Xây dựng chatbot Messenger cập nhật thời khóa biểu cho sinh viên (Phần 4) - Xử lí logic chatbot khi được hỏi các thông tin về học phần
Bài đăng này đã không được cập nhật trong 6 năm
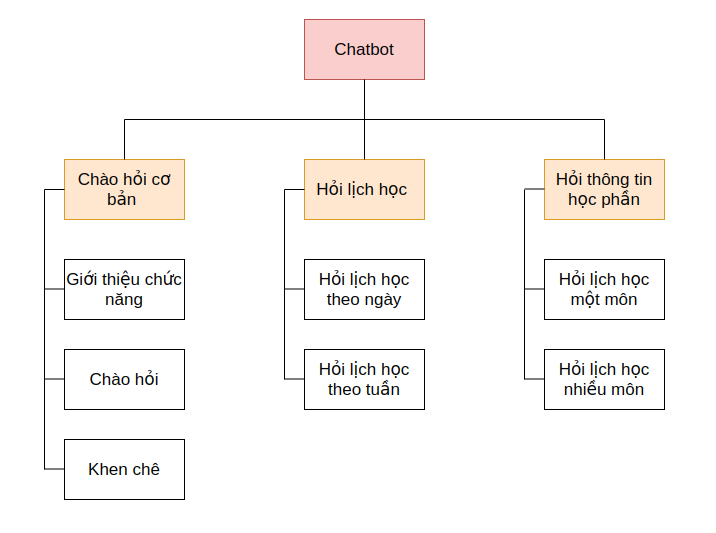
1. Đặt vấn đề
Trong bài viết trước Xây dựng chatbot Messenger cập nhật thời khóa biểu cho sinh viên (Phần 3) - Xử lí logic chatbot khi được hỏi về thông tin lịch học, chúng ta đã xây dựng thêm một tính năng của chatbot về xử lí thông tin khi được hỏi về lịch học, trong bài viết này, mình sẽ trình bày nốt chức năng chính tiếp theo: Xử lí thông tin khi có user hỏi chatbot về học phần
Ví dụ:
Bot ơi, cho mình hỏi, học phần "Các phương pháp tối ưu" học vào lúc nào đấy???
Các vấn đề cần xử lí ở đây là gì?? Có gì cần chú ý gì đặc biệt ở chức năng này không?? Cần bổ sung thêm những kiến thức về gì??
Hãy bắt đầu đọc bài viết thôi nào!
-
Luồng hội thoại
Vẫn theo bố cục các bài viết trước, mình sẽ trình bày ý tưởng cũng như luồng hội thoại xử lí của bot
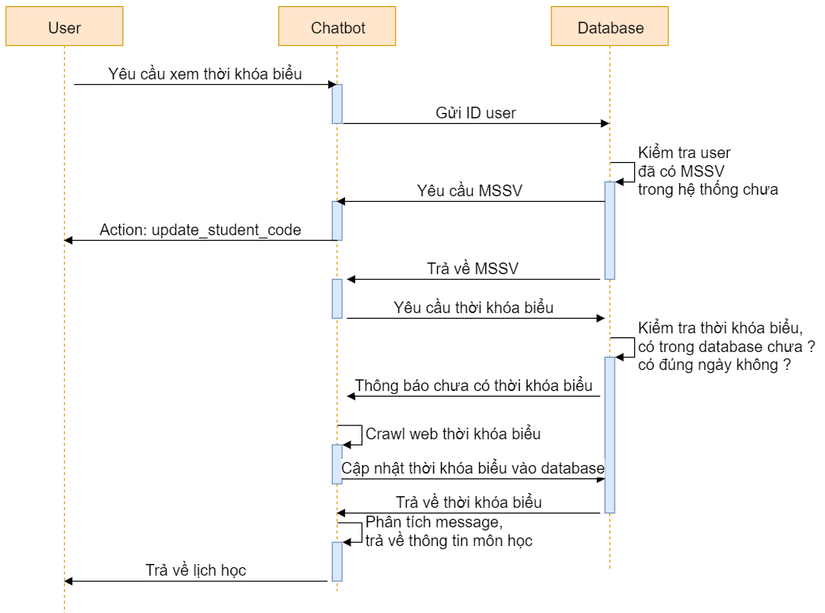
Phía trên là biểu đồ luồng hoạt động, khá tương tự với chức năng trước, bao gồm các bước sau:
-
Đầu tiên, khi một người dùng (sinh viên) bất kì muốn hỏi về thông tin một học phần, chatbot sẽ xác định được intent của câu, và đi vào action tương ứng
-
Ở đây, chatbot sẽ có được user_id của người hỏi, tiến hành kiểm tra xem ở database đã có lưu MSSV của user này hay chưa
- Nếu trong database đã có MSSV của người đó, việc tiếp đến là dùng MSSV để search xem trong database lưu thông tin thời khóa biểu đã có thông tin về thời khóa biểu của MSSV này không
- Nếu có, chúng ta sẽ lấy được ra thời khóa biểu. Việc tiếp đến là phân tích message để xác định tên các học phần mà user đang muốn nhắc đến, và show ra thông tin chi tiết
- Nếu không, chúng ta sẽ lại thực hiện một request đến trang web của trường để lấy thời khóa biểu tương ứng với MSSV của user, sau đó lưu lại vào database. Lại tiếp tục lấy từ thời khóa biểu ra, xử lí tin nhắn lấy thông tin về tên học phần và trả ra message
