69 khái niệm kinh điển trong hành trình 10 năm phát triển của NLP - Phần 1 - Giai đoạn 2014 - 2018
Lời giới thiệu
Hello tất cả mọi người, trong bài viết này chúng ta sẽ cùng nhau nhìn lại lịch sử hào hùng với những tiến bộ vượt bậc trong suốt 10 năm qua ở lĩnh vực xử lý ngôn ngữ tự nhiên NLP. Và cũng rất rất lâu rồi các fan hôm mộ của mình trên kênh Youtube chưa được xem video mới từ mình nên mình cũng có làm một video giải thích chi tiết các khái niệm này như một lời tri ân đến các bạn vẫn theo dõi mình trong suốt thời gian qua. Video mình sẽ update sau nhé. OK không lằng nhằng nữa chúng ta bắt đầu ngay thôi
Giai đoạn 1: 2013 - 2015
#1 - Language Model
Language Model hay còn gọi là các mô hình ngôn ngữ là một loại mô hình học máy (thường là các mạng nơ ron) được huấn luyện trên các dữ liệu text với mục đích là dự đoán xác suất xuất hiện của các từ hay câu trong một ngôn ngữ.
Có hai loại language model phổ biến mà chúng ta thường thấy đó là Masked Language Model và Next Word Prediction Language Model.
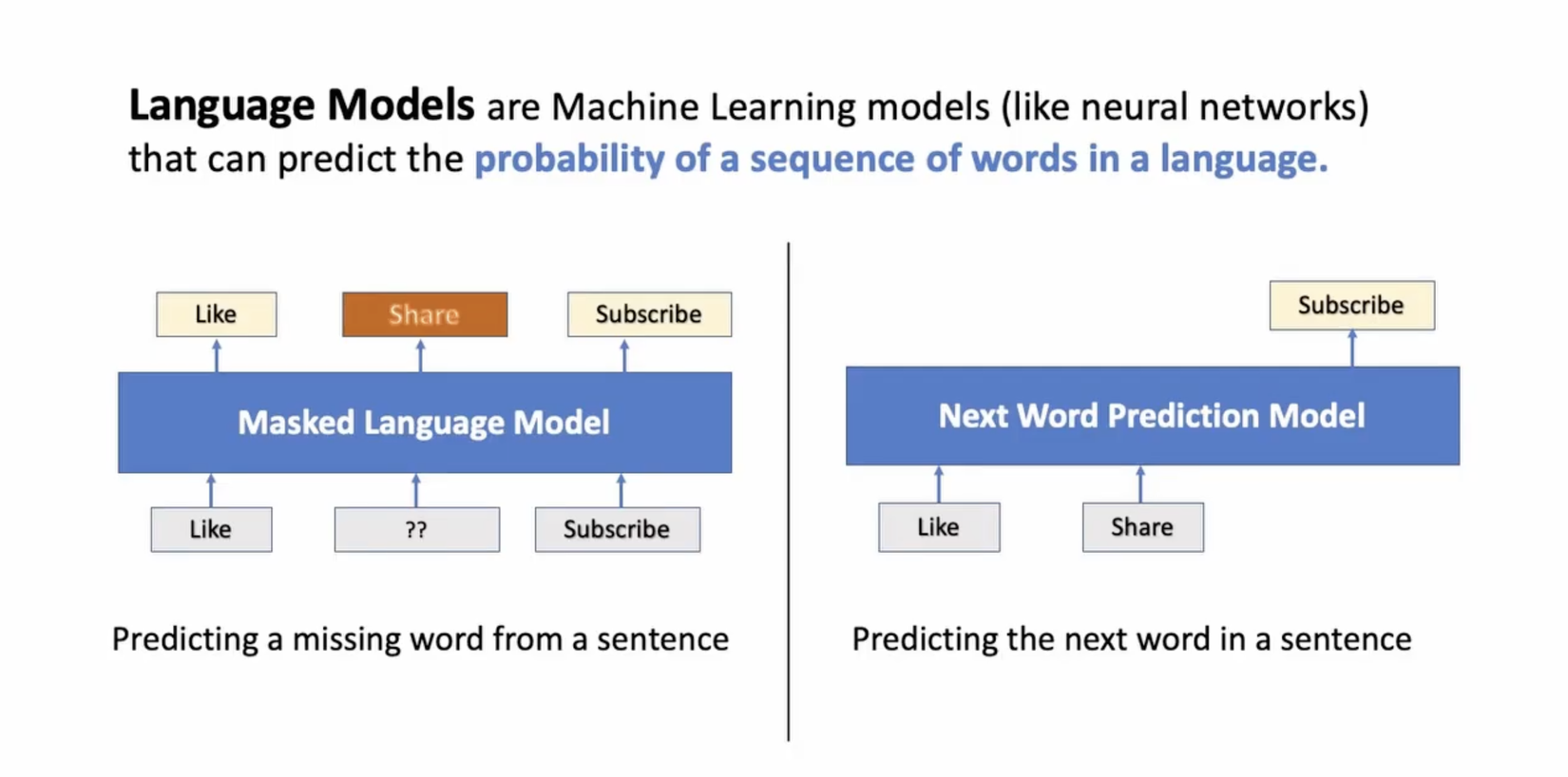
#2 - Masked Language Model - MLM
Là loại mô hình ngôn ngữ được học bằng cách che đi một phần thông tin trong câu văn (masked) và nhiệm vụ của mô hình là dự đoán lại các từ đã được masked. Việc huấn luyện mô hình MLM giúp mô hình hiểu được ngữ cảnh và quan hệ giữa các từ trong văn bản. Bằng cách dự đoán các từ bị che đi, mô hình học cách tương tác với các từ xung quanh, học cú pháp và ý nghĩa của các từ. Một đại diện nổi tiếng của MLM chính là mô hình BERT và các biến thể của nó.
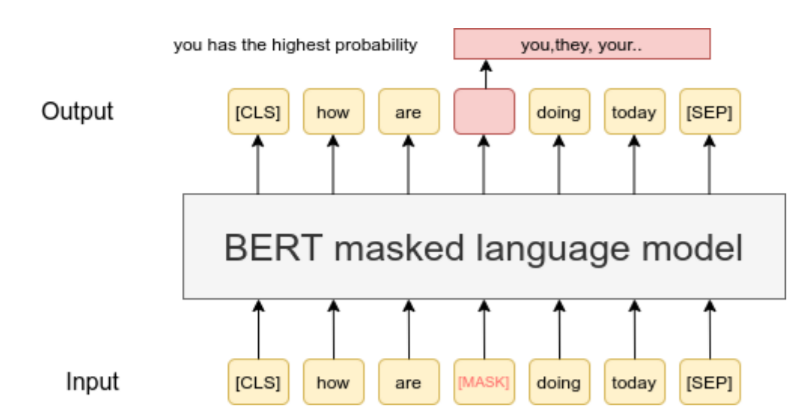
#3 - Next Word Prediction Model
Đây là loại mô hình ngôn ngữ với tác vụ dự đoán từ xuất hiện tiếp theo. Một trong những đại diện xuất sắc của mô hình này chính là ChatGPT mà chúng ta sử dụng rất nhiều ngày nay. Tuy nhiên trong giai đoạn trước đó thì mô hình này cũng xuất hiện rất nhiều trong các ứng dụng, nhất là Google Search. Các bạn có thể thấy khi nhập vào một câu query thì mô hình sẽ gợi ý các từ tiếp theo có xác suất xuất hiện lớn nhất

#4 - Tokenization
Tokenization trong xử lý ngôn ngữ tự nhiên (NLP) là quá trình chia văn bản thành các đơn vị nhỏ hơn gọi là "token". Một token có thể là một từ, một ký tự, một cụm từ, hoặc một phần khác của văn bản như dấu câu.
Việc tokenization là quan trọng bởi vì nó tạo ra các đơn vị nhỏ hơn để mô hình NLP có thể xử lý và hiểu. Thay vì xử lý một đoạn văn bản dài, chúng ta chia nó thành các token riêng lẻ để có thể áp dụng các phương pháp xử lý và phân tích trên từng token đơn lẻ.
Ví dụ, khi ta có câu "Tôi thích ăn pizza", quá trình tokenization sẽ chia nó thành các token như sau: ["Tôi", "thích", "ăn", "pizza"]. Mỗi từ trong câu trở thành một token riêng lẻ, giúp mô hình hiểu và xử lý từng phần của câu.
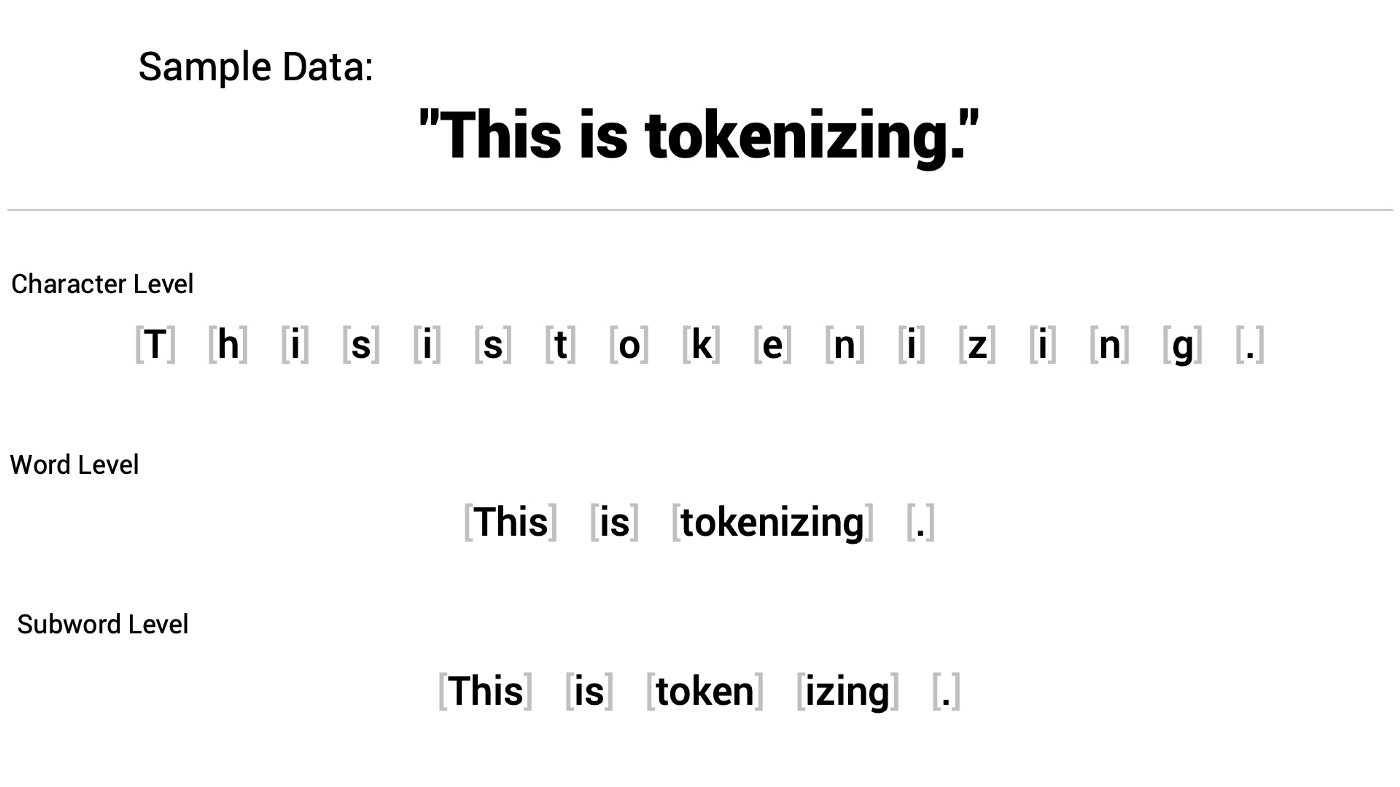
#5 - Subword Tokenization
Subword tokenization là một phương pháp của tokenization trong xử lý ngôn ngữ tự nhiên (NLP) mà không chỉ chia văn bản thành các từ riêng lẻ, mà còn chia các từ thành các phần nhỏ hơn gọi là "subword tokens". Trong subword tokenization, các từ được chia thành các subword token dựa trên các quy tắc ngữ pháp hoặc các thuật toán học máy.
