
Tất tần tật về LLaMA-2 - liệu có đủ làm nên một cuộc cách mạng mới
Bài đăng này đã không được cập nhật trong 3 năm
Lời giới thiệu
Xin chào tất cả các bạn, đã lâu lắm rồi kể từ sau bài viết về Trải lòng sau khi đọc GPT-4 Technical Report của OpenAI - các bác nên đổi tên công ty đi mình không có viết bài về LLM nữa. Không phải vì mình không còn quan tâm đến lĩnh vực này mà bởi vì một phần mình chưa thực sự gặp được một LLM nào đủ hay về mặt kĩ thuật để chia sẻ đến tất cả mọi người, một phần vì mình đang tập trung cho một số dự án chia sẻ trên kênh Youtube mới của mình mang tên EZTech - Lập trình tương lai của bạn. Nhưng hôm nay thực sự mình lại phải ngoi lên đây để hú lên cho các bạn biết là mình lại một lần nữa phải thức đêm để đọc paper dài 76 trang của LLaMa-2. Và mình nghĩ lần này mình đã không hề hối hận khi làm điều đó. Thật sự phải nói với bạn rằng sau khi đọc xong paper này mình chỉ muốn thốt lên như Bác hồ đọc được luận cương Lê-nin - chỉ biết nói một câu duy nhất:
HẠNH PHÚC LÀ ĐÂY, CƠM ÁO ĐÂY RỒI - Meta muôn năm, Mark Zúc ker bớt number one....
Thôi, bú phame idol thế đủ rồi, quay lại chủ đề chính thôi. LLaMa-2 paper khác hoàn toàn paper của GPT-4 mà mình đã nói ở các điểm:
- Giải thích rõ ràng tất cả các khái niệm kĩ thuật, từ kiến trúc mô hình, các tạo dữ liệu, cách huấn luyện, cách đánh giá cũng như cách cải thiện độ an toàn, độ hữu ích của mô hình
- Cung cấp mã nguồn mở và đặc biệt là cho phép sử dụng dưới mục đích thương mại
- Cung cấp cả dữ liệu với chất lượng cực cao cho mọi mục đích từ nghiên cứu đến tạo ra mô hình của mình.
Rồi chắc không cần phải nói nhiều nữa, chúng ta sẽ bắt đầu ngay vào chi tiết paper này thôi. Let's go
P/S: Sau khi viết xong bài viết này mình mới nhìn ra còn số thời gian đọc của Viblo tính bài này của mình thì.... má ơi.... 37 phút đọc lận. Chắc các bạn ghét mình quá. Nhưng thôi các bạn chịu khó đọc nhé, mình đã phải đọc 76 trang paper để tóm gọn hết mức có thể cho các bạn rồi. Còn nếu như bạn nào lười đọc thì mình sẽ có video giải thích ngắn gọn hơn, Khi nào có video mình sẽ cập nhật cho các bạn sau.
Trải nghiệm nhanh
Các bạn có thể trải nghiệm nhanh mô hình LLaMA-2 này tại https://llama.perplexity.ai/. Với những kĩ thuật caching thần sầu của perplexity cùng với sự tối ưu của LLaMa-2 chắc chắn bạn sẽ cảm thấy nó nhanh như tên lửa vậy. Mình có cảm giác chúng ta không hề nói chuyện với LLM mà như đang search google vậy. Kết quả sinh ra cũng khá ổn và đầy đủ nha các bạn dù mình mới đang dùng phiên bản 13B thôi.
LLaMa-2 là gì?
Nói một cách ngắn gọn thì LLaMa-2 là phiên bản tiếp theo của LLaMa - một mô hình ngôn ngữ lớn được tạo ra bởi Facebook AI Research và đội ngũ kĩ sư của họ. Mô hình này về mặt kiến trúc thì có vẻ tương tự như LLaMa nhưng được bổ sung thêm dữ liệu, cải thiện chất lượng cũng như đưa thêm các phương pháp tối ưu mới để đạt được hiệu suất cao hơn. Mô hình này cho benchmark vượt trội hơn hẳn so với các open source model khác và đặc biệt là nó open source cả model, dữ liệu và cho phép sử dụng trong mục đích thương mại.
Mô hình này được đội ngũ kĩ sư hùng hậu của Facebook AI Research tạo ra. Có đến gần 50 người đứng tên trong paper

Điều kì lạ là mình tìm mỏi mắt vẫn không thấy bác Yann Lecun - idol của mình ở đâu. Chắc có thể là bác đang bận một dự án khác hoặc là contribution của bác chưa đủ lớn đến mức được ghi tên vào paper này chăng ??? Một điểm lạ nữa là tên tổ chức đã đổi thành GenAI - Meta. Đây có thể là một bộ phận độc lập của FAIR chăng.
Rồi quay lại với LLaMA-2 thì họ release 2 phiên bản là pretrained LLM LLaMa-2 và một bản finetuned riêng cho tác vụ chat gọi là LLaMa-2-CHAT. Hai phiên bản này lại gồm nhiều biến thể với số lượng tham số từ 7B đến 70B. Điểm mới của mô hình này so với LLaMA-1 là:
- Context length tăng từ 2048 lên 4096 giúp cho mô hình có thể capture được nhiều thông tin ngữ cảnh hơn.
- Pretraining corpus được tăng kích thước lên 40% bằng việc bổ sung thêm nhiều dữ liệu chất lượng của Meta
- Áp dụng kĩ thuật Grouped Query Attention tại đây để làm tăng độ hiệu quả khi inference
Có thực sự Open Source hay không
Theo cá nhân của mình thì LLaMa-2 vẫn chưa thực sự được coi là Open Source, Lý do ở một ssoos điểm như sau:
- Thứ nhất họ chỉ cung cấp mô hình đã được fine-tune và cách huấn luyện thông qua technical report. Họ không cung cấp code training, dữ liệu để huấn luyện, và một yếu tố rất quan trọng đó là họ không cung cấp reward model - là một trong những thành phần quan trọng nhất để huấn luyện RLHF.