- Nếu chưa, chúng ta sẽ đưa user sang một action : "action_ask_studentcode" để cập nhật MSSV vào database
- Nếu trong database đã có MSSV của người đó, việc tiếp đến là dùng MSSV để search xem trong database lưu thông tin thời khóa biểu đã có thông tin về thời khóa biểu của MSSV này không
-
Done! Kết thúc
-
Các vấn đề cần xử lí
Như các bạn có thể thấy, luồng hội thoại khá tương tự như chức năng trước đó, vậy nên, hầu hết các vấn đề trong luồng hội thoại đã được xử lí hết rồi 
Thứ khác nhau duy nhất giữa 2 chức năng này là: một chức năng hỏi về thời gian, một chức năng hỏi về tên học phần. Vậy nên, vấn đề đặt ra ở đây là, làm sao để lấy ra được tên của học phần mà user đang nhắc đến ???
Vấn đề này thì mình chắc chắn là phải tự xây dựng hàm riêng rồi, vì vấn đề custom sao cho phù hợp với nội dung chatbot.
2 hướng tiếp cận sau đây sẽ được thực hiện đồng thời:
-
Do lượng thông tin chứa trong thời khóa biểu là khá nhỏ, thế nên, cách đơn giản nhất là: Lấy ra tất cả các tên học phần, sau đó, kiểm tra xem có tên học phần nào xuất hiện trong message hay không? Vậy là chúng ta xử lí được rồi
-
Một vấn đề khác nữa cần chú ý là: Việc kiểm tra tên học phần có trong 1 message cần yêu cầu user viết tên học phần đấy hoàn toàn đúng (kể cả vị trí đặt dấu câu), điều này không phải luôn xảy ra được. Sẽ tồn tại các trường hợp user nhắn vội khiến sai lỗi chính tả, vô tình thêm nhầm dấu câu vào tên học phần, sử dụng tên học phần viết tắt, viết thiếu từ, .... Giải quyết như nào đây???
Một đề xuất cho vấn đề này là liên quan đến String Metric, chúng ta sẽ sử dụng Regex để bắt ra các cụm từ có vẻ là tên học phần, sau đó sử dụng tính toán độ tương đồng của cụm từ với từng tên học phần được lấy ra từ thời khóa biểu. Tên học phần có độ tương đồng cao nhất và cao hơn ngưỡng mà chúng ta đặt ra, sẽ được xác định là học phần mà user muốn hỏi.
Done, ý tưởng là vậy. Bắt tay vào làm nào!
