
Tạo chatbot trên Chatwork tự động giải đáp thông tin về dịch COVID-2020
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào các bạn, có lẽ một trong những tiêu điểm của những tháng đầu năm 2020 đó chính là dịch viêm phổi cấp do chủng mới của virus corona gây ra. Theo ước tính cho tới thời điểm hiện tại ngày 15/2/2020 đã có trên 60.000 lượt nhiễm bệnh và gần 2000 người chết trên khắp thế giới. Để có thể có thêm một kênh thông tin cập nhật real time tình hình dịch bệnh thì hôm nay mình xin phép được hướng dẫn các bạn tạo một chatbot đơn giản trên nền tảng Chatwork để hỏi đáp về các thông tin liên quan đến dịch bệnh nguy hiểm này. Hi vọng qua bài viết này có thể giúp các bạn hình dung một cách dễ dàng hơn cách ứng dụng những thành tựu công nghệ vào trong giải quyết một bài toán thực tế. Bài viết này tuy không mang quá nặng tính kĩ thuật nhưng mình tin nó sẽ có ý nghĩa lớn trong giai đoạn bùng phát của dịch bệnh này. OK chúng ta bắt đầu thôi
Các vấn đề cần giải quyết
 Mục tiêu của mình là xây dựng một chatbot trả lời các thông tin như số ca tử vong, số ca nhiễm mới, số ca được chữa khỏi .... của dịch bệnh COVID 19. Dữ liệu sẽ được cập nhật từng ngày và chatbot có thể giao tiếp qua nền tàng Chatwork - một nền tàng mà mình thường xuyên sử dụng trong công việc. Chính vì thế bài toán này cần phải giải quyết 3 vấn đề lớn sau:
Mục tiêu của mình là xây dựng một chatbot trả lời các thông tin như số ca tử vong, số ca nhiễm mới, số ca được chữa khỏi .... của dịch bệnh COVID 19. Dữ liệu sẽ được cập nhật từng ngày và chatbot có thể giao tiếp qua nền tàng Chatwork - một nền tàng mà mình thường xuyên sử dụng trong công việc. Chính vì thế bài toán này cần phải giải quyết 3 vấn đề lớn sau:
- Vấn đề 1: Cập nhật dữ liệu thường xuyên: Việc cập nhật dữ liệu để vẽ lên các thống kê của dịch bệnh thì cần được thu thập từ những nguồn đáng tin cậy. Ở đây mình có lựa chọn một repo tổng hợp trên github tại đây nguồn dữ liệu ở đây được cập nhật mỗi 12h một lần chính vì thế nên đảm bảo tính cập nhật thường xuyên.
- Vấn đề 2: Xây dựng được hệ thống chatbot Hệ thống chatbot mình xây dựng ở đây nhằm mục đích hiểu được ý định của người người dùng nhằm thực hiện một số phân tích cụ thể
- Vấn đề 3: Xây dựng backend Tất nhiên rồi chúng ta sẽ cần phải có một hệ thống backend để sử dụng làm cầu nối liên kết tất cả các thành phần trên lại với nhau.
Sau khi định nghĩa được các vấn đề cần phải giải quyết rồi chúng ta sẽ tiến hành lựa chọn các công nghệ sử dụng cho các thành phần này. Đây là những công nghệ mà mình thường hay sử dụng trong việc thực hiện các sản phẩm và chính vì thế nên mình sẽ không đi quá sâu giải thích về chúng. Các bạn có thể thực hiện tìm kiếm từ các docs của các công nghệ này hoặc từ các bài viết khác trên Viblo nhé. Sau đây là list các công nghệ mình sẽ sử dụng:
- Django cho backend: Django là một framework rất mạnh mẽ hỗ trợ cho việc triển khai các nền tảng web và API bằng ngôn ngữ Python. Mình sử dụng nó để liên kết các thành phần lại với nhau.