Hầu hết các mô hình ngôn ngữ hiện nay đều sử dụng phương pháp subword tokenization như Byte-Pair Encoding (BPE), Unigram Language Model (ULM).
Phương pháp này sử dụng
#6 - Vocabulary
Sau khi tokenization chúng ta sẽ có một tập hợp các token tương ứng với các index. Index này cho phép mô hình truy cập và tham khảo từng từ trong quá trình xử lý văn bản. Bản thân các mô hình ngôn ngữ cũng là các mạng nơ ron nên nó sẽ sử dụng các vector dạng số trong quá trình xử lý nên trên thực tế thì Language model sẽ làm việc với các index trong vocabulary thay vì các token (thực tế người ta thường sử dụng dạng embedding của các từ thay vì sử dụng trực tiếp các index, quá trình tạo ra các embedding vector cho từng từ được gọi là word embedding). Ở quá trình decode, các index này sẽ được sử dụng để convert ngược lại thành các token và tạo thành câu hoàn chỉnh.

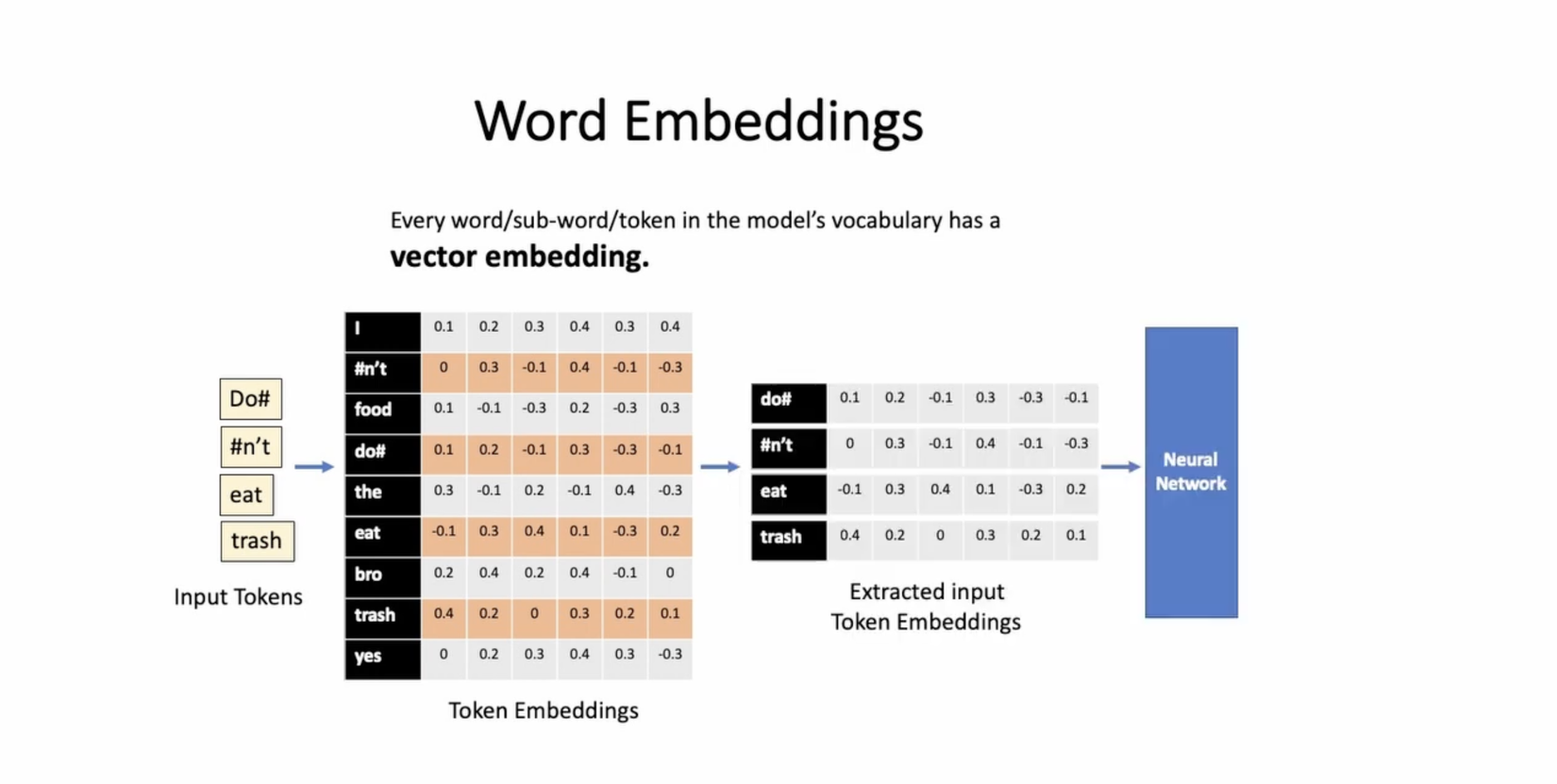
#7 - Word Embedding
Word embedding là một kỹ thuật biểu diễn từ dựa trên không gian vector, trong đó mỗi từ trong vocabulary được ánh xạ thành một vector số thực. Word embedding cho phép mô hình hiểu và biểu diễn ý nghĩa ngữ nghĩa của từ dưới dạng các giá trị số, giúp hỗ trợ quá trình huấn luyện và dự đoán.
Các mô hình ngôn ngữ thường sử dụng word embedding như là một phần của quá trình xử lý dữ liệu đầu vào. Thay vì truyền các index từ vocabulary trực tiếp vào mô hình, các từ được biểu diễn bằng các vector word embedding tương ứng. Điều này giúp mô hình học và hiểu các đặc trưng ngữ nghĩa của từng từ.
Có nhiều phương pháp để tạo word embedding, ví dụ như Word2Vec, GloVe, FastText, và Transformer-based models như BERT. Các phương pháp này huấn luyện các mô hình để tìm ra các mối quan hệ ngữ nghĩa giữa các từ và biểu diễn chúng thành các vector số thực.
Giai đoạn 2: 2015 - 2017: Kỉ nguyên của RNN
#8 - Recurrent Neural Network - RNN
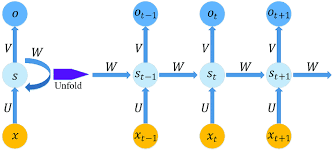
RNN là một kiến trúc mạng nơ-ron nhân tạo được thiết kế đặc biệt để làm việc với dữ liệu tuần tự hoặc chuỗi.
Ý tưởng chính của RNN là cho phép thông tin được truyền đi từ quá khứ đến timestep hiện tại và tiếp tục truyền qua các timestep tiếp theo. Điều này giúp RNN có khả năng nhớ thông tin từ quá khứ và sử dụng nó để bổ sung thông tin và đưa ra các quyết định tại thời điểm hiện tại.
Cấu trúc cơ bản của một RNN bao gồm một loạt các "cell" hay còn gọi là các "units". Mỗi cell có vai trò như một bộ nhớ nhỏ, giữ trạng thái nội tại (hidden state) để lưu trữ thông tin từ quá khứ. Tại mỗi timestep, RNN nhận đầu vào là hidden state từ các timestep trước đó kết hợp với input token tại timestep hiện tại, tính toán và truyền tiếp hidden state sang timestep tiếp theo.
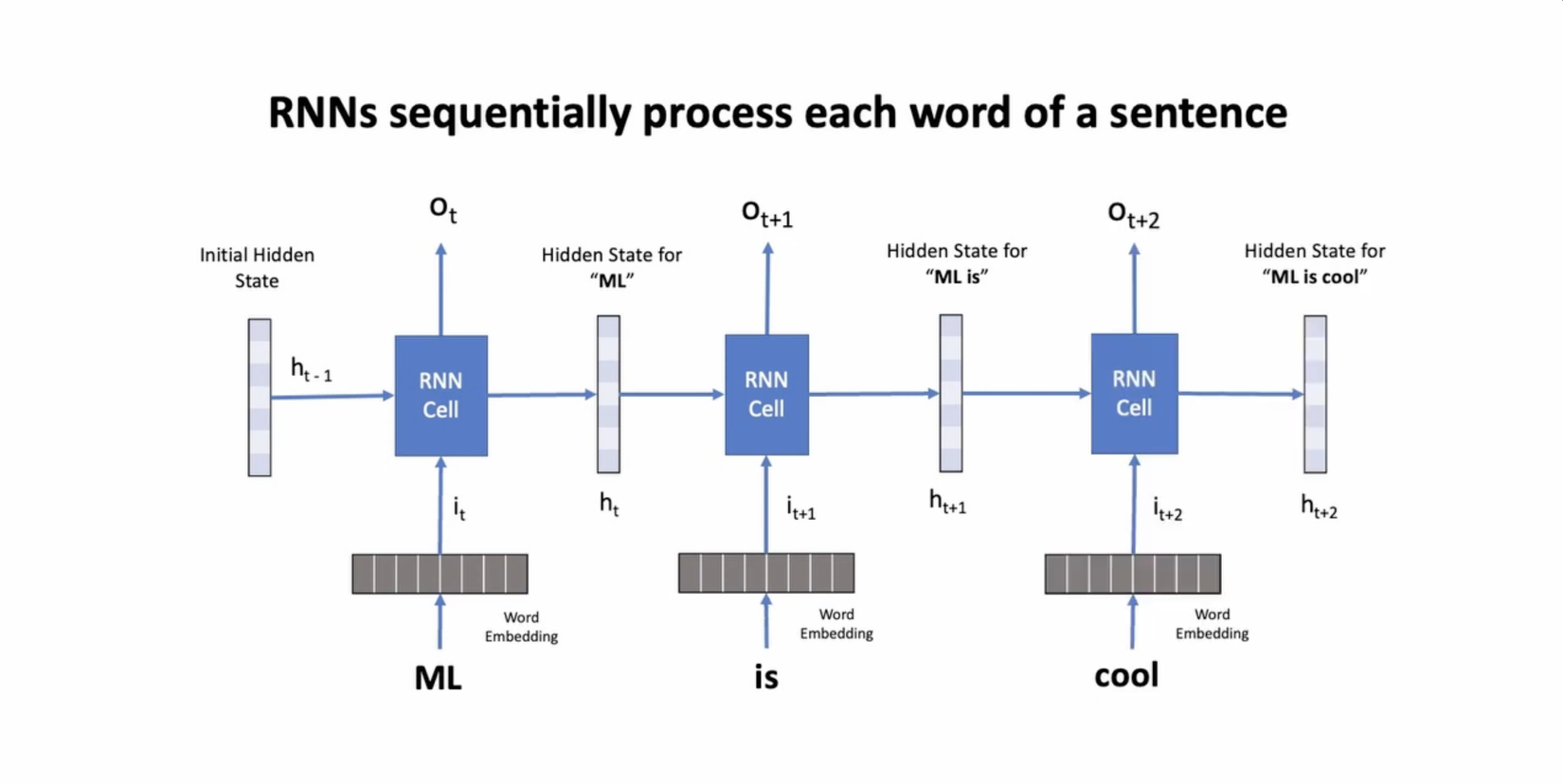
#9 - Weight Sharing
Như các bạn đã thấy trên sơ đồ trên thì các RNN Cell có cùng một màu xanh dương, điều này ám chỉ rằng các RNN Cell này có chung một bộ trọng số. Cơ chế này được gọi là weight sharing và nó đóng một vai trò quan trọng trong RNN. Một số lý do của weight sharing trong RNN như:
- Xử lý dữ liệu tuần tự: RNN được thiết kế đặc biệt để làm việc với dữ liệu tuần tự như ngôn ngữ tự nhiên, chuỗi thời gian, v.v. Trong các tác vụ này, thông tin từ quá khứ có ý nghĩa quan trọng và cần được giữ lại để ảnh hưởng đến quyết định tại thời điểm hiện tại. Bằng cách chia sẻ trọng số, RNN có khả năng duy trì trạng thái nội tại (hidden state) và truyền thông tin từ timestep trước đó sang timestep tiếp theo.
