[NVIDIA Tools] Bài 10: Bandwidth - Throughput - Latency
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài viết này mình sẽ giới thiệu 3 khái niệm rất quan trọng trong việc profiling là Bandwidth - Throughput - Latency
Bandwidth - Throughput - Latency
Để đánh giá 1 đoạn code, 1 chương trình thì ba khái niệm quan trọng cần được xem xét là bandwidth, throughput và latency . Tuy nhiên, chúng ta thường dễ nhầm lẫn khi chỉ đưa ra một trong ba thông tin này mà không kèm theo các thông tin khác, dẫn đến đánh giá không chính xác về hiệu năng - hiệu suất. Vì mỗi máy tính khác nhau có thể có dẫn đến thông số về latency hoặc bandwidth khác nhau, việc chỉ cung cấp một thông tin sẽ không phản ánh được hiệu năng thực sự của đoạn code.
Latency
Latency(s) : là thời gian để hoàn thành 1 task. 1 lưu ý vô cùng quan trọng là khi profile ( ví dụ như cudaEvent_t start, stop ) sẽ khiến performance bị ảnh hưởng nên vì vậy khi chạy chương trình 1 lần cuối nên xóa các dòng code profile.
Và thay vì dùng cudaEvent_t start, stop để kiểm tra latency thì chúng ta có thể dùng nsight system cho việc đó bằng command
nsys profile -o timeline --trace cuda,nvtx,osrt,openacc ./a.out
Thì lúc này tất cả những thứ chạy trên GPU sẽ được measure 1 cách chi tiết
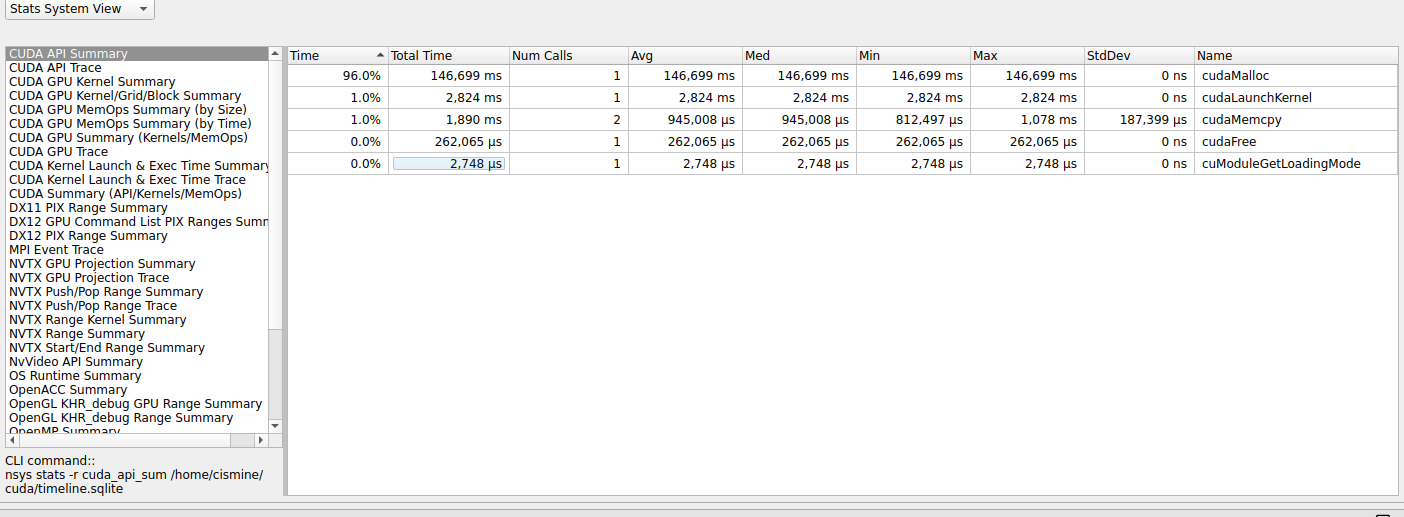
Và như bài Giới thiệu Nsight Systems - Nsight Compute thì qua các thông số phía trên chúng ta có thể xác định là đoạn code của chúng ta cần cải thiện ở phần cấp phát data cho GPU (cudaMalloc)
Bandwidth
Bandwidth(GB/s) : thể hiện tốc độ read/write data
Khi nhắc tới Bandwidth chúng ta sẽ đề cập tới 2 khái niệm:
- Theoretical Peak Bandwidth: tốc độ lý tưởng trong việc transfer data
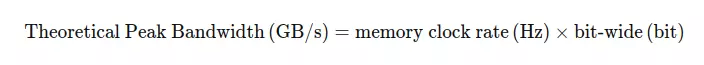
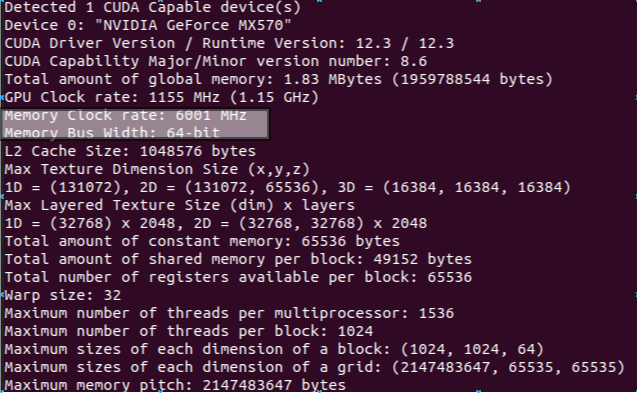
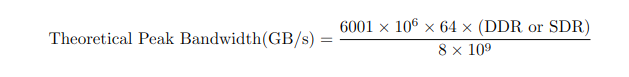
Chia cho 8 vì đổi từ bit sang byte
Chia cho 10^9 là dùng để đổi qua GB/s
DDR: double data rate thì là * 2
SDR: single data rate thì * 1
Cách xác định DDR hoặc SDR bằng command:
sudo lshw -c memory
Và vì máy mình là DDR nên
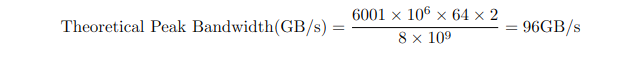
- Effective bandwidth : là tốc độ thực sự trong việc transfer data của kernel
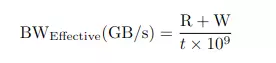
R(B): số lượng byte được read mỗi kernel
W(B): số lượng byte được write mỗi kernel
t(s): latency
Code
Chúng ta sẽ thực hiện bài toán y[i] = a*x[i] + y[i] với N = 20 * (1 << 20)
__global__
void saxpy(int n, float a, float *x, float *y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
// Perform SAXPY on 1M elements
saxpy<<<(N+511)/512, 512>>>(N, 2.0f, d_x, d_y);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
printf("time: %f\n", milliseconds);
printf("Effective Bandwidth (GB/s): %f", N*4*3/milliseconds/1e6);
}
Áp dụng công thức R + W thì N * 3 là vì read a + read y + write y và N * 4 là đổi qua byte ( float = 4 byte)
Và đây là output