- Pandas cho phân tích dữ liệu sử dụng để đưa ra các số liệu phân tích từ các bảng dữ liệu dạng file excel hay CSV
- RASA cho chatbot sử dụng để tạo chatbot. RASA là một fraemwork khá mạnh mẽ và đặc biệt là nó open ssource và có thể chạy hoàn toàn offline. Trong bài này mình sử dụng RASA NLU - Natural Language Understanding để nhằm phân loại intent từ các câu của người dùng.
- Chatwork SDK cho giao tiếp chatwork: Đương nhiên rồi, nền tảng triển khai ứng dụng trên Chatwork thì không thể thiếu Chatwork SDK được phải không các bạn.

Quy trình thực hiện
Thiết kế hệ thống
Bây giờ chúng ta sẽ từng bước thực hiện hệ thống của mình nhé. Có lẽ bước trước tiên chúng ta cần phải làm đó là thiết kế hệ thống tổng quan để có thể hiểu được flow của ứng dụng. Mô hình chung của hệ thống như trong hình sau:
 Trong hệ thống trên thì luồng dữ liệu được định nghĩa như sau:
Trong hệ thống trên thì luồng dữ liệu được định nghĩa như sau:
- Bước 1: Chatwork gửi event qua webhook Mỗi khi có một sự kiện diễn ra trên chatwork cụ thể ở đây là sự kiện khi có một người dùng gửi tin nhắn cho con bot thì tài khoản chatwork này sẽ gửi một POST request đến webhook được sử dụng để lắng nghe sự kiện. Webhoook này sẽ parse tin nhắn và chuyển tiếp đến bộ NLU của RASA
- Bước 2: RASA nhận diện ý định Sau khi đã thu được message của người dùng thì sử dụng RASA để hiểu được intent của câu nói người dùng. Từ intent đó sẽ quyết định xử lý sao cho phù hợp
- Bước 3: Xử lý intent Bước này bao gồm các xử lý logic đối với từng loại intent, sử dụng pandas để phân tích các số liệu và sinh ra câu trả lời cho phù hợp với người dùng
- Bước 4: Gửi tin nhắn qua Chatwork bước này sử dụng Chatwork SDK để chuyển tiếp tin nhắn sang tài khoản chatwork và hoàn thành flow của ứng dụng.
Tiếp theo chúng ta sẽ tiến hành xây dựng từng thành phần một nhé.
Crawler thông tin dịch bệnh
Như đã nói ở phía trên chúng ta cần phải có được dữ liệu cập nhật một cách nhanh chóng nhất. Điều này được thực hiện bằng cách tự động lấy dữ liệu mới nhất được cập nhật trên github. Dữ liệu được sử dụng cập nhật trong vòng 12h nên mình sẽ sử dụng cache để cache lại các dữ liệu trong vòng 1h trước đó. Mục đích là để đỡ mất công xây dựng DB lưu trữ và cập nhật ý mà. Chúng ta xử lý điều này bằng thử viện cachetools cụ thể như sau:
import requests
import csv
from cachetools import cached, TTLCache
"""
Base URL for fetching data.
"""
base_url = 'https://raw.githubusercontent.com/CSSEGISandData/2019-nCoV/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-%s.csv';
@cached(cache=TTLCache(maxsize=1024, ttl=3600))
def get_data(category):
"""
Retrieves the data for the provided type.
"""
# Adhere to category naming standard.
category = category.lower().capitalize();
# Request the data
request = requests.get(base_url % category)
