Xử lý ngôn ngữ tự nhiên - phần 1
Bài đăng này đã không được cập nhật trong 6 năm
Xử lý ngôn ngữ tự nhiên
Máy tính hiểu ngôn ngữ của con người như thế nào!
Bài viết này là một phần của loạt bài nói về NLP: Phần 1, phần 2, phần 3. Máy tính rất tuyệt khi làm việc với các dữ liệu có cấu trúc như bảng tính và bảng cơ sở dữ liệu. Nhưng con người chúng ta lại thường giao tiếp bằng lời nói chứ không phải trong bảng. Điều đó thật đáng tiếc cho máy tính.
 Thật không may chúng ta không sống trong phiên bản lịch sử này, nơi mà việc giao tiếp được thực hiện bằng bảng biểu, tức là dữ liệu có cấu trúc!
Thật không may chúng ta không sống trong phiên bản lịch sử này, nơi mà việc giao tiếp được thực hiện bằng bảng biểu, tức là dữ liệu có cấu trúc!
Rất nhiều thông tin trên thế giới không có cấu trúc - văn bản thô bằng tiếng Anh, hoặc các ngôn ngữ khác trên thế giới. Làm thế nào chúng ta có thể làm cho máy tính có thể hiểu được văn bản phi cấu trúc và trích xuất dữ liệu từ chúng?

Xử lý ngôn ngữ tư nhiên hay còn được gọi là NLP là một lĩnh vực con của AI, trong đó, nó sẽ tập trung vào việc cho phép máy tính hiểu và xử lý được ngôn ngữ của con người. Hãy cùng kiểm tra xem cách NLP hoạt động và tìm hiểu cách viết một chương trình có thể trích xuất thông tin ra khỏi văn bản thô bằng python!
Lưu ý: Nếu bạn không quan tâm đến cách thức hoạt động của NLP mà chỉ muốn cắt và dán một số đoạn code, thì hãy bỏ qua phần Coding NLP Pineline in python nhé!
Máy tính có thể hiểu được ngôn ngữ hay không?
Từ khi máy tính tồn tại cho đến nay, thì các lập trình viên đã cố gắng viết ra các chương trình có thể hiểu được ngôn ngữ tiếng Anh. Lý do khá rõ ràng, con người đã có lịch sử về chữ viết hàng ngàn năm và sẽ thực sự hữu ích nếu một máy tính có thể đọc và hiểu được tất cả dữ liệu từ lượng bài viết đã được viết trong ngần ấy năm đó.
Máy tính chưa thể thực sự hiểu được tiếng Anh theo cách mà con người làm - nhưng chúng đã có thể làm được khá nhiều trong việc hướng tới điều này! Trong một số lĩnh vực hạn chế nhất định, những gì bạn có thể làm với NLP dường như sẽ cho bạn cảm giác như đang có phép thuật vậy  . Bạn có thể tiết kiệm rất nhiều thời gian bằng cách áp dụng các kỹ thuật NLP cho các dự án của riêng bạn.
. Bạn có thể tiết kiệm rất nhiều thời gian bằng cách áp dụng các kỹ thuật NLP cho các dự án của riêng bạn.
Và thậm chí còn tốt hơn, những tiến bộ gần đây trong NLP có thể dễ dàng được sử dụng thông qua các thư viện python nguồn mở như spaCy, textacy và neuralcoref. Những gì bạn có thể làm là chỉ cần code một vài dòng mã python. Điều đó thật tuyệt vời.
Trích xuất ý nghĩa từ văn bản là khó
Quá trình đọc và hiểu tiếng Anh rất phức tạp - và đó thậm chí là chúng ta còn chưa nghĩ tới việc rằng tiếng Anh không tuân theo các quy tắc hợp lý và nhất quán. Ví dụ: tiêu đề của đoạn tin tức này có ý nghĩa là gì?
“Environmental regulators grill business owner over illegal coal fires.”
Dịch: Các nhà quản lý môi trường nướng các chủ doanh nghiệp trên các vụ cháy than bất hợp pháp

Có phải các cơ quan quản lý đặt câu hỏi cho chủ doanh nghiệp về việc đốt than bất hợp pháp? Hay là các nhà quản lý đang nấu ăn với nguyên liệu là các chủ doanh nghiệp đúng theo nghĩa đen? Như bạn có thể thấy, phân tích tiếng Anh rất phức tạp đặc biệt là đối với máy tính.
