Detect object sử dụng mô hình SSD
Bài đăng này đã không được cập nhật trong 7 năm
Giới thiệu
SSD được thiết kế để phát hiện đối tượng trong thời gian thực. R-CNN nhanh hơn sử dụng mạng đề xuất khu vực để tạo các hộp ranh giới và sử dụng các hộp đó để phân loại các đối tượng. Mặc dù được coi là khởi đầu chính xác, toàn bộ quá trình chạy ở 7 khung hình mỗi giây. Thấp hơn nhiều so với những gì cần cho một nhu cầu xử lý thời gian thực. SSD tăng tốc quá trình bằng cách loại bỏ sự cần thiết của mạng đề xuất khu vực. Để giải quyết về vấn đề độ chính xác giảm, SSD áp dụng một vài cải tiến bao gồm các feature map đa kích thước và sử dụng các hộp mặc định. Những cải tiến này cho phép SSD tiến gần được với độ chính xác của Faster R-CNN nhưng lại có thể sử dụng hình ảnh có độ phân giải thấp hơn, giúp đẩy tốc độ cao hơn.
1. Tổng quan: Mô hình SSD được chia làm hai giai đoạn:
- Trích xuất feature map (dựa vào mạng cơ sở VGG16) để tăng hiệu quả trong việc phát hiện => thì nên sử dụng ResNet, InceptionNet, hoặc MobileNet
- Áp dụng các bộ lọc tích chập để có thể detect được các đối tượng.
2. Giai đoạn 1: mô hình SSD sử dụng mạng cơ sở VGG16 để trích xuất feature map
SSD sử dụng VGG16 làm mạng cơ sở để trích xuất feature map:
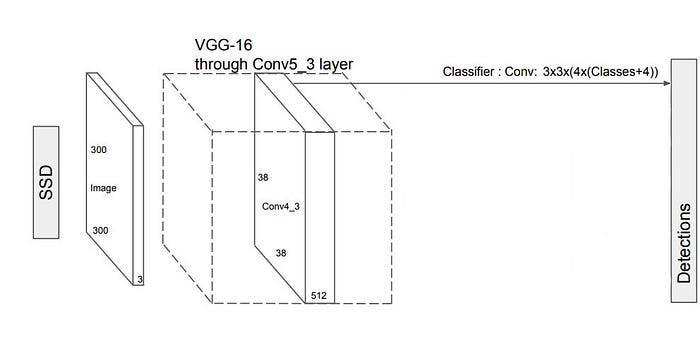
- Đầu vào: image kích thước (300 * 300)
- Sau đó sử dụng VGG16 làm mạng cơ sở để trích xuất bản đồ tính năng. Lưu ý, đối với VGG16, chúng ta sẽ sử dụng lớp Conv4_3 là một trong những lớp predictor object của mạng, những lớp còn lại chỉ có tác dụng trích xuất các đặc trưng của hình ảnh đầu vào
- *Hình ảnh trên là sự minh họa cho Conv4_3 với kích thước kernel là (8, 8) cho nên ko gian kích thước là (38, 38).
Sau khi tạo ra feature map thì mỗi ô của feature map sẽ đưa ra 4 dự đoán đối tượng.
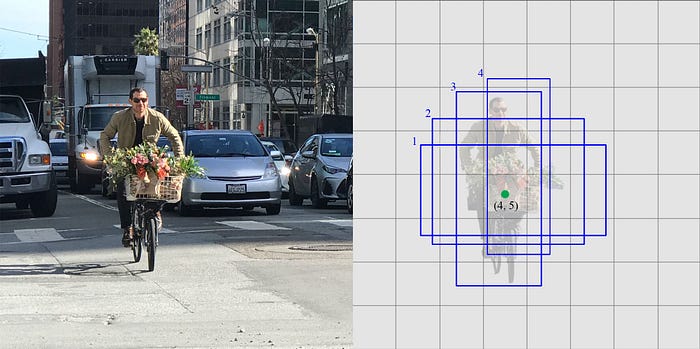
hình ảnh bên trái là hình ảnh gốc, hình ảnh bên phải là hình ảnh với 1 ô là sự thể hiện của 4 bbx dự đoán.