- Giảm số lượng tham số: Chia sẻ trọng số trong RNN giúp giảm số lượng tham số cần tối ưu. Thay vì có một tập trọng số riêng cho mỗi timestep, cùng một tập trọng số được áp dụng cho tất cả các timestep. Điều này giúp giảm độ phức tạp tính toán và tiết kiệm bộ nhớ, đặc biệt quan trọng khi làm việc với dữ liệu lớn và mô hình phức tạp.
- Mô hình hóa mẫu dữ liệu: Chia sẻ trọng số giữa các timestep cho phép mô hình học các mẫu dữ liệu tuần tự. Khi trọng số được chia sẻ, cùng một quy tắc tính toán được áp dụng cho mỗi timestep. Điều này giúp mô hình nhận biết và mô hình hóa các mẫu ngữ pháp, ngữ nghĩa hay các mẫu chuỗi thời gian trong dữ liệu đầu vào.
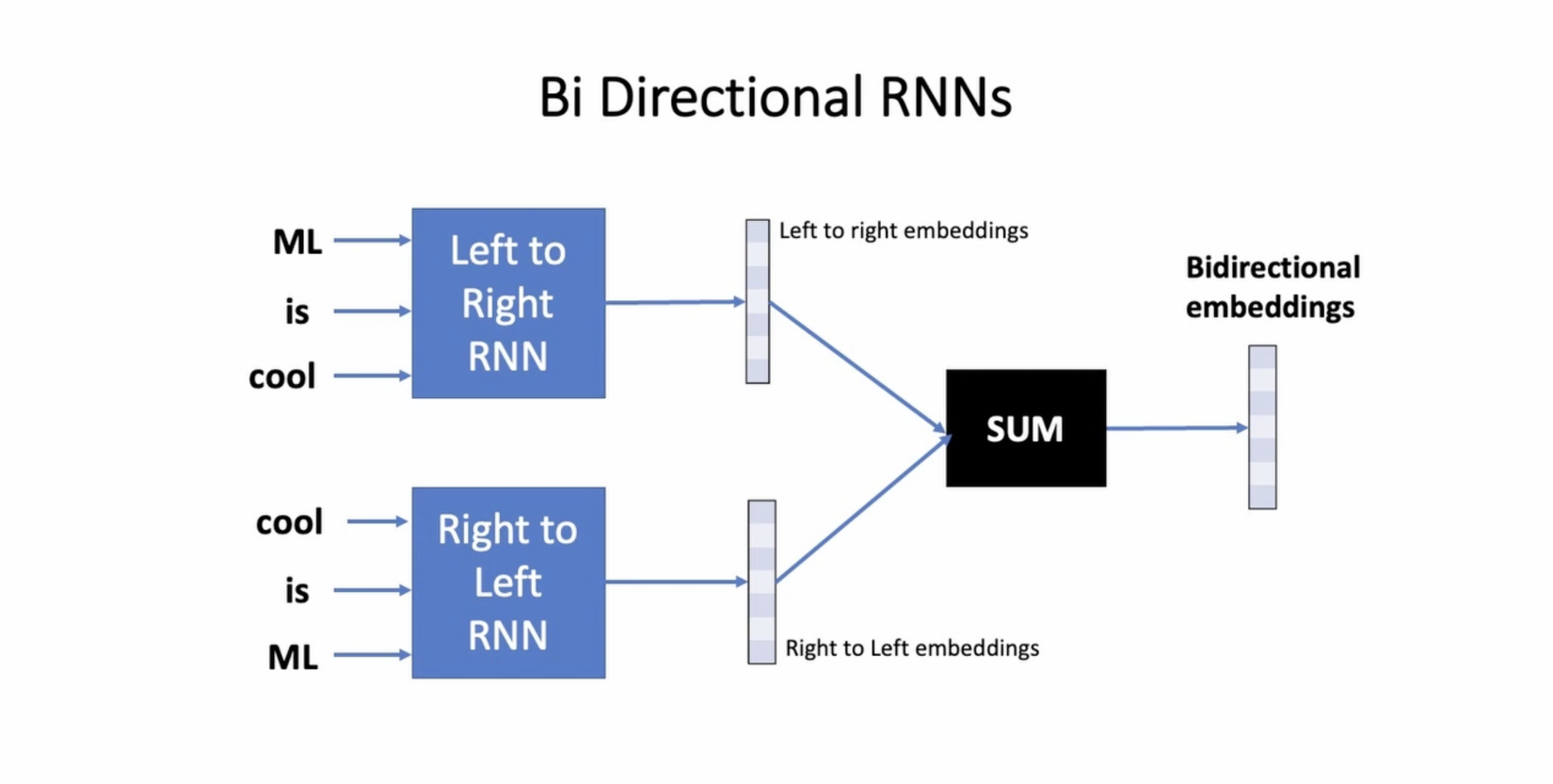
#10 - Bi-Directional RNN
Mạng nơ-ron định hướng hai chiều (Bi-directional Recurrent Neural Network - Bi-RNN) là một kiến trúc mạng nơ-ron đặc biệt trong đó thông tin được xử lý cả theo hướng thuận (forward) và hướng ngược (backward) của dữ liệu đầu vào.
Trong một mạng nơ-ron thuận (forward neural network), thông tin chỉ di chuyển từ đầu vào tới đầu ra theo một hướng duy nhất. Điều này có nghĩa là mạng chỉ có thể dự đoán các đầu ra dựa trên thông tin từ quá khứ và hiện tại, trong khi không có thông tin về tương lai.
Tuy nhiên, trong một số tác vụ, thông tin từ tương lai có thể cung cấp sự hỗ trợ quan trọng để hiểu và dự đoán các đầu ra. Đó là lý do mạng nơ-ron định hướng hai chiều được sử dụng. Bi-RNN sử dụng hai bộ mạng nơ-ron độc lập, một theo hướng thuận và một theo hướng ngược.
Trong quá trình huấn luyện, đầu vào được xử lý cả theo hướng thuận và hướng ngược. Mỗi timestep, mạng thuận tính toán đầu ra trên cơ sở thông tin từ quá khứ và hiện tại, trong khi mạng ngược tính toán đầu ra trên cơ sở thông tin từ hiện tại và tương lai. Kết quả là mỗi timestep sẽ có hai đầu ra, một từ mạng thuận và một từ mạng ngược.
Thông tin từ mạng ngược và mạng thuận trong Bi-RNN thường được kết hợp (combine) với nhau bằng một phép toán đơn giản như nối chuỗi (concatenation) hoặc cộng vector (addition). Cách kết hợp này tùy thuộc vào cấu trúc và mục tiêu của mô hình cụ thể.
Quá trình này cho phép mạng nơ-ron định hướng hai chiều sử dụng cả thông tin từ quá khứ và tương lai để hiểu và dự đoán các đầu ra. Điều này rất hữu ích trong các nhiệm vụ như dịch máy, nhận dạng giọng nói, phân loại câu, v.v., nơi cả ngữ cảnh trước và sau đều quan trọng để đưa ra quyết định chính xác.
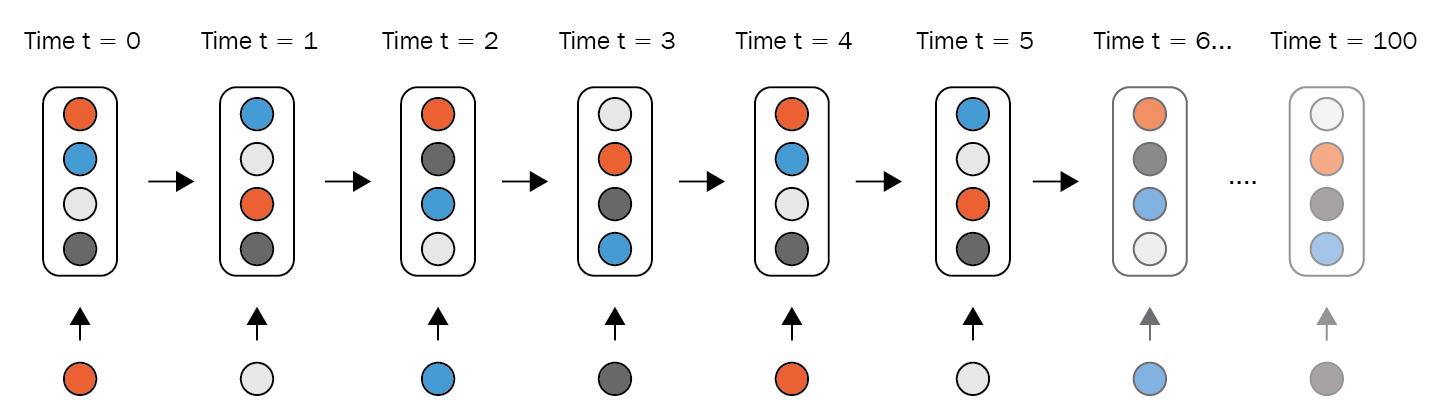
#11 - Unbounded Temporal Depth hay Long-term Memory
Unbounded Temporal Depth hay đôi khi còn có tên goi khác là Long-term Memory là một thuật ngữ sử dụng để ám chỉ rằng về mặt lý thuyết thì RNN có thể lưu trữ được thông tin có độ dài vô hạn. Hay nói cách khác thì thông tin truyền qua RNN qua các timestep không bị giới hạn về độ dài.
Trong lý thuyết, RNN cho phép truyền thông tin qua các timestep mà không bị mất mát hoặc giảm đáng kể. Điều này đồng nghĩa với việc RNN có thể lưu trữ và ghi nhớ thông tin từ quá khứ xa trong dữ liệu tuần tự.
Tuy nhiên, trong thực tế, vấn đề biến mất gradient (gradient vanishing) và bùng nổ gradient (gradient exploding) trong RNN có thể làm giảm khả năng lưu trữ thông tin qua các timestep lớn. Điều này làm cho việc đạt được độ dài timestep vô hạn trở nên khó khăn trong thực tế.
