
Bí kíp võ công thượng thừa giúp cải tiến ứng dụng Retrieval Augmented Generation (RAG)
Bài đăng này đã không được cập nhật trong 2 năm
Lời nói đầu
Xin chào các bạn, lâu lắm rồi mình mới có viết một bài viết mới, rất hi vọng là các bạn vẫn còn nhớ đến mình. Dạo gần đây với sự phát triển bùng nổ của các loại LLM khác nhau thì các ứng dụng RAG. - Retrieval Augmented Generation (RAG) cũng nổi lên như một kĩ thuật thượng thừa khi làm việc với các LLM. Ưu điểm của RAG thì không phải bàn cãi nữa rồi nhưng làm thể nào để có thể xây dựng được các pipeline RAG hiệu quả hơn thì vẫn là một chủ đề nghiên cứu rất hot trong thời gian gần đây. Vậy nên nhân một ngày cuối tháng 5 tươi đẹp thì mình xin mạn phép được viết một bài viết chia sẻ một vài kiến thức góp nhặt lại thành một cẩm nang tạm gọi là Bí kí võ công thượng thừa giúp cải tiến ứng dụng Retrieval Augmented Generation (RAG). Mời các bạn cùng đón đọc nghe.
OK không lằng ngoằng dây điện nữa, chúng ta bắt đầu thôi
Nhắc lại về một số điểm yếu của LLM
Có lẽ rằng sự phát triển của LLM là một trong những bước tiến vĩ đại nhất của lĩnh vực AI hiện đại, khi mà tốc độ phát triển của nó tính bằng ngày thì kèm theo đó là các ứng dụng LLM cũng mọc lên như nấm sau mưa. Một trong những ứng dụng nổi tiếng đó là RAG. Để cho các bạn nào chưa biết đén kĩ thuật RAG là gì thì mình xin phép được nhắc lại một chút về ý tưởng của nó. Câu chuyện thì thực ra nên bắt đầu từ các yếu điểm của LLM. Có lẽ sau hơn một năm ra đời thì bài viết ChatGPT hay là "Chết GPT" của mình vẫn còn nguyên giá trị. Khi mà LLM càng phát triển nhưng nó vẫn tồn tại những nhược điểm của nó như
- Thông tin thiếu tính cập nhật: Thường thì tốc độ training của LLM cũng ngang với tốc độ của rùa đi bộ nên chúng ta không thể kì vọng nó sẽ update được các thông tin real time được. Dù sao thì nếu chưa có một đột phá về mặt phần cứng để training thì việc training một LLM vẫn cần rất nhiều thời gian và công sức đẻ cập nhật lại mô hình.
- Chém gió - hallucination: mình đã phân tích rất là kĩ ở trong bài viết ChatGPT hay là "Chết GPT" rồi và chắc mọi người cũng đã không còn xa lạ gì với hiện tượng này nữa. Kiểu như Chí Phèo lại là một tác phẩm viết vào thời nhà Hán như đoạn chat dưới đây chẳng hạn. Thật là chả biết đâu mà lần với ông ChatGPT này nữa.
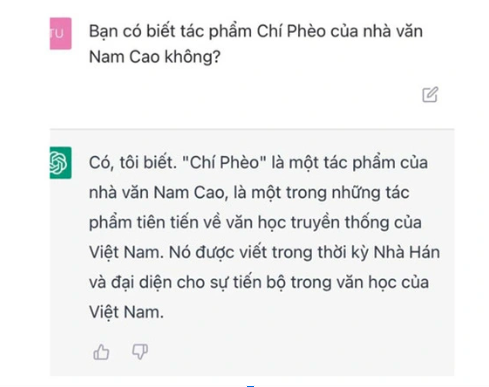
- Không làm việc được với dữ liệu nội bộ: Thật đấy, LLM sẽ không thể cover được hết các thông tin mà bạn muốn đâu, cái điều này thì chắc chắn luôn. Thử nghĩ xem, một ngày đẹp trời mà ChatGPT của ông OpenAI ở tít tận trời tây mà lại biết rõ tường tận gia phả nhà bạn thì chết dở ý chứ chẳng đùa đâu 😜😜😜
- Fine-tuning thì yêu cầu kinh nghiệm và chi phí: Thật sự thì cứ nhìn bảng giá mấy model fine-tuning của OpenAI thì sẽ thấy là giá sẽ đăt gấp vài lần so với model thông thường, mà cũng chắc gì đã đảm bảo được rằng model sau khi fine-tuning sẽ không gặp hiện tượng trên.
Đó là các vấn đề mình nghĩ là quan trọng nhất để RAG có cơ hội và đất diễn trong kỉ nguyên của LLM. Vậy RAG thực sự là gì, nó được sinh ra với mục đích chi thì chúng ta sẽ tiếp tục trong phần tiếp theo nhé.
Nhập môn RAG
RAG viết tắt của Retrieval Augmented Generation, ở trong cái tên đã nói lên tất cả. Mục đích cuối cùng vẫn là Generation tức là sinh ra câu trả lời cho một câu hỏi sử dụng LLM thôi, nhưng nó đặc biệt hơn ở chỗ Retrieval Augmented, tức là việc Generation này sẽ được làm giàu thêm các thông tin, tăng cường (augmented) thêm các thông tin ngữ cảnh (context). Các thông tin này được trích xuất (retrieval) từ các nguồn thông tin mà chúng ta quy định. Do LLM được cung cấp thông tin ngữ cảnh đầy đủ nên nó có thể trả lời được các thông tin chính xác và có căn cứ hơn. Cái này giang hồ gọi với cái tên mỹ miều là in-context learning
Túm cái váy lại
RAG là kĩ thuật giúp tìm kiếm các thông tin liên quan và bổ sung vào context của LLM giúp LLM trả lời chính xác hơn.
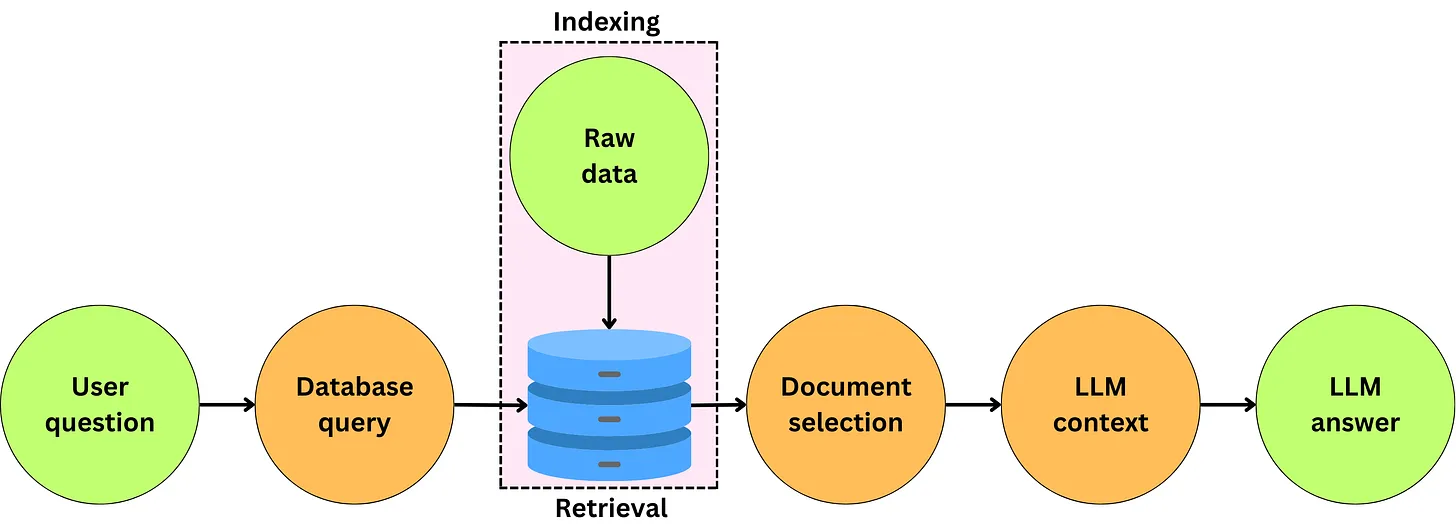
Vậy khi nào chúng ta cần dùng RAG, chúng ta cần dùng RAG khi cần bổ sung thêm thông tin vào context cho LLM. Đơn giản vậy thôi, ví dụ như một số tình huống sau:
- LLM không biết thông tin về gia phả nhà bạn, nên khi bạn cần phải truy vấn các thông tin như bố mẹ bạn gặp nhau ở đâu, ông. bà bạn cưới nhau ngày nào? Thì sẽ cần dùng RAG để truy vấn và cung cấp các thông tin liên quan cho LLM
- LLM không biết thông tin về công ty bạn, nên khi bạn cần phải truy vấn thông tin về ngày thành lập công ty, giám đốc hiện tại là ai.... vân vân và mây mây về công ty của bạn thì cần phải sử dụng RAG.
Chính vì tính chất rất đặc biệt là in-context learning nên RAG rất phù hợp cho việc tạo ra các trợ lý ảo để làm việc với các thông tin bên ngoài, các thông tin real time của dữ liệu.
Giờ chúng ta cùng tìm hiểu xem RAG gồm có những thành phần nào nhé.