Mỗi dự đoán này bao gồm:
- 1 bounding box
- 21 score biểu thị cho độ tin cậy của mỗi lớp (bao gồm cả lớp background)
- score: là xác suất xuất hiện đối tượng được dự đoán có trong bounding box, 20 score là 20 xác suất phát hiện 20 loại đối tượng trong thực tế, 1 score còn lại là xác suất dự đoán trong bounding box là class background
Do đó, lớp Conv4_3 đưa ra tổng số lượng dự đoán là 38 × 38 × 4 (4 bbx được dự đoán tại mỗi vị trí pixel).
Khi đó, các bbx predict của chúng ta trên hình ảnh sẽ có dạng như sau:

do tại mỗi pixel thì sẽ bao gồm 4 bbx dự đoán cho nên tổng thể số lượng bbx dự đoán trên hình ảnh sẽ rất nhiều
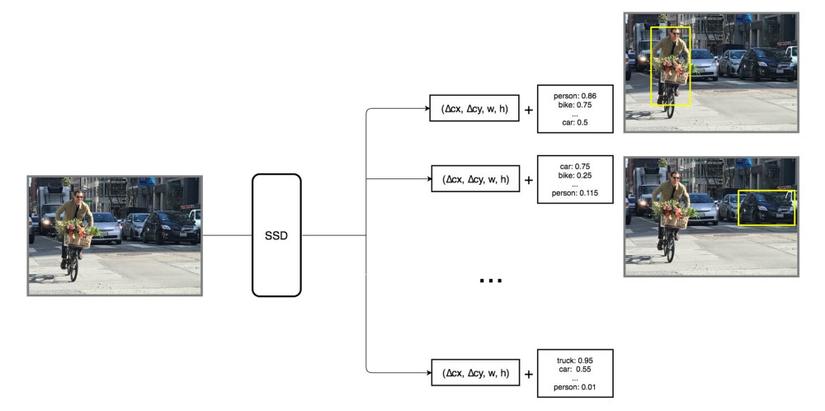
Mỗi dự đoán bao gồm một bbx và 21 score biểu thị cho 21 class ~ 21 score này là 21 xác suất thể hiện cho khả năng trong bbx là đối tượng thuộc class đó.
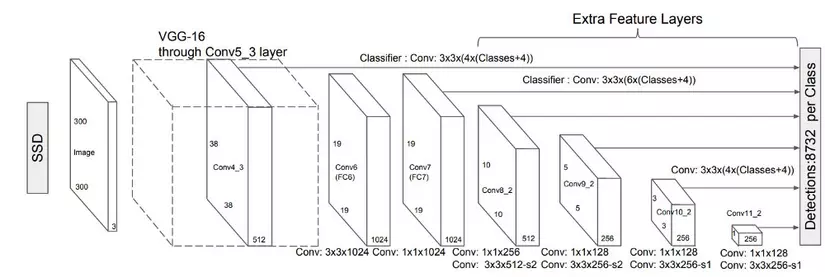
3. Giai đoạn 2: Sử dụng trình dự đoán tích chập (Convolution preditors) cho phát hiện đối tượng:
Sau khi trích xuất feature maps dựa vào kiến trúc của mạng cơ sở (base network), mô hình SSD sẽ tiếp tục tính toán cả hai giá trị: đối với từng location và score cho các class bằng việc sử dụng các bộ lọc tích chập nhỏ. Sau khi extract feature maps, SSD sử dụng một kernel 3 × 3 trên mỗi ô để tạo ra dự đoán. Mỗi đầu ra của bộ lọc là 25 channels: 21 scores đối với mỗi lớp + 1 bbx.
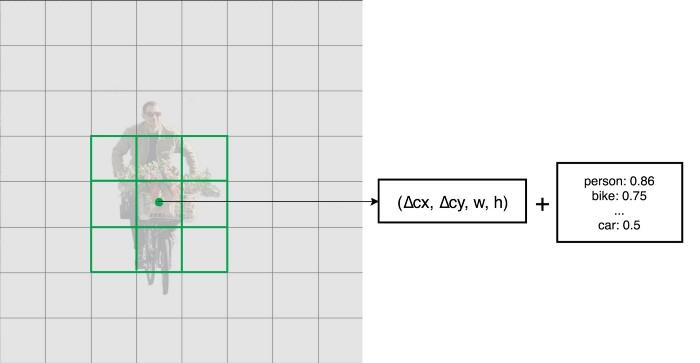
Áp dụng bộ lọc 3 × 3 để tạo ra các predict đối với mỗi location và các class. Quá trình sử dụng các trình phát hiện tích chập đơn giản cũng chỉ là quá trình predict ra các bbx dự đoán (với mỗi vị trí pixel sẽ là 4 bbx dự đoán giống như VGG16 đang làm) có điều nó khác bởi vì nó sử dụng các feature map có kích thước khác nhau với mục đích như sau:
- Feature maps nhiều tỷ lệ cho việc detection:
- Vấn đề phối cảnh sẽ thay đổi kích thước của các vật thể.
