[Lập trình song song] Bài 4: Cách thức hoạt động CPU-GPU
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài này mình sẽ đi sâu hơn 1 tí về cách thức vận hành của CPU và GPU và thông qua đó chúng ta sẽ trả lời được câu hỏi cuối cùng mà mình đã đề cập ở bài 3
1 lưu ý nhỏ là nếu bạn nào muốn đọc bằng tiếng anh thì có thể ghé qua github, vì tiếng anh nên từ ngữ dùng sẽ chính xác hơn khi viết lại bằng tiếng việt
CPU và GPU
Hồi xưa mình đã từng có câu hỏi ngớ ngẫn là CPU và GPU thì cái nào quan trọng hơn hay là khi mua máy tính chúng ta nên ưu tiên CPU hay là GPU hơn thì câu trả lời sẽ là tùy thuộc vào mục tiêu sử dụng của chúng ta để xác định nên ưu tiên cái nào hơn vì CPU và GPU được thiết kế với các mục đích khác nhau
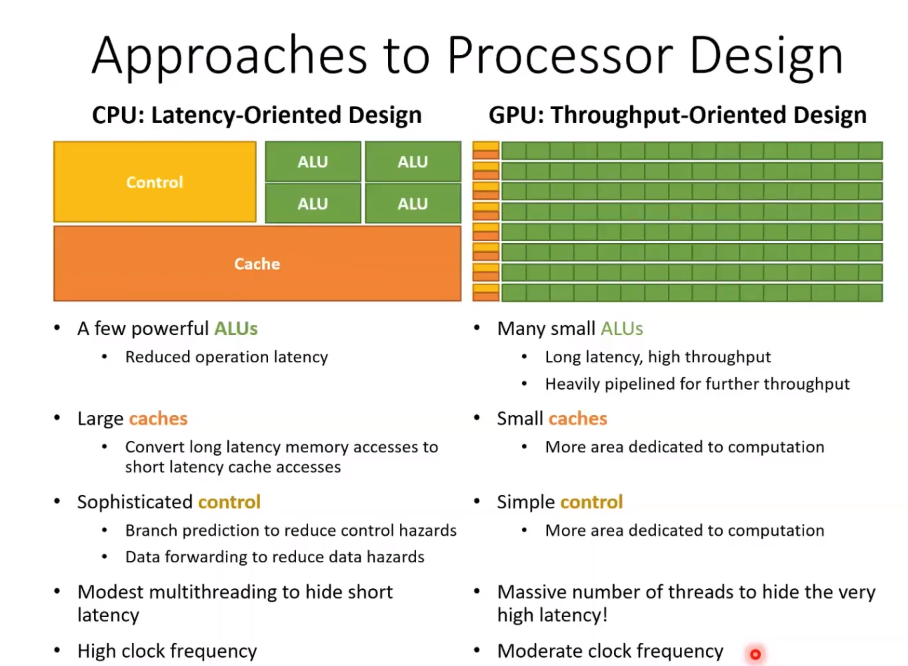
Approaches to processor Design
 CPU và GPU được thiết kế với 2 mục tiêu khác nhau nên không thể so sánh với nhau được, vậy thì 2 mục tiêu đó là gì?
CPU và GPU được thiết kế với 2 mục tiêu khác nhau nên không thể so sánh với nhau được, vậy thì 2 mục tiêu đó là gì?
CPU: Latency-Oriented Design
Là phương pháp thiết kế với mục tiêu là làm giảm độ trễ hoặc thời gian phản hồi trong việc xử lí các task phức tạp nhưng số lượng ít. Tại sao lại là giảm độ trễ hoặc thời gian phản hồi? Là vì CPU được thiết kế với số lượng cores rất ít NHƯNG bù lại mỗi core của CPU rất là chất lượng, rất là mạnh, rất là xịn nên ta có thể nói core của CPU đa nhiệm ( ví dụ như: thực thi các tác vụ ứng dụng, quản lí tài nguyên, điều khiển hệ thống, xử lí thông tin,...)
==> CPU dùng để xử lí các task phức tạp nên vì vậy mục tiêu khi thiết kế CPU là giảm độ trễ hoặc thời gian phản hồi khi xử lí các task đó.
Như trong hình ta có thể thấy Control Unit và Cache chiếm phần lớn diện tích:
- Control unit lớn: giúp tối ưu trong việc điều khiển các phép logic phức tạp (AND, OR, XOR, ..)