Các thành phần chính của RAG
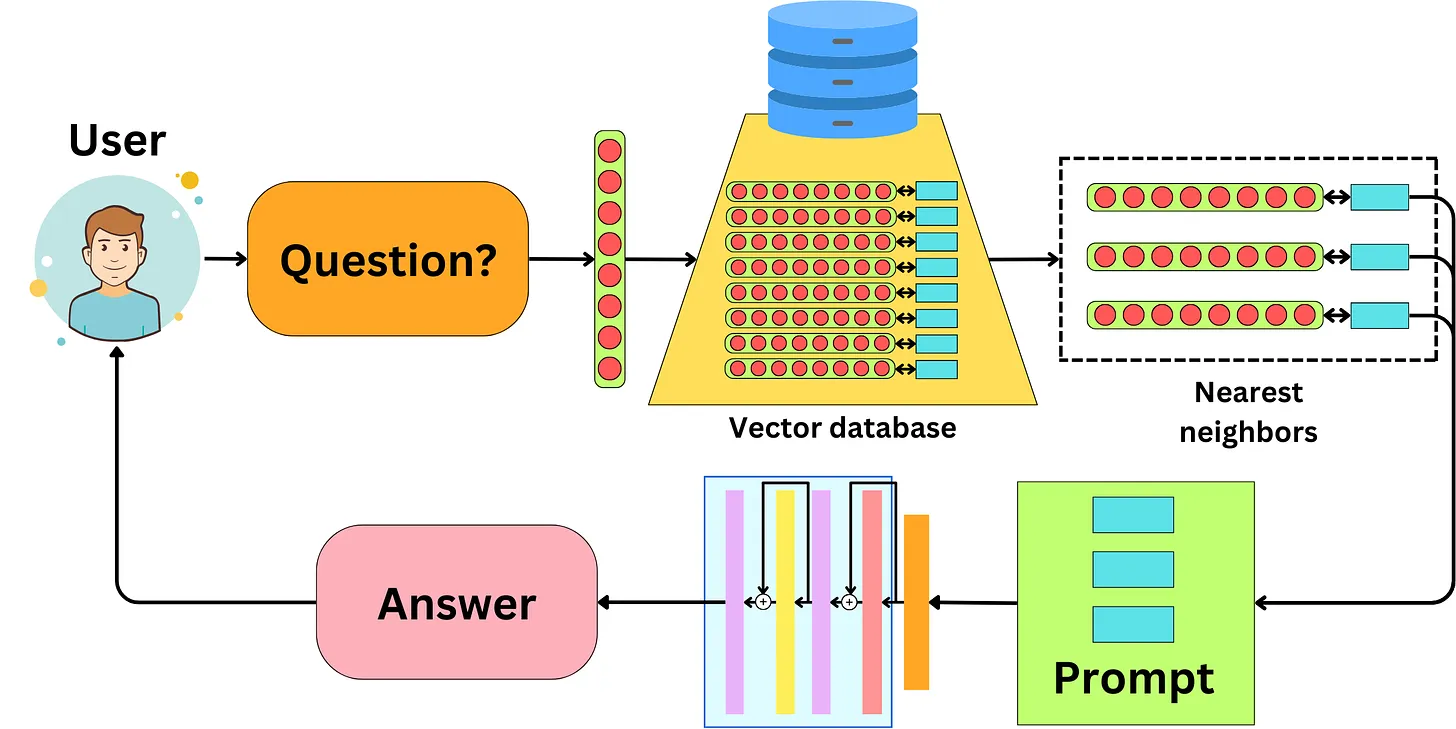
Như các bạn thấy ở hình trên thì một pipeline RAG cơ bản sẽ gồm có 3 phase chính
- Phase 1: Tạo cơ sở dữ liệu: đây là bước tạo nguồn dữ liệu lưu trữ lại các documents liên quan (ví dụ như tất cả các loại giấy tờ trong gia phả nhà bạn) vào một database. Thường người ta hay sử dụng vector database bởi tính chất phi cấu trúc của dữ liệu nên việc biểu diễn bằng vector sẽ giúp tìm kiếm dễ dàng hơn các thông tin tương tự về mặt ngữ nghĩa. Nhưng cái này là không nhất thiết nha, về cơ bản thì nếu bạn có thể build được một hệ thống cơ sở dữ liệu tối ưu cho việc tìm kiếm các tài liệu liên quan với một câu hỏi bất kì thì bạn hoàn toàn có thể thay thế vector database.
- Phase 2: Truy vấn đây chính là bước tìm kiếm các tài liệu liên quan trong cơ sở dữ liệu đối với một input query. Output của phần này là một tập hợp các documents có liên quan đến câu query input
- Phase 3: Generation từ các documents liên quan thì tiến hành việc sinh ra nội dung dựa vào các context tạo thành từ các documents đó.
Cũng từ các thành phần chính này chúng ta sẽ có các chiêu thức để tối ưu pipeline RAG khác nhau mà chúng ta sẽ tìm hiểu trong các phần dưới đây.
Bí kíp 1: Tối ưu hoá quá trình Indexing
Indexing với các chunk nhỏ của data
Các bạn có thấy ở phần trên mình có nói đến vector database không, ưu điểm của nó là việc tìm kiếm tương tự. Tại sao phải tìm kiếm tương tự, bởi vì bạn sẽ không bao giờ có thể biết được người dùng sẽ hỏi ứng dụng của bạn câu hỏi gì. Khi áp dụng pipeline RAG thì một lưu ý cần nhớ rằng thông tin query RAG không nhất thiết phải trùng khớp với các thông tin chứa trong database. Diều đó ngầm ám chỉ rằng chúng ta sẽ tìm các đoạn có tính tương tự cao nhất trong vector database để tạo ra nội dung.
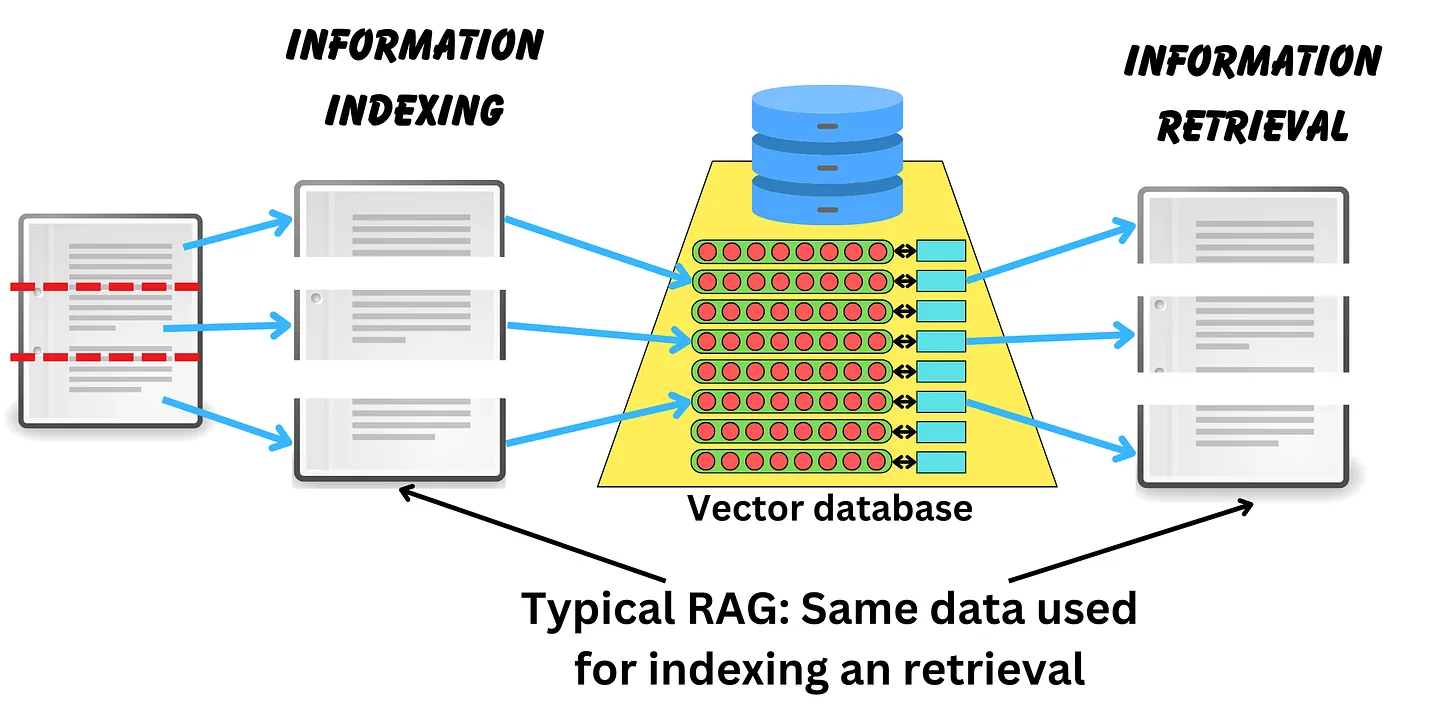
Thực tế cũng vậy thôi, thường chúng ta sẽ ít khi query cả một đoạn văn bản lớn mà thường hay hỏi về một khái niệm hoặc một đối tượng duy nhất trong một câu query. Chính vì thế việc indexing bằng các document quá lớn đôi khi khiến cho vector biểu diễn của câu hỏi không giống với vector biểu diễn của cả document lớn đó.
Thay vào đó, chúng ta có thể chia tài liệu lớn thành các phần nhỏ hơn, chuyển đổi chúng thành dạng biểu diễn vectơ của chúng và tiến hành indexing các tài liệu lớn nhiều lần bằng cách sử dụng vectơ của các đoạn con. Các đoạn nhỏ có nhiều cơ hội chứa một khái niệm unique hơn, vì vậy chúng rất tốt cho việc indexing dữ liệu để tìm kiếm sự tương đồng
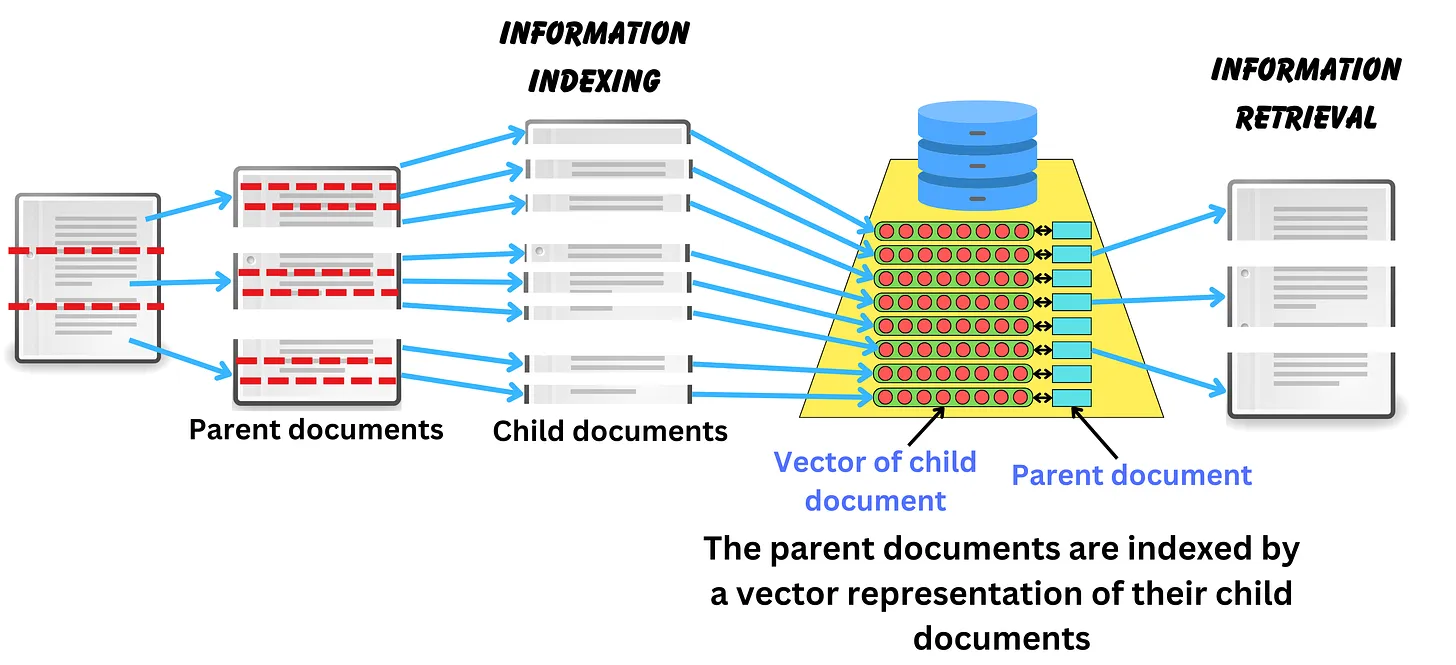
Indexing bằng cách tạo câu hỏi cho các documents
Chúng ta có thê thực hiện indexing bằng cách tạo ra các câu hỏi tương ứng với các documents được cung cấp và từ đó indexing các câu hỏi. Lúc này các documents có thể được coi như là các metadata của các câu hỏi được indexing. Để thực hiện điều này thì chúng ta thường sử dụng một model xịn xò như GPT-4 trở lên để nhờ nó sinh ra các câu hỏi có thể có cho các documents này. Sau đó chúng ta sẽ tiến hành lấy embedidng của các question và indexing như bình thường, các documents sẽ được lưu lại như metadata để phục vụ cho quá trình lấy context phía sau.