- Ở trên là việc phát hiện đối tượng ở 1 kích thước, trên thực tế thì việc detect nhiều đối tượng vs nhiều kích thước sẽ sử dụng quy trình tương tự nhưng ở các lớp khác nhau.
Một điểm cần chú ý:
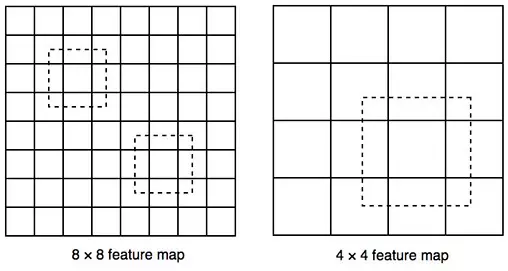
Đối với các feature maps có độ phân giải thấp ở bên phải sẽ có khả năng phát hiện được đối tượng có kích thước khác nhau.
Do đó, SSD thêm 6 lớp Conv phụ trợ vào sau VGG16, 5 trong số chúng sẽ được thêm vào để detect object. Và trong 3 trong số 6 lớp này sẽ đưa ra dự đoán là 6 (bbx + score) thay vì 4 (bbx + score). Tổng cộng, SSD đưa ra 8732 dự đoán với việc sử dụng 6 layers.
feature map đa tỷ lệ cải thiện được độ chính xác detect object ở nhiều kích thước khác nhau.
- Bbx mặc định:
Anchor Box có thể hiểu là các bbx xếp chồng lên nhau. Nó giúp phát hiện các đối tượng:
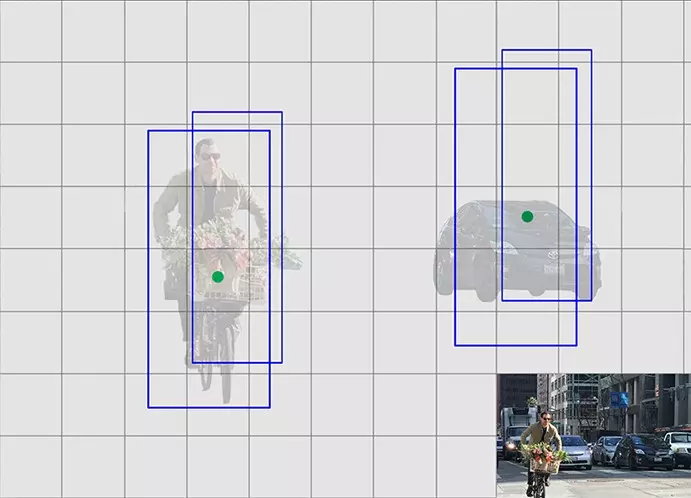
Một điều trong thực tế, hình dạng của các đối tượng trong hình ảnh không phải là giống nhau. Ví dụ: hình ảnh về con người thì các bbx dọc thể hiện tốt, bbx nằm ngang sẽ không thể hiện tốt, đối với hình ảnh về ô tô, bbx nằm ngang có thể bao trọn ô tô, nhưng các bbx dọc thì lại ko thể làm điều này
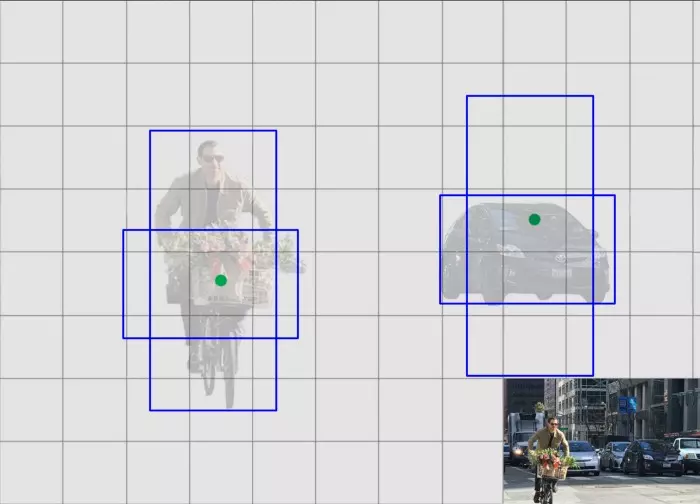
Cho nên các bbx dự đoán mà không đa dạng thì model mà ta đào tạo sẽ ko đem lại giá trị nếu muốn detect nhiều object.