- Thứ hai: Các bên sử dụng cũng bị giới hạn và có một số điều khoản khá nghiêm ngặt ví dụ chỉ áp dụng cho các công ty có active user nhỏ hơn 700 triệu hàng tháng, tức là họ hướng tới các doanh nghiệp nhỏ và startup nhỏ

Mặc dù nó không hẳn là OS nhưng từ góc độ một người làm kĩ thuật, mình đánh giá cao công sức của họ. Thực sự là technical report của họ có rất nhiều yếu tố kĩ thuật mà chúng ta có thể học được và mình tin rằng đối với cộng đồng và các doanh nghiệp nhỏ thì đây thực sự là một bước ngoặt lớn về tiến bộ công nghệ.
Kiến trúc của mô hình
Trong paper tác giả không nói rõ về kiến trúc mô hình, họ chỉ tiết lộ rằng kiến trúc mô hình tuần theo kiến trúc Transformer chuẩn và tương tự như kiến trúc của LLaMA-1. Vậy thì để hiểu sâu hơn về kiến trúc của LLaMa-2 chúng ta sẽ tìm hiểu qua về kiến trúc của mô hình LLaMa.
Cả kiến trúc của LLaMa và LLâM-2 đều là các Generative Pretrained Transformer dựa trên kiến trúc Transformer. Chúng ta có thể tham khảo source code của nó tại đây. Về cơ bản nó có một số điểm khác biệt so với kiến trúc GPT tiêu chuẩn:
- LLaMa sử dụng RMSNorm để chuẩn hoá input dầu vào cho mỗi layer transformer thay vì đầu ra
- Sử dụng SwiGLU activation thay vì ReLu giúp cho improve performance của quá trình huấn luyện
- Sử dụng phương pháp tương tự như trong GPT-Neo-X LLaMA sử dụng rotary positional embeddings (RoPE) trong các layer của mạng
Theo như report trong paper của LLaMa-2 thì họ chỉ thay đổi duy nhất trong kiến trúc nằm ở kích thước của context length và sử dụng grouped-query attention. Việc tăng kích thước của conetxt length giúp cho mô hình có thể tạo ra và xử lý được nhiều thông tin hơn, nó rất thuận tiện cho việc hiểu các long documents. Việc thay thế* multi-head atttention trong kiến trúc Transformer tiêu chuẩn - có nhiều query có thể tương ứng với một key-value projection thành grouped-query attention với 8 key-value projection cho phép tăng tốc độ huấn luyện, nó giúp dễ dàng tăng độ phức tạp của mô hình cũng như tăng batchsize và context length.
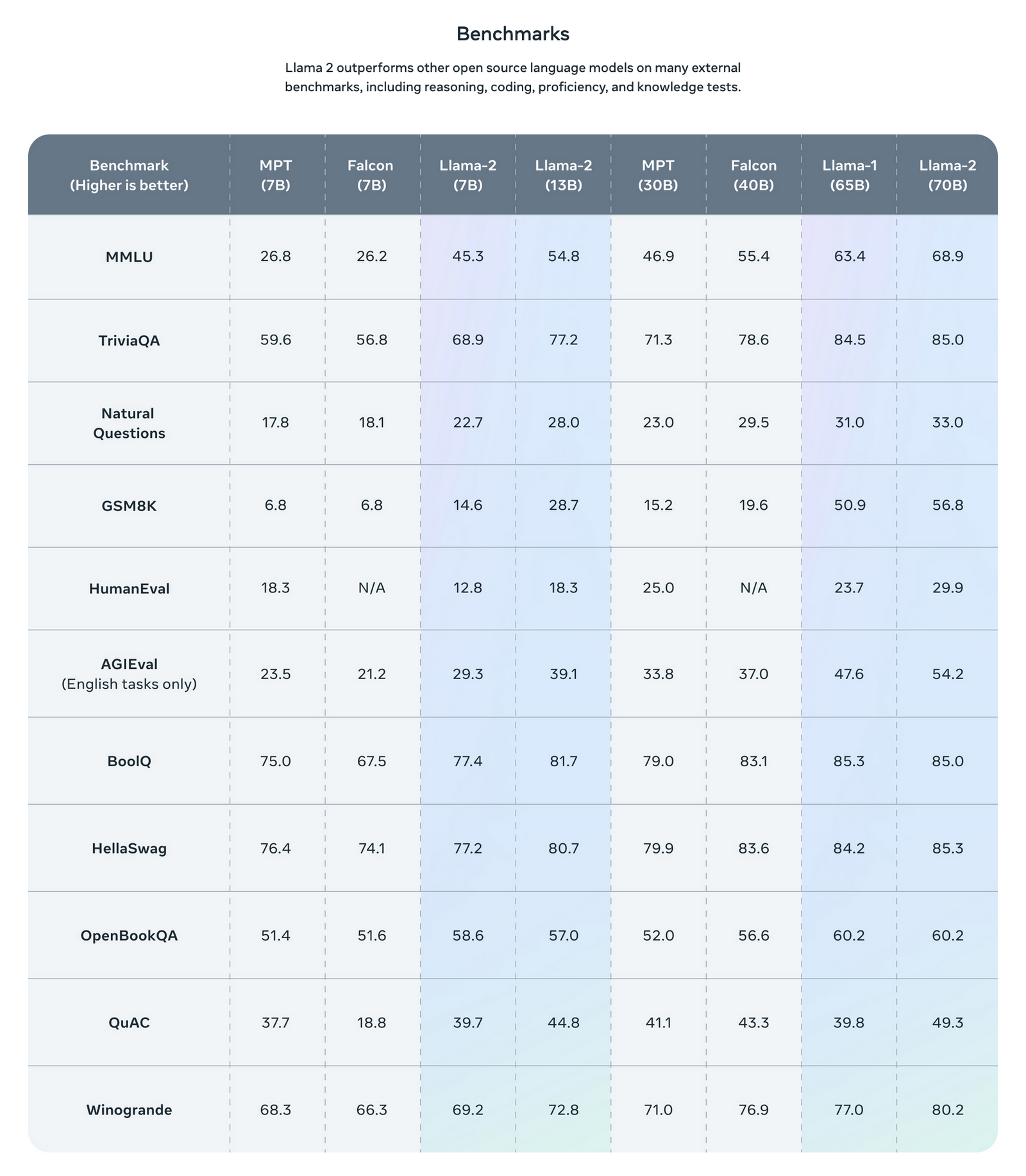
Những thay đổi này giúp cho mô hình LLaMa-2 có thể xử lý tốt hơn nhiều mô hình open source LLM trước đó trong nhiều tác vụ khác nhau như Falcon hay MPT. hi vọng rằng với động thái cung cấp mã nguồn mở thì chỉ trong vòng một thời gian ngắn nữa chúng ta sẽ có các phiên bản LLaMa có thể cạnh tranh được với GPT-4 và Google Bard.