Làm bất cứ điều gì phức tạp trong học máy thường có nghĩa là xây dựng một quy trình - đường đi hay nói cách khác đó là việc xây dựng một
Pinline. Ý tưởng là chia nhỏ vấn đề lớn của bạn thành các mảnh công việc nhỏ hơn và sau đó sử dụng học máy để giải quyết từng mảnh nhỏ đó một cách riêng biệt. Sau đó, bằng cách kết hợp một số mô hình học máy, bạn có thể làm được những điều phức tạp hơn.
Đó chính xác là chiến lược mà chúng ta sẽ sử dụng cho NLP. Chúng ta sẽ chia quá trình hiểu tiếng Anh thành nhiều phần nhỏ và xem cách làm của mỗi phần nhỏ đó.
Xây dựng đường ống (pineline) cho NLP, từng bước một
Hãy cùng nhau xem một đoạn văn bản được trích dẫn từ Wikipedia:
London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.
DỊch: London là thủ đô và là thành phố đông dân nhất của England và United Kingdom. Đứng trên dòng sông Thamse ở phía đông của đảo Great Britain, London là một khu định cư lớn trong hai thiên niên kỷ. Nó được thành lập bởi người La Mã, những người đã đặt tên cho nó là Londinium.
Đoạn văn này chứa một số sự thật hữu ích. Sẽ thật tuyệt nếu một máy tính có thể đọc văn bản này và hiểu rằng Lodon là một thành phố, Lodon nằm ở England, London được người La Mã định cư, ... . Nhưng để đạt được điều đó, trước tiên chúng ta phải dạy cho máy tính những khái niệm đơn giản và cơ bản nhất về ngôn ngữ viết và sau đó từ đó mới tiến dần lên từ đó.
Step 1: Sentence Segmentation - Bước 1: phân đoạn câu văn
Bước đầu tiên trong đường ống là chia văn bản thành cách câu riêng biệt. Điều đó sẽ cho chúng ta kết quả sau:
- “London is the capital and most populous city of England and the United Kingdom.”
- “Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia.”
- “It was founded by the Romans, who named it Londinium.”
Chúng ta có thể cho răng, mỗi câu trong tiếng Anh mang một ý nghĩa hoặc một ý tưởng đặc biệt. Và sẽ dễ dàng hơn để viết một chương trình có thể hiểu một câu đơn hơn là hiểu liền một lúc cả một đoạn văn.
Việc code mô hình phân đoạn các câu văn có thể đơn giản ví dụ như việc bạn sẽ tách các câu bất cứ khi nào bạn thấy dấu chấm cuối câu. Nhưng các đường ống NLP hiện đại thường sử dụng các kỹ thuật phức tạp hơn, hoạt động ngay cả khi tài liệu không được định dạng sạch.
Step 2: Word Tokenization - Bước 2: mã hóa các từ
Bây giờ, chúng ta đã chia tài liệu của chúng ta thành các câu văn riêng lẻ, và do đó, chúng ta cần phải xử lý từng câu văn một. Hãy bắt đầu với câu đầu tiên trong tài liệu của chúng ta:
“London is the capital and most populous city of England and the United Kingdom.”
Bước tiếp theo trong đường ống của chúng ta đó là chia câu văn này thành các từ riêng lẻ được gọi là các words hoặc các tokens. Điều này được gọi là các tokenization. Và đây là các kết quả:
“London”, “is”, “ the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”, “.”
Tokenization rất dễ làm bằng tiếng Anh: chúng ta sẽ tách các từ bất cứ khi nào có khoảng cách giữa chúng. Và chúng ta sẽ coi dấu chấm câu là các Token riêng biệt vì dấu chấm câu cũng có mang ý nghĩa.
Step 3: Predicting Parts of Speech for Each Token - Bước 3: Dự đoán các phần của bài phát biểu cho mỗi token
Tiếp theo chúng ta sẽ xem xét từng token (tức là từng từ của một câu văn) và cố gắng dự đoán loại từ của token này. Có thể nó là danh từ, động từ, hoặc tính từ, vân vân, ... . Biết được vai trò của từng từ trong câu, việc đó sẽ giúp ta có thể bắt đầu tìm ra được câu đang nói về cái gì.