Do đó chúng ta cần các bbx nhiều hình dạng hơn để có thể bao quát được nhiều object hơn:
- Bbx bao gồm nhiều loại đối tượng hơn:
Trong thực tế, thì ko phải hình dạng của các đối tượng là tùy ý, nó luôn tuân theo một quy tắc, tỷ lệ nào đó, cho nên ta có thể sd một bbx default mặc định như sau, nó có khả năng giúp bao và phát hiện được nhiều đối tượng nhất: Đối với mỗi lớp feature maps, nó sẽ chia sẻ cùng một bộ bbx mặc định khác nhau để có thể tùy chỉnh detect các đối tượng có các kích thước khác nhau (các feature maps ở các độ phân giải khác nhau). 4 hộp bbx màu xanh dưới đây là 4 hộp bbx mặc định của một lớp:
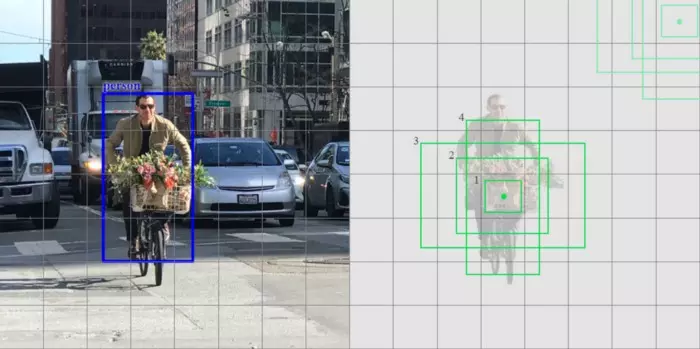
Feature map nhiều kích thước & các bbx default
Dưới đây là ví dụ cho việc sử dụng feature map nhiều tỷ lệ và bbx default để có thể detect ra các object nhiều kích thước:
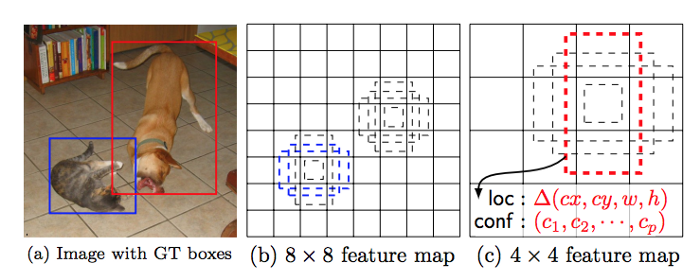
Con chó khớp với bbx mặc định màu đỏ được thể hiện trong feature map có kích thước nhỏ là 4 * 4, và bbx mặc định màu xanh phát hiện con mèo ở feature map kích thước lớn 8 * 8.
Do đó, feature map ở độ phân giải cao thì phát hiện được đối tượng nhỏ và feature map ở độ phân giải thấp thì phát hiện được đối tượng lớn.
Nhược điểm: Khi hình ảnh đầu vào cho vào SSD thì kích thước của hình ảnh đã giảm đi đáng kể cho nên các độ chính xác detect object không cao.
Giải pháp: sd hình ảnh đầu vào có độ phân giải cao hơn.
Hàm mất mát (Loss Function)
- Hàm mất mát của vấn đề localization là việc đánh giá sự ko phù hợp giữa các bbx dự đoán và bbx trong tập train sets = > làm sao cho các sai số này là nhỏ nhất.
- Hàm mất mát của vấn đề classification
![]()

Các điểm khác trong mô hình SSD
SSD sử dụng non-maximum suppression (nms) để thực hiện loại bỏ các bbx dư thừa
SSD sử dụng lấy mẫu cứng (hard sample) để đào tạo làm tăng độ chính xác dự đoán của model.
SSD sử dụng các kỹ thuật tăng cường dữ liệu (data augmentation) để giúp tăng độ chính xác của thuật toán.
Bài viết được dịch từ bài viết của tác giả Jonathan Hui
All rights reserved
