
Nhận diện text trong hình ảnh với CRNN+CTC
Bài đăng này đã không được cập nhật trong 5 năm
I.Introduction
Xin chào các bạn, trong các bài viết trước viết trước mình có chia sẻ với các bạn về YOLOV5 - Detect lúa mì chỉ trong vài phút cũng như các bài viết chia sẻ về thuật toán detection như FasterRCNN hay YOLOV3 thì trong bài viết hôm nay mình sẽ chia sẻ tới các bạn về bài toán text recognition hay nhận dạng văn bản. Ngoài ra các bạn có thể tham khảo thêm bài viết Alignment ảnh chứng minh thư với PyTorch. Hướng dẫn dễ như ăn kẹo của tác giả Phạm Văn Toàn hay Thiết kế module OCR cho bài toán nhận diện chữ cổ Nhật Bản - Building OCR module for Kuzushiji recognition của tác giả Phan Huy Hoàng , các bạn chỉ cần google search theo keywork OCR hay text detection, text recognition kèm theo viblo sẽ ra được rất nhiều bài viết hay và tâm huyết đến từ các tác giả.
II. Optical Character Recognition Pipeline
Trước tiên chúng ta sẽ cùng trao đổi về một pipeline OCR sử dụng deep learning và computer vision. Optical character recognition là phương pháp chuyển đổi các tài liệu in, viết tay hay những text trong hình ảnh thành các văn bản được số hoá. 
Những ứng dụng về OCR có thể kể đến như sau:
- Nhận dạng biển số từ các loại xe.
- Nhập dữ liệu tự động từ tài liệu.
- Đọc đồng hồ đo điện.
- Đọc hộ chiếu và các chứng minh thư.
Dưới đây là 1 pipeline về OCR:

1. Creating Data Set: Đối với bất kì bài toán deep learning nào cũng cần một lượng dữ liệu phong phú , trong bài toán OCR thì chúng ta cần hình ảnh và văn bản tương ứng của chúng
2. Image Preprocessing: Hình ảnh đầu vào cho bài toán OCR có thể từ nhiều nguồn khác nhau. Đôi khi chúng ta cần số hóa một tài liệu được quét, đôi khi chúng ta cần trích xuất văn bản từ các hình ảnh cảnh tự nhiên như biển báo đường phố, hình ảnh từ các cửa hàng, v.v. Những hình ảnh này có thể được xoay, có thể chứa nhiễu, chèn và các vấn đề khác có thể ảnh hưởng đến hệ thống OCR. Để làm cho hệ thống OCR trở nên chính xác hơn, chúng ta cần thực hiện một số xử lý trước hình ảnh có thể được thực hiện bằng OpenCV hoặc bất kỳ thư viện xử lý hình ảnh nào khác.
3. Text segmentation: Hình ảnh đầu vào cho OCR thường chứa rất nhiều từ và dòng, chúng ta cần chuyển các phân đoạn từ hình ảnh này làm đầu vào cho OCR. Các phân đoạn này có thể là từng từ, từng dòng hoặc từng ký tự. Có nhiều thuật toán khác nhau có thể được sử dụng để phân đoạn văn bản như EAST, CTPN, Faster R-CNN, v.v. Chúng ta có thể thay vì segmentation text thì có thể dùng detect text.
4. Optical Character Recognition: Sau quá trình segmentation hoặc detection thì chúng ta sẽ pass đầu ra dự đoán box text vào mô hình text recognition nhận dạng nội dung text.
5. Restructuring: Sau quá trình segmentation hoặc detection chúng ta cần restructuring các phần nôi dung đó vào tương ứng với các vị trí ban đầu
6. Natural Language processing: Ví dụ theo yêu cầu của bài toán, chúng ta cần áp dụng các mô hình NLP như RNN hoặc regular expressions trong các văn bản có cấu trúc. Giả sử chúng ta xử lý một tài liệu và cần tìm ra tên và tuổi của một người trong tài liệu đó. Sau đó, chúng ta sẽ sử dụng dữ liệu được gắn thẻ cho tên và tuổi để train mô hình RNN (có thể là một mô hình nhận dạng thực thể tên).