text = request.text
# Parse the CSV.
data = list(csv.DictReader(text.splitlines()))
Decorator cached sử dụng để lưu lại đầu ra của hàm đó trong một khoảng thời gian nhất đinh. Ở đây chỉ định là 1h. Biến data trong đoạn code trên chứa toàn bộ dữ liệu mà chúng ta cần. Có thể để ý thấy chúng ta có 3 loại category trên trang github chứa data biểu thị số lượng người confirm, số lượng người chết và số lượng đã chữa khỏi. Chúng ta có thể chế thêm một loại category nữa biểu thị thông tin tổng hợp của cả ba loại trên
Phân tích các kết quả
Sau khi thực hiện xong chúng ta cần thực hiện phân tích các kết quả để đưa ra các con số thống kê như số lượng tại thời điểm hiện tại và thời gian cập nhật của dữ liệu. Chúng ta add thêm vào hàm trên những thông tin sau
for item in data:
# Filter out all the dates.
history = dict(filter(lambda element: date_util.is_date(element[0]), item.items()))
# Normalize the item and append to locations.
locations.append({
# General info.
'country': item['Country/Region'],
'province': item['Province/State'],
# Coordinates.
'coordinates': {
'lat': item['Lat'],
'long': item['Long'],
},
# History.
'history': history,
# Latest statistic.
'latest': int(list(history.values())[-1]),
# Latest datetime.
'latest_date': date_util.to_date(list(history.keys())[-1]).strftime("%d/%m/%Y"),
})
# Latest total.
latest = sum(map(lambda location: location['latest'], locations))
vn_latest = sum([location['latest'] for location in locations if location['country'] == 'Vietnam'])
# Return the final data.
return {
'locations': locations,
'latest': latest,
'vn_latest': vn_latest,
'global_latest': latest - vn_latest,
'latest_date': locations[0]['latest_date']
}
Xây dựng chatbot
Đối với việc xây dựng chatbot bằng RASA đã có khá nhiều bài viết trên VIblo giới thiệu về vấn đề này. Các bạn có thể tham khảo thêm chi tiết từ các bài viết trên đó. Ở đây mình chỉ lưu ý một số điểm như sau:
Config cho support tiếng Việt
SAu khi khởi tạo rasa bằng câu lệnh
rasa init --no-prompt
các bạn sẽ thu được một tập hợp các file như sau:
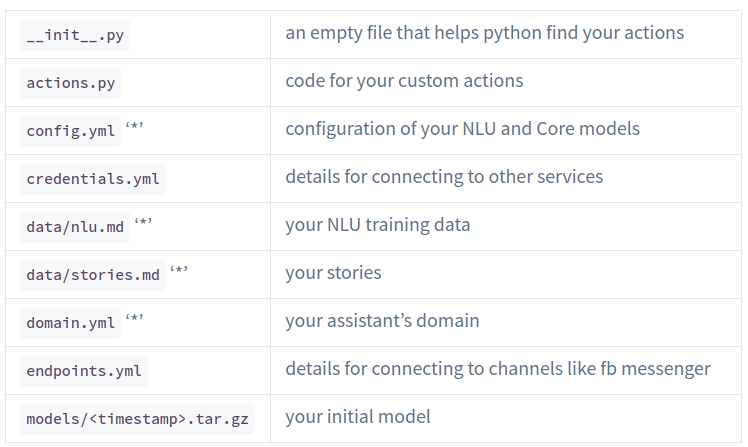
Các file này đều có ý nghĩa của nó tuy nhiên để sử dụng RASA cho tiếng Việt một cách chính xác nhất thì chúng ta cần để ý đến file config
# Configuration for Rasa NLU.
# https://rasa.com/docs/rasa/nlu/components/
language: vi
pipeline: supervised_embeddings
Do mục đích của mình chỉ cần detect intent nên mình thấy sử dụng pipeline supervised_embeddings khá ổn đối với những data được làm cẩn thận. Các bạn cũng có thể thử nghiệm các pipeline khác theo docs chuẩn của rasa tại đây
Xây dựng model
Việc xây dựng model trong RASA khá đơn giản, các bạn chỉ cần định nghĩa sẵn các intent theo ý muốn của mình sao cho gần khớp với ngôn ngữ tự nhiên nhất. Ở đây mình không sử dụng RASA Core để quản lý hội thoại mà chỉ sử dụng NLU thôi. Việc xử lý hội thoại sẽ được xử lý bằng phần backend sẽ trình bày sau. Ở đây mình có 4 loại intent khác nhau đó là:
- ask_all - hỏi thông tin tình hình chung của dịch
- ask_resolve - hỏi về thông tin các ca đã chữa khỏi
- ask_death - hỏi về thông tin các ca đã tử vong
- ask_confirm - hỏi về thông tin các ca đã mắc bệnh
Đây là một số ví dụ về dữ liệu của RASA NLU. Các bạn truy cập thử thư mụcdata/nlu.mdnhé.
