Bài 3 - Linear models for sentiment analysis
Bài đăng này đã không được cập nhật trong 6 năm
Trong bài viết này, mình sẽ trình bày về mô hình phân loại đầu tiên dựa trên các features đã extract được từ kỹ thuật TF-IDF mà bài trước mình đã đề cập. Nhiệm vụ phân loại của mô hình đó là phân loại sắc thái cảm xúc của các câu review về các bộ phim trong tập dữ liệu - semtiment classification.
Giới thiệu bộ dữ liệu
Bộ dữ liệu mà mình lấy là bộ dữ liệu IMDB movie reviews datasets. Bạn có thể download và sử dụng nó một cách miễn phí. Nó bao gồm 25.000 câu review tích cực (positive) và 25.000 câu reiview tiêu cực (negative). Labels được đánh dưới dạng star, từ 1 star cho đến 10 star. Như vậy, bộ dữ liệu này hoàn toàn phù hợp cho nhiệm vụ classification nơi bạn có đầu vào là text và đầu ra là số lượng star, nơi thể hiện cảm xúc review của người dùng.

Nếu số lượng star ít nhất là 7 star thì bạn có thể đánh label cho nó là positive. Nếu số lượng star mà lớn nhất mới chỉ đạt được 4 star thì bạn có thể đánh label cho nó là negative.
Bộ dữ liệu này bao gồm 30 review cho mỗi bộ phim và nó cố gắng tránh bị bias nhất có thể cho bất kỳ bộ phim nào trong tập dữ liệu. Bộ dữ liệu được chia 50 / 50 cho tập train và tập test. Một bộ dữ liệu khá lý tưởng trong thực tế.
Để đánh giá mô hình, chúng ta sẽ sử dụng accuracy để xem những gì đang diễn ra bởi vì chúng ta có cùng số lượng positive và negative trong bộ dữ liệu. Tức là bộ dữ liêu là cân bằng với tất cả các terms trên toàn bộ tập dữ liệu.
Mô hình
Extract feature from text
Bước đầu tiên, hãy cùng transform text thành các features dựa vào kỹ thuật TF-IDF mà mình đã đề cập trong bài trước. Giả sử n-gram mà ta sử dụng đầu tiên là n = 1. Và trong kết quả, chúng ta có ma trận features bao gồm 25.000 hàng biểu diễn cho 25.000 câu reviews trong bộ dữ liệu huấn luyện, và 75.000 cột biểu diễn cho 75.000 các features mà chúng ta tách ra được. Đây có thể được coi là một feature matrix tương đối lớn.
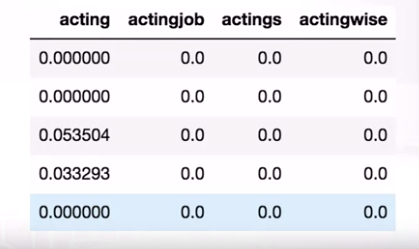
Và một điều nữa đó là đây là một ma trận vô cùng thưa. Chúng ta nhìn thấy rất nhiều vị trí chứa số 0, có thể nhìn thấy 99.8% các vị trí trong ma trận đều là số 0.
Và đối với kiểu features không tốt này, bạn có thể sử dụng linear model - bởi vì nó hoạt động nhanh và tốt với hàng triệu các features, tương tự với Naive Bayes. Ngoài ra, với features chất lượng kém như thế này, bạn không nên sủ dụng Decision Tree bởi vì nó sẽ mất rất nhiều thời gian vì nó tìm kiếm toàn diện trên tất cả các features để thực hiện lần phân chia tiếp theo, tương tự với Gradient Boosted Trees.
Mô hình mà chúng ta có thể sử dụng là mô hình hồi quy logistics. Nó làm việc như sau:
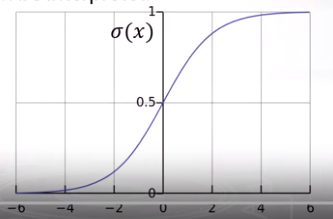
Nó cố gắng dự đoán xác suất của một câu review là positive dựa vào features của câu review tương ứng. Bạn có thể dựa vào các giá trị features TF-IDF để tìm các tham số tương ứng đi với từng feature bằng cách nhân từng features với giá trị TF-IDF sau đó tính tổng của chúng và cho giá trị này đi qua activation sigmoid function. Và đó là cách bạn nhận được logistics regression model. Nó là model nâng cao của linear model khi mà dữ liệu bây giờ là phân bố tuyến tính, linear ko thể biểu diễn được thì logistics regression model fit được hàm phi tuyến này mà vẫn giữ được tư tưởng của linear. Và nó là mô hình phân loại tuyến tính và nó tốt khi nó xử lý được dữ liệu thưa thớt.
Mô hình này có thể train nhanh và hơn nữa các trọng số của chúng có thể giải thích được ý nghĩa sau quá trình train.
Nhìn vào đồ thị của hàm activation sigmoid, nếu bạn có tống tuyến tính các giá trị TF-IDF và weights tương ứng của chúng (ký hiệu là X) thì giá trị đầu ra của hàm activation sigmoid là 0.5, và với giá trị này, chúng ta chưa thể xác định được câu review đầu vào là pos hay neg. Nếu X mà tăng dần thì xác suất là pos sẽ tăng, và ngược lại.
Bạn có thể tưởng tượng rằng, để một câu là pos, thì các trọng số gần như sẽ đi lên theo chiều dương, trong khi câu review là neg thì trọng số sẽ đi theo chiều âm.
Train model
Giả sử, chúng ta train mô hình logistic regression trên bag của 1-grams với giá trị TF-IDF chúng ta sẽ có giá trị accuracy trên tập test là 88.5%. Hãy cùng xem các giá trị weights đi theo từng n-grams để có sự đánh giá, bởi vì mô hình linear model hoàn toàn có thể giải thích được ý nghĩa của nó :