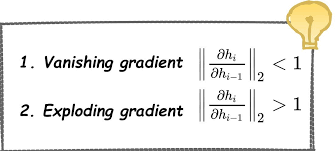
#12 - Gradient Vanishing - biến mất gradient
Gradient vanishing (biến mất gradient) là hiện tượng xảy ra trong quá trình huấn luyện mạng nơ-ron sâu (deep neural network), khi đạo hàm của hàm mất mát giảm dần đáng kể khi lan truyền ngược từ các lớp cuối cùng về các lớp đầu tiên. Điều này dẫn đến việc giảm tốc độ học và khả năng mô hình hội tụ chậm hoặc không thể hội tụ hoàn toàn.
Nguyên nhân chính của gradient vanishing là tích chập liên tục của các đạo hàm trong quá trình lan truyền ngược. Khi đạo hàm nhỏ hơn 1, việc tích chập liên tục có thể làm cho giá trị của gradient giảm một cách đáng kể qua từng lớp, đặc biệt là các lớp đầu tiên. Khi gradient giảm quá nhỏ, các trọng số trong mạng không được cập nhật đáng kể và mô hình không học được thông tin từ các training sample.
Gradient vanishing thường xảy ra trong các mạng nơ-ron sâu có kiến trúc như Recurrent Neural Networks (RNNs) và các mạng nơ-ron sâu truyền thẳng (feedforward neural networks) với nhiều lớp ẩn. Đặc biệt, trong RNNs, khi lan truyền ngược xuyên qua các thời điểm, việc tích chập liên tục của gradient có thể làm mất mát thông tin quan trọng từ các timestep xa.
#13 - Gradient Exploding - bùng nổ gradient
Nguyên nhân chính của exploding gradient là tích chập liên tục của các đạo hàm trong quá trình lan truyền ngược. Khi đạo hàm lớn hơn 1, việc tích chập liên tục có thể làm cho giá trị gradient tăng một cách nhanh chóng qua từng lớp. Khi gradient tăng quá lớn, việc cập nhật trọng số dựa trên gradient này có thể làm cho mô hình thay đổi quá nhanh và không ổn định, gây ra sự không hội tụ hoặc mô hình không học được.
#14 - Gated RNNs
Gated RNN (Gated Recurrent Neural Network) là một dạng mở rộng của RNN (Recurrent Neural Network) được thiết kế để giải quyết vấn đề biến mất gradient (vanishing gradient) và nổ gradient (exploding gradient) trong việc xử lý dữ liệu tuần tự dài.
Gated RNN sử dụng các cơ chế cổng (gates) để điều chỉnh luồng thông tin trong quá trình lan truyền ngược và tránh mất mát thông tin quá sớm hoặc quá nhanh. Hai kiến trúc phổ biến của Gated RNN là Long Short-Term Memory (LSTM) và Gated Recurrent Unit (GRU).
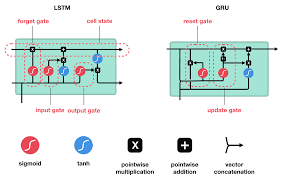
#15 - Long Short Term Memory - LSTM
LSTM có khả năng duy trì và truyền thông tin qua các timestep dài hơn trong RNN. Nó sử dụng các cơ chế cổng để điều chỉnh thông qua của gradient, giúp kiểm soát quá trình lan truyền ngược và lưu trữ thông tin quan trọng từ quá khứ.
Kiến trúc LSTM bao gồm các đơn vị nhớ (memory cells) và ba cổng chính: cổng quên (forget gate), cổng đầu vào (input gate) và cổng đầu ra (output gate). Cổng quên quyết định thông tin nào sẽ được loại bỏ từ đơn vị nhớ. Cổng đầu vào quyết định thông tin nào sẽ được cập nhật vào đơn vị nhớ. Cổng đầu ra quyết định thông tin nào sẽ được truyền ra từ đơn vị nhớ.
Các cổng trong LSTM cho phép mô hình điều chỉnh mức độ lưu trữ và quên thông tin từ quá khứ, giúp giải quyết vấn đề biến mất gradient và nổ gradient. Điều này làm cho LSTM trở thành một công cụ mạnh mẽ để xử lý dữ liệu tuần tự và mô hình hoạt động dựa trên dữ liệu chuỗi có khả năng ghi nhớ thông tin xa trong quá khứ.
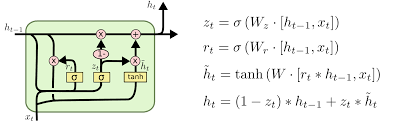
#16 - Gated Recurent Unit - GRU
GRU (Gated Recurrent Unit) là một kiến trúc mạng nơ-ron hồi quy (RNN) được thiết kế để giải quyết vấn đề biến mất gradient và nổ gradient, tương tự như LSTM (Long Short-Term Memory).
GRU cũng như LSTM, có khả năng lưu trữ và truyền thông tin qua các timestep trong mạng RNN. Nó sử dụng các cơ chế cổng để điều chỉnh thông qua của gradient, nhưng có cấu trúc đơn giản hơn so với LSTM.
Kiến trúc GRU bao gồm hai cổng chính: cổng đặc biệt (update gate) và cổng đầu ra (reset gate). Cổng đặc biệt quyết định mức độ lưu trữ thông tin mới và thông tin cũ từ quá khứ. Cổng đầu ra quyết định thông tin nào sẽ được truyền ra từ đơn vị nhớ.
GRU loại bỏ cổng quên có trong LSTM và thay thế bằng cổng đặc biệt, giúp đơn giản hóa kiến trúc và giảm độ phức tạp tính toán. Sự đơn giản này cũng làm cho việc huấn luyện GRU nhanh hơn so với LSTM.
Mặc dù GRU có cấu trúc đơn giản hơn, nó vẫn có khả năng mô hình hóa dữ liệu chuỗi phức tạp và lưu trữ thông tin từ quá khứ xa. GRU đã trở thành một lựa chọn phổ biến trong các ứng dụng RNN và đã chứng minh được hiệu suất tốt trong nhiều tác vụ như dịch máy, nhận diện giọng nói và dự đoán chuỗi thời gian.
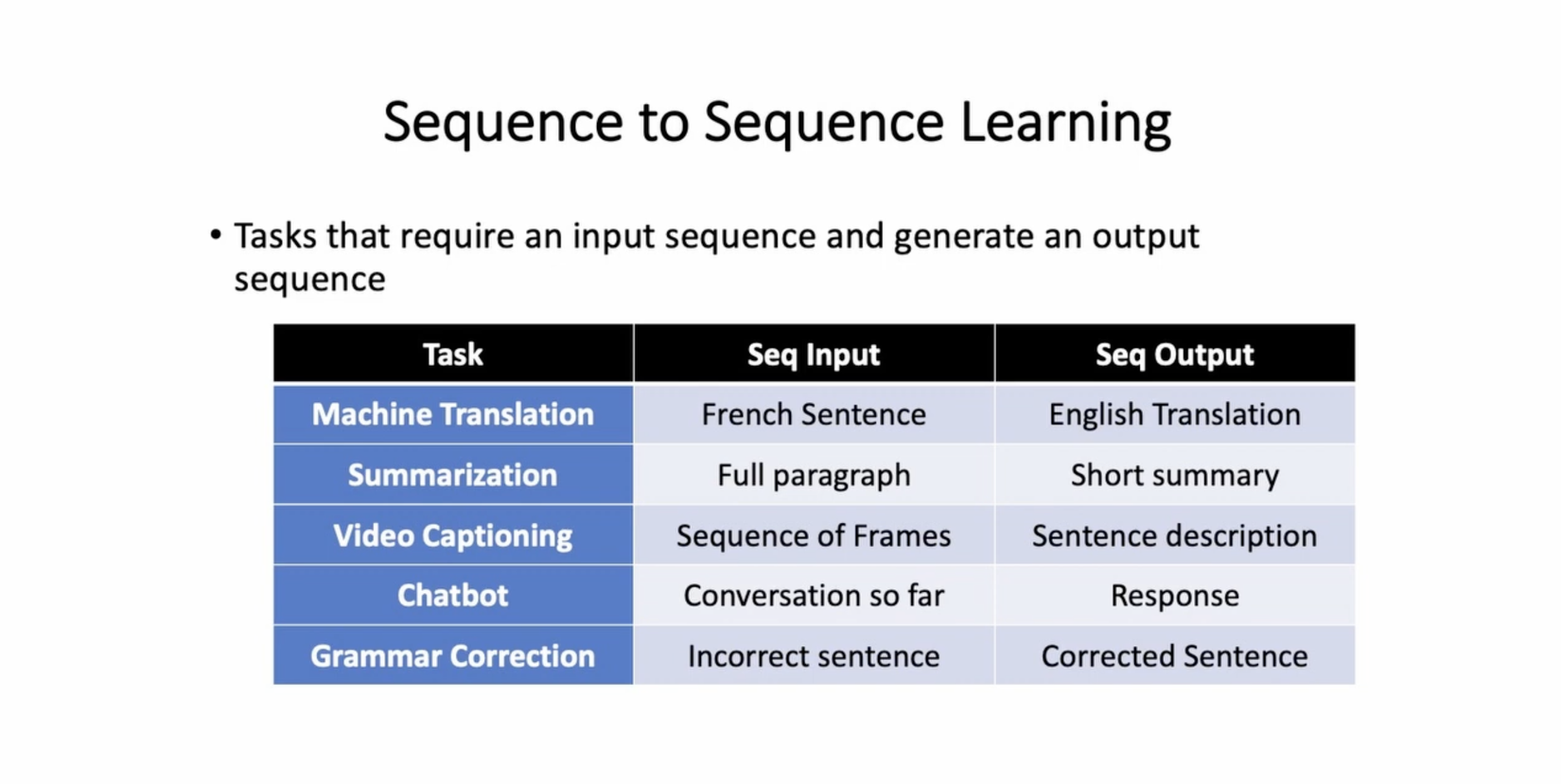
#17 - Sequence to sequence tasks
Sequence-to-sequence (seq2seq) tasks là những nhiệm vụ trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) mà đầu vào và đầu ra đều là các chuỗi (sequence) của các thành phần ngôn ngữ, chẳng hạn như từ, ký tự hoặc câu.
Mục tiêu chính của seq2seq tasks là tạo ra một mô hình có khả năng chuyển đổi một chuỗi đầu vào thành một chuỗi đầu ra khác. Các nhiệm vụ phổ biến của seq2seq tasks bao gồm:
- Mô hình dịch máy: Mô hình seq2seq được sử dụng để dịch một câu hoặc một đoạn văn bản từ một ngôn ngữ nguồn sang một ngôn ngữ đích. Ví dụ, chuyển đổi từ tiếng Anh sang tiếng Pháp.
- Tóm tắt văn bản: Mô hình seq2seq có thể được sử dụng để tạo ra một bản tóm tắt ngắn gọn của một đoạn văn bản dài. Ví dụ, tạo ra một tóm tắt cho một bài báo hoặc một bài đăng trên mạng xã hội.
- Hỏi đáp (Question-Answering): Mô hình seq2seq có thể được sử dụng để trả lời các câu hỏi dựa trên một đoạn văn bản. Ví dụ, trả lời các câu hỏi từ một đoạn văn bản trong một bài báo.
- Tạo tiêu đề: Mô hình seq2seq có thể được sử dụng để tạo ra một tiêu đề cho một đoạn văn bản dựa trên nội dung của nó. Ví dụ, tạo tiêu đề cho một bài báo hoặc một bài blog.