- Cache lớn: giúp giảm thời gian truy xuất data
==> CPU thiên về sử dụng Cache và điều khiển
CPU: Hide short latency
Một trong những phương pháp giúp giảm độ trễ hoặc thời gian phản hồi của CPU là modest multithreading. Cách thức hoạt động của modest multithreading:
- CPU thực thi 1 công việc thì công việc đó sẽ được chia thành K task nhỏ
- CPU tạo ra 1 vài shadow threads ( thread dự phòng )
- Các shadow threads sẽ xử lí 1 phần nhỏ của K task, phần còn lại sẽ do main threads xử lí
- Khi các main threads gặp 1 vài vấn đề dẫn đến latency ( ví dụ như: đợi read data, đợi transfer data ) thì các main threads sẽ nhảy qua xử lí 1 phần nhỏ công việc mà shadow threads đang làm cho đến khi hết latency ( tức là khi data được read xong, các data đã được transfer xong ) thì sẽ nhảy về lại để làm tiếp. ( nên vì vậy mới có tên gọi là hide short latency )
GPU: Throughput-Oriented Design
Là phương pháp thiết kế với mục tiêu là tăng khả năng xử lí 1 lượng task lớn nhưng đơn giản trong thời gian ngắn. Vậy tại sao lại là xử lí nhiều task cùng 1 lúc trong 1 thời gian ngắn? Là vì GPU được thiết kế với số lượng core rất nhiều nhưng lại kém chất lượng hơn so với core của CPU, nên vì vậy mục tiêu của GPU là xử lí các task đơn giản nhưng số lượng nhiều ( giống như tôi yếu nhưng anh em tôi đông )
===> Vì vậy GPU xử lí các task đơn giản nhưng số lượng lớn nên cần tăng khả năng xử lí 1 lượng lớn task trong thời gian ngắn
Như trong hình ta có thể thấy phần lớn diện tích là các đơn vị tính toán:
- Nhiều core: dẫn đến việc tính toán nhanh hơn ==> để đáp ứng được nhu cầu cung cấp data cho việc tính toán nên GPU được thiết kế với 1 kiến trúc giúp cho bandwidth ( băng thông ) trở nên nhanh hơn và memory cũng nhiều hơn (bandwidth/memory của GPU hơn CPU rất nhiều )
==> GPU dùng vào mục đích xử lí lượng lớn data và song song
GPU: Hide very high latency
một trong những phương pháp giúp tăng khả năng xử lí 1 lượng lớn task trong thời gian ngắn của GPU là sử dụng massive number of threads ( 1 lượng lớn threads )
==> có thể hiểu đơn giản là mình tăng số lượng task được thực thi tại 1 điểm thì tức là mình đã giảm được tổng thời gian cần thực hiện tất cả các task
Tóm tắt:
CPU xử lí các task phức tạp nhưng ít
GPU xử lí nhiều task nhưng đơn giản
CPU giống như là 1 chiếc siêu xe với 1 bộ mã lực siêu mạnh, GPU giống như là 1 chiếc xe bus siêu dài và nhiệm vụ là chở khách. Thì nếu chỉ chở 1 số lượng ít khách thì CPU sẽ nhanh hơn nhưng nếu số lượng khách nhiều thì GPU sẽ là lựa chọn tuyệt vời.
Multithreads: chia 1 task lớn thành các task con và để nhiều threads xử lí ==> short latency
Massive threads: tạo ra nhiều threads để thực hiện nhiều task ==> high latency
Một chút thú vị về GPU
Mỗi khi nhắc đến GPU là ta nhắc đến card đồ họa ( Graphics Card ) vậy thì tại sao người ta lại đặt cái tên đó? Hồi xưa, khi ngành game nói riêng cũng như các ngành liên quan đến xử lí đồ họa nói chung đang ngày càng được nhiều người biết tới ==> nhu cầu tăng cao nhưng chất lượng thì vẫn không có sự phát triển ( cung thì tăng còn cầu thì vẫn vậy ) lý do hết sức đơn giản: ví dụ 1 bức ảnh sắc nét và đẹp thì cũng cỡ 1600x900 ( này là con số mình lấy ví dụ nhưng các bạn có thể hình dung tất là CPU phải xử lí 1440000(1600x900) pixel tại 1 thời điểm và nhiệm vụ là video tức là frame tức là tại mỗi thời điểm phải xử lí nhiều bức ảnh có số lượng pixel như vậy ).