Khi người dùng hỏi một câu hỏi thì câu hỏi này có khả năng cao sẽ similar với câu hỏi mà GPT-4 đã sinh ra. Documents được truy vấn tương ứng để có thể giúp cho LLM hiểu được toàn bộ ngữ cảnh.
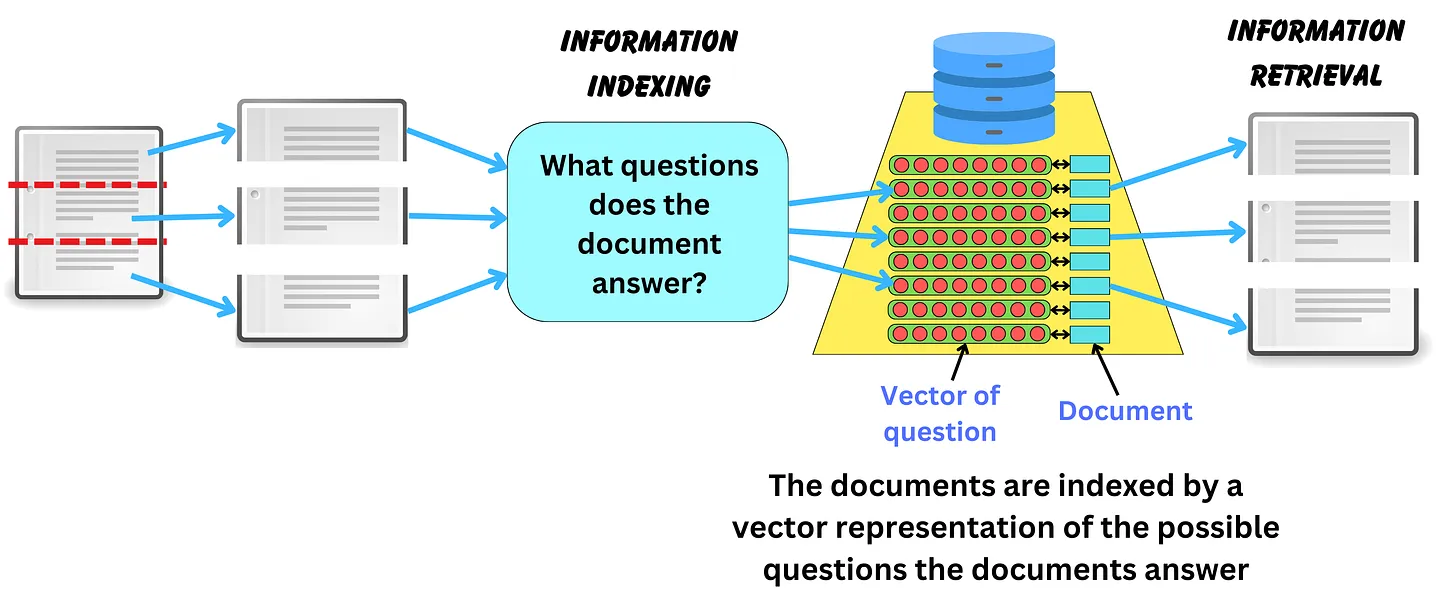
Indexing bản tóm tắt của các documents
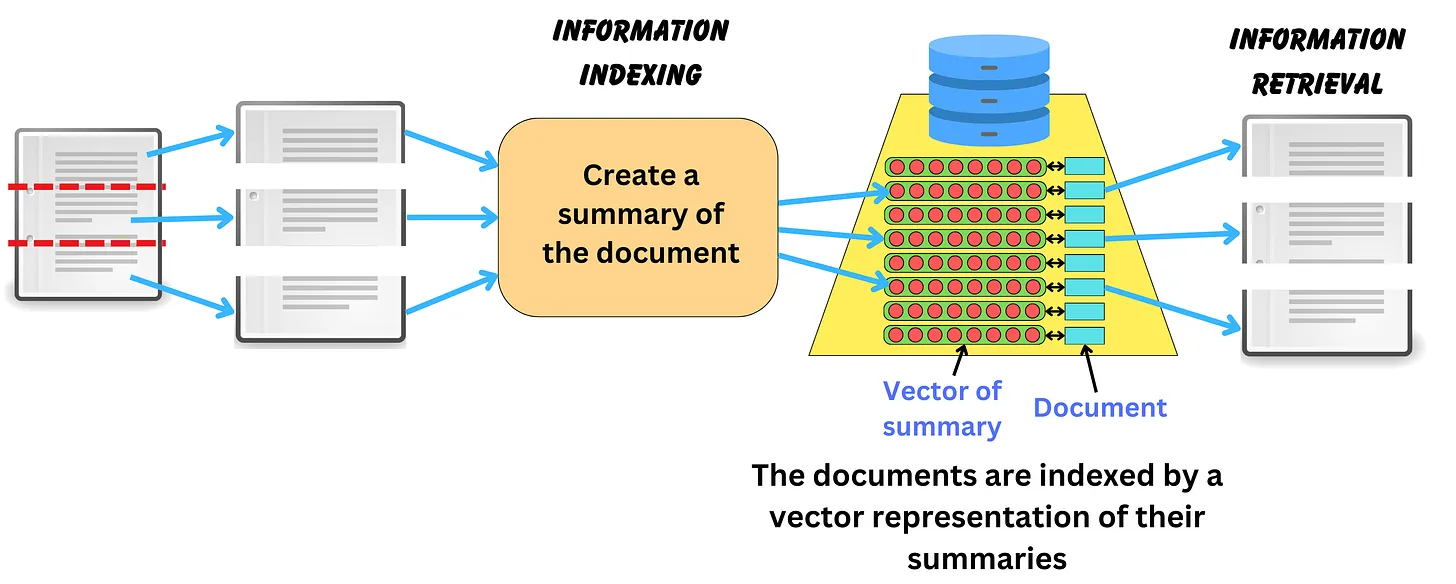
Chúng ta cũng có thể thực hiện indexing các documents đã được summary. Việc tóm tắt này cũng nên sử dụng các model xịn xò như GPT-4, văn bản sau khi tóm tắt sẽ trở nên ngắn gọn hơn và "tinh khiết hơn về mặt ngữ nghĩa" vì thế có thể là một lựa chọn tốt hơn cho việc tìm kiếm độ tương đồng.
Tương tự thì các documents gốc cũng sẽ được lưu lại như một metadata để phục vụ cho quá trình generation sau này LLM sẽ có được đầy đủ context hơn.
Bí kíp 2: Tối ưu hoá Query
Phương pháp HyDE
Trong phương pháp RAG cố điển thì chúng ta sẽ sử dụng trực tiếp câu hỏi của users để converted sang query của LLM và tìm kiếm tương tự trong vector database. Tuy nhiên chúng ta hoàn toàn có thể cải tiến câu query này để đạt hiệu quả tốt hơn.
Một trong những phương pháp phổ biến đó là Hypothetical Document Embeddings (HyDE), phương pháp này sử dụng các model Instruction following để tạo ra các Hypothetical answer là các câu trả lời giả định.
Câu trả lời giả định (hypothetical answers) là các câu trả lời được tạo ra một cách tưởng tượng, không phải là các câu trả lời thực tế. Chúng thường được tạo ra bằng cách sử dụng mô hình ngôn ngữ tự động (LLM) để tạo ra các câu trả lời dựa trên thông tin có sẵn từ câu hỏi hoặc văn bản liên quan. Các câu trả lời giả thuyết này không phải là chính xác hoặc dựa trên thông tin thực tế, mà thường chỉ là các dự đoán hoặc giả định về câu trả lời có thể có. Điều này cho phép mở rộng phạm vi tìm kiếm và khám phá các khả năng khác nhau để trả lời câu hỏi.
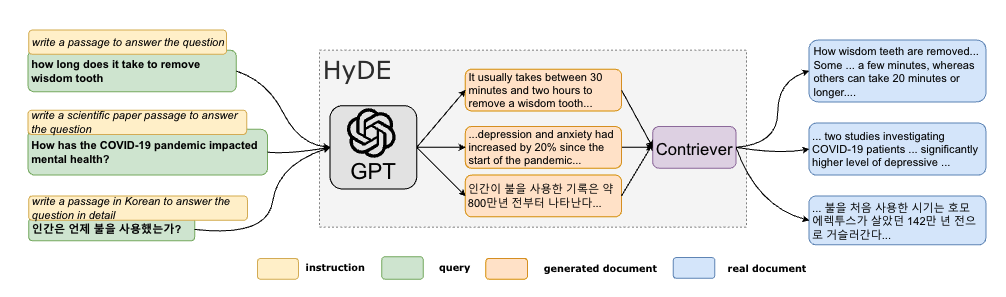
Chúng ta cần lưu ý rằng các câu trả lời giả định có thể không chính xác nhưng sẽ là các thông tin có liên quan gần hơn đến domain của câu hỏi. Tức là các nội dung trong câu trả lời giả định có xác suất cao sẽ chứa nhiều thông tin liên quan tương tự như thông tin được indexing. Chính vì thế nên khi tìm kiếm trong vector database nó có khả năng tìm được các document có độ liên quan lớn hơn.