Các mô hình seq2seq phổ biến như Recurrent Neural Networks (RNNs) và Transformer đã được sử dụng trong các nhiệm vụ seq2seq tasks. Thông qua việc học và mô hình hóa các mối quan hệ giữa các thành phần trong chuỗi, mô hình seq2seq có khả năng xử lý các tác vụ phức tạp trong lĩnh vực xử lý ngôn ngữ tự nhiên.
#18 - Kiến trúc Encoder - Decoder
Trong paper "Sequence to Sequence Learning with Neural Networks" của tác giả Lê Viết Quốc và cộng sự (2014) giới thiệu kiến trúc Encoder-Decoder cho các nhiệm vụ seq2seq (sequence-to-sequence) trong xử lý ngôn ngữ tự nhiên.
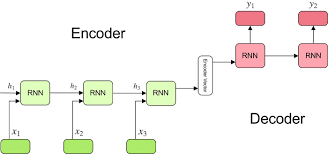
Kiến trúc Encoder-Decoder bao gồm hai phần chính: một mạng nơ-ron hồi quy (RNN) đóng vai trò là Encoder và một RNN khác đóng vai trò là Decoder.
- Encoder: Đầu vào của Encoder là một chuỗi đầu vào (ví dụ: câu tiếng Anh) và nhiệm vụ của nó là mã hóa thông tin của chuỗi đầu vào thành một biểu diễn ngữ cảnh (context representation) duy nhất. Trong paper này, tác giả sử dụng mạng nơ-ron hồi quy (RNN) làm Encoder, trong đó mỗi thành phần trong chuỗi đầu vào (từ hoặc ký tự) được đưa vào mạng theo thứ tự và mỗi bước thời gian của RNN sẽ xử lý một thành phần trong chuỗi. Khi đạt đến thành phần cuối cùng, RNN sẽ trả về biểu diễn ngữ cảnh của toàn bộ chuỗi.
- Decoder: Đầu vào của Decoder là biểu diễn ngữ cảnh từ Encoder và nhiệm vụ của nó là dự đoán chuỗi đầu ra (ví dụ: câu tiếng Pháp) từ biểu diễn ngữ cảnh. Tương tự như Encoder, tác giả sử dụng một RNN làm Decoder. Tuy nhiên, RNN của Decoder được huấn luyện để tạo ra các thành phần trong chuỗi đầu ra một cách tuần tự. Mỗi bước thời gian của RNN Decoder sẽ dự đoán một thành phần trong chuỗi đầu ra và sử dụng dự đoán trước đó để ảnh hưởng đến dự đoán hiện tại.
Qua quá trình huấn luyện, Encoder-Decoder được điều chỉnh để tối ưu hóa khả năng dự đoán chuỗi đầu ra chính xác. Kiến trúc này đã chứng tỏ hiệu quả trong nhiều nhiệm vụ seq2seq như dịch máy, tóm tắt văn bản và hỏi đáp.
#19 - Beam Search
Beam Search là một thuật toán tìm kiếm được sử dụng trong seq2seq để tạo ra văn bản tự động. Thay vì chỉ chọn từ có xác suất cao nhất, Beam Search duyệt qua các lựa chọn tiềm năng và giữ lại các chuỗi đầu ra có xác suất cao nhất dựa trên một số lượng xác định (beam width). Điều này giúp tăng tính đa dạng của văn bản được sinh ra và đảm bảo rằng chúng ta không chỉ tập trung vào một lựa chọn duy nhất.
#20 - Encoder - Decoder (Flaws)
Kiến trúc Encoder-Decoder có những điểm hạn chế như việc nén tất cả các thông tin của câu input đầu vào dưới một embedding layer ở cuối quá trình encode có thể dẫn đến hiện tượng mô hình bị mất thông tin ngữ cảnh nhất là đối với các câu dài
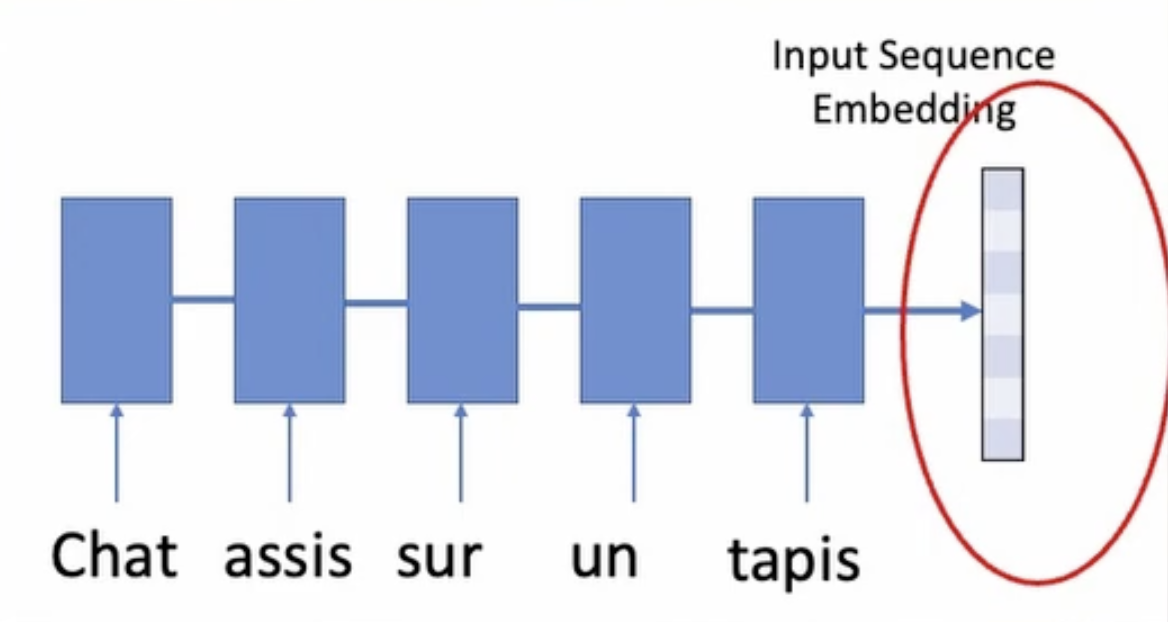
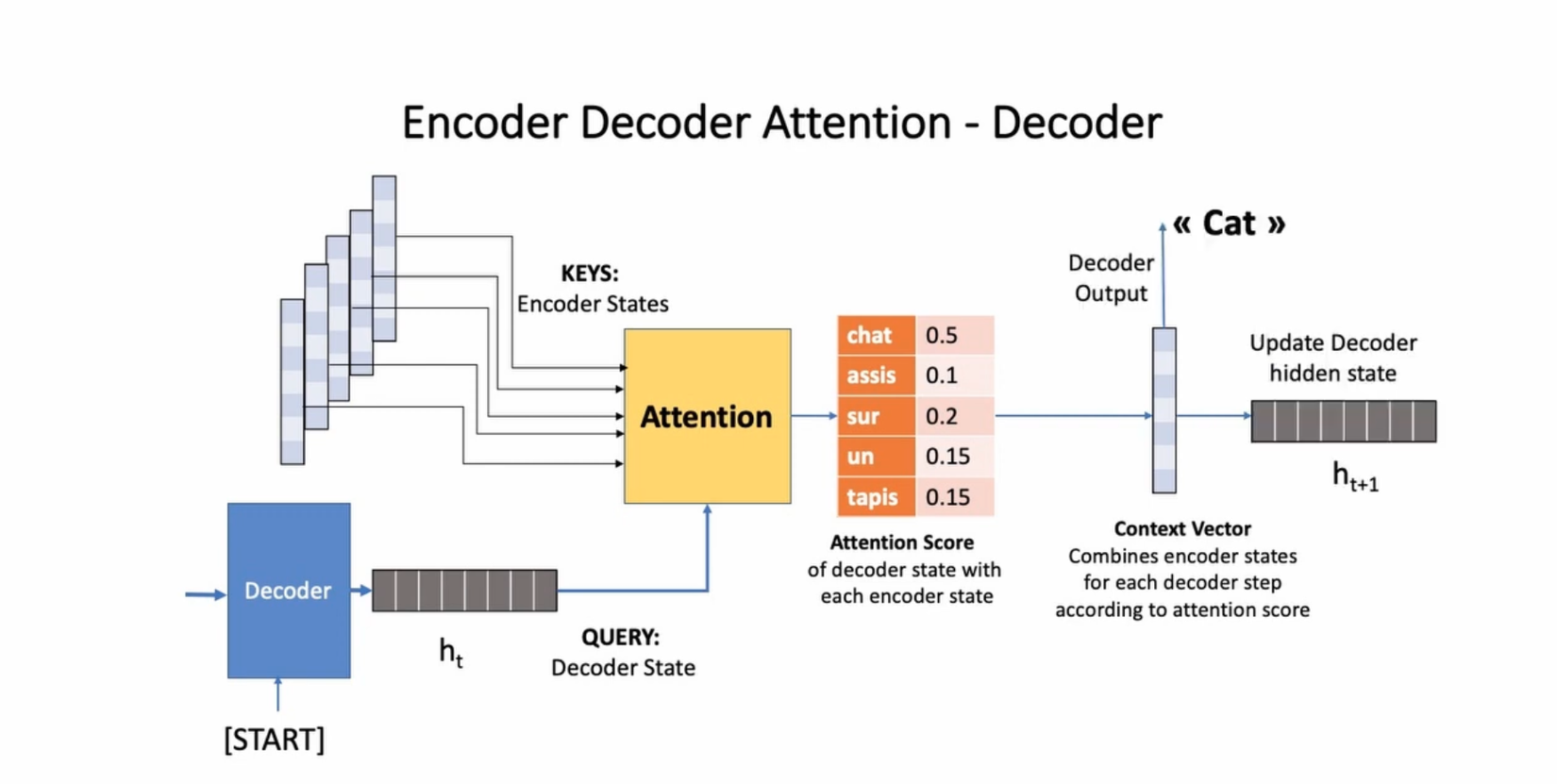
#21 - Cơ chế Attention (2015)
Cơ chế Attention được đề cập lần đầu trong bài báo "Neural Machine Translation by Jointly Learning to Align and Translate" năm 2015 là một phương pháp giúp mô hình Seq2Seq xử lý dữ liệu dài và tập trung vào các phần quan trọng của chuỗi đầu vào.

Trong cơ chế Attention, mô hình Seq2Seq không chỉ sử dụng một vector tóm tắt ngữ cảnh duy nhất từ quá trình encode, mà còn tạo ra một trọng số (attention weight) cho mỗi từ trong chuỗi đầu vào. Trọng số này biểu thị mức độ quan trọng của từ đó đối với việc dự đoán từ tiếp theo trong quá trình giải mã.