Rồi, nhìn chung phần mô hình này cũng không có nhiều điều dể nói. Phần lớn thời gian của paper này viết về cách huấn luyện cũng như đảm bảo độ án toàn của mô hình hình hơn là nói về kiến trúc. Thế mới biết là kiến trúc mô hình quan trọng nhưng các kĩ thuật về xử lý dữ liệu và phương pháp huân luyện còn quan trọng hơn gấp nhiều lần. Hoặc có thể họ không muốn nói đến những kĩ thuật dạng kinh nghiệm bí truyền của các kĩ sư tại FAIR trong việc chọn lựa mô hình và lý do tại sao họ lại lựa chọn như vậy. Đây có thể coi là một trong những lợi thế để đội ngũ kĩ sư của FAIR có thể giữ vị trí đứng đầu trong việc tạo ra các LLM nguồn mở.
Bản thân mình cũng nghĩ rằng sức mạnh của LLM nằm ở khả năng biểu diễn thông tin khổng lồ của nó do kích thước mô hình lớn và các thức xây dựng dữ liệu huấn luyện. Các bạn có thể tham khảo trực tiếp source code của LLaMa-2 tại đây. Nó hoàn toàn không có gì bí mật ở đây cả. Vậy nên có một phát ngôn trong khoa học gần đây là các ông nghiên cứu chẳng cần làm gì cả, hãy tập trung làm cho mô hình đủ lớn, bởi bản thân mô hình lớn nó có rất nhiều tính chất hay mà mô hình nhỏ không có được. Tựu chung lại thì nó vẫn là lấy thịt đè người.
Cách huấn luyện như thế nào
Đây có thể coi là linh hồn của việc huấn luyện ra các mô hình ngôn ngữ lớn, như mình đã nói ở phía trên thì điểm quan trọng nhất không nằm ở kiến trúc mô hình mà nó nằm ở dữ liệu và cách họ huấn luyện mô hình đó. Về dữ liệu thì lát nữa chúng ta sẽ bàn bạc sau nhưng mình muốn nói trước hết đến kĩ thuật huấn luyện và fine-tuning LLM với kĩ thuật RLHF. Đây có thể coi là mấu chốt trong huấn luyện LLaMa-2 mà cũng là phần mình đã nghe thấy rất nhiều nhưng chưa có một paper nào giải thích cụ thể cách thức triển khai nó cho đến paper của LLaMa-2 thì mọi thứ đã không còn là bí mật nữa. Mình chỉ muốn nói với các bạn hai từ thôi XUẤT SẮC. Tổng quan về các huấn luyện và fine-tuning mô hình với RLHF các bạn có thể tham khảo trong hình sau
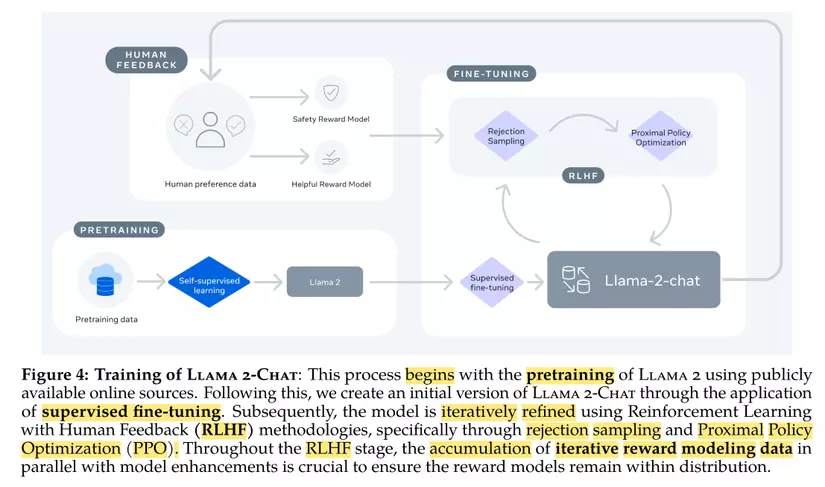
Tồng quan của quá trình này có thể tóm gọn lại trong 3 bước:
- Pretraining: Huấn luyện một foundation model sử dụng các nguồn dữ liệu online có sẵn với kĩ thuật training sử dụng self supervised learning như các mô hình Transformer gốc.
- Supervised Finetuning: Tạo ra một phiên bản đầu tiên của LLaMa-2-Chat sử dụng tập dữ liệu được gán nhãn sẵn bởi con người, tập dữ liệu này có dạng instruction bao gồm prompt và câu trả lời tương ứng.