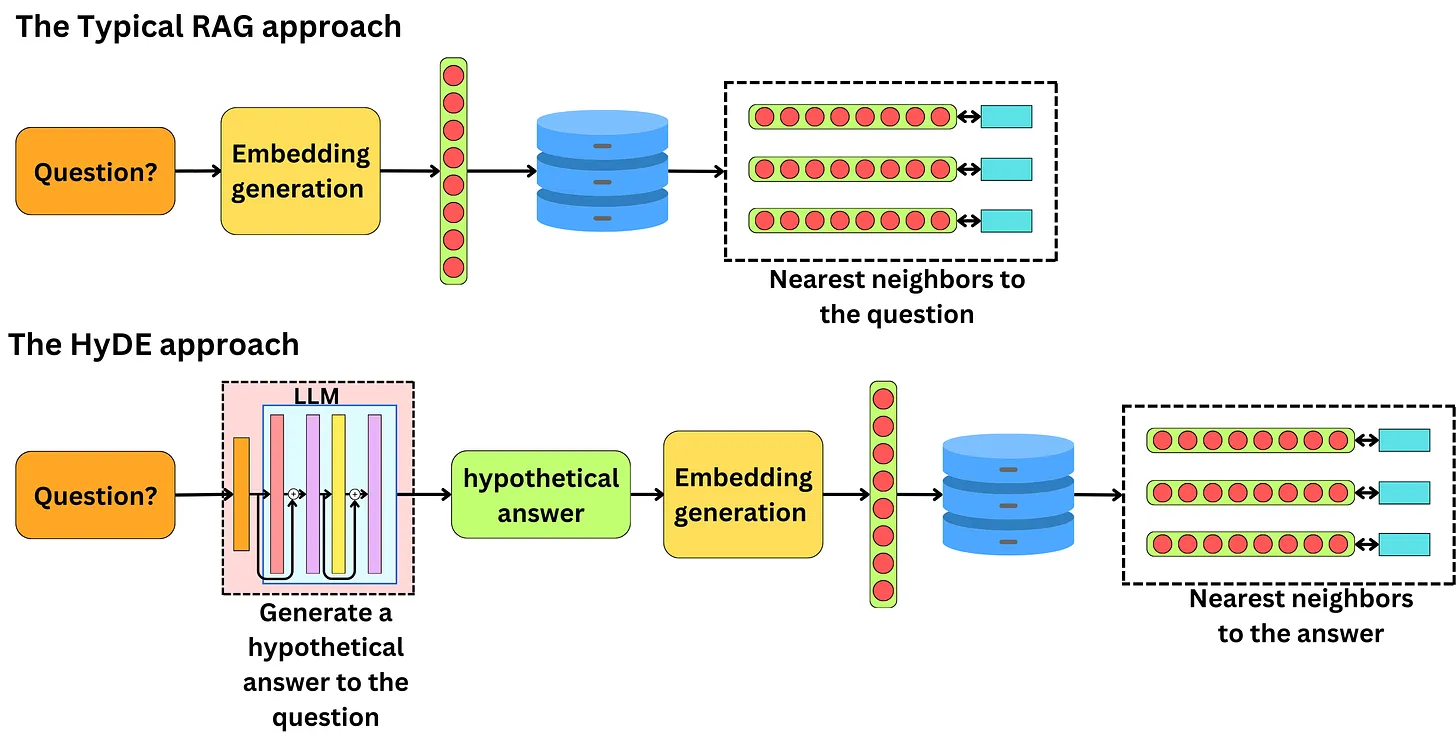
Phương pháp Multi-Query Retriever
Hẳn là chúng ta đã gặp các trường hợp này trong thực tế, cùng một ý nhưng mỗi người lại có một cách diễn đạt khác nhau. Điều này là dễ hiểu bởi ngôn ngữ tự nhiên rất đa dạng mà trình độ văn chương của mỗi người lại có hạn, thế nên cùng một ý đó nhưng mỗi người có thể hỏi theo các cách khác nhau. Điều này có thể ảnh hưởng đến pipeline RAG của chúng ta bởi mỗi cách hỏi khác nhau sẽ dẫn đến các câu trả lời cũng khác nhau. Người dùng thường không cung cấp đầy đủ context trong câu hỏi và có xu hướng suy nghĩ theo một hướng trả lời nhất định.
Để khắc phục hiện tượng này thì chúng ta có thể sử dụng kĩ thuật query expansion. Cụ thể trong quá trình query chúng ta có thể sử dụng một LLM xịn xò như GPT-4 để sinh ra các biến thể khác nhau của orignal query. Sau đó việc query với nhiều phiên bản khác nhau của orignai query sẽ giúp chúng ta có thể tìm kiếm được các context đa dạng hơn.
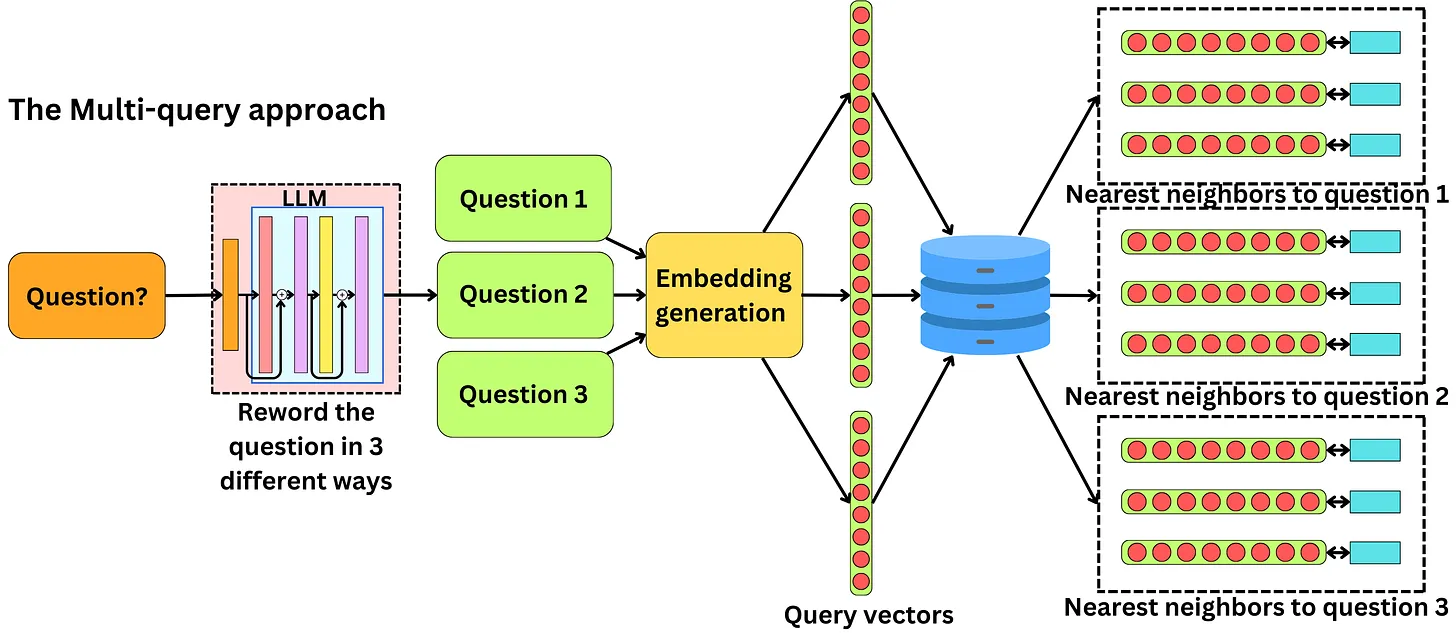
Đây là một prompt trong Langchain để thực hiện việc expansion query ban đầu tạo ra các phiên bản khác nhau
You are an AI language model assistant. Your task is to generate 3 different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of distance-based similarity search. Provide these alternative questions separated by newlines. Original question:
{question}
Và một điều hay ho là trong quá trình Query chúng ta có thể kết hợp cả hai chiêu thức HyDE và Multi-Query Retriever như sau

Bí kíp 3: Tối ưu hoá quá trình Retrieval
Phương pháp Self-Querying
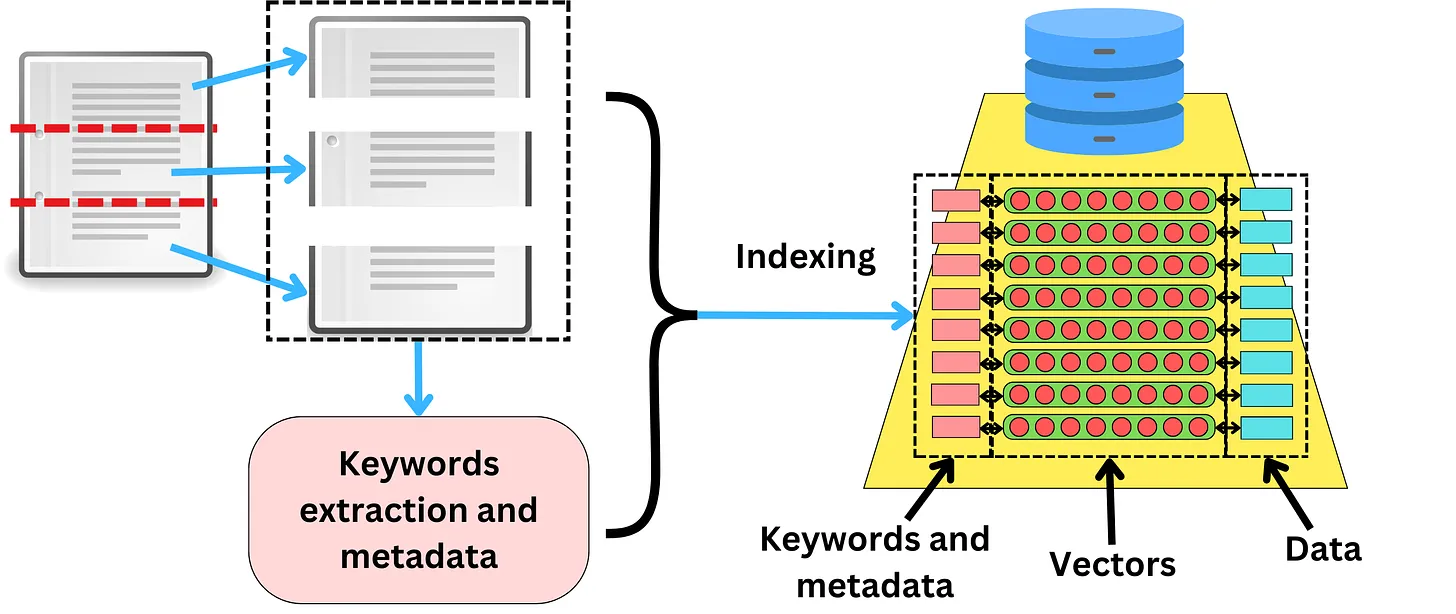
Trong vector database, chúng ta thường giả sử rằng các dữ liệu chỉ được index dưới dạng vectors và việc tìm kiếm chỉ được thực hiện thông qua thuật toán ANN - Approximate Nearest Neighbor search. Bạn nào chưa biết đến khái niệm này thì có thể tham khảo một bài viết khác của tác giả Phan Huy Hoàng trên Viblo, mình thấy bài viết đã giải thích rất cụ thể và chi tiết. Quay lại với vector database thì một số database như. Milvus chẳng hạn hỗ trợ chúng ta index không chỉ dữ liệu dạng vector mà còn các dạng metadata khác như text, number. Ví dụ chúng ta muốn thêm các thông tin về ngày tháng xuất bản, rating hay tác giả của document đó... Chúng ta có thể lưu trữ các thông tin bổ sung (gọi là metadata) bên cạnh vector biểu diễn cho mỗi document.
Truy vấn đầu vào (bằng ngôn ngữ tự nhiên) sẽ được convert thành vector biểu diễn đồng thời sẽ sử dụng một LLM để tạo ra một structured query để querr các metadata (tương tự như SQL) để có thể thực hiện hybird retrieval. LLM sử dụng tạo ra structed data sẽ được cung cấp database metadata schema. Việc sinh ra các structured data này là độc lập với quá trình sinh vector biểu diễn và không nằm trong query pipeline do LLM cần được access vào database schema cụ thể. Lý do kĩ thuật này được gọi là Self-Querying bởi vì retriever tự sinh ra các structured query (như SQL) để query chính nó.
