google đã mở mã nguồn TensorFlow, một ứng dụng cho phép xây dựng chương trình học máy hiệu quả. Đây cũng chính là công nghệ đã làm nên Google Dịch. Đó thực sự là một bước tiến lớn khi mỗi người đều có thể truy cập ứng dụng cực hữu hiệu miễn phí.
Tuy thế, nếu không có dữ liệu ngôn ngữ khổng lồ như Google, bạn sẽ không thể trở thành một đối thủ cạnh tranh trong lĩnh vực dịch ngôn ngữ này. Dữ liệu là điều làm nên sự khác biệt.
Nguồn bài viết
Bài gốc: Machine Learning is Fun (part 2) Tác giả Nguyễn Đức Vinh đã dịch phần ứng dụng RNN vào tự tạo văn bản trong bài dưới đây. Sau khi hỏi ý kiến tác giả, mình đã sử dụng bài viết như nguồn tư liệu trong bài
Nếu các bạn thấy hứng thú với series này, các bạn có thể follow mình hoặc clip series để nhận được thông báo khi có bản dịch mới nhất. Series hiện có 8 bài, những bản dịch tiếp theo sẽ được cập nhật dần dần.
All rights reserved
