Bài 2 - Feature extraction from text
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào các bạn, trong bài viết này mình xin nói về việc biến đổi các token đã tách được từ input text sang features. Điều này là khá quan trọng trong việc tạo ra các đặc trưng đầu vào để train các mô hình NLP.
Transform token into features
Bag of words
Một trong những cách tốt để transform token thành các features, cũng là phương pháp mang ý tưởng cốt lõi cho các phương pháp transform token into features về sau là kỹ thuật Bag of Words. Ý tưởng của kỹ thuật này là việc tính các biến cố xảy ra của các token cụ thể trong input text của chúng ta.
Cách thực hiện của kỹ thuật này như sau: Chúng ta sẽ tìm kiếm các từ đã xuất hiện trong một câu và đánh dấu chúng bằng giá trị 1, các từ không xuất hiện thì đánh dấu chúng bằng giá trị 0.
Cùng xem ví dụ về 3 câu review sau:

Bây giờ, chúng ta sẽ tìm kiếm tất cả các token có thể trong documents của chúng ta. Viết chúng thành tiêu đề của các cột trong ma trận, các hàng sẽ là giá trị mark đánh dấu các xem việc các token đấy có xuất hiện trong các câu reivew với số thứ tự tương ứng với hàng hay không. Khi đó ta sẽ có một ma trận feature tương đối lớn. Đây là cách mà chúng ta dịch được các câu text sang một vector tương ứng với câu review.
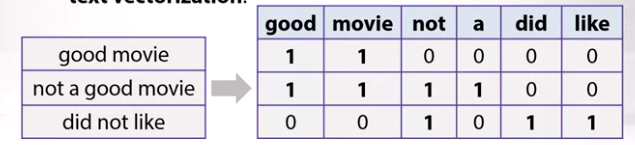
Đây được gọi là text vectorization.
Tuy nhiên với phương pháp này, nó tồn tại nhiều vấn đề bất lợi:
- Đầu tiên là thứ tự các token không được giữ nguyên, điều này ảnh hưởng đến ngữ nghĩa của câu. Đó là lý do tại sao chúng ta gọi là bag of words bởi bag là không mang ý nghĩa thứ tự.
- Thứ hai, các counter (bộ đếm) ko được chuẩn hóa và mang ý nghĩa không cao.
Để giải quyết hai vấn đề này, một phương pháp mới được đưa ra với mục đích duy trì được thứ tự của các token.
TF-IDF
Trên thực tế, cách tốt nhất để duy trì được thứ tự của các token đó là việc quan tâm đến các cặp token, bộ ba token liên tiếp, hoặc hơn thế nữa thay vì chỉ quan tâm đến một token duy nhất. Cách tiếp cận này được gọi là extracting n-grams. 1-gram tương ứng với 1 token, 2-gram tương ứng với 2 token, và cứ tiếp tục như thế.
Hãy cùng xem cách thực hiện của phương pháp này.
Chúng ta vẫn có cùng 3 câu review. Bây giờ các cột ko phải chỉ là 1 token riêng biệt mà bây giờ là một cặp token. Và các câu reivew cũng được chuyển sang dạng vector một cách tương ứng với phương pháp Bag of words, với giá trị 1 / 0 thể hiện cho việc cặp token có xuất hiện / ko xuất hiện trong câu review tương ứng hay không.
Hãy để ý ở đây, cách biểu diễn ở mức này mới chỉ đưa ra được mối quan hệ thứ tự địa phương (local) trong câu, nhưng cái mà chúng ta mong muốn là phân tích đoạn text đầu vào một cách tốt hơn. Và một vấn đề nữa đó là sẽ có rất nhiều các features mà chúng ta sẽ có ở đây nếu lấy một cặp các token. Giả sử số lượng token lên đến 100.000 token thì số lượng các features có thể tăng lên theo cấp số mũ.
Để giải quyết vấn đề này, chúng ta sẽ loại bỏ một số n-grams dựa trên tần suất xuất hiện của chúng trong tập hợp các câu review đầu vào của chúng ta (corpus). Có ba trường hợp xảy ra, n-grams có tần suất xuất hiện cao, n-grams có tần suất xuất hiện thấp, n-grams có tần suất xuất hiện trung bình.
- n-grams có tần suất xuất hiện cao: đây là trường hợp trong hầu hết các documents, bạn đều có thể thấy được n-grams này. Đối với Tiếng Anh, đó có thể là các giới từ, ... (a, an, the, ... ). Và bởi vì chúng ta chỉ sử dụng cấu trúc ngữ pháp, cho nên chúng không có ý nghĩa nhiều lắm. Chúng được gọi với cái tên là stop-words, nó không thực sự giúp chúng ta phân biệt các đoạn text với nhau. Và sẽ có ích nếu bạn loại bỏ các stop-words này.