Nhìn hình sau bạn có thể hiểu rõ hơn
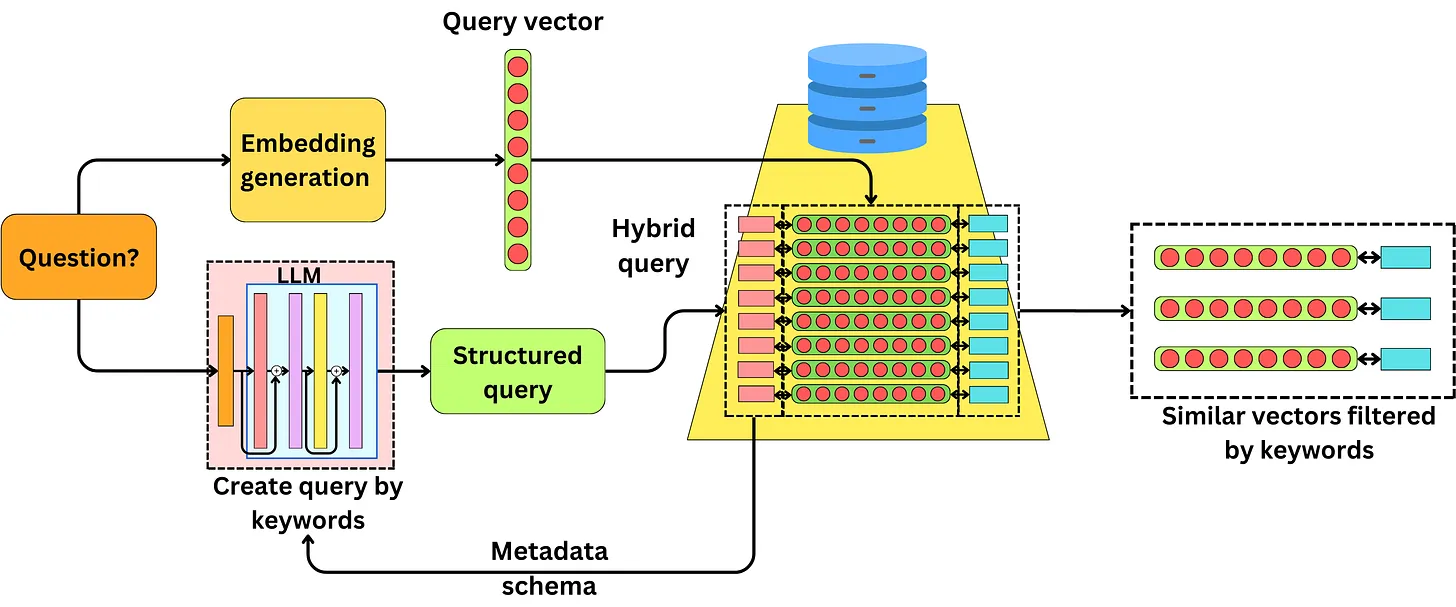
Mình tin rằng Hybrid retrieval approach sẽ rất tiềm năng trong tương lai đặc biệt là khi các ứng dụng RAG ngày càng trở nên phổ biến. Chiến thuật này cũng được sử dụng trong Azure Cognitive Search để tăng hiệu quả của quá trình truy vấn.
Phương pháp Time-weighted retriever
Trong một vài trường hợp thì thông tin hữu ích cho câu trả lời thường là các thông tin có độ cập nhật. Nếu như câu hỏi đang hỏi về các vấn đề mang tính thời sự thì người dùng thường sẽ không mong muốn nhận được các câu trả lời bị out dated. Chính vì thế việc tìm kiếm tương tự về mặt ngữ nghĩa là không đủ để có thể tạo ra được các thông tin hữu ích. Time-weighted retriever là một ví dụ điển hình trong việc xây dựng một hệ thống hybird retrieval. Các vector database phổ biến thường index các thông tin theo các khoảng cách như Euclidean distance, dot-product, or the cosine similarity metric và mục đích của chúng để capture được mức độ liên quan về mặt ngữ nghĩa. Tuy nhiên khi combine khoảng cách này với một số metric khác như thừoi gian tạo của tài liệu là hoàn toàn khả thi. Chúng ta có thể có một score tính toàn dựa trên age của document như sau
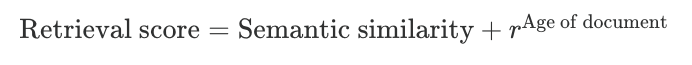
Trong đó thì được gọi là rate decay là một trọng số từ 0 - 1. Hiểu đơn giản là các document càng cũ thì score sẽ càng giảm
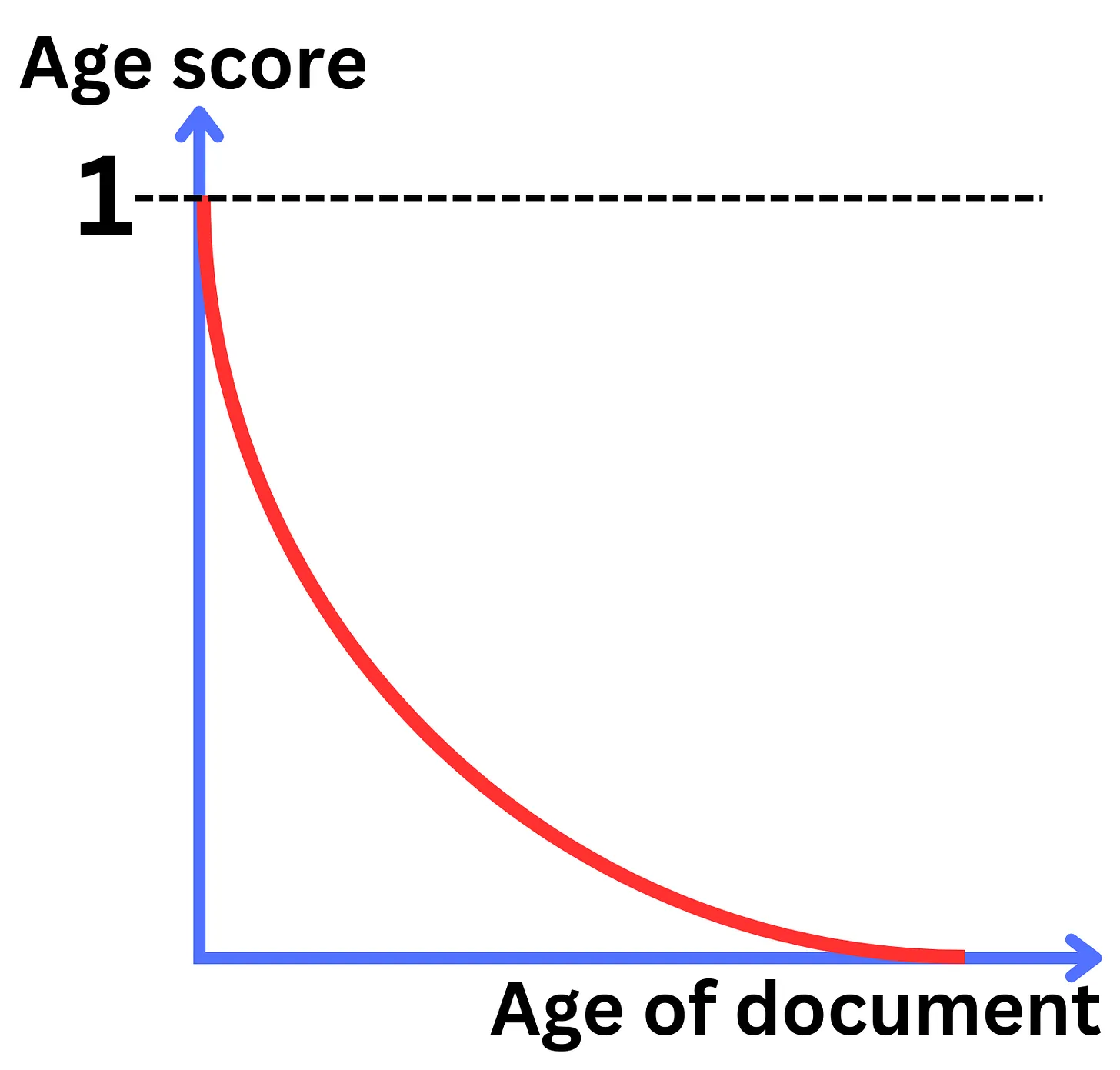
Việc add thêm các metrics về thời gian khiến cho các data được truy vấn sẽ có tính cập nhật về mặt thời gian. Các bạn có thể tham khảo hình bên dưới để rõ hơn
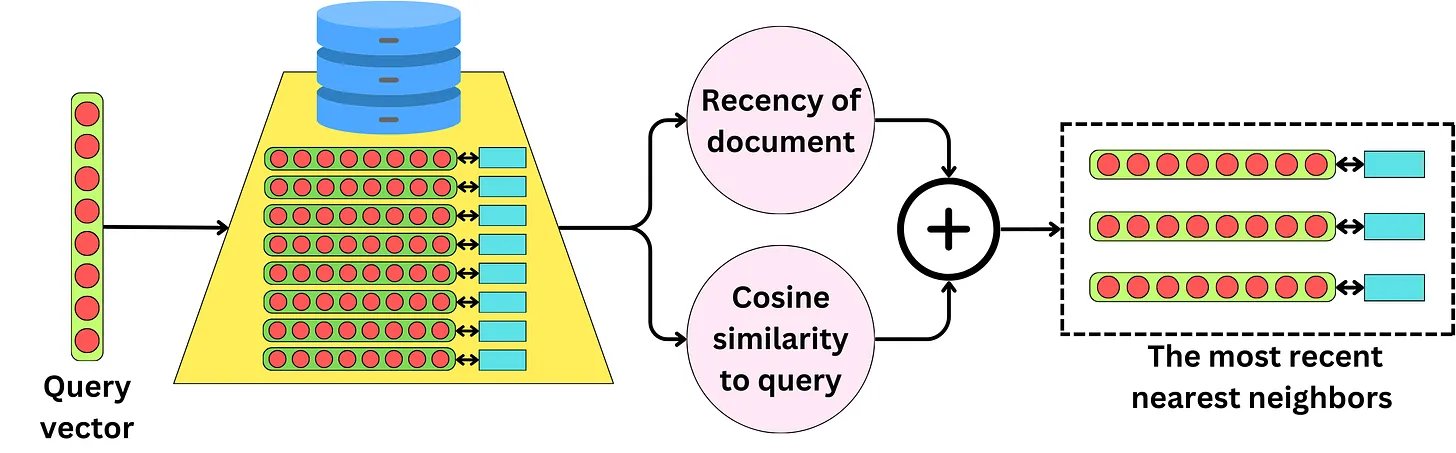
Bí kíp 4: Tối ưu hoá Document selection
Phương pháp Maximal Marginal Relevance
Retrieval process được tối ưu hoá cho việc tìm kiếm các nearest neighbors của document hiện tại trên hàng tỉ các document trong database chỉ với vài milisecond. Tuy nhiên điều này cũng giới hạn chúng ta trong việc tìm ra các documents thực sự có ý nghĩa nhất bởi thường thì các document khá tương đồng nhau ở kết quả truy vấn. Điều này không thực sự quá ý nghĩa nếu chúng ta đưa các context gần giống nhau vào trong LLM. Thay vào đó chúng ta có thể add thêm các layer reranker để để chọn lựa ra các documents tốt nhất đưa vào context của LLM.