Nếu bạn nhìn vào trong bảng top positive, bạn có thể thấy các giá trị weights của chúng dương và tương đối lớn, trong khi đó, trong bảng top negative, các giá trị weights mang giá trị âm và tương đối nhỏ. Bạn có thể thấy, mặc dù bạn không biết tiếng Anh nhưng bạn vẫn có thể kết luận rằng câu review này là tích cực hay là tiêu cực chỉ bởi các ví dụ có sẵn được đưa ra cho mô hình học.
Tiếp theo, giả sử chúng ta train model trên n-grams to hơn một chút, giả sử 2-grams, thường thì giá trị n trong n-grams ko vượt quá 5. Bởi vì với giá trị n lớn thì thường đến từ lỗi chính tả, hoặc n-grams đó không có ý nghĩa, và nó có thể làm cho mô hình bị overfit khi gặp các trường hợp quá riêng biệt. Cho nên chúng ta sẽ sử dụng n=2 với giá trị ngưỡng của frequency nhỏ nhất có thể lấy, và từ đó bạn có thể nhận được một ma trận features kích thước lớn với 25.000 dòng tương ứng cho các câu reviews và 15.6821 cột tương ứng cho các biểu diễn features.
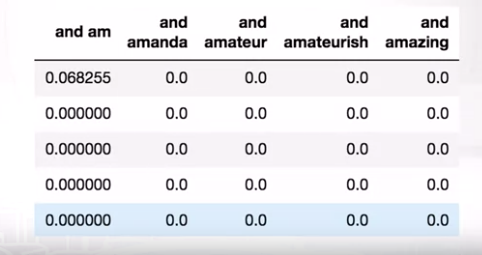
Mặc dù đây là một ma trân tương đối lớn, nhưng chúng ta vẫn sử dụng linear model và nó vẫn hoạt động :

Với việc tăng lên 2-grams, giá trị accuracy đã tăng lên 1.5% so với ban đầu với giá trị 89.9%, gần 90%. Và bạn nhìn vào weight và bạn có thể thấy với n = 2 thì các giá trị weight có tác dụng phân biệt các class tốt hơn, positive lớn hơn và negative nhỏ hơn.
Một vài trick khác để tăng được độ chính xác lên :
- Do trong các câu review có các icon biểu thị cảm xúc, bạn có thể dựa vào các icon này để làm features cũng là một trong những features tốt.
- Thử chuẩn hóa các token dựa vào các kỹ thuật stemming hoặc lemmazation
- Thử các mô hình phân lớp khác : SVM, Naive bayes, ...
Như vậy, mình đã nói qua về mô hình phân loại cảm xúc của các câu review. Hiện tại chưa có code về mô hình này, mình sẽ cập nhật lại vào cuối bài viết trong thời gian tới. Hy vọng các bạn hứng thú với chủ đề này trong NLP. Cảm ơn các bạn đã đọc bài viết.
Mình có sử dụng nội dung dựa vào bài giảng Feature extraction from text trong khóa học Natural Language Processing được tạo bởi National Research University Higher School of Economics. Hẹn gặp lại bạn trong bài viết tiếp theo của mình trong series NLP với chủ đề: Hashing trick in spam filtering (Thủ thuật băm trong lọc thư rác).
All rights reserved