- RLHF: Sau đó mô hình được tinh chỉnh liên tục dựa trên kĩ thuật RLHF thông qua hai thuật toán là PPO và Rejection Sampling. Trong quá trình RLHF, mô hình tính toán toán reward được cập nhật liên tục song song với mô hình Chat để đảm bảo rằng hai mô hình này có distribution của dữ liệu giống nhau. Tiếp theo chúng ta sẽ cùng nhau đi vào chi tiết từng phần chính trong paper này nhé
Bước Pretraining
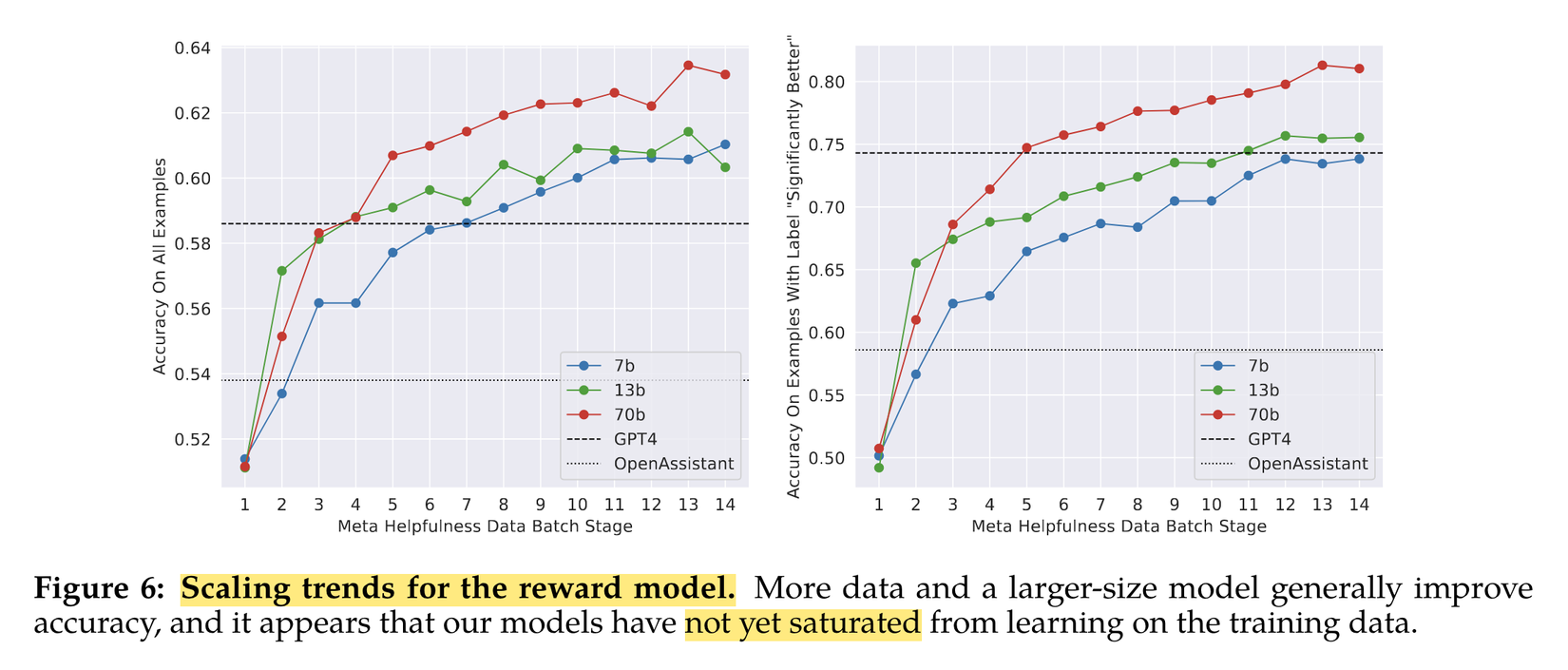
Bước đầu tiên là Pretraining tức là huấn luyện mô hình transformer trên một tập dữ liệu rất lớn sử dụng các kĩ thuật self-supervised learning. Nói đến kĩ thuật này thì nó là một kĩ thuật được sử dụng phổ biến giúp mô hình có thể học được từ nội tại dataset thông qua các phép biến đổi trực tiếp trong dữ liệu. Ví dụ các bạn có thể che đi một vài từ trong câu để bắt mô hình dự đoán các từ bị che. Điểm mấu chốt ở đây, là họ sử dụng thêm khoảng 40% dữ liệu kết hợp với các nguồn dữ liệu có sẵn và họ dành rất nhiều effort để lọc các thông tin cá nhân có thể gây độc hại cho mô hình. Nên có thể coi đây là một tập dữ liệu khá sạch. Tập dữ liệu này khoảng 2 trillion tức 2000 tỉ tokens. Họ huấn luyện mô hình Transformer sử dụng thuật toán AdamW, sử dụng learning rate scheduler với warmup 2000 bước đầu tiên. Điểm thú vị là sau khi train với 2000 tỉ token thì training loss vẫn chưa có dấu hiệu bão hoà, tức là nếu tiếp tục bổ sung thêm dữ liệu và thời gian training thì có thể chúng ta sẽ thu thập được mô hình tốt hơn. Tuy nhiên rằng với phiên bản hiện tại của LLaMa đã đủ out-perform tất cả các open source model khác trên các chỉ số benchmark khác nhau. Và cũng có kết quả khá cạnh tranh với các closed source LLM như ChatGPT nhưng có vẻ vẫn kém khá xa so với GPT-4. Điều này cũng dễ hiểu thôi bởi không có cái gì vừa ngon, bổ, rẻ (thậm chí là free) lại còn được nhiều phải không các bạn. Nhưng mình nghĩ rằng với sự phát triển của cộng đồng thì chắc chắn chỉ một thời gian nữa thôi sẽ có rất nhiều phiên bản mới của LLaMa tiệm cận với các closed source LLM. Chúng ta hãy cùng chờ đợi thêm nhé.
Supervised Finetuning
Chất lượng dữ liệu là yếu tố quan trọng nhất trong việc fine-tuning mô hình. Tuy nhiên, việc sử dụng hàng triệu dữ liệu third-party SFT từ nhiều nguồn khác nhau có thể gặp phải vấn đề về tính đa dạng và chất lượng. Thay vào đó, tác giả tập trung vào việc sử dụng một tập nhỏ hơn nhưng có chất lượng dữ liệu cao hơn từ đội ngũ làm dữ liệu của mình. Kết quả cho thấy rằng chỉ cần khoảng 10000 mẫu dữ liệu để đạt được hiệu quả tốt. Sau khi có mô hình pretrained, tác giả tiến hành fine-tuning sang dữ liệu dạng chat. Họ sử dụng instruction tuning với các dữ liệu public để làm mồi cho mô hình. Quá trình fine-tuning được thực hiện với batchsize 64 và độ dài chuỗi là 4096. Để đảm bảo độ dài chuỗi của mô hình được điền đầy đủ, tất cả các câu hỏi và câu trả lời từ tập huấn luyện được ghép lại với nhau bằng một token đặc biệt để phân tách phần câu hỏi và phần câu trả lời. Việc backpropagation chỉ được thực hiện trên các token trong phần câu trả lời. Mô hình được fine-tune trong 2 epochs.