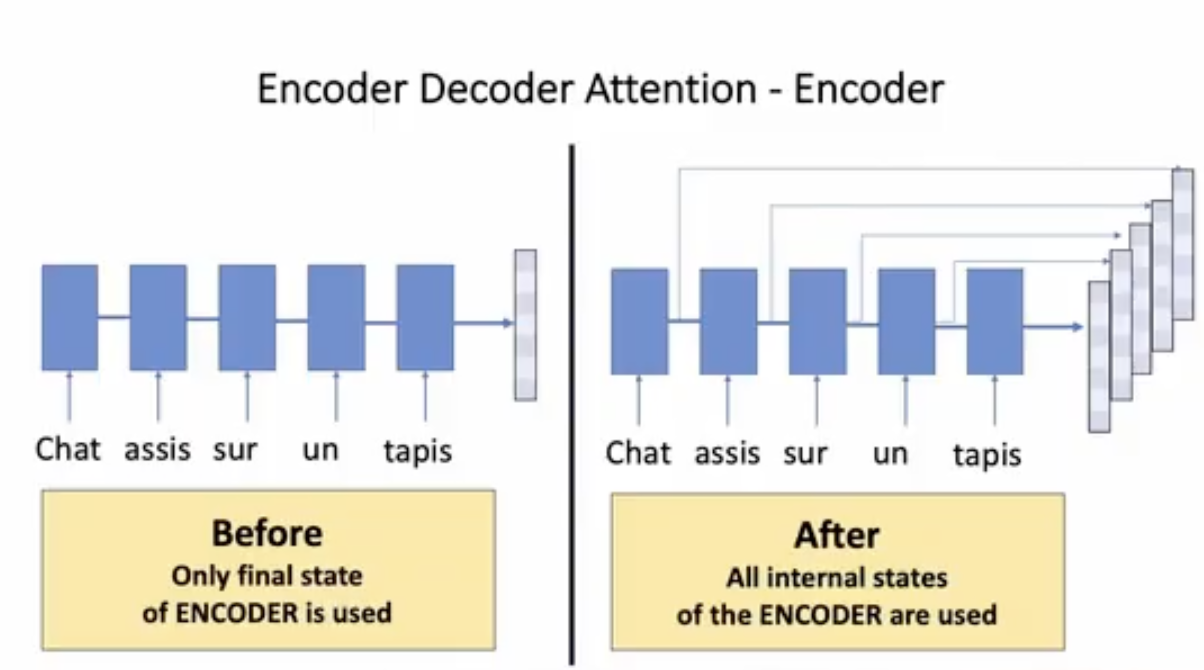
Cơ chế Attention cho phép mô hình decoder có thể tập trung vào các phần quan trọng của chuỗi đầu vào khi thực hiện dự đoán. Thay vì chỉ sử dụng thông tin ngữ cảnh là 1 vector biểu diễn cuối cùng của quá trình encode, mô hình decoder có thể truy cập vào tất cả các từ trong chuỗi đầu vào thông qua trọng số Attention. Điều này giúp cải thiện khả năng xử lý các phụ thuộc xa trong dữ liệu và tăng cường khả năng dịch ngôn ngữ tự nhiên.
Cơ chế Attention đã trở thành một thành phần quan trọng trong nhiều mô hình Seq2Seq sau này và đã được áp dụng rộng rãi trong các ứng dụng dịch máy, tóm tắt văn bản và xử lý ngôn ngữ tự nhiên khác.
#22 - Attention Query, Key và Value Vectors
Khi tiếp cận với Attention chúng ta sẽ bắt gặp 3 khái niệm quan trọng đó là 3 vector Query, Key và Value. Để dễ hình dung hơn chúng ta có thể tưởng tượng bạn đang là một người tìm kiếm thông tin trên google thì Query chính là câu chúng ta truy vấn, ví dụ "Ông Toàn Vi Lốc là ai?". Lúc này Google sẽ đưa chúng ta đến một loạt các bài viết có tiêu đề sắp xếp theo thứ tự liên quan, đây chinh là các Key. Sau khi bạn click vào các đường dẫn đó ví dụ như trên Viblo chẳng hạn thì nội dung trong các bài viết chính là Value mà chúng ta nhận được
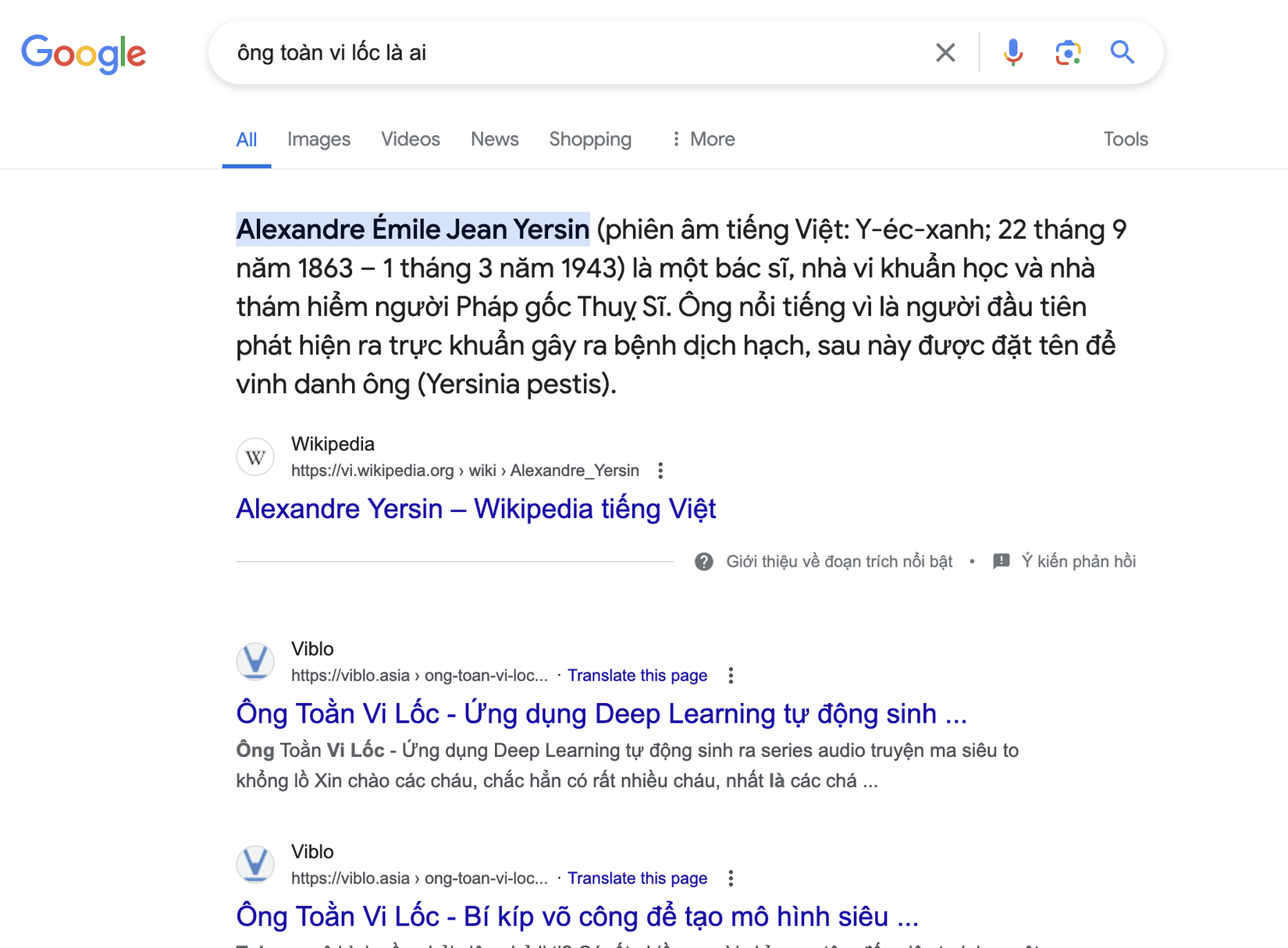
Cụ thể hơn đối với bài toán seq2seq sử dụng cơ chế Attention thì tại mỗi timestep, các hidden state của decoder sẽ đóng vai trò là một Query, các Key là biểu diễn vector của các từ trong chuỗi đầu vào. Nó được sử dụng để tạo ra trọng số Attention, chỉ định mức độ quan trọng của từng từ trong quá trình dự đoán.
#23 - Long sequence struggle trong RNN, LSTM và GRU
Mặc dù cơ chế Attention đã giúp cho quá trình decoder được tốt hơn và giảm vấn đề phụ thuộc xa nhưng về bản chất của mô hình phía sau vẫn dự trên RNN hoặc các biến thể của nó như LSTM hay GRU. Một trong những nhược điểm cố hữu của chúng khi xử lý với các câu dài như:
- Vấn đề hiệu suất tính toán: Với câu dài, số lượng từ và các trọng số Attention cần tính toán tăng lên đáng kể. Điều này có thể tạo ra một lượng tính toán lớn và làm tăng thời gian xử lý. Trong một số trường hợp, việc tính toán Attention cho toàn bộ chuỗi đầu vào có thể trở nên không khả thi với các mô hình cơ sở.
- Vấn đề mất mát thông tin xa: Mặc dù cơ chế Attention giúp tập trung vào các phần quan trọng của chuỗi đầu vào, nhưng trong các câu dài, vẫn có thể xảy ra mất mát thông tin xa. Điều này xảy ra khi các từ ở phần đầu câu không thể truyền thông tin quan trọng đến các từ ở phần cuối câu thông qua các trọng số Attention.
- Vấn đề quá tải bộ nhớ: Với câu dài, việc phải lưu trữ các trọng số Attention và biểu diễn của từng từ trong chuỗi đầu vào có thể gây tăng tải bộ nhớ. Điều này có thể gây khó khăn cho huấn luyện và triển khai mô hình trên các thiết bị có tài nguyên hạn chế.
Chính vì các nhược điểm của chúng nên các kiến trúc hiện đại hơn như Transformer mới được phát minh trong giai đoạn tiếp theo.
Giai đoạn 3: 2017 - 2018: Sự ra đời của Transformer
Có thể nói giai đoạn này thực sự là một bước ngoặt lớn trong lĩnh vực xử lý ngôn ngữ tự nhiên, là giai đoạn đặt nền móng cho tất cả những phát minh kinh thiên động địa như ChatGPT sau này. Và mở đầu giai đoạn này chính là sự ra đời của kiến trúc Transformer
#24 - Attention is all you need - Transformer
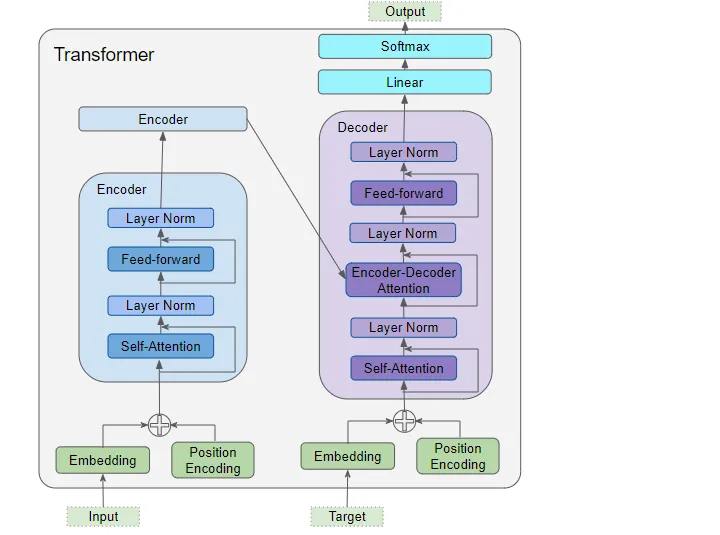
Transformer là kiến trúc được đề xuất trong paper Attention is All You Need nó cũng được base trên kiến trúc encoder - decoder giống như các mô hình seq2seq trước đây nhưng có một đặc điểm khác biệt lớn nhất là nó không sử dụng kiến trúc RNN mà sử dụng cơ chế Attention kết hợp với Positional Encoding để mã hoá các thông tin trong chuỗi đầu vào. Chính vì vậy nên Transformer có những ưu điểm vượt trội như:
- Tính toán song song: Transformer cho phép tính toán các phần tử độc lập trong một chuỗi cùng một lúc, giúp cải thiện hiệu suất tính toán. Điều này đặc biệt hữu ích khi xử lý các chuỗi dữ liệu dài.