Một trong những phương pháp đó là sử dụng Maximal Marginal Relevance (MMR) để rerank lại các documents đã được truy xuất và chỉ lựa chọn các top documents cho context LLM
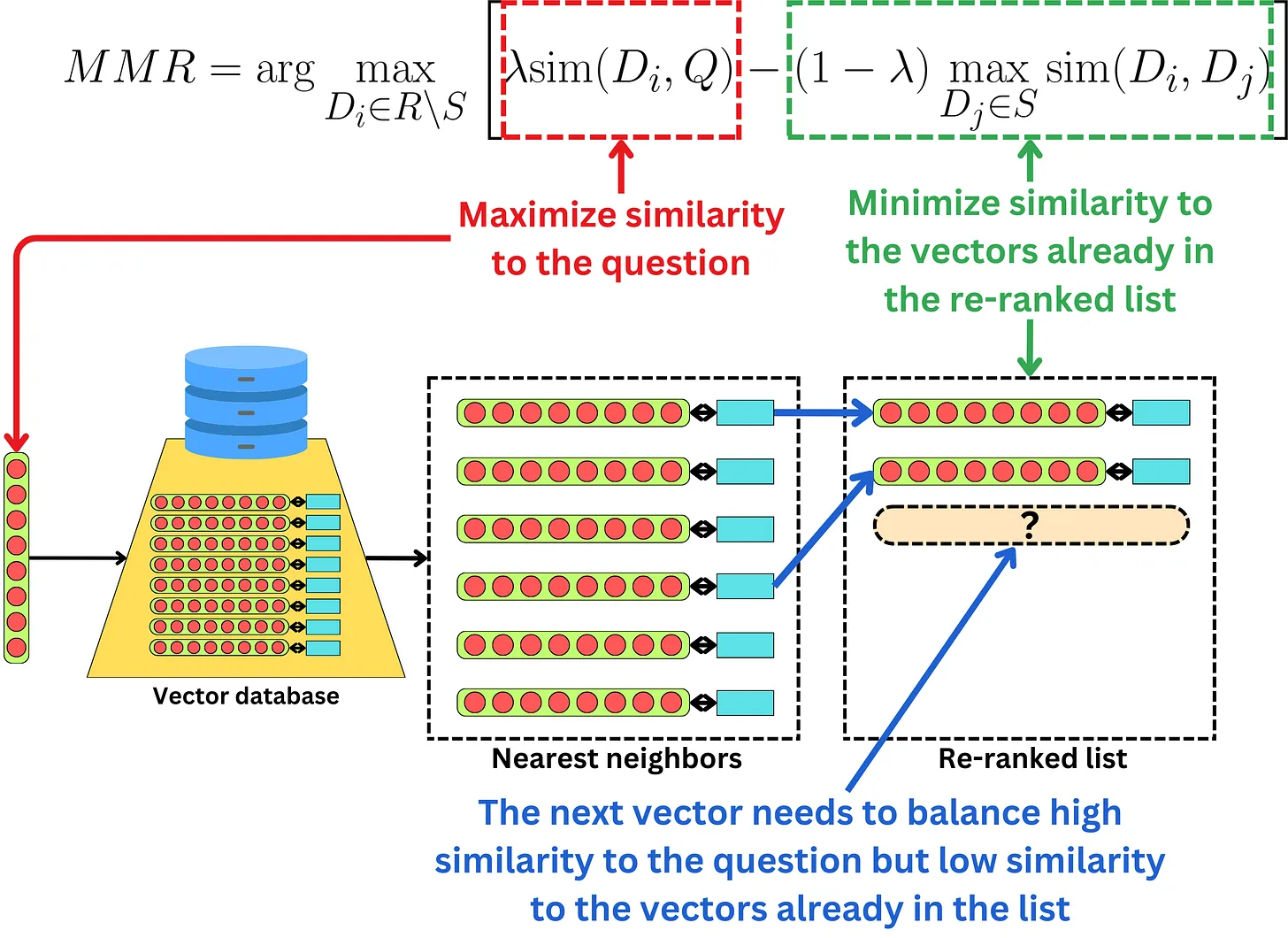
HIểu một cách đơn giản thì metrics MMR sẽ phạt thật nặng vào các thông tin bị dư thừa. Reranking là một quá trình lặp lại qua nhiều bước. Với mỗi bước sẽ thực hiện các công việc như sau :
- Tính toán độ tương tự của các vectors mà chúng ta cần reranking đến vector query
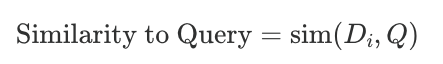
- Tính toán độ tương tự của các vectors mà chúng ta đang cần reranking với các vector đã được reranking
![]()
- Chúng ta sẽ lấy ra các vector nào giúp tối đa hoá tổ hợp của hai phép đo trên
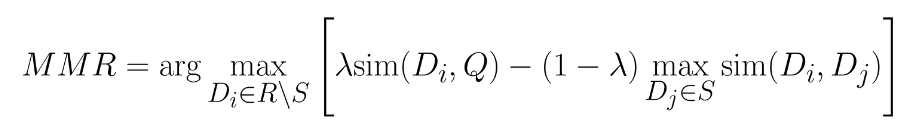
Mục đích của việc này giúp chúng ta tìm ra các vector tương tự với query nhưng có sự khác biệt với các vector đã được reranking. Bằng việc lặp lại quá trình này nhiều lần, từng chút một chút ta sẽ rerank lại vectors bằng cách tránh việc thêm vào trong danh sách những thông tin đã có trong list.
Phương pháp nén ngữ cảnh - Contextual compression
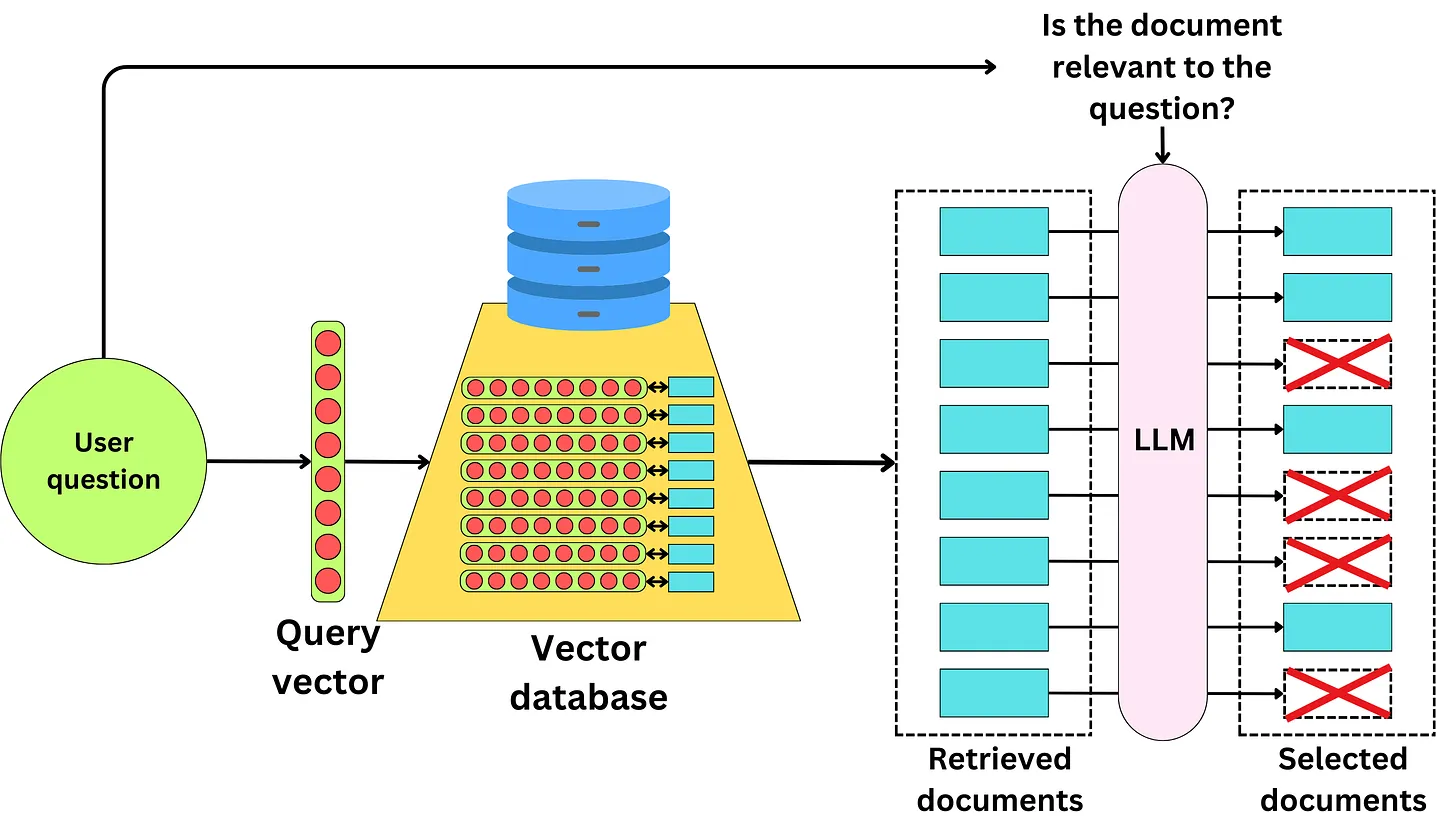
Trong quá trình truy vấn thông tin, sẽ có rất nhiều lần chúng ta gặp phải tình huống khi những thông tin hữu ích không được lấy ra. Điều này có nghĩa là trong các documents mà chúng ta chưa truy vấn đề có thể tồn tại các thông tin hữu ích mà chúng ta chưa bóc tách ra đầy đủ để đưa vào context. Việc chúng ta cần phải làm đó là từ các documents được coi là không liên quan bóc tách được các thông tin liên quan đến câu hỏi của người dùng.
Để thực hiện được điều đó chúng ta có thể sử dụng các LLM khác nhau để định nghĩa xem các documents nào là có liên quan đén câu hỏi đồng thời bóc tách các thông tin có liên quan trong các documents. Đó có thể là hai LLM khác nhau. Các document sau khi được lựa chọn sẽ làm giàu hơn thông tin của context như hình bên dưới
Một hướng tiếp cận khác đó là với mỗi documents được truy xuất ra thì chúng ta có thể tiếp tục phân tách nó thành các sub-document nhỏ và tính toán độ tương tự với các câu query và chỉ lấy các sub-documents nào chưa nội dung liên quan đến query.