Thực hiện RLHF
Đây là phần mà mình thấy cực kì hay trong paper này, Meta đã chỉ ra cho chúng ta cách mà họ dùng kĩ thuật RLHF để cải thiện chất lượng của mô hình như thế nào. Nó không chỉ là những khái niệm hay các lý thuyết mơ hồ như trong các report khác của GPT-4 mà nó rất chi tiết,
Trước hết mình muốn nói đến mục tiêu của huấn luyện LLM là để có thể alignment hay còn gọi là điều chỉnh mô hình cho phù hợp với sở thích và hành vi của con người. Để thực hiện căn chỉnh này người ta đề xuất ra kĩ thuật RLHF. Trong RLHF chúng ta cần quan tâm đến hai yếu tố:
-
Reinforcement Learning: Trước hết nói về Học tăng cường RL: thì là kĩ thuật của học máy giúp các huấn luyện ra các mô hình để tối đa hoá một reward nào đó. Trong trường hợp của LLM thì reward ở đây có thể hiểu chính là cái cảm xúc của con người, họ thấy hay, họ thấy wow, họ thấy hữu ích, họ thấy tự nhiên với một câu trả lời của chatbot. Tuy nhiên một yếu tố khó khăn ở đây là có những trường hợp rất dễ tính reward như chơi trò chơi chẳng hạn. Nhưng như trường hợp bài toán LLM thì reward function lại rất khó định nghĩa vì. nó thiên về cảm tính hơn.
-
Human feedback: chính là cái đánh giá của con người trên những kết quả trả ra của mô hình, đánh giá này sẽ được lượng hoá bằng một số điểm cụ thể. Các điểm đánh giá này được sử dụng để huấn luyện mô hình tính toán phần thưởng gọi là Reward Model. Mình xin nhắc lại rằng Reward Model chính là linh hồn của kĩ thuật RLHF, và Meta cũng đã tốn rất hiều công sức để tạo ra một cái Reward Moel thật sự đủ tốt. Cách để tạo ra một reward model như thế nào chúng ta sẽ nói rõ hơn trong các phần sau.
Sau khi có một reward model, nó cũng là một mạng nơ ron thì người ta sử dụng các chiến lược huấn luyện RLHF phổ biến để huấn luyện
- PPO
- Rejection Sampling
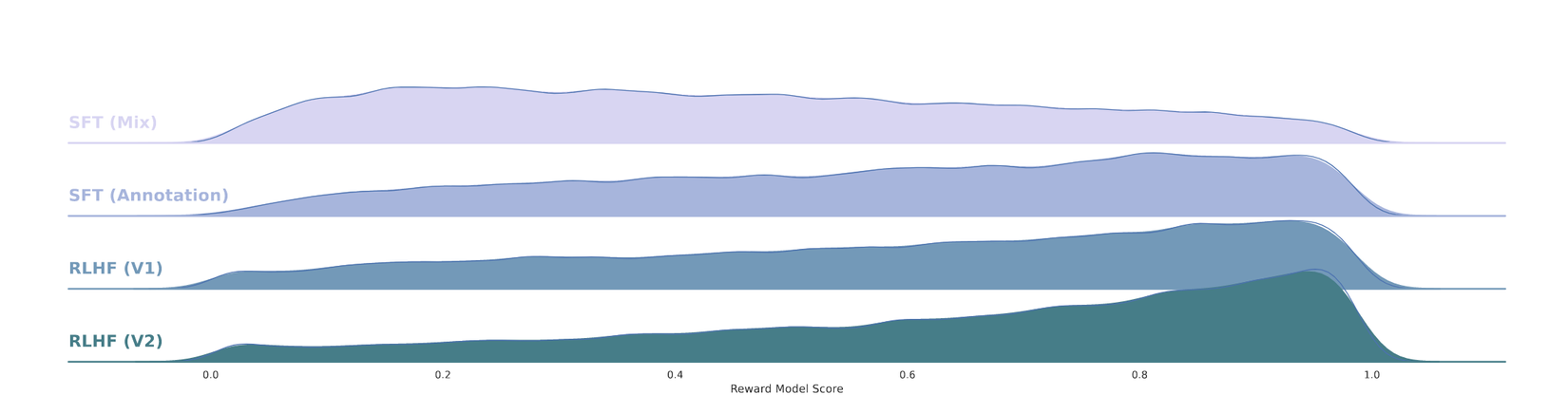
Trong quá tình tuning thì reward model sẽ cập nhật liên tục với các dữ liệu mới. Trước khi nói rõ hơn về cách thức huấn luyện reward model. Chúng ta sẽ cùng nhau tìm hiểu các họ xây dựng tập dữ liệu. RLHF giúp cho mô hình ngày càng gần hơn với phân phối thực tế, trên màn hình các bạn có thể nhìn thấy sự chuyển dịch phân phối từ mô hình được huấn luyện với Superivsed Fine-tuning sang phân phối của RLHF. Có thể thấy phân phối RLHF càng gần với con người hơn.
Cách xử lý dữ liệu
Một điểm đáng chú ý của paper này đó chính là Meta đã công khai thừa nhận một yếu tố quan trọng nhất trong việc huấn luyện LLM với phương pháp RLHF đó chính là Reward Modeloing. Trước đây mình có hóng được trên Twitter từ một số người có liên quan đến OpenAI đã đồn đoán rằng, việc thành công của các mô hình học với RLHF nằm chính ở chỗ học reward function. Hay nói cách khác, chìa khoá của RLHF chính là reward model. Chúng ta cũng đã biết rằng, thuật toán Reinforcêmnt learning sẽ cần một hàm đính tính toán reward. Có nhiều bài toán rất dễ để đưa ra reward nhưng cũng có những bài toán rất khó để đưa ra nhưng việc đánh giá text sinh ra có hữu ích hay không chẳng hạn. Nó là một yếu tố hết sức định tính. Chính vì thế để thiết kế ra được một reward funciton chuẩn cho bài toán đánh giá text này, Meta đã rất hao tâm tốn sức để tạo ra được các tập dữ liệu mà có reward cao theo cách hiểu của con người. Tập dữ liệu này gọi là preference data.