- Cơ chế tự chú ý (self-attention): Cơ chế tự chú ý cho phép mô hình tập trung vào các phần quan trọng của chuỗi đầu vào. Điều này giúp mô hình hiểu được mối quan hệ giữa các từ trong câu và cải thiện khả năng xử lý ngôn ngữ tự nhiên.
- Tăng tốc độ tính toán Transformer không sử dụng mạng nơ-ron tái phát, điều này giúp giảm bớt thời gian huấn luyện và tăng tốc độ dự đoán.
- Khả năng học thông tin xa: Với cơ chế tự chú ý, mô hình transformer có khả năng học thông tin xa và hiểu được ngữ cảnh dài hạn trong chuỗi đầu vào. Điều này làm cho nó hiệu quả trong việc xử lý câu dài và các tác vụ xử lý ngôn ngữ tự nhiên khác.
- Dễ dàng mở rộng: Kiến trúc transformer có thể mở rộng để xử lý các chuỗi đầu vào dài hơn bằng cách thêm các lớp transformer mới. Điều này giúp nâng cao khả năng mô hình xử lý dữ liệu phức tạp và đa dạng.
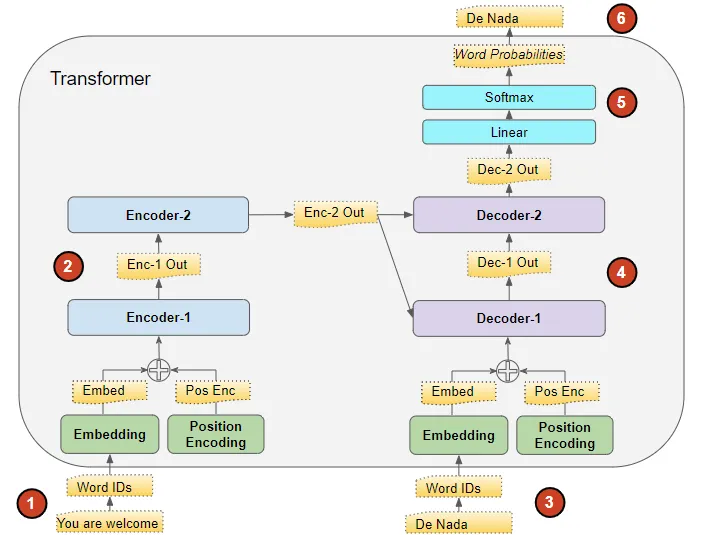
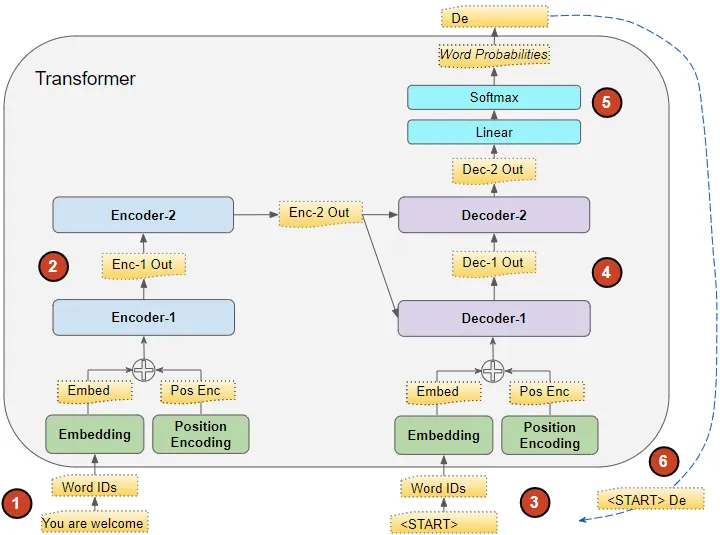
#25 - Transformer - Training steps
Chúng ta cùng tìm hiểu các bước cơ bản để huấn luyện một transformer. Giá sử chúng ta có một bài toán dịch máy thì flow huấn luyện sẽ như sau
-
Bước 1: Chuẩn bị dữ liệu huấn luyện: Dữ liệu huấn luyện bao gồm hai phần: chuỗi nguồn hoặc đầu vào (ví dụ: "You are welcome" trong tiếng Anh, trong một bài toán dịch thuật) và chuỗi đích hoặc đầu ra (ví dụ: "De nada" trong tiếng Tây Ban Nha). Mục tiêu của Transformer là học cách tạo ra chuỗi đích bằng cách sử dụng cả chuỗi đầu vào và đầu ra.
-
Bước 2: Xử lý dữ liệu đầu vào: Chuỗi đầu vào được chuyển đổi thành các Embedding (với Position Encoding) và được đưa vào Bộ mã hóa (Encoder). Bộ mã hóa xử lý chuỗi đầu vào này và tạo ra một biểu diễn mã hóa của chuỗi đầu vào.
-
Bước 3: Xử lý dữ liệu đầu ra: Chuỗi đầu ra được thêm một mã thông báo bắt đầu câu, chuyển đổi thành các Embedding (với Position Encoding) và được đưa vào Bộ giải mã (Decoder). Bộ giải mã xử lý chuỗi này cùng với biểu diễn mã hóa của Bộ mã hóa để tạo ra một biểu diễn mã hóa của chuỗi đầu ra.
-
Bước 4: Tạo ra chuỗi đầu ra: Lớp Đầu ra (Output layer) chuyển đổi biểu diễn mã hóa thành xác suất từ và tạo ra chuỗi đầu ra cuối cùng.
-
Bước 5: Output layer của các khối decoder sẽ được đi qua một lớp Linear và Softmax để tính toán ra xác suất đầu ra của các từ để tạo thành output sentence
-
Bước 6: Tính toán hàm mất mát (Loss function): Hàm mất mát của Transformer so sánh chuỗi đầu ra này với chuỗi đích từ dữ liệu huấn luyện. Hàm mất mát này được sử dụng để tạo ra độ dốc (gradients) để huấn luyện Transformer trong quá trình lan truyền ngược (back-propagation).
#26 - Transformer - Inference steps
Trong quá trình inference thì chúng ta sẽ chỉ có input sentence mà không có target sentence để pass vào trong Decoder. Nhiệm vụ chính của Transfromer là dự đoán output sentence từ input sentence.
Cũng giống như bước inference của mô hình seq2seq tức là chúng ta cũng sẽ chạy qua decoder nhiều lần để sinh output trong mỗi timestep. Chỉ có một khác biệt rằng với Transformer chúng ta sẽ đưa tất cả các từ đã được predict trước đó vào dự đoán thay vì chỉ sử dụng một từ là output của timestep trước đó như trong seq2seq. Chúng ta có thể hình dung các bước cơ bản như sau
-
Bước 1: Chuẩn bị dữ liệu đầu vào: Chuỗi đầu vào được chuyển đổi thành các Embedding (với Position Encoding) và được đưa vào Bộ mã hóa (Encoder). Bộ mã hóa xử lý chuỗi đầu vào này và tạo ra một biểu diễn mã hóa của chuỗi đầu vào.
-
Bước 2: Chuẩn bị dữ liệu đầu ra: Thay vì sử dụng chuỗi đầu ra, chúng ta sử dụng một chuỗi trống chỉ có một token đặc biệt thông báo bắt đầu câu (Ví dụ START_OF_SENTENCE). Chuỗi trống này được chuyển đổi thành các Embedding (với Position Encoding) và được đưa vào Bộ giải mã (Decoder).
-
Bước 3: Xử lý dữ liệu đầu ra: Bộ giải mã xử lý chuỗi này cùng với biểu diễn mã hóa từ Bộ mã hóa (Encoder) để tạo ra một biểu diễn mã hóa của chuỗi đầu ra.
-
Bước 4: Tạo ra chuỗi đầu ra: Lớp Đầu ra (Output layer) chuyển đổi biểu diễn mã hóa thành xác suất từ và tạo ra một chuỗi đầu ra.
-
Bước 5: Dự đoán từ tiếp theo: Chúng ta lấy từ cuối cùng của chuỗi đầu ra làm từ được dự đoán. Từ đó được điền vào vị trí thứ hai của chuỗi đầu vào của Bộ giải mã (Decoder), bao gồm mã thông báo bắt đầu câu và từ đầu tiên.
-
Bước 6: Lặp lại các bước từ 3 đến 5: Quay lại bước 3. Như trước, đưa chuỗi giải mã mới vào mô hình. Sau đó, lấy từ thứ hai của chuỗi đầu ra và thêm vào cuối chuỗi giải mã. Lặp lại quá trình này cho đến khi mô hình dự đoán mã thông báo kết thúc câu.
-
Bước 7: Kết thúc quá trình dự đoán: Quá trình dự đoán kết thúc khi mô hình dự đoán mã thông báo kết thúc câu.
Lưu ý rằng vì chuỗi đầu vào của Bộ mã hóa (Encoder) không thay đổi cho mỗi lần lặp, chúng ta không cần lặp lại các bước 1 và 2 mỗi lần
#27 - Teacher Forcing
Teacher Forcing là kỹ thuật đưa target sequence vào Decoder trong quá trình huấn luyện.
Trong quá trình huấn luyện Transformer chúng ta hoàn toàn có thể thực hiên tương tự như trong quá trình inference tức là chạy qua Decoder nhiều lần, mỗi timestep sẽ lấy input là output của các timestep trước đó. Nhưng điều đó thì không khác gì chúng ta làm việc với các mô hình seq2seq truyền thống cả. Nó sẽ khiến cho mô hình không chỉ training lâu hơn mà còn rất khó hội tụ.
Ưu điểm của Transformer là nó hoàn toàn có thể song song hoá việc dự đoán các từ nên việc truyền toàn bộ target sequence vào trong decoder sẽ giúp cho Transformer dễ dàng huấn luyện hơn và cũng tăng tốc độ xử lý hơn. Giống như việc một giáo viên đang đưa ra các hint và bắt buộc các học sinh phải follow theo các hint của mình, tránh hiện tượng sai càng thêm sai, lầm đường lạc lối.
#28 - Transformer - Input / Output Embedding
Trong Transformer có hai loại embedding mà chúng ta cần quan tâm đó là Input Embedding và Output Embedding, Chuối đầu vào input sequence được pass qua layer input embedding để học giá trị biểu diễn của từng từ trong câu trong khi đó thì output sequence sẽ được đi qua output embedding với việc thêm token đặc biệt START_OF_SENTENCE vào đầu câu và shift giá trị possition embedding sang phải 1 đơn vị.
