[Lập trình song song] Bài 13: Shared memory
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài viết này mình sẽ giới thiệu các bạn cách dùng shared memory trên GPU bằng cuda, trước khi đọc bài viết này thì hãy xem qua bài viết Các bộ nhớ trong GPU
Shared memory
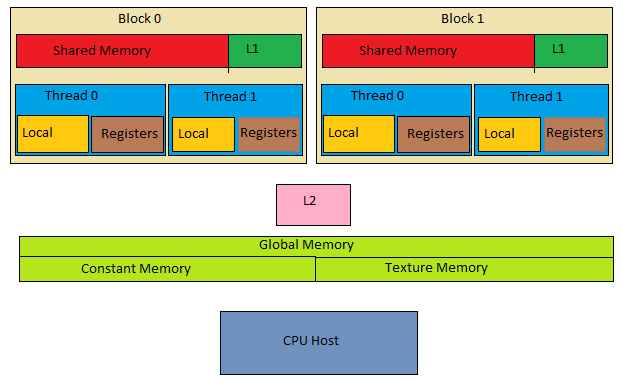
Shared memory là memory nhanh nhất ( chỉ sau register file ) trong GPU và phạm vi truy cập của shared memory là các thread trong 1 cùng block
Mỗi khi copy data từ global --> shared chúng ta phải syncthread để đồng bộ các threads trong cùng 1 block để tránh race conditional vì while threads in a block run logically in parallel, not all threads can execute physically at the same time. ( có thể hiểu là các thread không khởi chạy cùng 1 thời điểm dẫn đến sẽ có 1 số thread xong trước, vậy nên cần syncthread )
Các bạn có thể tham khảo lại 2 bài này để hiểu rõ hơn: Data Hazard + Synchronization - Asynchronization
Đây là quy trình data đi từ global --> shared
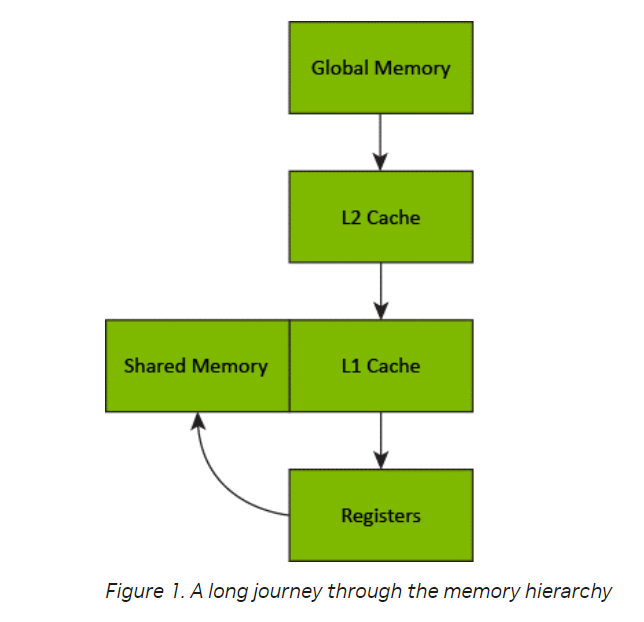
Ở bài viết này mình chỉ tập trung vào khái niệm cũng như cách dùng shared memory, ở những bài sau mình sẽ chỉ những kĩ thuật giúp cải thiện cũng như tối ưu khi dùng shared memory
Code
Chúng ta đã quá quen với khái niệm static - dynamic memory thì ở shared memory chúng ta cũng có
__global__ void staticReverse(int *data, int n)
{
__shared__ int s[64];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = data[t];
__syncthreads();
data[t] = s[tr];
}
__global__ void dynamicReverse(int *data, int n)
{
extern __shared__ int s[];
int t = threadIdx.x;
int tr = n-t-1;
s[t] = data[t];
__syncthreads();
data[t] = s[tr];
}
Ở đây bài toán của chúng ta có 2 bước là:
- copy data từ global sang shared theo thứ tự bé đến lớn
- copy data từ shared về lại global theo thứ tự từ lớn đến bé
staticReverse<<<1,n>>>(d_data, n);
dynamicReverse<<<1,n,n*sizeof(int)>>>(d_data, n);
<<<a,b,c,d>>> lần lượt là:
- a: số block
- b: số thread trong 1 block
- c: kích thước của shared memory
- d: số streaming
code mình sẽ để ở đây
All rights reserved