Ở đây mình xin tóm tắt lại một vài điểm chính trong cách làm dữ liệu của họ như sau:
- Thu thập các binary comparisons từ người gán nhãn. Tức là với mỗi một prompt đầu vào họ sẽ lấy ra 2 câu trả lời cho prompt đó. Người gán nhãn sẽ đánh giá hai câu trả lời này và lựa chọn 1 trong hai. Annotator cũng đưa ra các mức đánh giá định tính như significantly better, better, slightly better, or negligibly better/ unsure.
- Sử dụng multi-turn preferences điều này có nghĩa răng người ta sẽ sử dụng các câu trả lời từ các checkpoints khác nhau của mô hình kết hợp với sự thay đổi tham số temperature để có thể sinh ra đa dạng câu trả lời của một prompt. Việc tăng tính đa dạng rất có lợi cho việc huấn luyện mô hình với RLHF sau này.
- Tập trung vào giải quyết hai vấn đề mà họ mong muốn LLaMA-2 sẽ sinh ra đó là helpfulness and safety và sử dụng hai guideline riêng biệt cho mỗi data vendor. Họ ưu tiên mức độ an toàn của câu trả lời sinh ra bởi mô hình nhiều hơn. Trong paper, các tác giả sử dụng safety metadata trong quá trình huấn luyện và đảm bảo rằng không có dữ liệu thiếu an toàn nào được đưa vào finetuning. Họ không trình bày xem các metadata này được tạo ra với mục đích nào khác và còn các loại metadata nào khác trong dữ liệu hay không nhưng mình đoán sẽ có một số loại metadata khác như prompt dễ gây nhầm lẫn chẳng hạn.

- Họ tiến hành thu thập dữ liệu một cách liên tục theo batch hàng tuần để có thể phục vụ cho việc quản lý phân phối của dữ liệu, tức là sau mỗi tuần thì batch dữ liệu mới sẽ được sử đụng dể huấn luyện reward model và chat model để tránh sự khác biệt về mặt phân phối của dữ liệu. Khi reward model được cải thiện thì Chat model cũng được nâng chất lượng lên tương ứng.
Reward modeling
Cách thức huấn luyện
Như đã nói ở phía trên, việc training một reward model tốt có thể coi là yếu tố then chốt dẫn đến thành bại của kĩ thuật RLHF. Trong paper này tác giả trình bày chi tiết về xây dựng reward model. Họ có hai reward model riêng biệt:
- Sử dụng riêng biệt hai reward model cho hai khía cạnh khác nhau là độ an toàn safety và độ hữu dụng helpfulness
- Sử dụng scaling law để tính toán số lượng dữ liệu và tài nguyên càn thiết cho huấn luyện reward model
Để làm rõ hơn về hai mô hình này, trong paper có nói rằng reward model được chia làm hai loại, một loại tối ưu cho tính an toàn safety và một loại được otois ưu cho tính hữu ích helpfulness. Cả hai mô hình này đều được base trên mô hình chat (tức là LLaMa-2-CHAT) chỉ khác mỗi một điều là thay thế các head của mô hình ngôn ngữ (next-token prediction) thành regression head để đầu ra là scalar. Về lý do tại sao lại sử dụng chung một base model với Chat model thì họ có giải thích răng để cho In short, the reward model “knows” what the chat model knows tức là hai mô hình này share cùng một bộ não, tránh việc suy luận nhập nhằng, không tương ứng. Vậy nên họ sử dụng các checkpoint gần nhất của chatmodel để làm base cho reward model.
Một vài lưu ý khi huấn luyện
Một vài lưu ý về mặt kĩ thuật mình có note lại như sau:
- Về cách tổng hợp data: học sử dụng các data nguồn mở kết hợp với data của họ tự annotate để huán luyện reward model. Tuy nhiên ở thời điểm đầu tiên thì chỉ các data nguồn mở được sử dụng để huấn luyện reward model. Họ cũng nhận ra rằng các data nguồn mở cũng không ảnh hưởng tiêu cực đến kết quả của RLHF nên họ vẫn giữ lại chúng trong các quá trình training tiếp theo.
- Giữ lại 90% dữ liệu Anthropic's harmlessness data mix với 10% dữ liệu của Meta: cái này họ không giải thích lý do, và tại sao lại chỉ sử dụng 10% dữ liệu của Meta. Liệu họ có giữ lại 90% để tạo một model mạnh hơn không?

- Chỉ training 1 epoch mỗi lần cập nhật dữ liệu để tránh hiện tượng overfiting
- Độ chính xác trung bình của reward model ở mức khoảng 60 - 70% theo như trong paper nhưng đặc biệt với các trường hợp Significantly Better thì độ chính xác tầm 90%. Điều này cũng dễ hiểu bởi vì đây là các class mà con người ít phân vân nhất, lựa chọn tính điểm đánh giá dễ nhất. Còn với những classs mà bản thân con người cũng không chắc chắn thì độ chính xác của mô hình chỉ khoảng 50% (ngang lựa chọn random). Điều này có vẻ thấp nhưng thực ra nó phản ảnh đúng hành vi của con người. bản thân con người cũng đang phân vân mà, nên xác định cái nào là tốt hơn cái nào thực ra cũng rất khó mà phải không các bạn.
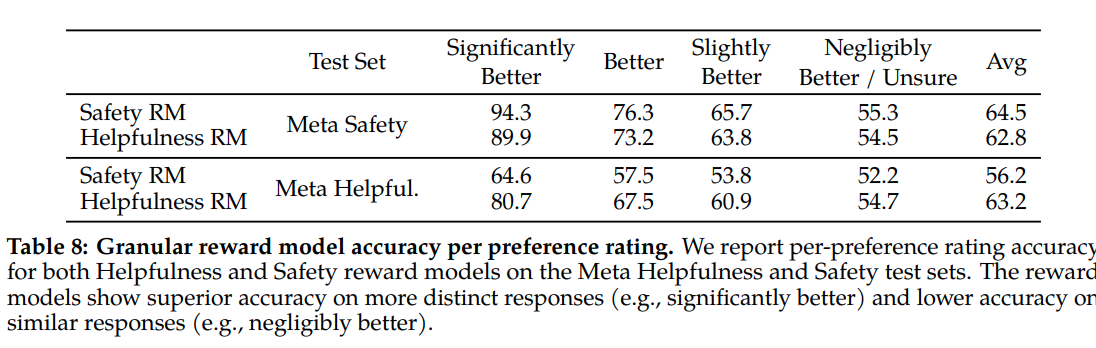
- Huấn luyện bằng ranking loss và có sử dụng thêm tham số margin để giúp mô hình học tốt hơn với các level khác nhau của score.