2. Xây dựng hàm tính độ tương đồng giữa các cụm từ
Trước hết, chúng ta sễ điểm qua một vài hàm tính độ tương đồng của chuỗi dưới đây, sau đó lựa chọn phương án hiệu quả nhất cho bài toán của mình
-
Cosine similatity
Cosine similarity tính toán độ tương đồng của 2 câu dựa trên khoảng cách vector đại diện cho 2 câu đó. Do đó, trước khi tính toán độ tương đồng, ta tiến hành embedding các câu lại bằng các thuật toán thông dụng như Bag of Word, TF-IDF, Word2Vec, .... Sau đó áp dụng công thức sau
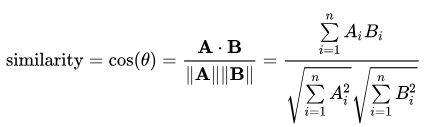
Độ similarity của hai vector là 1 số trong đoạn [-1, 1].
-
Giá trị bằng 1 thể hiện hai vector hoàn toàn similar nhau. Hàm số cos của một góc bằng 1 nghĩa là góc giữa hai vector bằng 0, tức một vector bằng tích của một số dương với vector còn lại.
-
Giá trị cos bằng -1 thể hiện hai vector này hoàn toàn trái ngược nhau. Điều này cũng tức là 2 vector hoàn toàn trái ngược nhau
-
Levenshtein
Khoảng cách Levenshtein (Levenshtein Distance) được đo bằng số lần tối thiểu cần thiết để chỉnh sửa một ký tự sao cho thay đổi từ này thành từ khác, Ví dụ:
- Câu 1: "Tôi là sinh viên"
- Câu 2: "Tôi là học sinh"
=> Ở đây, để biến câu 1 thành câu 2, chúng ta cần thay đối ít nhất 4 kí tự, vậy khoảng cách Levenshtein ở đây là 4.
Do khoảng cách Levenshtein là độ sai lệch nên kết quả sẽ luôn là một số nguyên dương và nhạy cảm với độ dài chuỗi.
Đó là về khoảng cách, còn về độ tương đồng, chúng ta sẽ quy về xét giá trị của
với d là số lượng từ trong câu, L là khoảng cách Levenshtein
. Khi đó, kết quả đánh giá sẽ là phần trăm và dễ để đưa ra các đánh giá hơn
Một vài metric khác các bạn có thể xem xét như
-
Hamming Distance: Đo bằng số lượng ký tự khác nhau trong hai chuỗi có độ dài bằng nhau
-
Smith–Waterman: Một nhóm các thuật toán để tính toán độ tương tự của các chuỗi con
-
Sørensen–Dice Coefficient: Một thuật toán tính toán độ tương tự dựa trên các hệ số tương quan của các cặp ký tự liền kề.
-
...
-
Lựa chọn metric
Ở đây, chúng ta sẽ lựa chọn Levenshtein với ngưỡng là 0.5
Tiến hành nào
Đầu tiên, loại bỏ dấu câu, đưa chuỗi là chữ thường
def clean_string(text):
stopwords = ['với', 'được', 'nữa', 'nhỉ', 'nha', 'nhá', 'luôn']
text = ''.join([word for word in text if word not in string.punctuation])
text = text.lower()
text = ' '.join([word for word in text.split() if word not in stopwords])
return text
Tiếp theo, xây dựng hàm tính khoảng cách Levenshtein
def levenshtein_distance(first, second):
first = clean_string(first)
second = clean_string(second)
first_len = len(first)
second_len = len(second)
if first_len == 0 or second_len == 0:
raise ValueError("Inputs must not have length 0")
matrix = np.zeros((first_len+1, second_len+1), dtype=np.int)
matrix[:,0] = range(first_len+1)
matrix[0,:] = range(second_len+1)
for i, first_char in enumerate(first, start=1):
for j, second_char in enumerate(second, start=1):
if first_char == second_char:
cost = 0
else:
cost = 1
min_cost = min(
matrix[i-1, j] + 1,
matrix[i, j-1] + 1,
matrix[i-1, j-1] + cost
)
matrix[i, j] = min_cost
return matrix[first_len, second_len]
Cuối cùng tính toán độ tương đồng
def get_similarity(first, second):
changes = levenshtein_distance(first, second)
min_total_chars = min(len(first), len(second))
return (min_total_chars - changes)/min_total_chars
Tổng kết lại, ta sẽ xác định được tên học phần trong câu khi kết hợp cả matching với database và chỉnh lỗi
def get_list_subject(self, text, schedule):
list_subject = set()
# part 1: check subject_name in message
for subject in schedule["subject_schedule"].keys():
if subject in text:
list_subject.add(subject)
# part 2: check regex subject is similarity with subject_name
list_regex = re.findall(r'\"(.*?)\"', text)
best_similarity = 0.5
for regex in list_regex:
best = None
for subject in schedule["subject_schedule"].keys():
similar = similarity(regex, subject)
if similar > best_similarity:
best_similarity = similar
best = subject
if best:
list_subject.add(best)
return list(list_subject)
3. Xây dựng nlu, core cho action hỏi đáp về học phần
Xây dựng NLU và Core cho rasa, ta tiến hành bổ sung
-
NLU
Bổ sung vào file nlu.md
## intent: ask_a_subject
- mình muốn xem lịch của môt môn được không?