Nhưng nếu các bạn profile bằng Nsight compute bằng command:
ncu -o profile --set full ./a.out
Thì sẽ thấy là

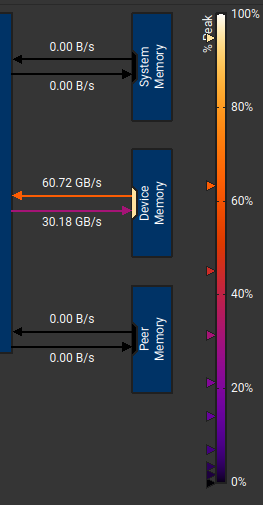

Từ đây chúng ta có thể tính toán
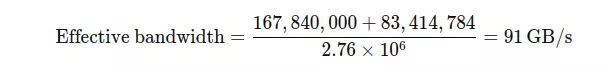
Như mình đã đề cập phía trên, nếu chúng ta profile ( cudaEvent_t start, stop ) sẽ khiến performance của code bị ảnh hưởng từ 91GB/s --> 87.8GB/s
Và chúng ta cũng có thể tính toán ngược lại để xác định
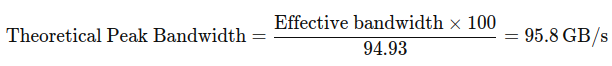
Việc bị lệch 1 xíu so với công thức phía trên ( 96 GB/s --> 95,8 GB/s là do các yếu tố như memory và kernel ảnh hưởng )
Từ đây chúng ta có thể kết luận code của chúng ta về mặt transfer data rất ổn - không có sự chênh lệch lớn giữa Theoretical - Effective
Các bạn có thể xác định effective bandwidth nhanh hơn bằng command:
Load: ncu --metrics l1tex__t_bytes_pipe_lsu_mem_global_op_ld.sum.per_second ./a.out
Store: ncu --metrics l1tex__t_bytes_pipe_lsu_mem_global_op_st.sum.per_second ./a.out


Ta có thể thấy 60.68 + 30.40 = 91.08 GB/s gần với 96GB/s ==> code ổn
Computational Throughput
Throughput(GFLOP/s): Là số lượng FLOP mà kernel có thể thực hiện trong một giây
FLOP (Floating Point Operations): Là một phép toán dấu chấm động. Một phép toán này có thể là phép cộng, trừ, nhân, chia, hoặc các phép toán phức tạp hơn như căn bậc hai, sin, cos,....
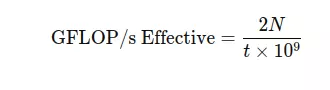
Câu hỏi đặt ra là nên cải thiện bandwidth hay là throughput? Vì ông này tăng là ông khác giảm vậy làm sao biết được giá trị đạt chuẩn?
Tăng bandwidth ==> nhiều data được read/write ==> số lượng phép toán tăng ==> throughput giảm và ngược lại
Để trả lời cho câu hỏi đó chúng ta có 1 kĩ thuật gọi là roofline chart và mình sẽ đề cập ở các bài sau
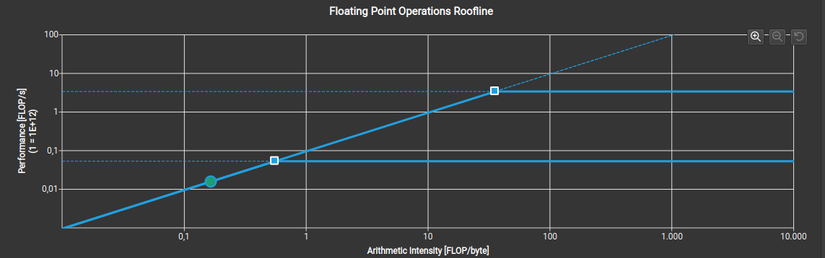
code mình sẽ để ở đây
All rights reserved