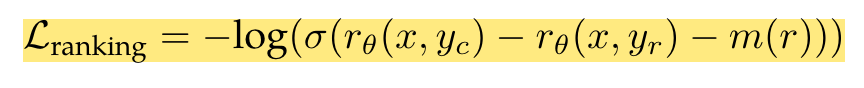
- Tác giả đánh giá mô hình với cả GPT-4 bằng cách sử dụng zero-shot prompt: Choose the best answer between A and B trong đó A và B là 2 câu trả lời tương ứng của mô hình. Kết quả cho thấy mô hình reward model của các tác giả cho kết quả tốt hơn GPT-4 trong khi các mô hình reward model chỉ được training trên các tập dữ liệu public thì kết quả không bằng GPT-4
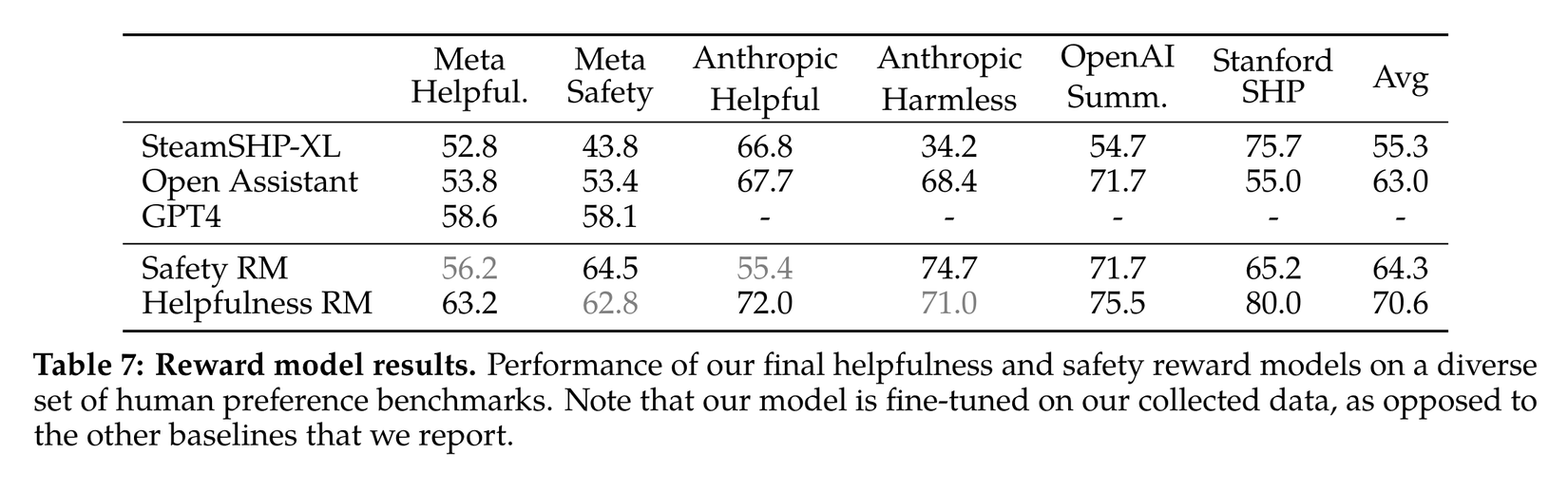
Biểu đồ bên dưới thể hiện mức độ tăng trưởng accuracy của mô hình reward model khi bổ sung thêm dữ liệu. Các đối tác để làm dữ liệu của họ sẽ gửi dữ liệu theo batches hàng tuần
Lạm bàn
Kết quả của reward model là cực kì quan trọng có ảnh hưởng lớn đến độ chính xác của mô hình, và là nhân tố chính ảnh hưởng đến chiến lược RLHF. Điều này cũng là lý do tại sao chưa có một bên nào open-source mô hình reward của họ. Ngay cả trong source code của llama-2 mình cũng KHÔNG THẤY HỌ OPEN-SOURCE phần này. Có lẽ cũng hợp lý thôi bởi chi phí để tạo ra một reward model tốt là quá đắt đỏ.
Tính an toàn của mô hình
Hơn một nửa paper nói về cách đảm bảo tính an toàn cho mô hình. Khía cạnh an toàn của mô hình và báo cáo này là sự tiến bộ lớn nhất so với các mô hình nguồn mở có sẵn (Mình thực sự ngạc nhiên về cách mà Falcon 40b-instruct đã làm tốt trong mặt này, khi biết được quá trình huấn luyện ở đó tương đối dễ dãi, nhưng điều này sẽ được bàn sau vì nó không nằm trong phạm vi của bài viết này).
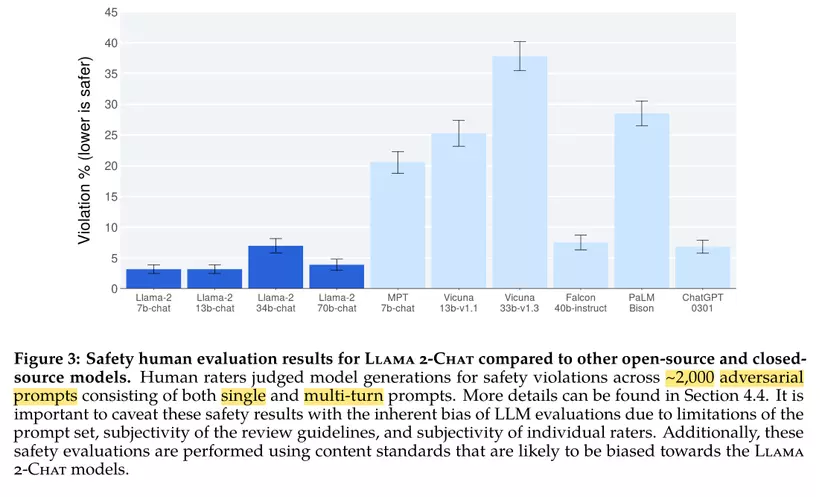
Cá nhân mình thực sự chưa quan tâm nhiều lắm đến mức độ an toàn hay so sánh tính an toàn giữa các mô hình. Chúng ta dùng free mà, mình tôn trọng công sức của những tác giả đã tạo ra các mô hình đó. Còn việc đảm bảo tính an toàn là việc của chúng ta khi làm sản phẩm. Chỉ có một điều mình thấy băn khoăn là liệu cách đánh giá và đảm bảo độ an toàn này có quá nhạy cảm hay không vì bằng chứng là phiên bản 34B đã không đảm bảo an toàn đến mức chưa được phát hành dù họ làm cùng một cách huấn luyện.