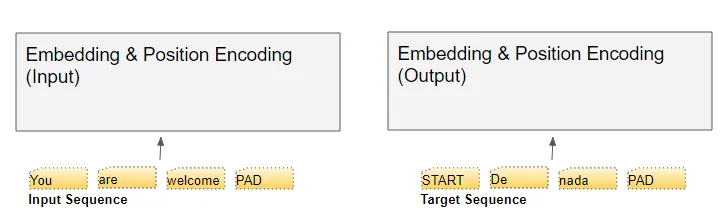
Khi truyền các câu vào trong transformer thì chúng ta sẽ thực hiện việc tokenize chuỗi đầu vào thành các token và đưa vào trong mạng thông qua layer embedding để học được các biểu diễn tốt hơn cho mỗi token
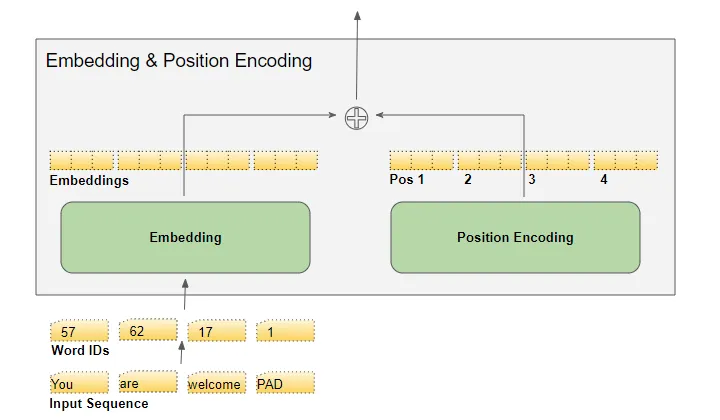
#29 - Transformer - Positional Encoding
Trong Transformer, Positional Encoding (mã hóa vị trí) được sử dụng để đưa thông tin về vị trí của các từ vào kiến trúc mô hình mà không sử dụng thông tin về thứ tự từ trong chuỗi đầu vào. Vì Transformer không sử dụng các lớp Recurrent hoặc Convolutional để duy trì thông tin về vị trí từ, nên cần có một cơ chế để mô hình có thể hiểu vị trí tương đối của các từ trong chuỗi.
Positional Encoding là một ma trận hoặc vector được thêm vào embedding của từ để biểu thị vị trí tương đối của từ trong chuỗi đầu vào. Mỗi chiều của Positional Encoding đại diện cho một thông tin về vị trí, nhưng không chứa thông tin về mối quan hệ giữa các từ cụ thể. Điều này đảm bảo rằng mô hình có thể học được mối quan hệ giữa các từ từ thông tin quan trọng khác như Attention.
Positional Encoding được tính toán theo công thức:
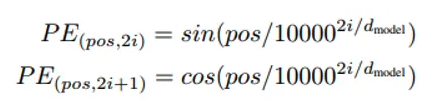
Trong đó, là vị trí của từ trong chuỗi, là chỉ số của chiều trong Positional Encoding, và là kích thước của vector embedding. Công thức này sử dụng các hàm sin và cos để tạo ra các giá trị có sự biến đổi dựa trên vị trí của từ.
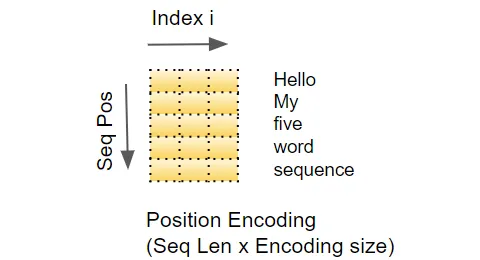
Positional Encoding được cộng vào embedding của từ trước khi đưa vào mô hình Transformer. Quá trình này cho phép mô hình học được vị trí tương đối của các từ trong quá trình huấn luyện và giúp mô hình hiểu vị trí từ trong quá trình dự đoán.
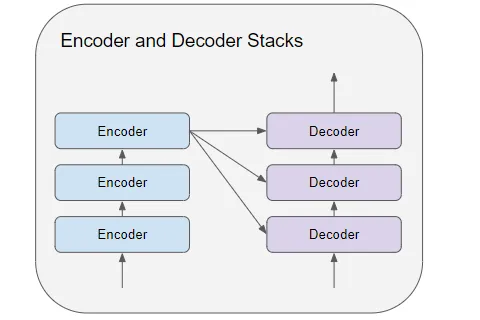
#30 - Transformer - Encoder Stacks
Trong mô hình Transfromer bộ mã hoá bao gồm các khối encoder được xếp chồng lên nhau (ví dụ 6 khối encoder) trong đó input của khối encoder đầu tiên là combine của input embedding và positional encoding. Các khối encoder tiếp theo sẽ nhận input là output của khối encoder trước đó. Khối encoder cuối cùng
Trong mỗi khối encoder nói trên sẽ nhận đầu vào và pass nó qua một layer Multi-head Self Atttention. Self Attention output sẽ được pass qua một mạng Feed Forward để tạo ra output cho các block encoder tiếp theo.
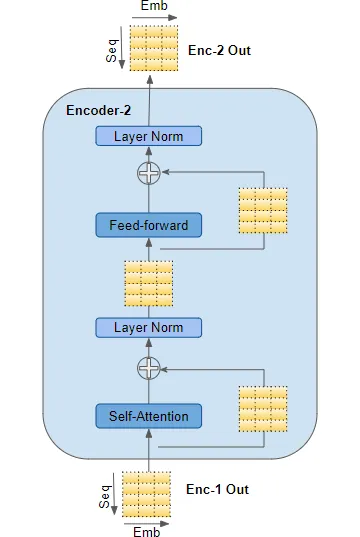
Ở mỗi lớp self-attention và feed-forward sub-layers có một skip connection và một lớp LayerNormalization. Output của khối encoder cuối cùng sẽ được feed vào trong Decoder Stacks
#31 - Transformer - Decoder Stacks
Decoder stacks có kiến trúc khá tương tự như Encoder như có một vài điểm khác biệt
- Cũng giống như Encoder, khối Decoder đầu tiên sẽ nhận đầu vào từ Ouput Embedding và Positional Embedding. Các khối Decoder khác nhận input từ khối decoder trước đó.
- Decoder cũng truyền input của mình thông qua một lớp Multi head attention tuy nhiên lớp này hoạt động khác so với lớp Multi head attention trong encoder. Trong Decoder, với mỗi từ trong output sequence sẽ chỉ được phép attend đến các từ trước đó mà không thể attend để các từ ở tương lai. Điều này thực hiện bằng cơ chế Masking Attention chúng ta sẽ nói ở phần sau.
- Khác với Encoder, Decoder có một tầng Multi-head attention thứ hai, được gọi là tầng Encoder-Decoder attention. Tầng Encoder-Decoder attention hoạt động tương tự như Self-attention, nhưng nó kết hợp hai nguồn đầu vào - tầng Self-attention của khối decoder trước nó và đầu ra của Encoder stack.
Đầu ra từ Self-attention được truyền vào một tầng Feed-forward, sau đó đầu ra của tầng này được truyền lên tầng Decoder tiếp theo.
Mỗi tầng con này, Self-attention, Encoder-Decoder attention và Feed-forward, đều có một kết nối bỏ qua (skip-connection) xung quanh chúng, tiếp theo là Layer-Normalization.
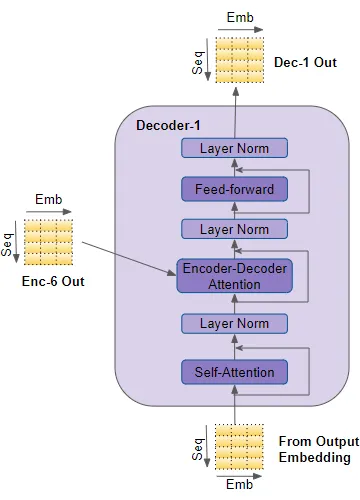
#32 - Transformer - Self Attention Encoder / Decoder
Như đã nói ở phần trên thì các lớp Attention chính là linh hồn của mạng Transformer. Đối với lớp Encoder thì các từ trong câu input sẽ được học để attention với chính nó. Tương tự đối với decoder thì self attention sẽ được chú ý với chính output sequence.
Đối với self attetnion trong encoder và decoder thì input embedidng và output embedidng sẽ đồng thời sử dụng cho 3 ma trận key, query và value.
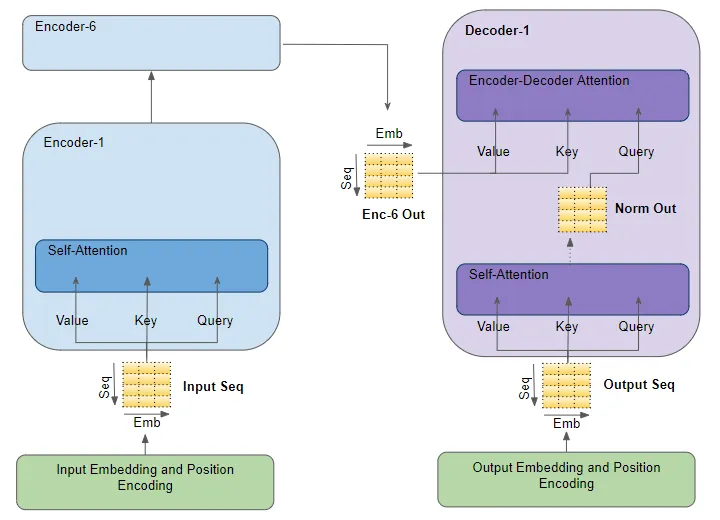
#33 - Transformer - Encoder Decoder Attention
Encoder Decoder Attention lại có chút khác biệt, output đầu ra của khối encoder sẽ được gán cho ma trận key và value trong khi Query là output của khối Decoder Selft Attention. Mục đích của nó là biểu diễn attention scores của target sequence và input sequence
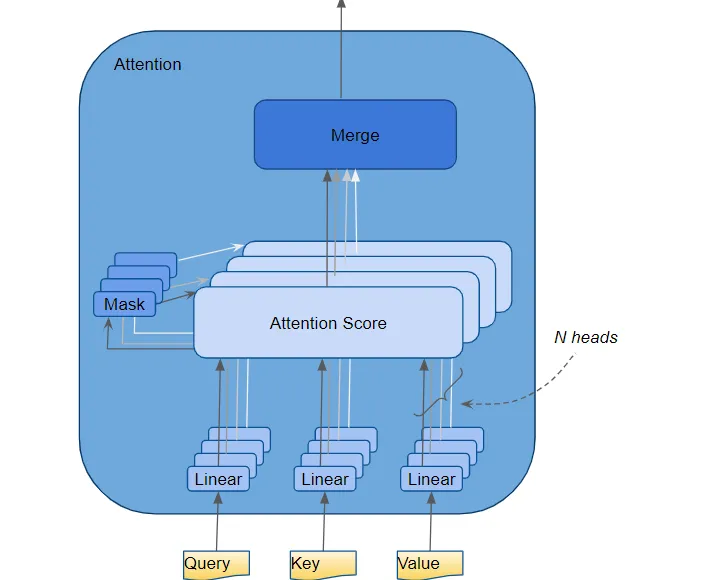
#34 - Transformer - Multi-head Attention
Việc chia nhỏ dữ liệu input đầu vào ra thành nhiều thành phần khác nhau và sử dụng cơ chế Attention để học mối tương quan giữa các thành phần đó một cách độc lập được gọi là Multi head attention. Bằng cách này mô hình có thể capture được nhiều khía cạnh khác nhau trong câu đầu vào. Đây là một cơ chế rất quan trọng và có thể nói là linh hồn của Transformer. Nó giúp cho mô hình Transformer có khả năng biểu diễn được nhiều mối liên hệ hơn trong thông tin input
Kết luận
Thui viết tạm đến đây thui cũng dài quá rồi. Hẹn gặp lại các bạn vào phần 2 nhé
All rights reserved