- cho xem thông tin môn học với
- môn Tối ưu Tổ hợp học hôm nào đấy?
- xin lịch học cụ thể một môn
- xin thông tin môn học
- môn học
- học phần
- học phần Xác suất thống kê học những hôm nào ấy nhỉ
- chi tiết môn học
- môn này học bao giờ thế ?
- xin lịch học môn Toán kinh tế
- lịch học
-
Core
Bố sung file stories.md
## ask_a_subject
* ask_a_subject
- action_show_subject_information
Bố sung file domain.yml
intents:
- ask_a_subject
actions:
- action_show_subject_information
Bố sung file actions.py
class ActionShowSubject(Action):
def name(self) -> Text:
return "action_show_subject"
def run(self, dispatcher: CollectingDispatcher,
tracker: Tracker,
domain: Dict[Text, Any]) -> List[Dict[Text, Any]]:
sender_id = [x["sender_id"] for x in tracker.events if x["event"] == "user"][-1]
message = tracker.latest_message.get('text')
student_code = PreProcess().get_student_code(sender_id=sender_id)
if student_code:
schedule = PreProcess().get_schedule_json(student_code=student_code)
if schedule:
list_subject = Subject(student_code=student_code).get_list_subject(text=message, schedule=schedule)
if list_subject:
response = ""
for subject in list_subject:
response += Subject(student_code=student_code).get_subject_info(subject_name=subject, schedule=schedule)
return dispatcher.utter_message(response)
return dispatcher.utter_message(message_no_subject_name)
return dispatcher.utter_message(message_no_schedule)
return FollowupAction("action_ask_studentcode")
4. Tổng kết
Đó là toàn bộ những gì mình muốn chia sẻ trong chuỗi bài viết này. Hi vọng, qua đây, có thể giúp các bạn lên các kế hoạch, thiết kế các hệ thống một cách tốt hơn, cũng như giới thiệu với các bạn một số thứ mới mẻ.
Về cơ bản, chatbot đã hoàn thành (tuy vẫn sơ sài nhưng đã đáp ứng được các yêu cầu chính, và hoàn toàn có thể mở rộng tiếp). Một phần cũng khá đáng chú ý nữa là việc deploy chatbot với heroku. Đây là một công việc khá khó, có thể liệt kê 1 số vấn đề như sau
- Rasa chỉ hỗ trợ deploy thông qua docker --> Các bạn cần có kiến thức tương đối vững về docker để đóng gói lại code của mình
- Vì Rasa action chạy trên 1 cổng 5005 riêng, thế nên deploy Rasa và Rasa actions là hoàn toàn riêng rẽ. Các bạn cần thực hiện cả 2 việc này
- Có khá nhiều vấn đề xảy ra khi deploy lên Heroku nên hiện tại mình cũng chưa thể làm được =((
Hi vọng trong thời gian sắp tới mình có thể làm được và chia sẻ với các bạn sau
Cảm ơn các bạn đã theo dõi hết chuỗi bài viết này. Hi vọng nó giúp ích một phần cho các bạn
See ya!
All rights reserved