- n-grams có tần suất xuất hiện thấp: đây là trường hợp thường đến từ lỗi gõ sai từ người dùng, hoặc là n-grams thường hiếm xuất hiện trong bất kỳ các câu review nào trong tập dữ liệu của chúng ta. Cả hai trường hợp này là xấu đối với model sau này. Bởi vì, nếu chúng ta ko xóa các n-grams này, model có thể sẽ bị overfit.
- n-grams có tần suất xuất hiện trung bình: đây là các n-grams tốt nhất bởi vì chúng bao gồm n-grams mà không có stop-words cũng như không có n-grams bị gõ sai chính tả hoặc hiếm xuất hiện trong tập dữ liệu. Vấn đề là trong tập n-grams có tấn suất xuất hiện trung bình, có rất nhiều n-grams thuộc các dải tần số xuất hiện khác nhau. Thật hữu ích khi chúng hữu dụng để có thể dựa vào tần số mà có thể lọc được n-grams là tốt, n-grams nào là xấu hơn. Nếu chúng ta có thể ranking các n-grams này theo mức độ quan trọng của chúng thì sẽ ra sao, chắc chắn sẽ rất có lợi. Chúng ta có thể quyết định được n-grams với tần suất xuất hiện trung bình thì n-grams nào là tốt, n-grams nào là xấu. Và ý tưởng ở đây là : n-grams có tần suất nhỏ hơn sẽ được đánh trọng số cao hơn vì nó là thể hiện cho các trường hợp riêng biệt trong câu review.
Để thực hiện được ý tưởng này ở đây, thuật ngữ TF sẽ được dùng cho việc biểu thị tấn suất xuất hiện của n-grams.
TF (Term Frequency)
Chúng ta ký hiệu TF cho tần suất xuất hiện của term t. Term t ở đây có thể hiểu là môt n-grams token trong một document d:
tf(t, d): frequency cho term t trong document d
Có nhiều cách tính giá trị tần suất xuất hiện tf này :

Cách đầu tiên và là cách dễ nhất là sử dụng giá trị binary (0, 1). Bạn có thể đưa 0 hoặc 1 vào tương ứng với việc token đấy có xuất hiện / không xuất hiện trong input text của bạn.
Cách thứ hai là việc đưa vào là giá trị đếm số lần xuất hiện một cách thông thường (raw count), tức là có bao nhiêu lần bạn thấy term t xuất hiện trong documents của bạn. Ký hiệu cho giá trị này là f.
Cách thứ ba là việc bạn tính tống số lần xuất hiện của tất cả các term trong document d. Sau đó chia giá trị f này cho tổng vừa tìm được. Như vậy bạn đã chuẩn hóa giá trị tf về khoảng (0, 1). Điều này biểu thị cho đối với tổng số lần xuất hiện của tất cả các term thì term t xuất hiện nhiều hay ít.
Cách cuối cùng, đó là bạn có thể sử dụng lược đồ chuẩn hóa logarit. Điều này sẽ đưa bạn về thang đo logarit và sẽ có thể giúp bạn giải quyết các task về sau tốt hơn.
IDF (Inverse Document Freequency)
Một cách khác là tinh tần suất xuất hiện đảo ngược của document (viết tắt là IDF).
Đầu tiên, đặt ký hiệu : N: Tổng tất cả các documents trong tập dữ liệu của chúng ta. D: bộ dữ liệu của chúng ta, đó là tập hợp tất cả các documents. Hiểu đơn giản, một documents có thể là một câu review trong tập dữ liệu.
Bây giờ, chúng ta cần tìm số lượng các documents mà term t xuất hiện trong đó:
Bây giờ, bạn có thể thấy rằng, bạn có tần suất của document, sau đó, bạn lại quan tâm đến số lượng các documents nơi mà có sự xuất hiện của term t, và sau đó chia số lượng này cho tổng N, và như vậy bạn sẽ có tần xuất xuất hiện của term t trên toàn bộ tập dữ liệu của bạn. Từ đây bạn có thể đảo ngược thương số này và lấy logarit nó, theo công thức :
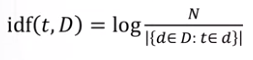
Và điều này thể hiện cho việc, với term t mà xuất hiện nhiều, thì mức độ quan trọng sẽ giảm, và term t xuất hiện ít thì mức độ quan trọng sẽ tăng lên, do thương số càng lớn thì logarit càng lớn, thương càng nhỏ, logarit càng nhỏ. Và công thức này được gọi là Inverse document freequency.
TF-IDF
Bây giờ, chúng ta sẽ sử dụng cả hai thuật ngữ TF và IDF, ta sẽ được giá trị TF-IDF. Một cái là tần suất xuất hiện của term t trong document d, và một cái là tần suất xuất hiện của term t trên toàn bộ tập dữ liệu. Giá trị TF-IDF sẽ bằng tích của TF và IDF. Nó sẽ cho ta cái nhìn toàn diện trên toàn bộ tập dữ liệu cũng như trên chinh document chứa term t mà ta đang xét.