III. Text recognition
Với sự phát triển của các mô hình deep learning thì optical character recognition (OCR) ngày càng chính xác và tốc độ. Về cơ bản thì có hai thuật toán deep learning nổi tiếng cho bài toán nhận dạng văn bản, một là convolutional recurrent neural network (CRNN) với CTC loss và một là attention OCR. Trong bài viết này mình sẽ tập trung nói về phương pháp convolutional recurrent neural network (CRNN) với CTC loss, tuy nhiên mình sẽ giới thiệu qua về attention OCR để giúp các bạn dễ hình dung hơn. Như các bạn có thể biết thì trước đây các model attention sinh ra để giải quyết các vấn đề về liên kết và dịch thuật trông các thuật toán neural machine translation . Attention chủ yếu tập trung vào các phần quan trọng liên quan của đầu vào để dự đoán các phần của đầu ra. Do bài toán optical character recognition (OCR) cũng là vấn đề nhận dạng chuỗi nên ta attention model có thể được sử dụng ở đây. Attention-based OCR models bao gồm các phần chính như sau: convolution neural network, recurrent neural network, and a novel attention mechanism. Chúng ta cùng xem hình dưới đây:

Như kiến trúc ở trên ta có thể thấy được một vài CNN layers được áp dụng cho hình ảnh đầu vào để trích xuất đặc trưng. Sau đó RNN encoder layer được thêm vào để xử lý những đặc trưng được mã hóa (encoder) từ hình ảnh. Cuối cùng visual attention model được thêm vào như một bộ decoder để xử lý kết quả đầu ra cuối cùng.
IV. Convolutional Recurrent Neural Network with CTC
Nhận dạng kí tự (OCR) về cơ bản là bài toán nhận dạng chuỗi dựa trên hình ảnh đầu vào và đối với vấn đề nhận dạng trình tự thì mạng nơ ron phù hợp nhất có lẽ là recurrent neural networks(RNN) trong khi đó đối với các vấn đề về hình ảnh thì mạng nơ ron phù hợp nhất là convolution neural networks(CNN). Để đối phó với các vấn đề về OCR thì tác giả đã nghĩ ra giải pháp kết hợp CNN và RNN.

Từ trên xuống ta có thể thấy kiến trúc có thể được chia thành các phần chính như sau:
1.Convolution layers: Với các hình ảnh đầu vào được cho qua lớp CNN từ đó giúp trích xuất những đặc trưng, đầu ra của CNN layer là một feature map.
2. Recurrent layers: Đầu ra từ lớp CNN được cung cấp như những chuỗi vào recurrent layers. Recurent layers bao gồm deep bidirectional LSTM (long short term memory) networks. RNN có khả năng nắm bắt thông tin ngữ cảnh rất tốt trong một chuỗi. Đầu ra từ lớp RNN sẽ bao gồm các giá trị xác suất cho mỗi nhãn tương ứng với mỗi đặc điểm đầu vào (input feature). Giả sử đầu vào cho recurrent layer có kích thước là (batch_size, 250) và tổng số labels là 53 thì đầu ra của recurrent layer sẽ có kích thước (batch_size, 250, 53).
3. Transcription layer: Thành phần cuối cùng là transcription layer. Nó sử dụng Connectionist temporal classification(CTC) để dự đoán đầu ra cho từng time step. Chúng ta sẽ cùng lấy ra một ví dụ để hiểu rõ hơn về cách sử dụng CTC loss. 
Đầu ra của RNN sẽ là xác suất của văn bản (từng kí tự). Gỉa sử ta có hình ảnh đầu vào với text là "good", đầu ra của RNN là [‘g’, ‘g’,’o’,’o’,’o’,’d’,’d’,’d’] . Để dự đoán text đầu ra chúng ta có thể gộp những kí tự giống nhau vào thì từ đso kêt quả dự đoán sẽ là "god" và kết quả thì hoàn toàn sai so với text đầu vào. CTC giải quyết vấn đề này bằng cách thêm kí tự khoảng trắng giữa những kí tự giống nhau liên tục. Và khi decode thì CTC sẽ thoát khỏi những kí tự khoảng trắng và cho kết quả đầu ra là "good".
CTC Loss
Để training mạng nơ-ron chúng ta cần tính toán một hàm loss functions. CTC loss khác so với các hàm loss trong các mô hình deep learning. Để tính toán CTC loss chúng ta cần thực hiện theo những bước sau:
- Trước tiên chúng ta cần tính tổng tất cả các xác suất có thể xảy ra khi căn chỉnh của text có trong hình ảnh.
- Sau đó lấy logarit âm để tính toán hàm loss này.
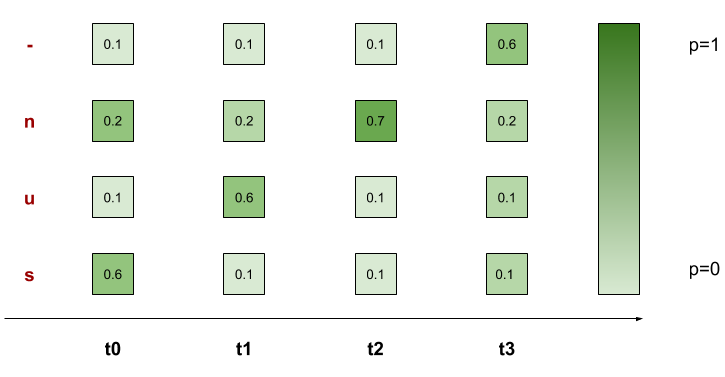
Giả sử chúng ta có đầu vào text lafc "cat" trong hình ảnh và có đầu vào là 5 time step. Chúng ta cần tính tổng xác suất 5 đầu vào time step của "cat".