Chúng ta có thể làm điều này bằng cách cung cấp từng từ (và một số từ xung quanh nó, để cung cấp ngữ cảnh) vào một mô hình phân loại một phần của bài phát biểu đã được đào tạo trước để thực hiện dự đoán từ loại của từ được truyền vào (việc dự đoán một từ thuộc dạng từ nào được gọi là dự đoán một phần của bài phát biểu):

Mô hình part-of-speech ban đầu được đào tạo bằng cách cung cấp cho nó hàng triệu câu tiếng Anh với mỗi từ của bài phát biểu đã được gắn thẻ và nó có thể tái tạo lại các hành vi đó.
Hãy nhớ rằng, mô hình này hoàn toàn dựa trên số liệu thống kê - nó không thực sự hiểu những từ này có nghĩa giống như cách con người làm. Nó chỉ biết làm thế nào để đoán một phần (tức một từ) của bài phát biểu dựa trên các câu và các từ tương tự mà nó đã thấy trước đó.
Sau khi xử lý được toàn bộ câu, chúng ta có thể có kết quả như thế này:

Với thông tin này, chúng ta có thể lượm nhặt một số ý nghĩa rất cơ bản. Ví dụ: chúng ta có thể thấy rằng các danh từ trong câu bao gồm "London" và "capital", vì vậy có lẽ câu này có lẽ đang nói về London.
Step 4: Text Lemmatization - Bước 4: bổ sung cho văn bản
Trong tiếng Anh (và hầu hết các ngôn ngữ khác) thì các từ xuất hiện dưới các hình thức khác nhau. Nhìn vào hai câu sau:
I had a pony.
I had two ponies.
Cả hai câu đều nói về danh từ pony, nhưng chúng đang sử dụng các cách viết khác nhau. Khi làm việc với văn bản trong máy tính, sẽ rất hữu ích khi biết dạng cơ bản của mỗi từ để bạn biết rằng cả hai câu đều nói về cùng một khái niệm. Mặt khác hai chuỗi "pony" và "ponies" trông giống như hai từ khác nhau đối với máy tính.
Trong NLP, chúng ta sẽ gọi quá trình tìm kiếm từ vựng này là quá trình tìm ra định dạng cơ bản hoặc bổ đề của mỗi từ (word) trong một câu văn.
Điều tương tự cũng sẽ được áp dụng cho động từ. Chúng ta có thể tìm các bổ ngữ (từ định dạng gốc) cho động từ bằng cách tìm các từ vựng gốc, tức là dạng chưa biến đổi (chưa được chia động từ) của chúng. Vì vậy, câu văn: "I had two ponies" trở thành: "I [have] two [pony]."
Việc bổ ngữ (Lemmatization) tức là đưa các từ về định dạng gốc được thực hiện bằng cách sử dụng một bảng tra cứu các từ vựng gốc của các từ trong câu văn, và có thể có một số quy tắc để xử lý các từ mà bạn chưa từng được nhìn thấy trước đây.
Đây là những gì mà câu văn của chúng tôi sẽ trở thành sau khi thực hiện quá trình chuyển các động từ trong câu sang định dạng gốc của động từ:

Sự thay đổi duy nhất mà chúng tôi thực hiện đó là việc biến "is" thành "be".
Step 5: Identifying Stop Words - Xác định các từ dừng
Tiếp theo chúng ta sẽ muốn xem xét tầm quan trọng của từng từ trong câu. Tiếng Anh có rất nhiều từ nối và được sử dụng rất thường xuyên như "and", "the" và "a". Khi thực hiện việc thống kê trên văn bản, những từ này sẽ mang lại rất nhiều nhiễu vì chúng xuất hiện thường xuyên hơn các từ khác. Một số pineline về NLP sẽ gắn cờ chúng là các từ dừng (stop words) - nghĩa là các từ mà bạn có thể sẽ muốn lọc ra trước khi thực hiện bất kỳ các phân tích thống kê nào.
Ở đây, cách câu của chúng ta trông như thế nào với các từ dừng sẽ được chuyển sang màu xám:

Các từ dừng thường được xác định chỉ bằng cách kiểm tra danh sách hardcoded của các từ dừng đã biết. Nhưng không có danh sách từ vựng tiêu chuẩn phù hợp cho tất cả các ứng dụng. Danh sách các từ có thể bỏ qua còn phụ thuộc vào từng ứng dụng cụ thể của bạn.