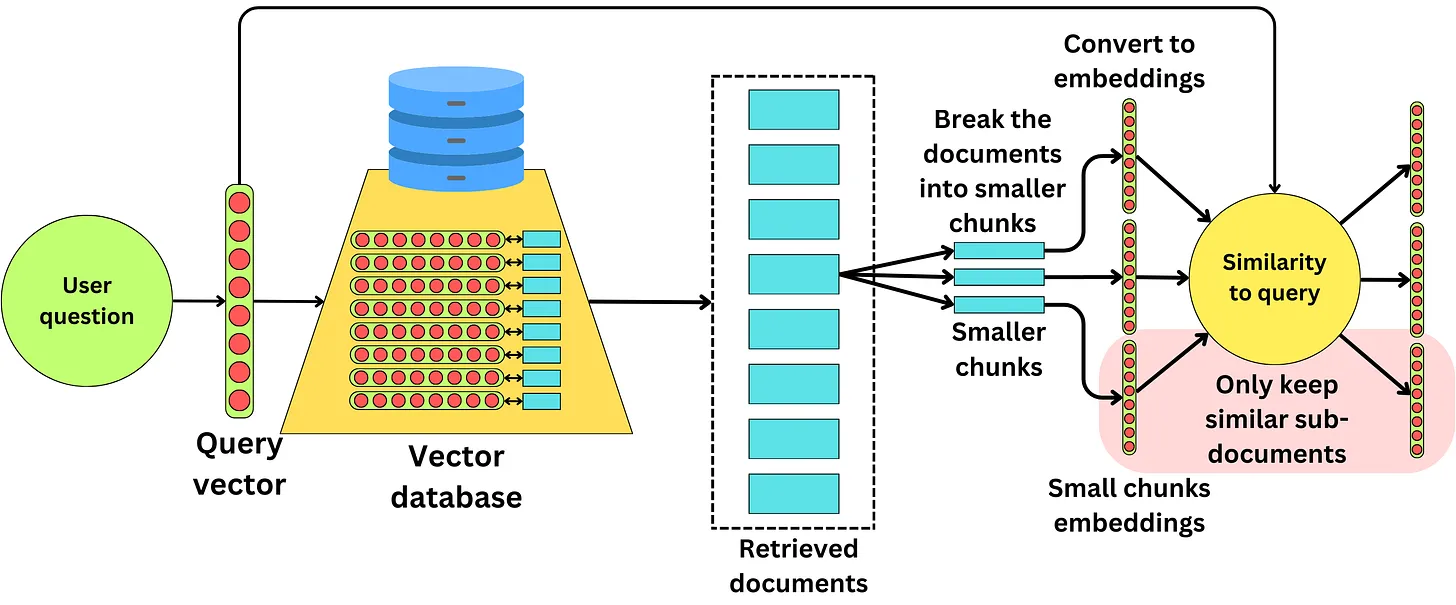
Chính việc lựa chọn được các ngữ cảnh nhỏ hơn, có liên quan trực tiếp đén query hơn khiến người ta gọi kĩ thuật này là nén context
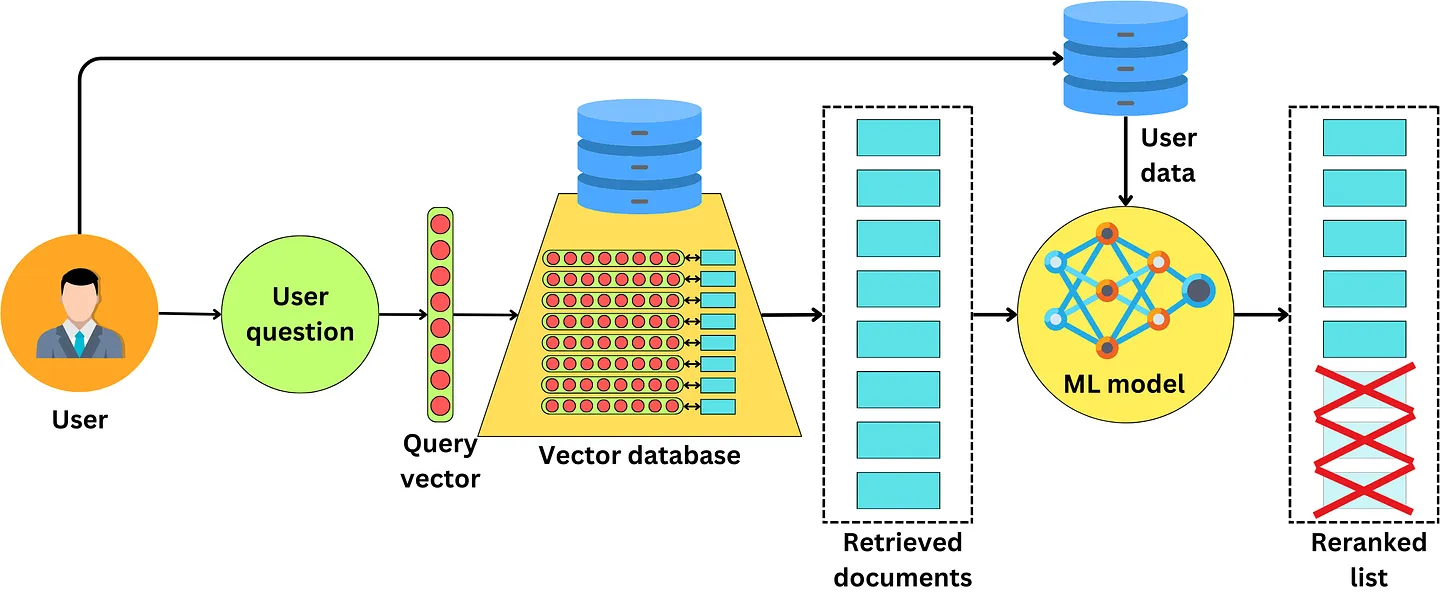
Phương pháp cá nhân hoá - Personalization
Một trong những phương pháp để lựa chọn các documents phù hợp đó là dựa trên tính cá nhân hoá của từng người đặt câu hỏi. Khi các documents được lấy ra từ database chúng ta có thể adapt nó theo hành vi của mỗi người dùng cụ thể. Ví dụ khi người dùng muốn tìm kiếm các thông tin liên quan đến một nhà hàng thi chúng ta nên ưu tiên các thông tin về nhà hàng ở gần vị trí hiện tại của người đùng. Hoặc nếu user hỏi về Python thì chúng ta nên dựa vào lịch sử tìm kiếm của người dùng trong quá khứ để biết các thông tin mà người dùng quan tâm liên quan đến ngôn ngữ lập trình python hơn là lĩnh vực động vật học (python là con trăn)
Sử dụng các phương pháp này chúng ta hoàn toàn có thể rerank lại các documents sao cho nó phù hợp với từng cá nhân cụ thể, từ đó khiên scho context của chúng ta càng chứa các thông tin hữu ích hơn.
Bí kíp 5: Tối ưu hoá ngữ cảnh - Context Optimization
Chiến lược cơ bản
Bước sau cùng sau khi chúng ta đã lựa chọn ra được một tập hợp các documents phù hợp với user query thì bước tiếp theo chúng ta cần pass tất cả đống data này vào LLM để sinh ra các câu trả lời. Một chiến lược điển hình đó là chúng ta sẽ concat tất cả các text của các documents vào một prompt
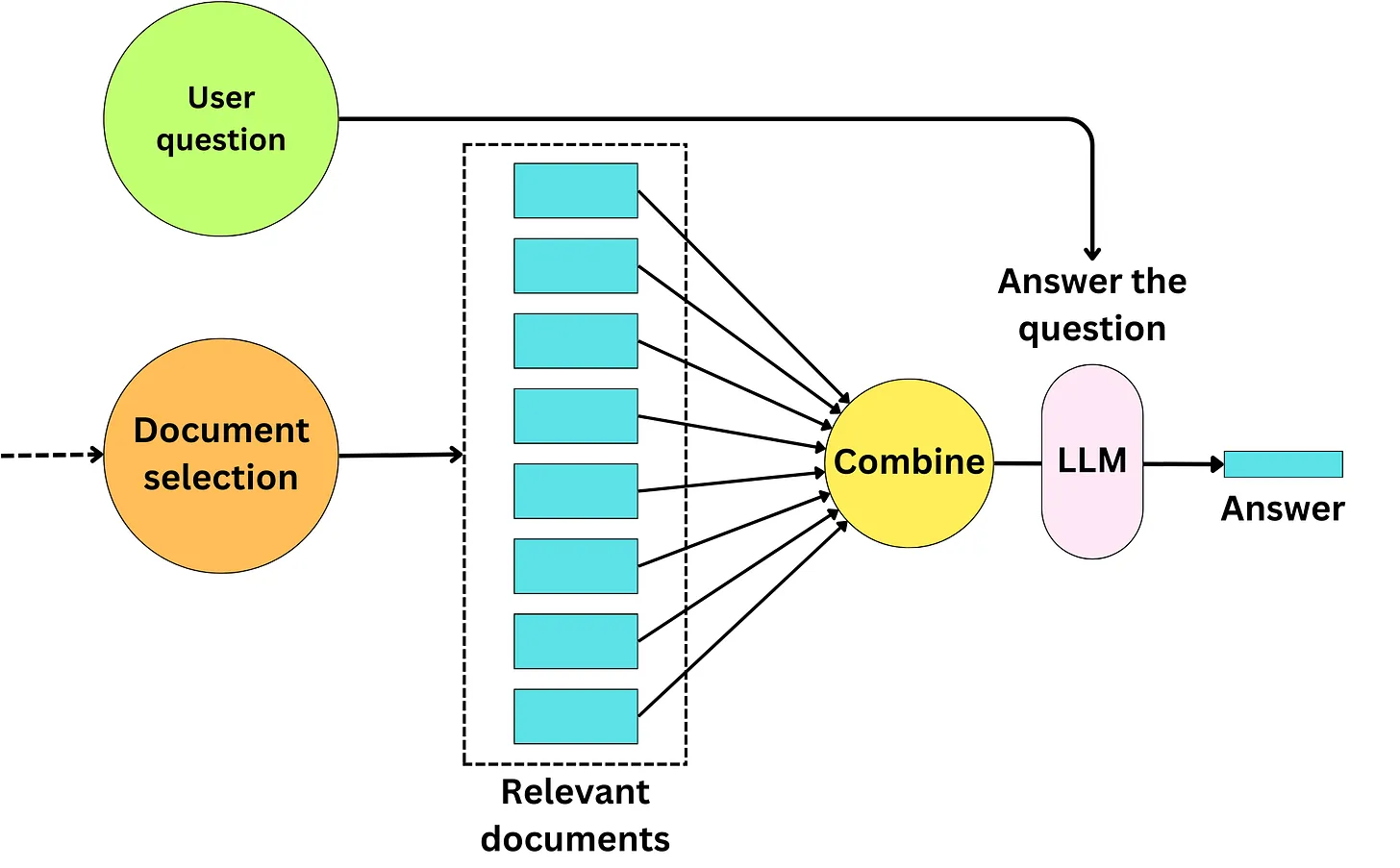
Chúng ta có thể thấy một prompt trong Langchain điển hình cho việc pass context vào LLM như sau
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. {context}
Question: {question}
Helpful Answer:
Trong đó {context} sẽ được thay; thế bằng nội dung concate của các documents. Tuy nhiên chúng ta có một số chiến lược khác tối ưu hơn mà các bạn có thể áp dụng dưới đây
Chiến lược Map-Reduce
Chắc hẳn bạn sẽ nhận ra một điểm yếu của chiến lược cơ bản phía trên đó là độ dài context của chúng ta có thể sẽ rất lớn nếu như số lượng documents càng nhiều. Điều này sẽ khiến cho ngữ cảnh của LLM bị phình to và đôi khi bị hiện tượng tràn context. Một chiến lược khác thay vì passing các documents trực tiếp để trả lời câu hỏi query, chúng ta có thể lặp qua các documents để lấy ra các thông tin có khả năng liên quan đến việc trả lời câu hỏi. Điều này đặc biệt hữu ích khi chúng ta có nhiều documents bởi chúng ta có thể extract các thông tin, tổng hợp các kết quả và lặp lại quá trình này cho đến khi các kết quả combined text vừa vặn với context length của LLM. Chúng ta có thể thấy rõ hơn trong hình dưới đây
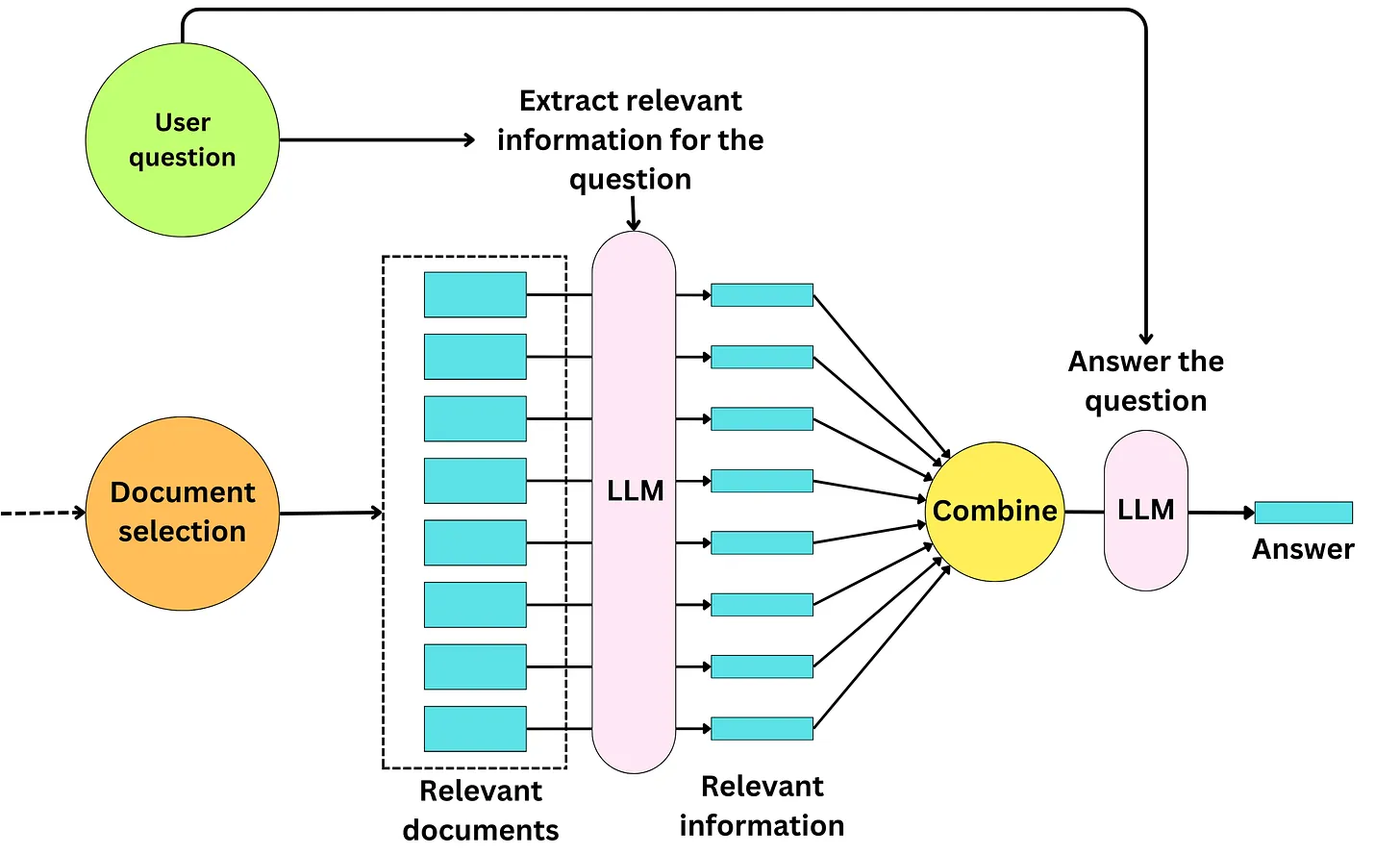
Quá trình này được gọi là Map-Reduce
TRong langchain chúng ta cso thể thực hiện Map step với prompt như sau
System: Use the following portion of a long document to see if any of the text is relevant to answer the question.