Một ví dụ cụ thể hơn các bạn có thể nhìn thấy dưới đây:
![]()
Với từ sun, ta có tổng 7 alignments đúng ở trên. Do đó theo model, xác suất từ sun xuất hiện là:
p('sun') = p('-sun') + p('s-un') + p('su-n') + p('sun-') + p('ssun') + p('suun') + p('sunn') = 0.2186
Hàm loss của chúng ta sẽ là 1 - p(‘sun’)
CTC decoder
Trong quá trình test, dự đoán nội dung text từ hình ảnh đầu vào, chúng ta cần decode từ RNN outputs. CTC thực hiện theo hai bước sau đây:
1.Lấy kí tự với xác suất cao nhất với từng time step.
2.Xóa đi những kí tự trùng nhau và những kí tự khoảng trắng từ đầu ra.
V. Implement CRNN model với keras
Mô hình bao gồm có 3 phần:
- Convolutional neural network để trích suất đặc trưng từ hình ảnh đầu vào
- Recurrent neural network để dự đoán đầu ra tuần tự cho từng time step
- CTC loss function
KIến trúc mô hình dưới đây:![]()

1 . Đầu vào với hình ảnh có kích thước height 32 và width 128.
2. Chúng ta sử dụng tất cả 7 conv2d với 6 kernel_size (3,3) và cái cuối cùng là (2,2) với số lượng filters tăng từ 64 tới 512 layers.
3. Hai max-pooling layers được add vào với kích thước (2,2) và 2 max pooling layers với kích thước (2,1) được add vào để trích xuất đặc trưng với các text dài.
4. Chúng ta có sử dụng thêm batch normalization layers sau convolutional thứ 5 và 6 để mục đích tăng tốc độ training.
5. Sau đó sử dụng 1 hàm lambda để ép đầu ra từ conv tương thích với đầu vào LSTM.
6. Sử dụng 2 Bidirectional LSTM layers với mỗi layer là 128 units. RNN layer có đầu ra với kích thước (batch_size, 31, 63). Số 63 ở đây là tổng các lớp đầu ra bao gồm cả kí tự trống.
# input with shape of height=32 and width=128
inputs = Input(shape=(32,128,1))
# convolution layer with kernel size (3,3)
conv_1 = Conv2D(64, (3,3), activation = 'relu', padding='same')(inputs)
# poolig layer with kernel size (2,2)
pool_1 = MaxPool2D(pool_size=(2, 2), strides=2)(conv_1)
conv_2 = Conv2D(128, (3,3), activation = 'relu', padding='same')(pool_1)
pool_2 = MaxPool2D(pool_size=(2, 2), strides=2)(conv_2)
conv_3 = Conv2D(256, (3,3), activation = 'relu', padding='same')(pool_2)
conv_4 = Conv2D(256, (3,3), activation = 'relu', padding='same')(conv_3)
# poolig layer with kernel size (2,1)
pool_4 = MaxPool2D(pool_size=(2, 1))(conv_4)
conv_5 = Conv2D(512, (3,3), activation = 'relu', padding='same')(pool_4)
# Batch normalization layer
batch_norm_5 = BatchNormalization()(conv_5)
conv_6 = Conv2D(512, (3,3), activation = 'relu', padding='same')(batch_norm_5)
batch_norm_6 = BatchNormalization()(conv_6)
pool_6 = MaxPool2D(pool_size=(2, 1))(batch_norm_6)
conv_7 = Conv2D(512, (2,2), activation = 'relu')(pool_6)
squeezed = Lambda(lambda x: K.squeeze(x, 1))(conv_7)
# bidirectional LSTM layers with units=128
blstm_1 = Bidirectional(LSTM(128, return_sequences=True, dropout = 0.2))(squeezed)
blstm_2 = Bidirectional(LSTM(128, return_sequences=True, dropout = 0.2))(blstm_1)
outputs = Dense(len(char_list)+1, activation = 'softmax')(blstm_2)
act_model = Model(inputs, outputs)
CTC loss
CTC loss yêu cầu 4 tham số để tính toán đó là: predicted outputs, ground truth labels, input sequence length to LSTM and ground truth label length. Sau khi chúng ta custom được hàm loss thì sẽ pass nó vào trong mô hình trên.