## intent:ask_death
- bao người chết rồi
- có bao nhiêu người chết
- có nhiều người chết chưa
- bao người tử vong rồi
- có nhiều người tử vong chưa
- bao người thiệt mạng rồi
- có bao nhiêu người thiệt mạng
- hiện có bao nhiêu người thiệt mạng rồi
- có nhiều người thiệt mạng chưa
- hiện có bao nhiêu người tèo rồi
- có bao nhiêu người bệnh bị chết
## intent:ask_confirm
- bao người nhiễm rồi
- có bao nhiêu người nhiễm
- con số người nhiễm là bao nhiêu
- hiện có bao nhiêu người nhiễm rồi
- có nhiều người nhiễm chưa
- bao người lây bệnh rồi
- có bao nhiêu người bị mắc bệnh
- con số người mắc bệnh là bao nhiêu
- hiện có bao nhiêu người mắc bệnh rồi
- có nhiều người mắc bệnh chưa
## intent:ask_resolve
- bao người khỏi bệnh rồi
- có bao nhiêu người khỏi bệnh
- con số người khỏi bệnh là bao nhiêu
- hiện có bao nhiêu người khỏi bệnh rồi
- có nhiều người khỏi bệnh chưa
- số trường hợp khỏi bệnh là bao nhiêu
- nhiều người được chữa khỏi chưa
## intent:ask_all
- tình hình dịch bệnh thế nào
- dịch bệnh tiến triển thế nào
- xem thống kê dịch bệnh
- xem chi tiết dịch bệnh
- dịch bệnh thế nào rồi
- dịch bệnh ra sao rồi
Các bạn có thể thêm nhiều mẫu câu khác cho tự nhiên để model có chất lượng tốt hơn
Training model
Rất đơn giản các bạn chỉ cần chạy lệnh
rasa train
Đánh giá model
Để thử nghiệm model các bạn cần test thử thông qua API. Đầu tiên các bạn chạy server RASA để expose API
rasa run --enable-api
Sau đó sử dụng Postman hoặc cURL để test. Ví dụ như sau:
curl -X POST \
http://localhost:5005/model/parse \
-H 'cache-control: no-cache' \
-H 'content-type: application/json' \
-H 'postman-token: a2d8b805-addc-514a-afeb-952cc06fecf7' \
-d '{
"text": "hiện có bao nhiêu người được chữa khỏi rồi"
}'
Tùy thuộc vào response thu được chúng ta sẽ tiến hành làm dữ liệu để có được một model tốt nhất.
Xây dựng backend
Chúng ta sẽ cần một số class để xử lý phần backend với framework Dajngo. Cụ thể đối với RASA thì chúng ta cần có class xử lý handle mesage gửi lên.
import requests
import json
from backend.settings import RASA_DOMAIN, RASA_NLU_POST_URL, RASA_MIN_CONFIDENCE
class RasaHelpers():
def __init__(self):
self.headers = {
'Content-Type': "application/json",
'Host': RASA_DOMAIN,
}
self.url = RASA_NLU_POST_URL
def detect_intent(self, response):
if response['intent']:
if response['intent']['confidence'] > RASA_MIN_CONFIDENCE:
return response['intent']['name']
return "fallback"
def post_nlu(self, message):
payload = {
"text": message
}
response = requests.request("POST", self.url, data=json.dumps(payload), headers=self.headers)
return json.loads(response.text)
def handle_message(self, message):
response = self.post_nlu(message)
intent = self.detect_intent(response)
# Logic here
Trong đó hàm post_nlu sử dụng để giao tiếp với server RASA và hàm detect_intent để tìm ra intent của câu xử lý. Hàm handle_message sử dụng để xử lý đầu ra của NLU, sau khi detect được intent của mesage. Phần này mình không đi quá sâu. Các bạn có thể tham khảo trên source code mình chia sẻ trên github ở link phía dưới nhé.