Return any relevant text verbatim.
{context}
Human: {question}
Và bước Reduce có thể thực hiện bằng prompt sau
Given the following extracted parts of a long document and a question, create a final answer.
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
{summaries}
Human: {question}
Chiến lược Refine answer
Chúng ta cũng có thể htuwcj hiện một chiến lược khác đó là refine dần dần câu trả lời khi lặp qua các documents và đưa vào context để trả lời cho câu hỏi của người dùng. Quy trình này thực hiện như sau
Chúng ta thực hiện chiến lược này với prompt trong Langchain như sau
Human: {question}
AI: {existing_answer}
Human: We have the opportunity to refine the existing answer(only if needed) with some more context below.
{context_str}
Given the new context, refine the original answer to better answer the question. If the context isn't useful, return the original answer.
Bằng thực nghiệm, phương pháp này có xu hướng khá không ổn định. Nếu LLM không trả lại câu trả lời ban đầu ở bất kỳ bước nào và quyết định giải thích rằng không có gì cần thêm vào câu trả lời hiện có, chúng ta sẽ mất hoàn toàn context và khả năng trả lời câu hỏi.
Chiến lược Map-rerank
Chiến lược này lặp lại qua các document và cố gắng trả lời các câu hỏi kèm theo một điểm số về mức độ chắc chắn của câu trả lời. Chúng ta sẽ lấy ra các câu trả lời có điểm số cao nhất làm câu trả lời cuối cùng.
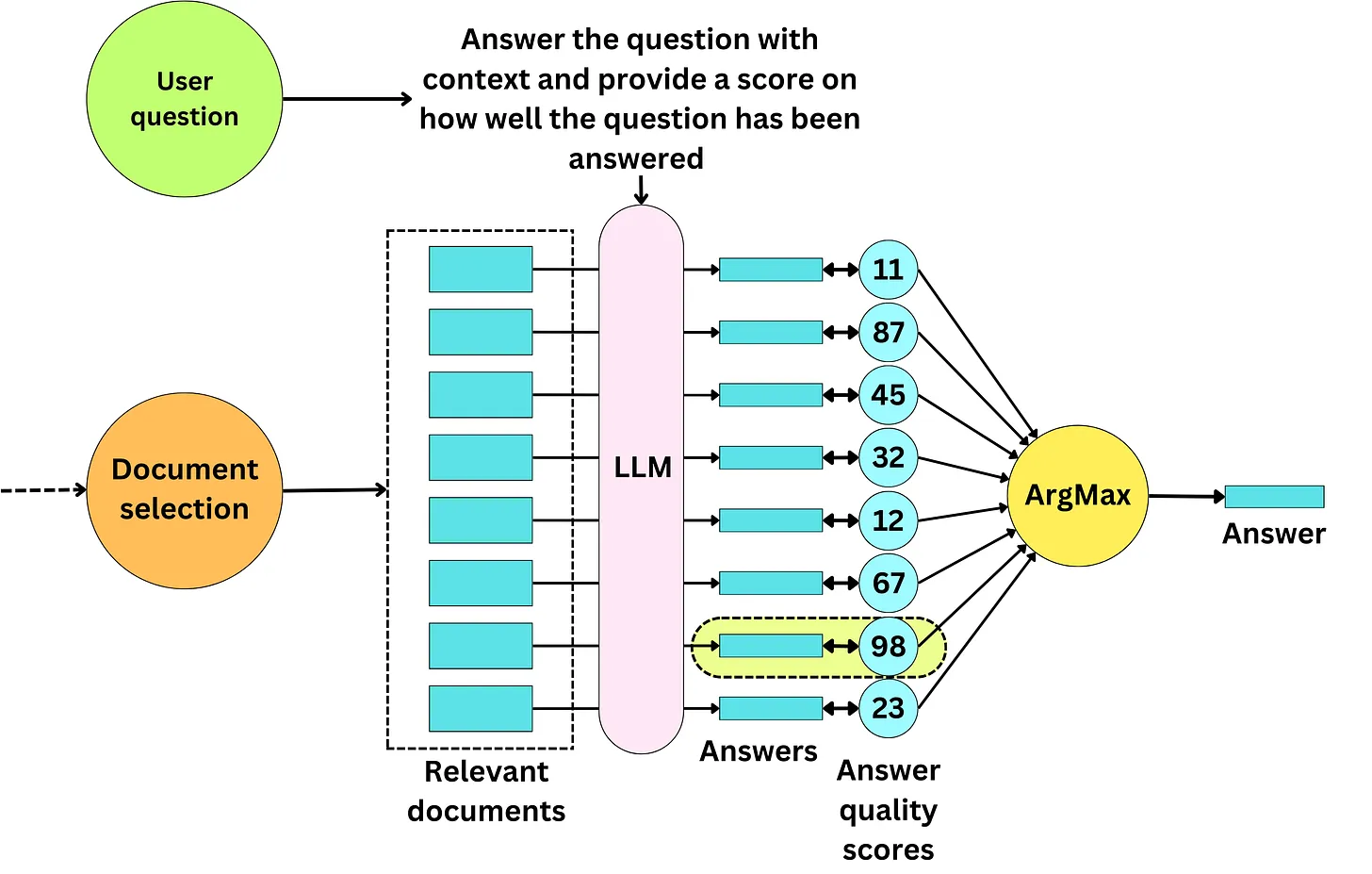
Prompt dưới đây cung cấp một vài few shot examples để LLM có thể hiểu làm thế nào để output ra một score như vậy
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
In addition to giving an answer, also return a score of how fully it answered the user's question. This should be in the following format:
Question: [question here]
Helpful Answer: [answer here]
Score: [score between 0 and 100]
How to determine the score:
Higher is a better answer
Better responds fully to the asked question, with sufficient level of detail
If you do not know the answer based on the context, that should be a score of 0
Don't be overconfident!
Example #1
Context:
Apples are red
Question: what color are apples?
Helpful Answer: red
Score: 100
Example #2
Context:
it was night and the witness forgot his glasses. he was not sure if it was a sports car or an suv
Question: what type was the car?
Helpful Answer: a sports car or an suv
Score: 60
Example #3
Context:
Pears are either red or orange
Question: what color are apples?
Helpful Answer: This document does not answer the question
Score: 0
Begin!
Context:
{context}
Question: {question}
Helpful Answer:
Kết luận
Trên đây là một vài bí kíp võ công thượng thừa khi làm việc với pipeline RAG. Rất mong nhận được đánh giá góp ý từ các bạn.
Nguồn tham khảo
https://newsletter.theaiedge.io/p/how-to-optimize-your-rag-pipelines
All rights reserved