labels = Input(name='the_labels', shape=[max_label_len], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
def ctc_lambda_func(args):
y_pred, labels, input_length, label_length = args
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
loss_out = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([outputs, labels, input_length, label_length])
#model to be used at training time
model = Model(inputs=[inputs, labels, input_length, label_length], outputs=loss_out)
Dataset
Các bạn có thể sử dụng bộ dữ liệu Visual Geometry Group. Tổng số lượng hình ảnh là 10GB, có 135000hình ảnh cho việc training còn 15000 ảnh cho valiation.
wget https://www.robots.ox.ac.uk/~vgg/data/text/mjsynth.tar.gz
tar -xvzf mjsynth.tar.gz
Preprocessing
Với dữ liệu là ảnh đầu vào chúng ta cần làm một vài bước xử lý trước khi cho vào mô hình :
- Đọc hình ảnh đầu vào và chuyển sang gray-scale
- Tạo mỗi hình ảnh có kích thước (128,32) bằng cách thêm các padding
- Mở rộng thêm chiều của hình ảnh thành (128,32,1) để cho phù hợp với đầu vào của mô hình
- Normalize các giá trị pixel bằng cách chia cho 255
# char_list: 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
char_list = string.ascii_letters+string.digits
def encode_to_labels(txt):
# encoding each output word into digits
dig_lst = []
for index, char in enumerate(txt):
try:
dig_lst.append(char_list.index(char))
except:
print(char)
return dig_lst
path = '/mnt/ramdisk/max/90kDICT32px'
# lists for training dataset
training_img = []
training_txt = []
train_input_length = []
train_label_length = []
orig_txt = []
#lists for validation dataset
valid_img = []
valid_txt = []
valid_input_length = []
valid_label_length = []
valid_orig_txt = []
max_label_len = 0
i =1
flag = 0
for root, dirnames, filenames in os.walk(path):
for f_name in fnmatch.filter(filenames, '*.jpg'):
# read input image and convert into gray scale image
img = cv2.cvtColor(cv2.imread(os.path.join(root, f_name)), cv2.COLOR_BGR2GRAY)
# convert each image of shape (32, 128, 1)
w, h = img.shape
if h > 128 or w > 32:
continue
if w < 32:
add_zeros = np.ones((32-w, h))*255
img = np.concatenate((img, add_zeros))
if h < 128:
add_zeros = np.ones((32, 128-h))*255
img = np.concatenate((img, add_zeros), axis=1)
img = np.expand_dims(img , axis = 2)
# Normalize each image
img = img/255.
txt = f_name.split('_')[1]
if len(txt) > max_label_len:
max_label_len = len(txt)
# split the 150000 data into validation and training dataset is 10% and 90%
if i%10 == 0:
valid_orig_txt.append(txt)
valid_label_length.append(len(txt))
valid_input_length.append(31)
valid_img.append(img)
valid_txt.append(encode_to_labels(txt))
else:
orig_txt.append(txt)
train_label_length.append(len(txt))
train_input_length.append(31)
training_img.append(img)
training_txt.append(encode_to_labels(txt))
# break the loop if total data is 150000
if i == 150000:
flag = 1
break
i+=1
if flag == 1:
break
train_padded_txt = pad_sequences(training_txt, maxlen=max_label_len, padding='post', value = len(char_list))
valid_padded_txt = pad_sequences(valid_txt, maxlen=max_label_len, padding='post', value = len(char_list))
- Mã hóa từng ký tự của một từ thành một số giá trị bằng cách tạo một hàm (như 'a': 0, 'b': 1 …… .. 'z': 26, v.v.). Giả sử chúng ta đang có từ 'abab' thì nhãn mã hóa của chúng ta sẽ là [0,1,0,1]
Train model
Để train model chúng ta sẽ sử dụng Adam optimizer, chúng ta sử dụng thêm Keras callbacks để tìm ra weight tốt nhất.
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer = 'adam')
filepath="best_model.hdf5"
checkpoint = ModelCheckpoint(filepath=filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
callbacks_list = [checkpoint]
training_img = np.array(training_img)
train_input_length = np.array(train_input_length)
train_label_length = np.array(train_label_length)
valid_img = np.array(valid_img)
valid_input_length = np.array(valid_input_length)
valid_label_length = np.array(valid_label_length)
batch_size = 256
epochs = 10
model.fit(x=[training_img, train_padded_txt, train_input_length, train_label_length], y=np.zeros(len(training_img)), batch_size=batch_size, epochs = epochs, validation_data = ([valid_img, valid_padded_txt, valid_input_length, valid_label_length], [np.zeros(len(valid_img))]), verbose = 1, callbacks = callbacks_list)
Kết quả:

VI. Kết luận
Trên đây là bài viết chia sẻ của mình về CRNN+CTC cho bài toán text recognition, cảm ơn các bạn đã theo dõi bài viết của mình nếu thấy hay cho mình xin 1 lượt upvote để thêm động lực viết bài nhé. Cảm ơn các bạn  ))
))
All rights reserved