Kết nối với Chatwork
Phần này mình cũng đã hướng dẫn khá kĩ trong bài Xây dựng chatbot tự động chat trên Chatwork với Chatterbot và Django mọi người có thể tham khảo và đọc thêm trong code nhé. Đây là một class cơ bản để xử lý các tác vụ liên quan đến Chatwork
import requests
import json
from backend.settings import CHATWORK_API_TOKEN
class Chatwork():
# Token Header key
TOKEN_HEADER_KEY = "X-ChatWorkToken"
def __init__(self):
self.apiToken = CHATWORK_API_TOKEN
self.reqHeader = {Chatwork.TOKEN_HEADER_KEY: self.apiToken}
def send_message(self, room_id, message):
uri = "https://api.chatwork.com/v2/rooms/" + str(room_id) + "/messages"
data = {"body": message}
req = requests.post(uri, headers=self.reqHeader, data=data)
return json.loads(req.text)
def reply_message(self, account_id, room_id, message_id, message):
return "[rp aid={%ld} to={%ld}-{%ld}]\n%s" % (account_id, room_id, message_id, message)
Source code
Các bạn có thể tham khảo source code tại đây
Demo ứng dụng
Thử một vài kịch bản demo như hình bên dưới hoặc kết bạn với con bot để trải nghiệm nhé. Nếu thấy model chưa tốt bạn có thể bổ sung thêm dữ liệu cho nó tốt hơn nhé
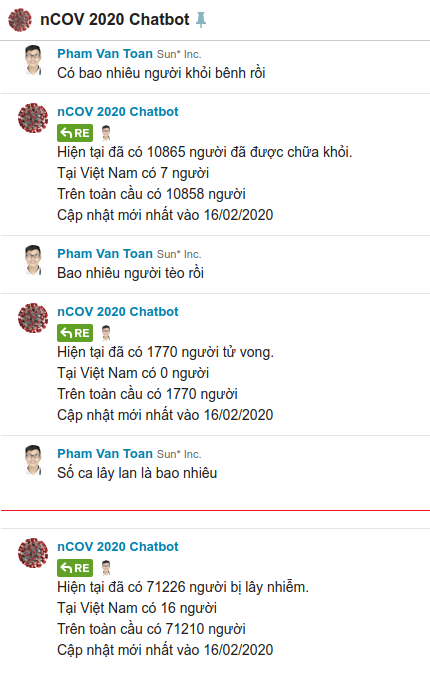
Các bạn có thể kết bạn với con bot như hình bên dưới nhé
Hướng phát triển tiếp theo
Chatbot này được phát triển cho nền tàng Chatwork tuy nhiên chúng ta hoàn toán có thể extend thêm để có thể support nhiều nền tàng khác như Facebook, Telegram hay nhúng và một web ... Hơn nữa ứng dụng này hoàn toàn có thể cập nhật thêm nhiều nguồn thông tin mới nữa như crawler và phân tích thông tin từ các báo mạng, lắng nghe thông tin từ các mạng xã hội .... Hi vọng là có đủ thời gian để cập nhật tiếp những chức năng cho ứng dụng này và một điều hi vọng rất lớn nữa đó là dịch bệnh sẽ sớm qua mà không để lại nhiều hậu quả nghiêm trọng. Chúc các bạn luôn mạnh khỏe và cảm ơn các bạn đã đọc bài viết này.
All rights reserved