Ví dụ: nếu bạn đang xây dựng một công cụ tìm kiếm ban nhạc rock, bạn sẽ chắc chắn muốn việc loại bỏ các từ dừng sẽ không được áp dụng trên từ "the". Bởi vì từ "the" xuất hiện khá nhiều trong tên của các ban nhạc trên thế giới, thậm chí vào những năm 1980, có hẳn một ban nhạc chỉ có tên là "The" nữa đấy!
Step 6: Dependency Parsing - Phân tích sự phụ thuộc về cú pháp
Bước tiếp theo đó là tìm hiểu xem làm thế nào tất cả các từ trong câu của chúng ta liên quan đến nhau. Hay nói cách khác là tìm hiểu xem các từ trong câu của chúng ta liên quan đến nhau như thế nào? Điều này được gọi là quá trình phân tích phụ thuộc.
Mục tiêu là xây dựng một cây có thể gán một từ đơn duy nhất làm parent cho mỗi từ trong câu. Từ root của cây này sẽ là động từ chính trong câu. Đây là phần đầu của cây phân tích sẽ trông như thế nào cho câu của chúng ta:
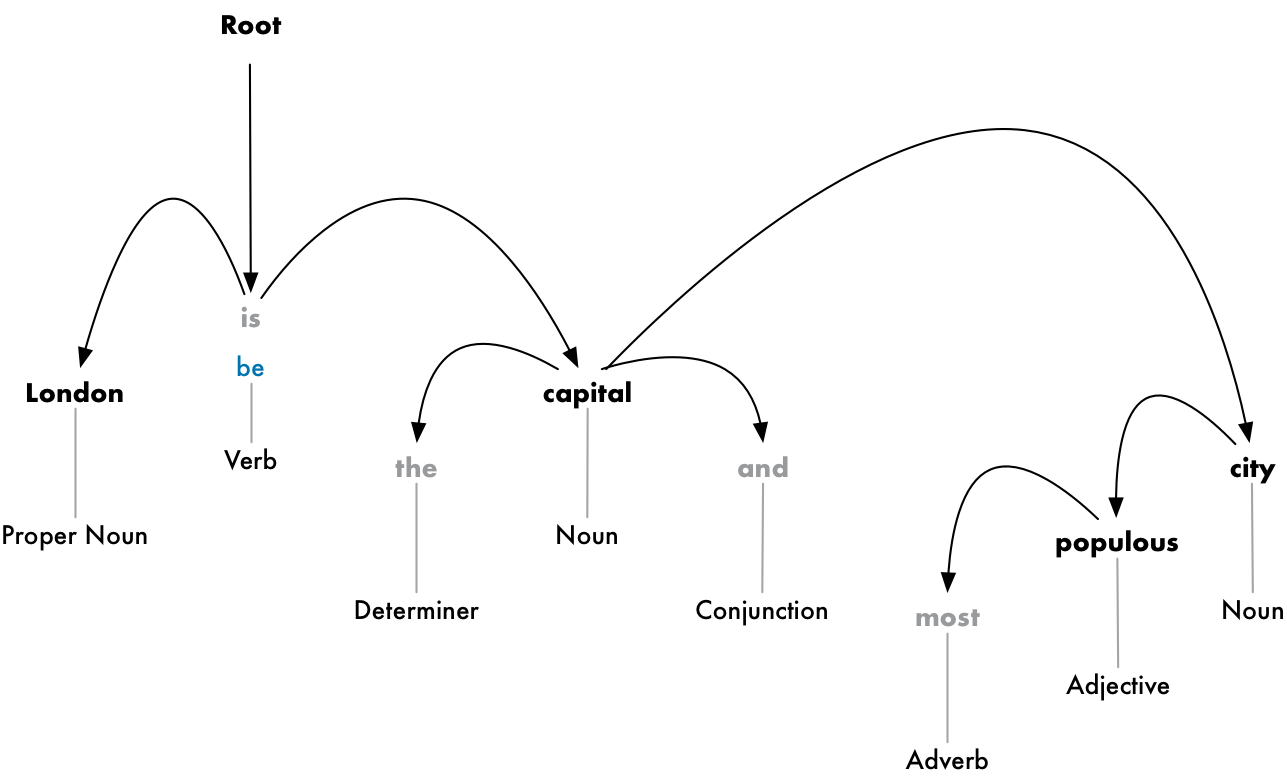
Nhưng chúng ta có thể tiến thêm một bước nữa. Ngoài ra việc xác định từ parent của mỗi từ, chúng ta có thể dự đoán được loại mối liên hệ, mối liên quan tồn tai giữa hai từ đó.