Mà như mình đã phân tich trên thì CPU nếu dùng để xử lí từng pixel 1 thì quá phí tài nguyên ( có thể hiểu đơn giản là for loop tới chết mà mỗi iteration ( lần lặp ) thì công việc lại đơn giản ==> không tận dụng triệt để khả năng của CPU, giống như việc dùng siêu xe để chở khách ). Thì lúc này người ta mới phát minh ra Graphics card chỉ dành riêng cho 1 mục đích là xử lí pixel. Sau này ngày càng phát triển dẫn đến việc tính toán của GPU ngày càng ưu việt nên người ta mới áp dụng GPU vào nhiều lĩnh vực khác liên quan đến tính toán nên mới có cái tên là GPGPU ( General-Purpose tính toán trên Graphics Processing Units )
Phân tích câu hỏi cuối bài 3
Trước khi giải đáp câu hỏi thì mình sẽ đi qua 2 khái niệm SIMD và SIMT
CPU: SIMD ( Single Instruction, Multiple Data): là một kiến trúc máy tính thường được sử dụng trong CPU với mục tiêu là làm sao tại mỗi instruction xử lí nhiều data nhất có thể
GPU: SIMT (Single Instruction, Multiple Threads): là một kiến trúc máy tính được phát triển bởi NVIDIA và được sử dụng trong GPU với mục tiêu là làm sao tại mỗi instruction sử dụng nhiều threads nhất có thể
Cả SIMD và SIMT đều là các kiến trúc được sử dụng trong việc xử lý dữ liệu song song trên các thiết bị tính toán như CPU và GPU.
Thoạt nhìn thì SIMD và SIMT có vẻ giống nhau nhưng nó là 2 kiến trúc khác nhau ở 1 số điểm cũng như lý do tại sao CPU lại là SIMD và GPU là SIMT
Như đã đề cập:
- CPU: vì xử lí task phức tạp nên cơ chế của SIMD sẽ chia task phức tạp đó ra thành các task con và từ đó sẽ xử lí song song các task con
- GPU: vì xử lí nhiều task đơn giản nên cơ chế của SIMT sẽ là xử lí song song các task lun
Ví dụ: bài toán cộng 2 vector ( mỗi vector chứa N phần tử )
- SIMD: ở đây nhiệm vụ sẽ là thực hiện 1 bài toán cộng 2 vector và từ đó SIMD sẽ chia bài toán cộng 2 vector thành N bài toán con là cộng 2 phần tử và từ đó thực hiện song song N bài toán con này
- SIMT: ở đây dưới góc nhìn của SIMT thì mỗi vector chứa N phần tử sẽ là N bài toán độc lập tức là nhiệm vụ sẽ là thực hiện N bài toán cộng các phần tử ( tức là sẽ có N bài toán chứ không phải là N bài toán con ) và từ đó mình ( các coder ) sẽ tự chia các thread để xử lí song song N bài toán này
SIMD: máy tính sẽ tự chia 1 bài toán lớn ( cộng 2 vector ) thành N bài toán con
SIMT: mình sẽ là người thực hiện chia các thread để xử lí N bài toán này
Phân tích câu hỏi
Bài toán của chúng ta là in hello world 10 lần và vì là SIMT nên mình sẽ tự chia các thread để thực hiện việc in hello world này. Ở đây mình chia các thread thành 2 kiểu là <<<1,10>>> và <<<2,5>>> vì chỉ là 10 thread nên 2 cách này là như nhau nhưng nếu bài toán là in hello world 64 lần và được biểu diễn là <<<1,64>>> và <<<2,32>>> thì lúc này sẽ có sự khác biệt ( là vì tại mỗi thời điểm trong 1 block chỉ thực hiện 32 warp ) nên nếu là <<<1,64>>> tức là sẽ tốn 2 đơn vị thời gian để xử lí xong 64 lần in hello world, còn <<<2,32>>> cũng chỉ tốn 1 đơn vị thời gian để xử lí.
Mình có giải thích rõ hơn ở bài bonus 2 nằm ở phần các QUY TẮC
Tóm lại qua bài này các bạn đã hiểu rõ hơn về CPU cũng như GPU, và vì là cơ chế SIMT nên việc chia các thread 1 cách hợp lí sẽ rất là quan trọng nên vì vậy chúng ta phải biết dùng bao nhiêu thread cho mỗi block cho hợp lí.
Nếu các bạn thấy bài viết hay thì xin hãy star cho mình ở github nha
All rights reserved
