Bài 1 - Các kiến thức cơ bản cần biết khi bạn bắt đầu với natural language processing
Bài đăng này đã không được cập nhật trong 6 năm
Text processing
Các khái niệm đầu tiên trong natural language processing:
-
Text là gì?: text là một chuỗi bao gồm nhiều thứ :
- 1 tập hợp các characters (ký tự - là level thấp nhất của text)
- 1 tập hợp các words (các từ - là một chuỗi các characters mang ý nghĩa nào đó)
- 1 tập hợp các phrases (các cụm từ - là một chuỗi các words)
- 1 tập hợp các sentences (các câu)
- 1 tập hợp các paragrahs (các đoạn văn)
-
Words là gì ?: là 1 chuỗi có ý nghĩa của các characters
-
tách words:
- Tách words trong English: tách dựa vào dấu câu, dấu cách bên trái của từng words
- Tác words trong các ngôn ngữ khác : khó hơn vì các words chưa hẳn cách nhau bởi các khoảng trắng
-
Các phương pháp text processing
Tách token là làm gì (spliting token)?:
Việc tách các token từ một input text được gọi là tokenization. Nó có tác dụng tách input text thành một tập hợp các token riêng biệt. Hay còn được gọi là các chunks có ý nghĩa. Có thể hiểu một chunk có thể là một words, một phrases, một sentenses hoặc thậm chí là một paragraphs. Mỗi chunk được gọi là token.
Các phương pháp thực hiện tokenization:
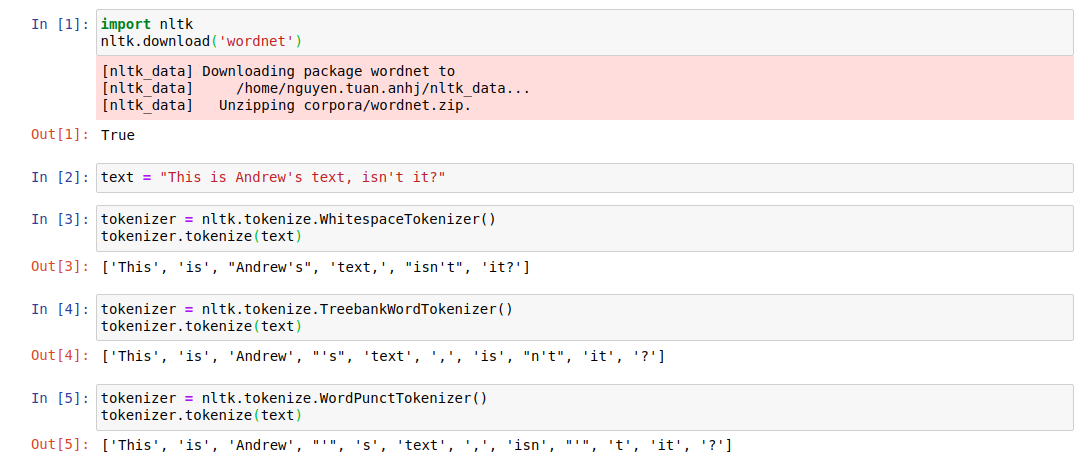
whitespaceTokenizer:
Tách các token dựa vào các khoảng trắng (space) hoặc bất kể các ký tự nào không được hiển thị. Có thể sử dụng trong python với thư viện NLTK: whitespaceTokenizer
Ví dụ : Input text: *This is Andrew's text, isn't it?*
Chúng ta có thể phân tách câu này dựa vào whitespace. Nhưng sẽ có vấn đề ở đây. Các token sẽ được tách là *This*,*is*, *Andrew's*, *text*, *isn't*, *it?*. *it?* có dấu hỏi cuối. Nó có thực sự mang ý nghĩa là một token riêng biệt nếu nó không mang dấu hỏi ở cuối ? Tức là *it?* và *it* là 2 token khác nhau nhưng có mang cùng ý nghĩa hay không !. Một điều dễ hiểu là chúng ta mong muốn gộp hai trường hợp này lại làm 1 bởi vì chúng mang cùng một ý nghĩa và dấu hỏi cũng giống như dấu phảy, nó giống như một token trong một đoạn text đơn giản.
WordPunctTokenizer:
Phương pháp này là việc tách các token dựa trên các dấu câu (punctuation). Một tokenizer này có sẵn trong thư viện NLTK. Nhược điểm của phương pháp này đó là sẽ phân tách các token không mang ý nghĩa. Ví dụ, vẫn với câu trên, nó được phân tách thành This, is, Andrew, ', s, text, ,, isn, ', t, it, ?. Các token t, s, isn không mang ý nghĩa cho việc phân tích về sau, và nó chỉ mang ý nghĩa khi kết hợp với các dấu câu hoặc các words trước đó.
TreebankWordTokenizer
Để giải quyết vấn đề của phương pháp thứ hai, chúng ta sẽ phân tách token dựa vào một tập hợp các luật (rules). Nó sử dụng các luật về ngữ pháp trong English để thực hiện tokenizer. Và nó thực sự mang ý nghĩa cho các token về mặt ngữ nghĩa. Cũng với ví dụ trên chúng ta sẽ tách được các token: *This*,*is*, Andrew, 's, text, ,, is, n't, it, ?. Các token 's và n't đều mang ý nghĩa nhất định.
Bạn có thể tham khảo đoạn code dưới đây :
Chuẩn hóa các token (token normalization)
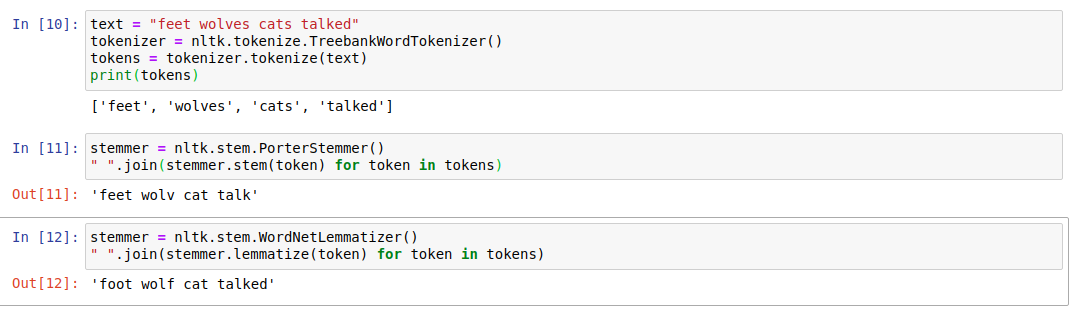
Công việc tiếp theo cần phải làm đó là thực hiện chuẩn hóa cùng một token về định dạng nguyên bản của nó. Ví dụ : wolf và wolves là các từ mang cùng nghĩa. Điều chúng ta cần thực hiện là đưa hai từ này về định dạng gốc là wolf. Tương tự, trong English có rất nhiều các trường hợp như vậy, trường hợp thêm s vào từ, trường hợp thêm ed hay trường hợp các từ bị biến đổi hoàn toàn khỏi định dạng từ gốc. Đối với các trường hợp được thêm ending vào từ thì chúng ta thực sự không cần quan tâm đến chúng, ít nhất là trong task: text classification.
Có hai phương pháp để thực hiện chuẩn hóa các token đó là stemming và lemmazation.
- Stemming: thay thế các hậu tố để đạt được định dạng gốc của từ, tức là cái được gọi là stem. Nó đến từ ý tưởng cắt bỏ hoặc thay thế các hậu tố của từ. Nhược điểm của phương pháp này là khi các token bị biến đổi hoàn toàn so với định dạng gốc, thì quy tắc này sẽ không còn đúng nữa. Ví dụ :
- Lemmazation: nói đến phương pháp này, người ta thường liên tưởng đến việc sử dụng việc phân tích vocabularies (từ vựng) và morphological (hình thái).
Một ví dụ về stemmer là Porter's stemmer. Đây là stemmer cổ nhất trong English. Nó có các quy tắc về hậu tố của từ và dựa vào đó chúng ta có thể chuẩn hóa được token:

Tuy nhiên trong các trường hợp đặc biệt, các token sẽ không thể áp dụng được quy tắc này, ví dụ :

Bạn có thể tìm thấy stemmer này trong thư viện nltk.
Một ví dụ về lemmtization: mình sử dụng WordNet lemmatizer, nó sử dụng WordNet database để tra cứu các lemma hay còn gọi là định dạng gốc của từ. Bạn cũng có thể tìm thấy nó trong thư viện NLTK. Ví dụ, cũng trong trường hợp của stemming bạn có thể thấy kết quả chuẩn hóa token đã đúng hơn:

Tuy nhiên, cách này cũng không thể cover hết được tất cả các trường hợp, ví dụ đối với danh từ, việc có s và es sẽ khác ý nghĩa hoàn toàn và đối với động từ cũng là một câu chuyện khác. Cho nên, trong thực tế, tùy vào ứng dụng mà bạn nên sử dụng stemmer hoặc lemmatizer một cách phù hợp.
Bạn có thể tham khảo đoạn code về hai phương pháp chuẩn hóa token sau:
P/S: ngoài ra, chúng ta còn có một vài trick trong việc chuẩn hóa token nữa. Ví dụ :
-
TH1: các ký tự được viết hoa: Ví dụ : Us và us hoặc US và us. Cả hai đều cùng một cách phát âm Us và us, nhưng sẽ an toàn hơn nếu đưa nó về dạng us. Đối với US và us là câu chuyện khác, một là đất nước, một là đại từ. Chúng ta cần phân biệt chúng theo cách nào đó. Một ý tưởng đơn giản là ví dụ phân loại cảm xúc của câu review chẳng hạn, thường thì trường hợp nhiều sẽ rơi vào việc người dùng viết khi Cap Locks còn đang bật. Tức là nó là viết hoa các ký tự, Us và us là đại từ, ko phải country. Một cách khác là trong tiếng Anh, chúng ta sẽ thường có ba trường hợp :
- Viết hoa đầu câu sẽ thường rơi vào việc token ấy chỉ là viết bởi chữ in hoa
- Viết hoa trong tiêu đề cũng rơi vào trường hợp 1: vì trong TA các ký tự trong tiêu đề đều phải viết hoa
- Viết hoa ở giữa từ, thường thì đây sẽ là tên các thực thể hoặc địa danh.
-
TH2: Các từ được viết tắt : đây thường là trường hợp khó trong việc chuẩn hóa.
Trong bài tới, mình sẽ nói về Feature extraction from text. Nội dung bài được lấy từ khóa học Natural Language Processing được cung cấp bởi National Research University Higher School of Economics. Bạn có thể tham khảo khóa học tại đây. Cảm ơn bạn đã đọc bài viết này. Hẹn gặp bạn vào bài viết sau!
All rights reserved