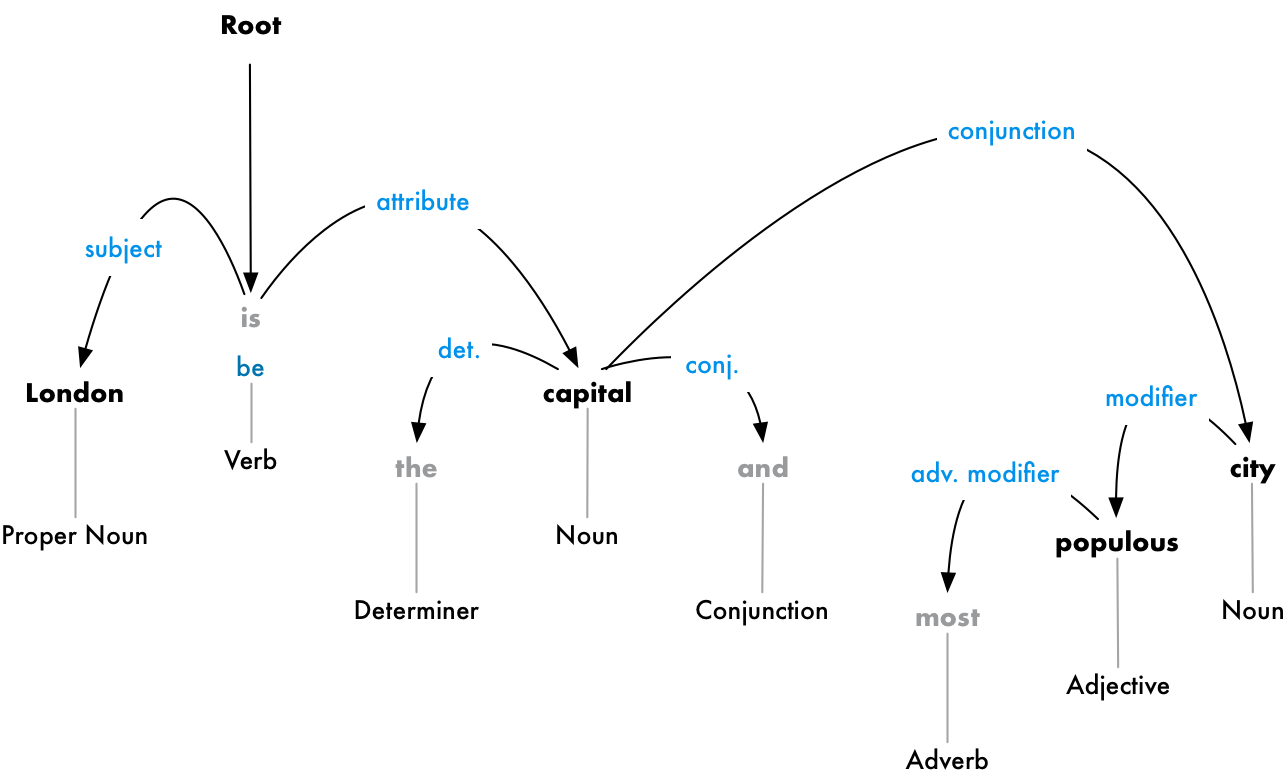
Cây phân tích cú pháp này cho chúng ta thấy chủ đề của câu là danh từ "London" và nó có có quan hệ "be" với "capital". Cuối cùng, chúng ta cũng biết một điều hữu ích đó là Lodon là thủ đô! Và nếu chúng ta đi theo cây phân tích hoàn chỉnh cho câu (ngoài những gì đã được hiển thị), chúng ta thậm chí còn có thể phát hiện ra rằng London là thủ đô của United Kingdom.