Chi phí xứng tầm "cụ kị của đại gia"
Chỉ tính nguyên chi phí làm dữ liệu cho LLaMa-2 người ta ước tính nó tiêu tốn của Meta đến 8 triệu đô la tương đương khoảng 200 tỉ VND. Nên là thực sự ước mơ để tự train một LLM đối với mình là NO DOOR, NO HOPE luôn các bạn ạ. Và thật sự thầm cảm ơn Meta vì họ đã không ngại dốc hầu bao để cho cộng đồng một mô hình ngôn ngữ có thể coi là tốt nhất trong thế giới LLM mã nguồn mở. Meta muôn năm
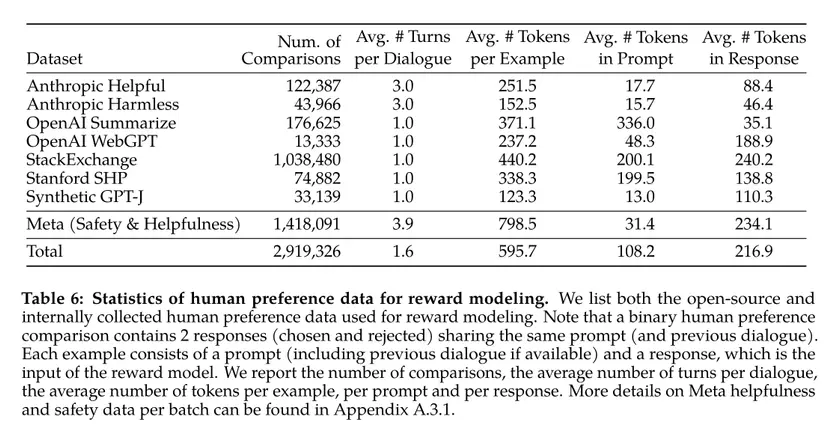
Dưới đây là thống kê của các dataset sử dụng cho human preference data để huấn luyện reward modeling. Nó có khoảng gần 3 triệu sample gồm prompt và các câu trả lời tương ứng.
Còn nói về chi phí cho GPUs thì paper cũng đã nói rõ ràng con số sử dụng. Họ tiêu tốn khoảng gần 3.4 triệu giờ GPUs. Bạn hãy tưởng tượng, nếu như bạn chỉ có một chiếc GPU để training mô hình này thì sẽ cần đâu đó 141666 ngày tương đương 388 năm để huấn luyện xong LLaMA. Mỗi GPU của họ là NVIDIA A100s và clusster của họ ước tính cỡ khoảng 6000 GPUs. Chi riêng tính toán chi phí để mua dàn GPU này đã tốn đến con số hàng nghìn tỉ VND rồi. Đó thực sự là một con số mà chỉ có tầm cỡ cụ kị của đại gia mởi đủ sức thực hiện mà thôi.
Những tổn hại đến môi trường
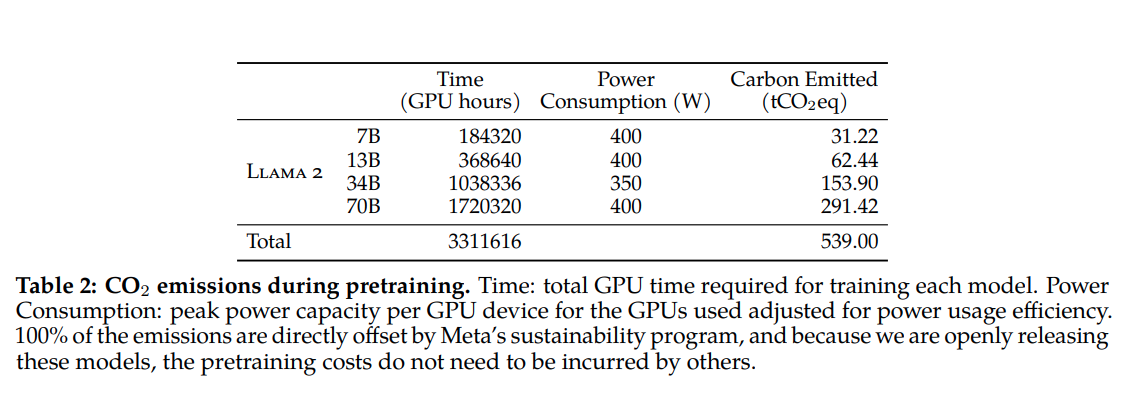
Đây cũng là paper đầu tiên nói về lượng điện tiêu thụ và khí thải carbon để huấn luyện. Nó tiêu tốn cỡ 3.3 triệu giờ GPU tương đương khoảng 1.3 triệu KW điện tiêu thụ và lượng khí thải carbon là 539 tấn CO2 thải vào môi trường. Đây là một con số rất đáng lưu tâm
Tổng kết
Thật sự đây là một technical report tuyệt vời trên phương diện kĩ thuật và mình thấy thật sự Meta đang rất nỗ lực trong mục tiêu dân chủ hoá AI mà họ ủng hộ. Sau khi có LLaMA-2 mình nghĩ rằng sẽ còn rất nhiều phiên bản nữa tốt hơn dưới sự góp sức của cộng đồng. Đây cũng có thể là một động thái làm giảm bớt lợi thế cạnh tranh của các đối thủ. Dù sao đi nữa thì mình cũng phải cảm ơn Meta vì đã trả lời cho mình rất nhiều câu hỏi liên quan đến LLM. Mình sẽ có một video tổng hợp và giải thích trong tương lai gần. Các bạn hãy theo dõi và ủng hộ mình nhé
All rights reserved