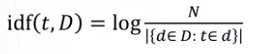
- Giá trị TF-IDF mà cao khi mà chúng ta có giá trị TF cao (tức là tần suất xuất hiện của term t trên document d cao) và tần suất của các documents chứa term t trên toàn bộ tập dữ liệu thấp (khi tần suất này mà thấp thì giá trị IDF sẽ lớn). Điều này phản ánh việc term t gần như chỉ tập trung vào trong document mà ta đang xét, và giá trị TF-IDF cao có tác dụng highlight term này để phân biệt được documents đang xét trong toàn bộ tập dữ liệu. Đây chính là ý tưởng mà chúng ta đang muốn follow.
Hãy xem thử cách TF-IDF hoạt động:
Chúng ta sẽ thay các giá trị counter của bag of words của việc biểu diễn các token thành giá trị TF-IDF. Sau đó, chúng ta có thể chuẩn hóa từng phần tử trong các hàng theo chuẩn L2. Bạn có thể chia dựa vào chuẩn L2 hoặc chia cho tổng, bất kỳ điều gì mà bạn muốn :
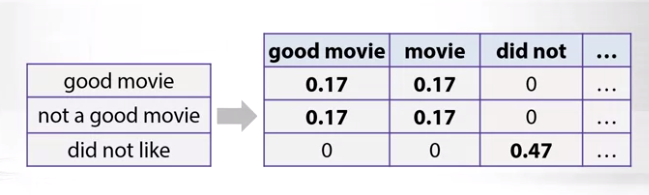
Bạn có thể thấy giá trị 0.47 cho did not là cao nhất, do nó chỉ nằm trong câu review thứ ba trong khi các n-grams good movie, movie nhỏ hơn do chúng xuất hiện trong 2 câu review, giá trị 0.47 có tác dụng highlight các trường hợp đặc biệt trong tập dữ liệu của chúng ta.
Trong thư viện sklearn có phương thức thực hiện vector hóa text dựa vào TF-IDF, bạn có thể import và sử dụng chúng. Bạn có thể xem đoạn code sau:
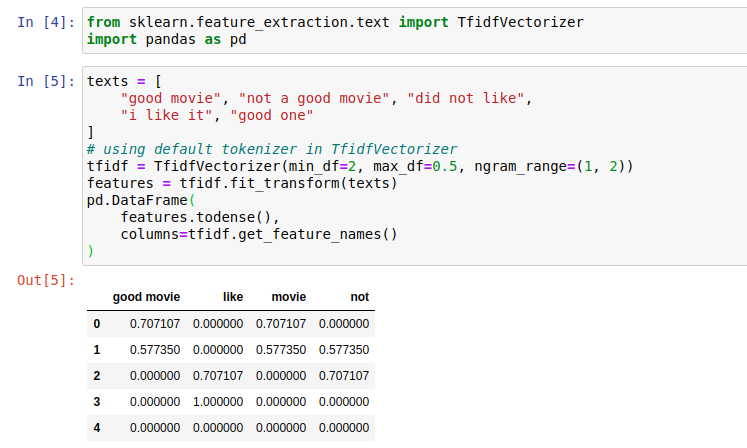
Có một số param mà bạn cần truyền vào bao gồm :
- mean_df: giá trị document freequency tối thiểu, bản chất là một ngưỡng dùng để cắt freequency thấp
- max_df: giá trị ngưỡng biểu thị cho document freequency lớn nhất, tức là số lượng các document chứa term t lớn nhất mà chúng ta có thể sử dụng, nếu lớn hơn giá trị này thì có lẽ term t thuộc các trường hợp stop-words.
- ngram_range: nó biểu thị trình TF-IDF vectorizer có thể dùng n-grams với n nằm trong khoảng nào cho việc biểu diễn các features. Và một điều nữa là ko phải tất cả n-grams đều được sử dụng mà trong thuật toán đã có các n-grams bị lọc ra.
Như vậy, trong bài viết này mình đã nói về các kỹ thuật extract features từ input text. Đây là cơ sở quan trọng để tạo ra các đặc trưng đầu vào cho việc train mô hình NLP về sau. Hy vọng mình viết dễ hiểu về kiến thức này. Cảm ơn bạn đã đọc bài viết.
Mình có sử dụng nội dung dựa vào bài giảng Feature extraction from text trong khóa học Natural Language Processing được tạo bởi National Research University Higher School of Economics. Hẹn gặp lại các bạn trong bài tiếp theo của mình về nội dung Linear models for sentiment analysis (sử dụng mô hình tuyến tính trong việc phân tích cảm xúc của các câu review) sử dụng các features được tạo từ các kỹ thuật trên.
All rights reserved