Giống như cách chúng ta dự đoán các từ của bài phát biểu trước đó bằng mô hình học máy, phân tích cú pháp phụ thuộc vào việc đựa các từ vào trong một mô hình học máy và nhận được kết quả đầu ra. Nhưng phân tích sự phụ thuộc này là nhiệm vụ đặc biệt phức tạp và yêu cầu toàn bộ bài viết giải thích một cách chi tiết. Nếu bạn tò mò về cách thức hoạt động của nó, thì một nơi tuyệt vời để bắt đầu đọc đó là bài viết của Matthew Honnibal với chủ đề: "Phân tích tiếng Anh trong 500 dòng code với python!".
Nhưng mặc dù có một lưu ý từ tác giả vào năm 2015 rằng cách tiếp cận này là tiêu chuẩn, nhưng ngày nay, nó thực sự đã lỗi thời và thậm chí ko còn được sử dụng bởi chính tác giả nữa. Vào năm 2016, Google đã phát hành một trình phân tích cú pháp phụ thuộc có tên là Parsey McParseface, nó vượt trội hơn so với các phương pháp tiêu chuẩn trước đây, bằng cách sử dụng học sâu mới và nhanh chóng lan rộng ra toàn ngành. Sau đó mất một năm, họ đã phát hành ra mô hình thậm chí còn tốt hơn có tên là ParseySaurus và nó cải thiện mọi thứ tốt hơn. Nói cách khác, kỹ thuật phân tích cú pháp vẫn là một lĩnh vực được nghiên cứu tích cực và liên tục được thay đổi và cải tiến.
Nó cũng quan trọng để nhắc lại rằng, nhiều câu trong tiếng Anh là mơ hồ và thực sự khó phân tích. Trong những trường hợp đó, mô hình sẽ đưa ra dự đoán dựa trên phiên bản phân tích cú pháp của câu đó, và có vẻ như nó không hoàn hảo và đôi khi mô hình sẽ dự đoán sai. Nhưng theo thời gian, mô hình NLP của chúng ta sẽ tiếp tục trở nên tốt hơn trong việc phân tích văn bản một cách hợp lý.
Bạn có thể sẽ muốn thử phân tích cú pháp của một câu riêng của bạn? Có một bản demo tương tác tuyệt vời từ nhóm spaCy ở đây, bạn có thể thử.
Step 6b: Finding Noun Phrases - Tìm các cụm danh từ
Cho đến nay, chúng tôi đã coi mỗi từ trong câu của chúng tôi là một thực thể riêng biệt. Nhưng đôi khi chúng sẽ có ý nghĩa hơn để nhóm các từ lại với nhau thành một cụm đại diện cho một ý tưởng hoặc một điều duy nhất nào đó. Chúng ta có thể sử dụng thông tin từ cây phân tích sự phụ thuộc để tự động nhóm các từ mà tất cả đang nói về cùng một điều.
Ví dụ: Thay vì điều này:
Chúng ta có thể nhóm các cụm danh từ để tạo ra điều này:

Chúng ta có làm bước này hay không phụ thuộc vào mục tiêu cuối cùng của chúng ta. Nhưng nó thường là một cách nhanh chóng và dễ dàng để đơn giản hóa câu nếu chúng ta không cần chi tiết thêm về những từ nào là tính từ và thay vào đó quan tâm nhiều hơn đến việc trích xuất các ý tưởng hoàn chỉnh.
Step 7: Named Entity Recognition (NER) - Nhận dạng thực thể được đặt tên
Bây giờ, chúng ta đã hoàn thành tất cả các công việc khó khăn đó, cuối cùng, chúng ta cũng có thể vượt ra ngoài ngữ pháp của trường và bắt đầu thực sự rút ra ý tưởng. Trong câu của chúng tôi, chúng tôi có các danh từ sau:

Một số danh từ này trình bày những điều có thật trên thế giới. Ví dụ: "London", "England" và "United Kingdom" đại diện cho các địa điểm thực tế trên bản đồ thế giới. Nó sẽ là tốt đẹp để có thể phát hiện ra điều đó! Với thông tin đó, chúng tôi có thể tự động trích xuất danh sách các địa điểm trong thế giới được đề cập trong tài liệu bằng NLP.
Mục tiêu của nhận dạng tên của thực thể, là việc phát hiện và gán nhãn cho các danh từ này với các khái niệm trong thế giới thực mà chúng đại diện. Ở đây, câu của chúng tôi trông như thế nào sau khi chạy mỗi từ vựng qua mô hình NER đã được train:

Nhưng hệ thống NER không chỉ thực hiện tra cứu từ điển đơn giản, mà thay vào đó chúng đang sử dụng bối cảnh về cách từ vựng đang xét xuất hiện trong câu và sử dụng mô hình thống kê để đoán loại danh từ mà từ vựng đó đang đại diện. Một hệ thống NER tốt có thể cho biết được sự khác biệt giữa tên người "Brooklyn Decker" và tên địa điểm "Brooklyn" bằng việc sử dụng các ngữ cảnh đối với nơi xuất hiện từ này trong câu.
Đây chỉ là một số loại đối tượng mà một hệ thống NER điển hình có thể gắn thẻ:
- Tên người
- Tên công ty
- Vị trí địa lý (cả vật lý và chính trị)
- Tên các sản phẩm
- Ngày và thời gian
- Số tiền
- Tên sự kiện
NER có hàng triệu cách để sử dụng vì nó dễ dàng lấy dữ liệu có cấu trúc ra khỏi văn bản. Nó là một trong những cách dễ nhất để nhanh chóng nhận được giá trị từ một pinline NLP.
Bạn có thể sẽ muốn thử nghiệm một mô hình nhận dạng thực thể? có một bản demo tương tác tuyệt vời khác mà bạn có thể sử dụng từ spaCy tại đây.
Step 8: Coreference Resolution - Giải quyết vấn đề cốt lõi
Tại thời điểm này, chúng tôi đã có một đại diện hữu ích của câu của chúng ta. Chúng tôi biết các từ, các từ liên quan đến nhau như thế nào và từ nào đang nói về thực thể nào bằng mô hình NER.
Tuy nhiên, chúng tôi vẫn có một vấn đề lớn. Tiếng Anh có đầy đủ các đại từ - những từ như he, she, it, ... .Đây là những từ viết tắt mà chúng tôi sử dụng thay thế vì phải viết đi viết lại các tên riêng của người. Con người có thể theo dõi những từ này dựa vào bối cảnh của câu. Nhưng mô hình NLP của chúng tôi không biết đại từ này có nghĩa là gì vì nó chỉ kiểm tra từ đó tại một thời điểm.
Hãy cùng nhìn vào câu thứ ba của tài liệu của chúng tôi:
“It was founded by the Romans, who named it Londinium.”
Nếu chúng tôi phân tích điều này với pineline NLP của chúng tôi, chúng tôi sẽ biết rằng "it" được thành lập từ người La Mã. Nhưng sẽ hữu ích hơn cho máy tính nếu biết rằng câu này có nghĩa là Lodon được thành lập bởi người La Mã.
Là một người đọc câu này, bạn có thể dễ dàng hiểu rằng "it" có nghĩa là "London". Mục tiêu của giải pháp là tìm ra ánh xạ tương tự này bằng cách theo dõi các đại từ qua các câu. Chúng tôi muốn tìm ra tất cả các từ đang đề cập đến cùng một thực thể.
Ở đây, kết quả của việc chạy việc tìm từ đều ám chỉ đến một thực thể của chúng tôi cho từ "London":

Với thông tin cốt lõi kết hợp (tức là các thông tin ánh xạ thực thể) với cây phân tích và thông tin thực thể được đặt tên, chúng ta sẽ có thể trích xuất rất nhiều thông tin ra khỏi tài liệu này!
Giải quyết cốt lõi (tức là ánh xạ các đại từ cùng chỉ một thực thể) là một trong những bước khó khăn nhất trong quy trình của chúng tôi để thực hiện. Nó còn khó hơn cả phân tích cú pháp câu. Những tiến bộ gần đây trong học tập sâu đã dẫn đến những cách tiếp cận mới chính xác hơn, nhưng nó vẫn chưa hoàn hảo. Nếu bạn muốn tìm hiểu thêm về cách thức hoạt động, hãy bắt đầu ở đây.
Bài viết được dịch từ bài viết Natural Language Processing is Fun! của tác giả Adam Geitgey. Bạn có thể nhấn vào link để xem bài viết gốc!
All rights reserved
